基于变分自编码器的人脸正面化产生式模型
2018-02-12张鹏升
张鹏升
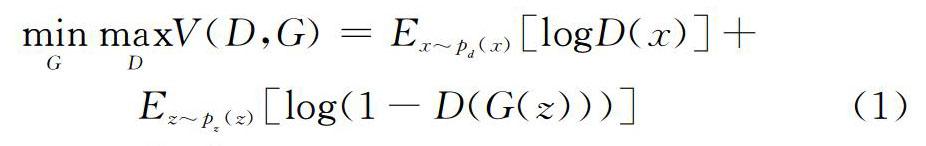
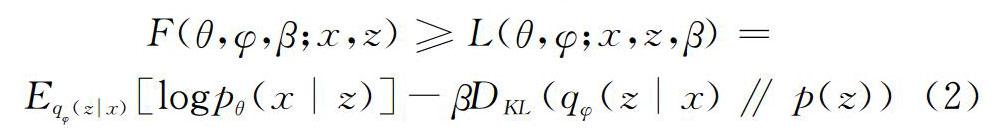
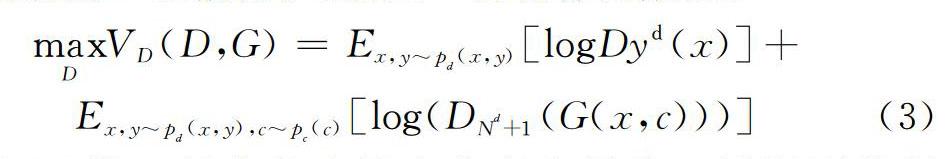
摘要:在人脸识别中,人脸姿态差异处理始终是一个难点。人脸正面化中大体可以分为两类:一是通过图形学方法生成正脸,二是通过产生式模型生成正脸。然而,第一类方法生成的正脸畸变会比较大,第二类方法普遍采用GAN网络,但是训练过程不易收敛。为解决以上问题,设计基于变分自编码器的产生式模型,采用β VAE模型,学习隐空间与真实图片空间关系,提高图片生成质量;使用模拟+无监督(S+U)学习方法,提高模型在训练过程的稳定性。通过在Multi PIE数据集上进行实验,模型在定量打分中取得了不错效果,能够生成更加真实的图片。实验证明,该模型能够有效解决传统方法中生成图片不真实和训练不稳定的问题。
关键词:人脸正面化;产生式模型;对抗生成网络;变分自编码器
The Generative Adversarial Network Based on Variational
Auto encoder for Face Frontalization
ZHANG Peng sheng
(Information Technology and Network Security, People′s Public Security University of China,Beijing 102623,China)
Abstract:Pose variations are always difficult to handle in face recognition. Face frontalization can be roughly divided into two categories. The first one is to obtain a frontal face by means of graphics. The second is to get a frontal face through the generative model. However, the frontal face images generated by the first method can be seriously distorted. The second method usually uses the GAN network. However, the process of training is not easy to converge. In order to solve the above problems, this paper proposes a generative network model based on variational auto encoder and makes the following innovations. First, the model uses the β VAE to learn the relationship between hidden space and real picture spaces so that the quality of the generated images is improved. Second, the model uses the simulation + unsupervised (S+U) learning method to the stability of the training process. We conducted experiments on the Multi PIE dataset, which achieved good results in quantitative scoring and could generate more realistic images. Through experiments, it is proved that the proposed model can effectively solve the problem of generating unrealistic images and unstable training in traditional methods.
