汉语复句中基于依存关系与最大熵模型的词义消歧方法研究
2018-02-09翟宏森刘凤娇黄文灿杨梦川
李 源 翟宏森 刘凤娇 黄文灿 杨梦川
(华中师范大学计算机学院 武汉 430079)
1 引言
在汉语自然语言中,由于复句运用的灵活性和网络用语的广泛使用,复句中经常会出现一词多意的现象,多义词的使用非常普遍[1]。但在特定的语境中,根据特定上下文,多义词的义项是确定的。如“卖”为动词词性具有三个词义,分别表示“交易”“背叛”“卖弄”,虽然使用频率最高的是“交易”的意思,但“倚老卖老”根据上下文语境判断恰巧是“卖弄”的意思。据数据统计,虽然汉语语言中多义词词语的数量不算太多,但使用的频率非常高。如“感受”有两个表示义项,可以表示为“感受”,也可以表示为“感知”。
近些年,随着义项词语知识库和语料库语言学的兴起,基于高质量的统计词义消歧的方法和技术受到了广泛关注。中科院算机所的鲁松、白硕[2]等提出基于向量空间模型中义项词语的无导词义消歧方法。杨陟卓、黄河燕等提出了基于词语距离的网络图词义消歧方法[3],该方法改进了传统网络模型,将距离信息添加入网络模型中,取得了较好的效果。北京信息科技大学的张仰森提出了基于最大熵模型的汉语词义消歧与标注方法[4],该方法从特征类型、窗口大小以及是否考虑位置特征三个方面设计特征模板,依据特征模板获取模型参数文件,进而进行词义消歧。电子工程学院的李永亮、黄曙光等结合PageRank算法与知网知识库进行词义消歧,提出基于PageRank算法和知网的词义消歧方法[5]。范冬梅提出基于信息增益改进贝叶斯模型的汉语词义消歧方法[6]。本文采用最大熵模型进行训练,设计了依存句法模板,并提出了5种复合模板,实验证明,提高了词义消歧的性能。
2 最大熵模型(ME)简述
假设y为某个事件,x是y事件发生的上下文(周围环境),那么x与y的联合概率记作p(x|y)。最大熵模型可分为条件最大熵模型和联合最大熵模型两种,一般情况下,将所有可能发生的事件组成记作集合Y,将所有环境组成记作集合X,若对于任意给定的 x∈X ,y∈Y ,要求求解概率p(x|y),则需建立联合模型;若在x发生的条件下,要求求解y发生的概率,即概率p(x|y),则需建立条件模型。对于词义消歧问题的解决,需在上下文特定的语境中计算中心词各义项发生的概率,因此,需建立条件最大熵模型。
2.1 最大熵模型词义消歧的思想
最大熵模型的基本原理强调,建立与训练集统一的模型,对未知情况不做任何主观假设,在以已知上下文作为约束条件下,求解最优的概率分布。
在汉语词义消歧中,设Y为中心词(多义词)所有可能义项的一个有限集合,X是其上下文语境信息构成的集合,则把确定某个中心词的某一个义项y∈Y看为一个事件,中心词周围语境出现的词其词性看为事件发生的上下文x∈X。建立条件最大熵模型的出发点就是计算在x发生的条件下中心词某个义项y的概率p(x|y),并选择Y集合中概率值p(x|y)相比最大的一个义项作为该中心词的确定含义。
假设给定一组样本集合为{(x1,y1),(x2,y2),…,(xn,yn)},其中 xi(1≤i≤n)表示中心词语境周围的上下文,yi(1≤i≤n),表示进入最大熵模型求解概率值的候选义项依据最大熵基本原理,以经验概率分布的方式来描述样本,以指数形式计算p(x|y)条件概率:
