基于深度降噪自编码网络的监测数据修复方法
2018-02-07陈海燕杜婧涵张魏宁
陈海燕, 杜婧涵, 张魏宁
(1. 南京航空航天大学计算机科学与技术学院, 江苏 南京 211106; 2. 软件新技术与产业化协同创新中心, 江苏 南京 211106)
0 引 言
随着物联网技术的快速发展,大规模远程监测被广泛地应用于各行各业。各种监测系统一般由大量传感器节点所构成,能够完成实时数据的采集并将数据传送到终端。由于硬件设备自身的局限,监测点失效或数据采集错误的现象时有发生,导致无法获取某区域的真实数据。因此,在监测点失效期间,如何通过软件的方法对监测数据进行修复(填补、补全)成为一个值得关注的问题[1]。
近年来,国内外学者们对监测数据修复(填补、补全)的研究不断深入,取得了一些可以借鉴的成果。文献[2]针对历史质量数据集中缺失数据对软件质量评估的影响,提出了基于灰色关系分析的K最近邻(K-nearest neighbor,KNN)数据补全算法。通过灰色关系分析寻找KNN的最优参数,缓解了KNN对K值敏感的问题,进而提高了软件质量评估精度;然而由于欧氏距离度量方式的局限性,补全算法的稳定性还有待提高。文献[3]通过构建一种基于属性的决策图,进而建立基于属性重要度的数据补全模型。在将分类问题作为评估标准的标准数据集中,该补全模型效果较好;由于该方法对数据质量要求较高,在含噪声较多的实际应用场景中无法达到令人满意的补全效果。文献[4]基于多维度相似性并考虑顺序敏感的填补情况,提出了面向多元感知数据且顺序敏感的缺失值填补框架,较好地解决了在缺失数据较为密集的情况下填补准确性难以保证的情况。文献[5]提出利用高斯混合模型和极限学习机预测模型,设计一种缺失数据多重填补方式的策略。在多个标准数据集中都对缺失数据取得了较好的预测精度。文献[6]提出基于支持向量机的缺失数据插补算法,利用周围监测点数据预测缺失数据。预测模型较好地解决了无线传感器网络中传感器节点数据收集过程中存在的缺失问题;然而该方法在待修复数据与有效数据之间存在高度相关关系时,才具有较好的预测精度。文献[7]提出联合使用模糊C均值和支持向量回归预测模型。该混合预测模型在多个标准数据集中对缺失数据达到了合理的估算,较传统的模糊C均值预测模型和支持向量回归模型,混合模型具有更好的稳定性。也有部分方法是结合相似性度量和回归预测模型来进行数据修复的。文献[8]提出基于KNN的支持向量机回归预测模型用于无线传感器网路中的数据异常检测和补全,先通过KNN筛选相似度高的有效数据,根据有效数据建立回归预测模型进而对异常数据进行补全。文献[9]提出基于动态时间规整(dynamic time warping,DTW)相似性度量回归预测模型,用于滚动轴承的寿命预测。通过DTW算法提取不同健康状态下的曲线相似度,根据曲线相似度建立支持向量回归(support vector regression,SVR)预测模型进而对轴承异常状态的发现和预测。