Key Words:face frontalization; generating model; generative adversarial network; variational auto encoder
0 引言
神經网络快速发展,各种网络模型出现,大规模人脸数据集可以进行训练,使得人脸识别技术取得了巨大进步。例如,Schroff等[1]提出的FaceNet网络在LFW数据集上识别率达到了99.63%。但是,姿态不变的人脸识别(Pose Invarian Face Recognition,PIFR)依然是人脸识别中一个巨大挑战[2]。Sengupta等[3]通过CFP数据集测试表明,在根据正脸或侧脸判别身份时,最优算法都比人类直观判别的效果差。所以,如何处理人脸姿态差异始终是人脸识别的一个难点。
目前人脸姿态识别解决方案大体可以分为两类:第一类是希望直接通过对非正脸进行学习得到可判别特征,如单一网络模型FaceNet根据不同姿态人脸特征之间的距离大小进行判断,以及多视图[4 5]或多特定角度的网络模型[6]先对人脸角度进行分类,再用对应角度的卷积网络进行识别;第二类是人脸正面化,将侧脸正面化,再对新生成的正面人脸进行判别,如Hassner等[7]利用图形学方法使用平均3D面部模型生成正脸,被证明有用且高效。基于深度神经网络的产生式模型在人脸正面化方面同样取得了很好成绩,如堆叠渐进式自编码器(Stacked Progressive Auto Encoders,SPAE)通过自编码器将非正脸旋转为正脸[8],以及通过对抗生成网络(Generative Adversarial Network,GAN)的各种变形合成正面人脸[9 12]。
目前,流行的产生式模式大多采用GAN网络模型,其中取得较好效果的有DR GAN网络模型,它能够学习姿态不变的身份表示特征,同时合成任意角度的人脸[12]。但是,该网络依旧存在两点问题:一是其编码—解码结构生成器的解耦表示特征不明显,保持身份特征的效果不是很好;二是GAN网络存在训练不稳定、不易收敛、对多样性与准确性惩罚不平衡等问题。
针对以上问题,本文设计基于变分自编码器(Variational Auto Encoder, VAE)的对抗生成网络模型,其由生成网络和判别网络两部分组成。生成网络采用β VAE模型,目前在解耦表示学习方面,β VAE模型是公认效果最好的[13]。生成网络中,编码器G enc输入任意角度的人脸,解码器G dec输出特定角度的人脸。判别网络D不仅区分图片为真实图片还是合成图片,而且还预测图片的身份。总体而言,本文进行了如下创新:①采用β VAE模型作为生成模型,在编码过程中不加条件,在解码过程中加入姿态编码c,通过采用变分自编码器模型,可使G enc更好地学习姿态不变情况下人脸特征表示;②运用模拟+无监督(Simulated + Unsupervised ,S+U)学习方法[14],采用局部對抗损失函数,避免G网络只注重图片的某一区域而欺骗D网络,并且设置缓存区,使用已经判别过的图片持续更新D,通过S+U方法提高整个网络训练过程的稳定性和有效性。
1 相关研究
1.1 人脸正面化
因为侧面人脸只含有正面人脸的一部分信息,所以根据侧脸生成正脸具有挑战性,一直是计算机视觉领域的一个难题。人脸正面化可以应用于人脸编辑、姿态变换、数据增益、表示学习等多个领域,因此受到广泛关注。人脸正面化常见方法可以分为两类:一是利用图形学方法从侧脸获得正面人脸,二是通过产生式模型根据侧脸生成正脸。在第二类方法中,可以引入对称性强约束,减小一对多问题困难,如TP GAN[9]通过一条全局通路和4个局部通路相融合,加入对称性损失函数,确保生成的人脸更真实。此外,如CAPG GAN、DR GAN能够进行任意角度人脸旋转,进一步提升了网络性能[11 12]。
1.2 对抗生成网络
本文产生式模型整体框架采用对抗生成网络模型,由生成网络和判别网络两部分组成。2014年,Goodfellow等[15]提出了对抗生成网络模型,GAN启发于博弈论中的二人零和博弈,博弈双方分别是生成网络 G和判别网络D。生成网络G尽可能学习样本数据分布,用服从某一分布的噪声z生成类似真实数据样本,生成样本越像真实样本就越好;判别网络D 是一个二分类器,尽可能判别接收的样本来自真实数据还是生成数据。二者关系可以用式(1)表示。
但是,文献[16]指出原始GAN网络在训练过程中容易发生 D达到最优、G梯度消失的现象,因为在判别网络D达到最优时,最小化生成网络G的损失函数等价变换为最小化真实分布p d与生成分布p z 之间的JS散度[15]。 p d和p z 大概率存在不重叠情况,此时JS散度为常数log2,导致 G 梯度消失。同时,因为KL散度的不对称性,GAN训练过程容易出现惩罚不准确、多样性不足问题。本文生成网络采用变分自编码器模型,改进了 D的损失函数,避免出现梯度消失情况,而且采用S+U 学习方法,增强了网络训练过程中的稳定性和图片生成的多样性。
1.3 变分自编码器
在本文产生式模型中,生成网络采用β VAE结构。变分自编码器是一类重要的生成模型,于2013年由Kingma等[17]提出。VAEs由编码器和解码器两部分组成,与GANs网络直接进行度量生成样本分布和真实样本分布不同,VAEs从变分和贝叶斯理论出发,将学习目标变成尽可能满足某个预设先验分布的性质[18]。通常希望一个好的生成模型可以学到数据的解耦表示,β VAE是目前最有效的模型之一[13]。该模型使用修正系数β修正VAE目标函数,通过重建精度、变化后验分布和先验分布的KL散度以更好地学习解耦表示。β VAE目标函数如下:
其中,生成模型通过标准的高斯先验 p(z)=N(0,1)定义,解码器p θ(x|z)通过神经网络进行优化,后验分布为q φ(z|x)。方程右半部分是期望E p data(x) [log p(x)]的变分下界。当β=1时,目标函数变为原始VAE的函数,其它情况取β>1,增强隐变量之间的独立性,以更好地学到数据的解耦表示。
2 网络模型
在本文模型中,生成网络采用变分自编码器结构从人脸图片学习身份表示, G采用人脸图片、姿态编码c作为输入,从而生成具有相同身份特定角度的人脸。G enc学习图片到特征表示的映射,G dec接收学到的表示并用姿态编码进行人脸旋转。判别网络D判别图片的身份,与G相互竞争,促使G 生成更加真实且具有特定身份的图片。
2.1 判别网络目标函数
给定人脸图片 x以及标签y={y d,y p},其中y d代表身份,y p代表角度。生成网络G的目标是学习姿态不变的身份表示,并且合成特定角度y p但具有相同身份y d的图片。判别网络D∈RN d+1代表身份判别器,N d包括身份类别总个数,1代表生成图片为假一类。对于真实图片x,D需要判断出它的身份;对于合成图片=G(x,c),D需要判断出是假的。因此,D的目标函数是:
式(3)第一部分代表最大化真实图片 x被识别的概率,第二部分代表最大化生成图片 被判断为假的概率。
2.2 生成网络目标函数
生成网络 G采用β VAE结构,包括编码器G enc和解碼器G dec。编码器输出隐变量z的均值μ和方差σ 文献[17]中指出q(z|x)~N(μ(x),σ(x)),同时需要保证q(z|x)向N(0,1)看齐,达到先验假设p(z)为标准正态分布,因此通过KL散度进行约束。公式推导如下:
隐变量通过重参数技巧采样 z=μ+ε×σ,其中选取ε~N(0,1)。采样操作不可导,但是利用重参数技巧使得从N(μ,σ 2)采样z转换为从N(0,1)采样ε,保证采样结果可导,使得整个模型可以训练。通过获得从x到z的映射f(x),G dec根据姿态编码c生成合成图片=G dec(f(x),c)。其中,姿态编码c∈RN P由特定角度标签y p经过one hot编码而来。因此,G的目标函数为:
其中, β>1激励生成网络G更好地学习各个变量的表示,增强网络解耦性。G和D网络进行交替更新,当D判别能力不断提高时,G也努力生成具有特定身份的正面人脸图片。
3 实验
3.1 网络结构
在实验中, G enc和判别网络D 采用CASIA Net网络模型,而且在每个卷积层后添加批归一化(Batch Normalization,BN)层和指数线性单元(Exponential Linear Unit,ELU)层[19]。 G enc与G dec之间添加全连接层,通过隐变量进行连接,G dec由与G enc相反的反卷积层组成。判别网络D的全连接层输出大小为N d+1,网络结构可简化为图1。
给定人脸图片 x ,通过生成网络G enc和G dec两部分生成图片 ,判别网络D接收真实图片x,生成图片进行更新并将梯度反传给生成网络G,G 根据目标函数式(5)更新参数。
3.2 实验细节
本文使用Multi PIE数据集进行训练,如文献[12]对数据集的设置一样,使用数据集中337位具有中性表情的参与者人脸进行实验,角度选取±60°,共9种,以及20种不同光照强度。选取200名参与者的人脸图片作为训练集,剩余137名参与者的人脸图片作为测试集。在训练过程中,因为Multi PIE数据集存在光照影响,因此,添加光照编码以提升网络的解耦性, N d=200,N P=9,Nil=20 。
训练过程采用S+U训练方法。在传统的对抗训练过程中, G有时会局限于图片的某一特征,重点放在一个区域欺骗D网络,忽视了整张图片的特征。因此,可以采用局部对抗损失函数,定义判别网络分别计算图片每个区域的交叉熵损失值并累加,从而促使生成图片的每一个区域都更加真实,而且G有时会生成重复图片,但是D因为惩罚的不准确性可能不予约束。因此,可为之前生成的图片设置缓存区,B为缓存区图片数量,b为每次批训练的大小。在每轮D的训练过程中,使用b/2当前生成图片和b/2缓存区图片计算损失函数,更新参数。训练过程始终保持B数量固定,每次训练结束后用随机的b/2 新生成refined图片替换缓存区图片,从而保证训练过程的稳定性。
3.3 实验结果
分别使用DR GAN和本文网络模型,通过选择是否采用S+U训练方法进行实验。直观上,可以通过生成图片观察不同网络模型的生成效果,此外,可以根据文献[20]中起始分值定量衡量生成图片的真实性,还可根据文献[21]中模型分数定量衡量生成图片的多样性。本文选取了测试集中4位参与者的侧脸进行人脸正面化,效果如图2所示。
在图2中,第一列为输入的侧脸图片,第2、3列是DR GAN未使用和使用S+U训练方法生成的图片,最后两列是本文设计模型未使用和使用S+U训练方法生成的图片。通过对比生成图片效果和采用定量衡量方式,本文网络模型通过使用S+U训练方法,能够较好地实现人脸正面化。
4 结语
GANs、VAE等生成模型迅速发展,使得人脸正面化在近来研究中已经取得巨大进步[22]。基于变分自编码器的产生式模型,结合了两类模型优点,使得训练过程可以学到更具区别性的身份表示,增强了网络的解耦性;采用新的训练技巧,提升了网络稳定性与生成图片多样性。但是,训练时间长以及未能高效应对多种干扰因素等问题仍需继续改进[23]。
参考文献:
[1] SCHROFF F, KALENICHENKO D, PHILBIN J. Facenet: a unified embedding for face recognition and clustering[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:815 823.