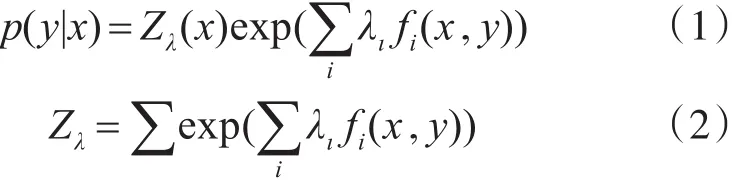
其中,Zx为归一化因子;f(x,y)为模型的特征函数,包含了中心词周围所有的信息特征函数定义为

λι为参数,表征 f(x,y)的重要性,用GIS算法进行估算。
依据最大熵的基本原理,在词义消歧中,使式(3)取得最大值所对应的义项y′就是中心词在上下文语境中的确切含义,y′可通过式(4)计算出来:
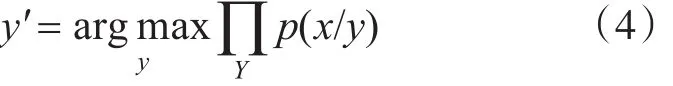
2.2 特征模板的设计
对于最大熵模型,窗口大小和特征模板的设计是影响词义消歧准确率的两个重要因素[10],首先,使用区分度高的特征模板才能准确地区分中心词的不同义项,其次,控制窗口的大小,减低维度有助于减低计算复杂度和数据的稀疏。
最大熵模型解决词义消歧的问题,一个关键步骤就是特征模板的设计[8],是建模成功的关键。对于特征模板特征的选择从如下三个方面进行考虑:
1)词形及词性特征模板
汉语多义词中有些是由于词性不同导致的多义,例如“代表”有两个义项“{expression|表示}”和“{model|典型}”,这两个义项的词性不同,前者为动词后者为名词,此类多义词根据词性则可判别确切含义。
本文用P表示上下文中词语标注的词性信息,即P-m,P-(m-1)…P-1,P0,P1…Pk,P-a,Pa分别表示中心词左边第a个词语和中心词右边第a个词语的词性;P0表示中心词的词性。词性原子模板如表1所示。

表1 中心词上下文词形及词性模板
2)词间距离特征模板
上下文中各词语与中心词间的距离,能够从某方面表示上下文词语对中心词义项确定的关联度。与中心词语距离较远的部分词语可能对中心词语义项的确定作用很小,反之,距离中心词语距离近的词语对中心词语义项的确定作用可能较大,距离越近越容易做出正确的判断。例如“今天/n他/r愿意/v被/p辅导/v学习/n。”句子中的“学习”是多义词,而句子上下文词汇中的{“今天”“他”“愿意”“被”}对中心词语义项的确定作用几乎为零,因此,引入距离模板非常有必要。距离模板如表2所示。

表2 距离模板
3)依存句法特征模板
依存句法是由法国语言学家特斯尼耶尔(L.Teseniere)最先提出的[7],能够通过句子上下文词语与词语之间的关联关系来表明句子的语言结构。构成句子的各词语之间存在着某种联系,这些联系把句子从线性序列构造成结构化的依存关系树,依存弧上的标注信息反映出句中各词语之间的依存关系,把多义词词义的确定从词语表层的分析,深入到句子语境的内部结构中去。句子中各词汇之间的关联关系,为多义词的语义消歧过程提供了更多依据。
依存句法的引入让多义词义项的确定不只依赖于词语的物理位置,借助依存关系树,能够得到句子内各词语之间的语义修饰关系,从而取得较长距离的词语关联信息,进而降低忽略特征对多义词义项确定的影响。举例来说,“这次机会,还是没有能把握好。”对其进行依存句法分析,并画出其依存关系树,如图1所示。