由于在监测数据修复这一问题中,被挖掘的数据都是实时监测数据,往往含有大量的噪声值,因此,对所采用的方法提出了更高的要求。深度学习近年来成为机器学习领域的研究热点[10-12],其理论被应用于解决各种数据挖掘问题。考虑到深度学习在特征提取方面表现出的优势以及提取相关信息对于数据修复的重要性,本文基于深度学习的思想,利用深度降噪自编码(deep denoising auto-encoder, DDAE)网络来挖掘数据间隐含的深层相关信息。这种相关信息一方面具有较少的冗余信息,另一方面能够很好地反映数据间本征相关性。基于深层相关信息并结合SVR预测算法,提出一种基于DDAE网络的异常监测点数据修复方法。
1 基于DDAE的关联监测点隐层特征提取
1.1 降噪自编码网络原理
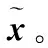
(1)
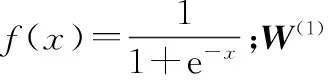
(2)
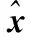
(3)
式中,hW,b(·)为输入数据的重构函数。
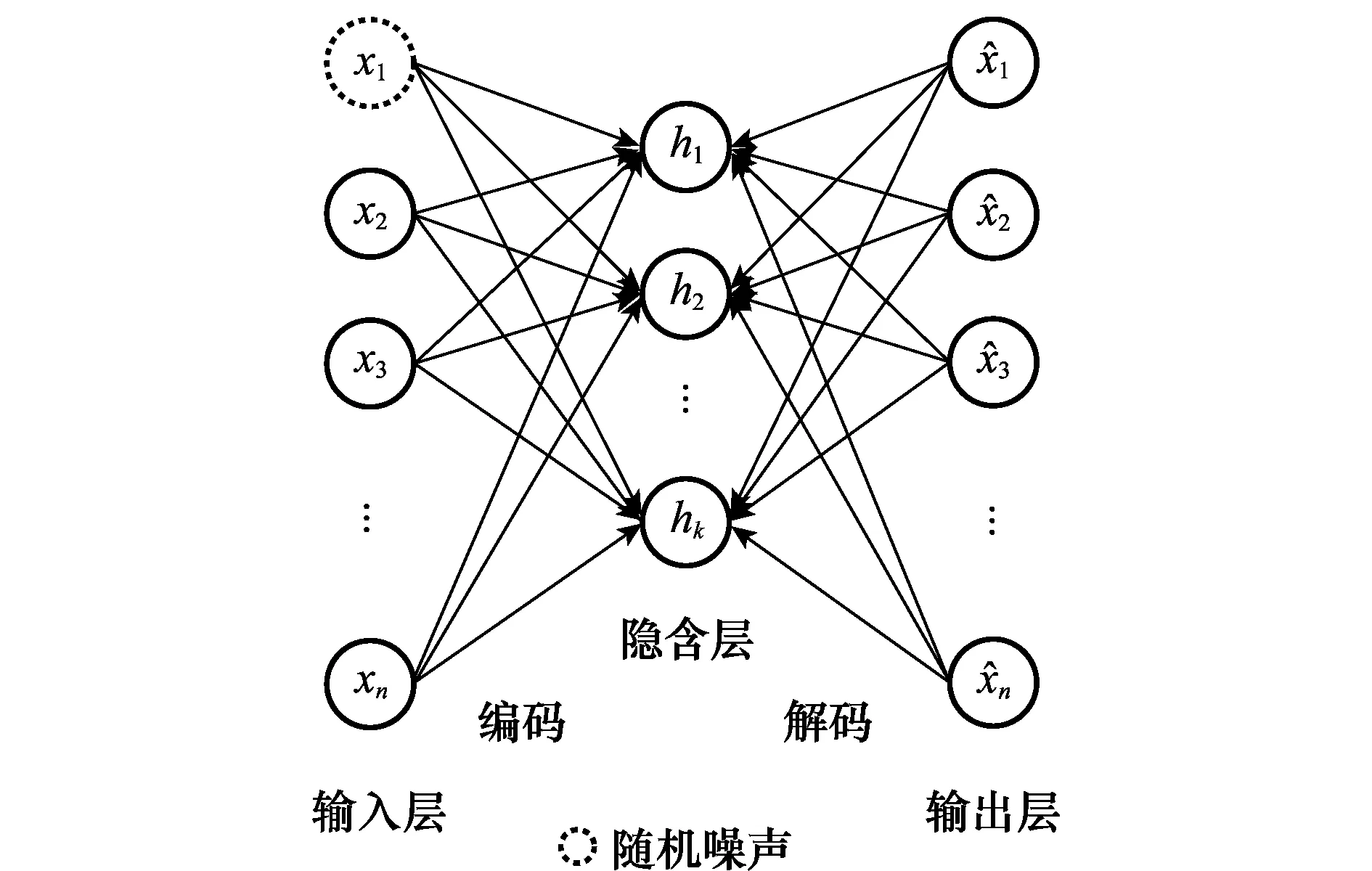
图1 DAE网络结构Fig.1 Structure of DAE network
对于一个含有m个样本的样本集{x1,x2,…,xm},为了使输出结果尽可能重构输入数据,DAE的目标函数可表示为
(4)
为进一步降低过拟合的风险并提高网络的泛化性,对DAE的学习参数设置了L2正则化约束,目标函数可进一步改写为
(5)
式中,θ={W,b};W是所有连接相邻两层的权重;b是各层的偏置项;λ则用于度量数据重构程度和正则化约束之间的权重。
1.2 DDAE网络的构造及训练
DDAE网络[15]是由多个自编码网络或其变形网络堆叠而成的深度神经网络,采用上述DAE作为基本结构单元构造了DDAE网络,网络结构如图2所示,其中,输入层和输出层的节点个数为数据的维数,最中间的隐含层节点个数通过本征维数估计[16]的方法来确定。
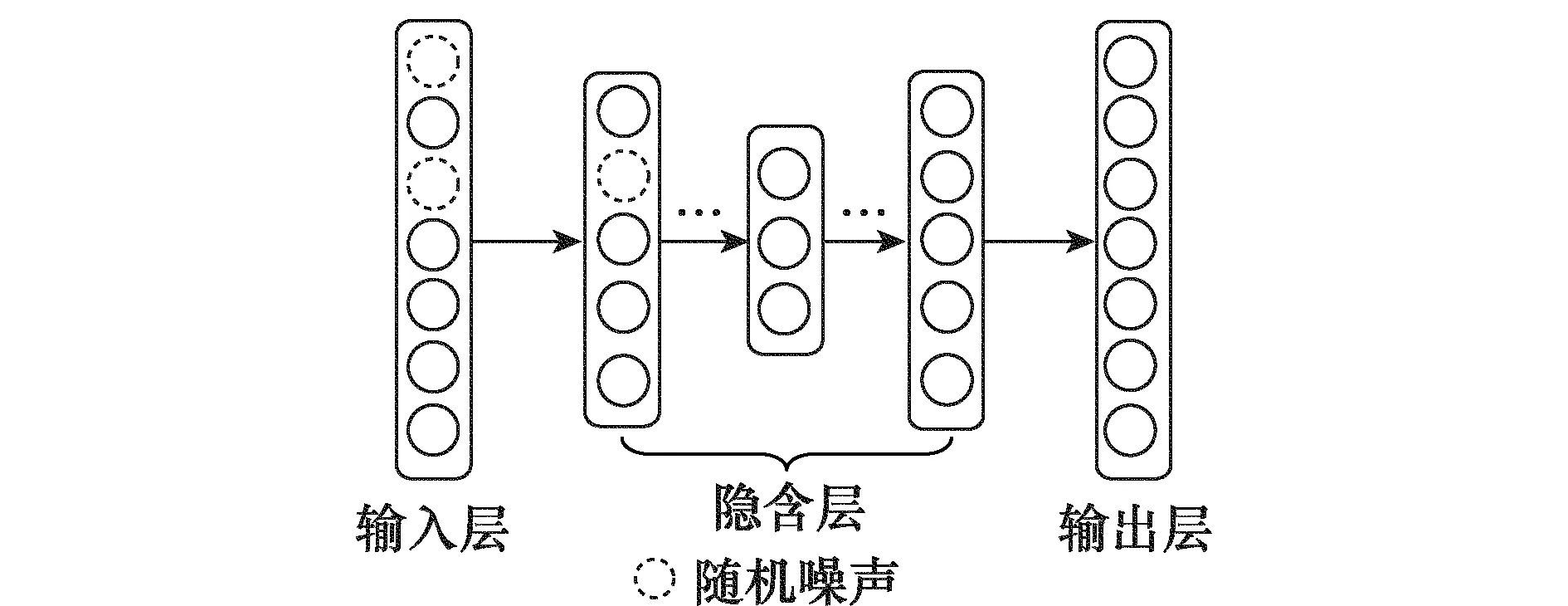
图2 DDAE网络结构Fig.2 Structure of DDAE network