[2] DING C, TAO D. A comprehensive survey on pose invariant face recognition[J]. ACM Transactions on Intelligent Systems and Technology (TIST),2016,7(3):37.
[3] SENGUPTA S, CHEN J C, CASTILLO C, et al. Frontal to profile face verification in the wild[C]. IEEE Winter Conference on Applications of Computer Vision,2016:1 9.
[4] KAN M, SHAN S, CHEN X. Multi view deep network for cross view classification[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:4847 4855.
[5] XIA Y, QIN T, CHEN W, et al. Dual supervised learning[DB/OL]. Arxiv Preprint:1707.00415, 2017.
[6] MASI I, RAWLS S, MEDIONI G, et al. Pose aware face recognition in the wild[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:4838 4846.
[7] HASSNER T, HAREL S, PAZ E, et al. Effective face frontalization in unconstrained images[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 4295 4304.
[8] KAN M, SHAN S, CHANG H, et al. Stacked progressive auto encoders(SPAE) for face recognition across poses[C].IEEE Conference on Computer Vision and Pattern Recognition, 2014:1883 1890.
[9] HUANG R, ZHANG S, LI T,et al. Beyond face rotation: global and local perception GAN for photorealistic and identity preserving frontal view synthesis[C].IEEE International Conference on Computer Vision, 2017:2458 2467.
[10] CAO J, HU Y, ZHANG H, et al. Learning a high fidelity pose invariant model for high resolution face frontalization[DB/OL].Arxiv Preprint:1806.08472,2018.
[11] HU Y, WU X, YU B, et al. Pose guided photorealistic face rotation[C]. Salt Lake City: IEEE Conference on Computer Vision and Pattern Recognition, 2018.
[12] LUAN T, YIN X, LIU X. Disentangled representation learning GAN for pose invariant face recognition[C]. Computer Vision and Pattern Recognition,2017:1283 1292.
[13] HIGGINS I, MATTHEY L, PAl, et al. Beta VAE: learning basic visual concepts with a constrained variational framework[C]. Toulon: International Conference on Learning Representations (ICLR), 2017.
[14] SHRIVASTAVA A, PFISTER T, TUZEL O, et al. Learning from simulated and unsupervised images through adversarial training[C]. Computer Vision and Pattern Recognition,2017,2(4):5.
[15] GOODFELLOW I J, POUGET ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. International Conference on Neural Information Processing Systems,2014:2672 2680.
[16] ARJOVSKY M, BOTTOU L. Towards principled methods for training generative adversarial networks[DB/OL].Arxiv Preprint:1701.04862,2017.
[17] KINGMA D P, WELLING M. Auto encoding variational Bayes[DB/OL].Arxiv Preprint:1312.6114, 2013.
[18] DOERSCH C. Tutorial on variational autoencoders[DB/OL].Arxiv Preprint:1606.05908,2016.
[19] YI D, LEI Z, LIAO S, et al. Learning face representation from scratch[DB/OL].Arxiv Preprint:1411.7923,2014.
[20] SALIMANS T, GOODFELLOW I, ZAREMBA W, et al.Improved techniques for training GANS[C]. Advances in Neural Information Processing Systems,2016:2234 2242.
[21] HEUSEL M,RAMSAUER H,UNTERTHINER T,et al. GANS trained by a two time scale update rule converge to a local Nash equilibrium[C].Advances in Neural Information Processing Systems,2017:6626 6637.
[22] 許哲豪,陈玮.基于生成对抗网络的图片风格迁移[J].软件导刊,2018,17(6):207 209+212.
[23] 邹国锋,傅桂霞,李海涛,等.多姿态人脸识别综述[J].模式识别与人工智能,2015,28(7):613 625.