首先确定句中的多义词是“把握”,仅仅依据词性模板和间距模板得到的特征向量为<PW(-3)=还是/c,PW(-2)=没有/d,PW(-1)=能/v,PW(0)=把握/v,PW(1)=好/a,PW(2)=Null,PW(3)=Null>,根据词性模板和间距模板“机会”对多义词“把握”的义项确定作用几乎为零,但在上下文语境及句子结构中,通过依存句法分析,它们实际是有联系的。依存句法模板能够有效地解决这一问题,使与多义词有关联的词语的选择,不仅局限于词性与位置的词语表层分析,使其更加深入至句子结构中。依存句法特征模板如表3所示。
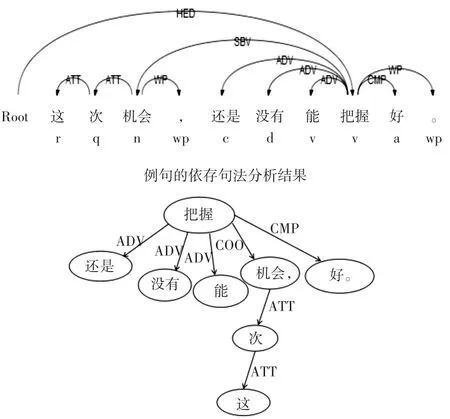
图1 例句各成分间的依存关系数树

表3 依存句法模板
表中模板12比较特殊,它表示此义项在某个模板下是否为中心词确定语义,取值为集合{YES,NO},任何一模板必须包含模板12。
4)复合模板
显然,单纯依靠原子模板解决词义消歧的问题显得太过简单,准确识别的有效性过低,不能充分刻画多义词与上下文中各词语之间的修饰依赖关系,且准确率不理想。考虑以上3个方面的原子模板,并结合对大量语料的观察,最终构成了5个复合模板,目的在于提高义项判别准确率,提高有效性。复合模板如下:
(1)多义词左右各三个词形及词性
PW(-3),PW(-2),PW(-1),PW(1),PW(2),PW(3)
(2)多义词左右各三个词形及词性+词间距离
PW(-3),PW(-2),PW(-1),PW(1),PW(2),PW(3),Dis
(3)多义词左右各三个词形及词性+依存模板
PW(-3),PW(-2),PW(-1),PW(1),PW(2),PW(3),PathParent,PathChild
(4)多义词左右各三个词形及词性+依存模板+词间距离
PW(-3),PW(-2),PW(-1),PW(1),PW(2),PW(3),PathParent,PathChild,Dis
(5)多义词左右各三个词形及词性+依存模板+词间距离+间隔多义词的个数
PW(-3),PW(-2),PW(-1),PW(1),PW(2),PW(3),PathParent,PathChild,Dis,N
依据如上构造的5个模板,结合训练语料,通过机器学习生成模型参数文件,依据模型参数文件进而确定多义词的确定义项。
3 基于依存句法与最大熵模型的复句词义消歧过程的实现
基于依存句法与最大熵模型词义消歧的过程,包括机器学习和词义消歧两个模块。采用如下步骤:
Step 1:
通过训练集进行机器学习,根据特征模板训练参数,产生模型参数文件
Step 2:
利用复句分析系统,对句子进行分句、分词和词性标注
Step 3:
判断词语是否为多义词,这里将分两路对词语进行处理:若待消歧的词为多义词,进行Step 4;若待消歧的词为单义词,则利用语义词典直接为该词标注
Step 4:
依据机器学习产生的模型参数文件,对Step 3判断出的多义词进行两路处理:该多义词若在训练集学习产生的参数文件中只有“词形+词性”一种情况,则直接根据词形对该词进行消歧;反之,则用最大熵模型对该词进行消歧。
Step 5:
依据Step 3产生的单义词标注于Step 4产生的多义词消歧输出带词义标记的消歧后文本。

图2 最大熵语义消歧的实现流程
4 实验结果及分析
4.1 实验数据及测评指标
语料集的选择必然面临着数据稀疏的问题,为了避开这一问题,选取汉语中多义词使用频率较高的常用词汇进行实验。本实验的语料数据选自华中师范大学的“汉语复句语料库”(CCCS)。从CCCS语料库65万余条复句中随机抽取含有多义词常用词汇的3000条复句,并以5∶1的比例进行随机抽取,2500条进行人工语义标注,构建成训练集,用于机器学习产生模型参数文件,剩余的500条作为测试集。
本文词义消歧的实验数据评测标准采用经典的三方面测评指标,包括:查全率R(Recall)、查准率P(Precision)和F-score[9]。其分别定义如下:
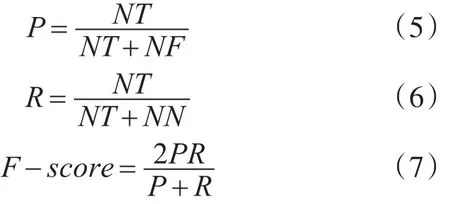
其中,NT表示正确实现词义消歧的歧义词个数;NF表示歧义词词义确定错误的歧义词个数;NN表示未进行词义消歧操作的歧义词个数;NT+NF表示所有进行消歧的歧义词数量;NT+NN表示所有未出现消歧错误的歧义词数量。
4.2 实验结果及分析
首先,为了发现加入依存语法模板对词义消歧的影响,本文对引入依存语法模板的最大熵模型和未引入依存语法模板的最大熵模型实验结果进行比较,然后,为了对比基于依存语法的最大熵模型与其他方法词义消歧的有效性,将基于依存语法的最大熵模型的性能与其他方法进行对比。本文采用经典的F-score分析方法性能。
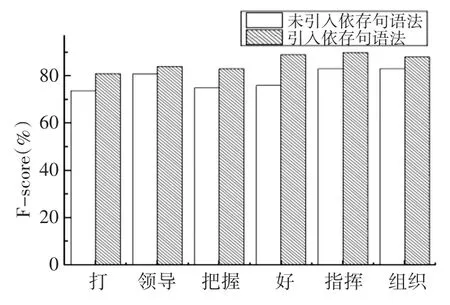
图3 基于是否引入依存语法模板的最大熵模型词义消歧结果对比
由图3可以看出,引入依存句法模板,提高了上下文词汇选择的准确性,从而正确率得到提高,可以看出引入依存句法模板的最大熵模型正确率比引入之前均有所提高,由此可见,引入依存句法模板能够得到较好的消歧效果。
实验数据结果中,多义词消歧的正确率不等可能受到实验过程中以下三个因素的影响:
1)多义词的义项数。实验数据中“打”的消歧正确率相比最低,原因可能是“打”有28个义项,多义词义项越多,一方面,词义的分类越细,区别越小;另一方面,义项越多,会提高计算复杂度,故降低正确率。
2)多义词上下文关联词汇个数。关联的词汇个数太少,词义消歧的依据太少,消歧的正确率越低。
3)训练集的语料。训练集的语料有局限性,训练集规模偏小,产生的规模参数文件有局限性,影响消歧的正确率。
对于该模型与其他方法的比较,现将测试集分成5组进行实验,该模型方法方法与基于贝叶斯模型、基于知网和隐马尔科夫方法进行对比,结果如图4所示。
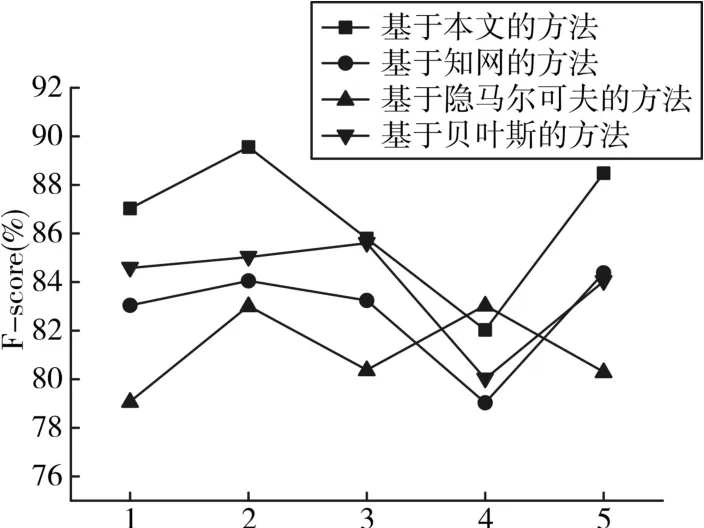
图4 4种方法词义消歧F-score比较
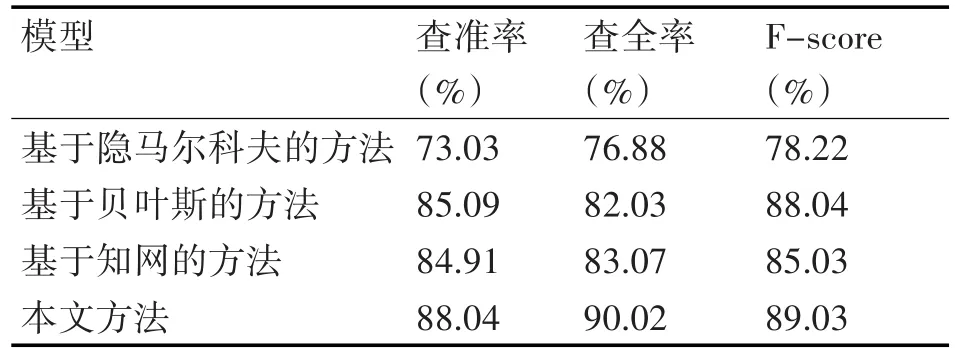
表4 4种方法的平均结果比较
从F-score来看,本文提出的基于依存句法的最大熵模型方法的性能要优于基于贝叶斯模型、基于知网和隐马尔科夫的三种方法,从平均结果来看,本文方法在查全率与F-score上比其他3种方法略高,从这表明本文提出的基于依存句法的最大熵模型进行词义消歧的思路方法是可行的。
5 结语
本文基于最大熵模型的原理结合依存句法构建了一个词义消歧模型,提出了5种复合特征模板,实验表明,该方法提高了词义消歧的正确率,达到了提高消歧准确度的效果。