DDAE网络在输出层重构输入数据,在隐含层学到输入数据的压缩表示。深度学习理论认为这种压缩表示通过学习获得的可表征样本集深层特征的新的表达形式。这种表达形式一方面具有较少的冗余信息,另一方面能够有效地反映输入数据的特性。用压缩表示作为新的特征向量代替原始特征向量输入到回归模型中,在很多任务中可以大大提高预测模型的准确度和鲁棒性[17-18]。
一般地,一个DDAE网络的训练过程分为逐层训练和微调两个步骤进行。
(1) 逐层训练
初始化整个网络参数W和b为服从标准正态分布的随机值,采用贪婪算法来逐层训练网络。即先利用输入数据训练DDAE网络的第一层,生成第一层网络的参数W(1)和b(1);然后将第一层的输出作为第二层的输入,继续训练得到第二层的参数W(2)和b(2);最后对后面各层采用同样的策略,即将前层的输出作为下一层输入的方式依次训练。对于上述训练方式,在训练每一层参数的时候,会固定其他各层参数保持不变。为了学习到更加鲁棒的特征,逐层训练时每一层的输入都需要加入噪声,即以一定的概率将神经元的取值重置为0。
(2) 微调
通过反向传播算法调整DDAE网络的参数,即利用梯度下降法迭代更新权重,更新过程可表示为
(6)
式中,α为学习速率。当目标函数达到一定阈值即完成微调整个网络过程。
1.3 深度降噪自编码网络性能分析
从首都机场15个机场噪声监测点的监测数据中随机选取了1 000条监测数据作为网络的训练集,152条作为网络的测试集。考虑到实际数据规模以及自编码网络的表达能力,为了对比不同自编码网络在重构数据性能上的差异,本文设置了3种自编码网络,分别是传统的DAE网络(15-6-15,简称DAE)、5层DDAE网络(15-10-6-10-15,简称DDAE-5)和7层DDAE网络(15-11-9-6-9-11-15,简称DDAE-7)。利用第1.2节提到的训练方式,训练上述3种自编码网络。为了分析自编码网络重构数据的效果,实验对比了不同自编码网络的重构数据与训练数据的相对误差,结果如图3所示。
从图3中可以看出,DDAE-5网络重构数据的效果最好,重构误差大都在5%以内。值得一提的是,DDAE-7网络没有取得很好的重构效果,这可能由于训练数据规模相比于网络复杂度而言过小,网络参数没有得到充分有效的学习。而传统DAE网络的重构效果介于DDAE-5和DDAE-7之间。
为了检验上述3种自编码网络的泛化能力,在未参与训练的测试集中对比了3种网络的学习效果,其重构误差如图4所示。通过对比可以看出,DDAE-5在测试集中的泛化性能最好,这说明该网络学到的隐层特征可以较好地表征输入数据。同样地,对于DDAE-7来说,由于在训练阶段网络没有得到充分的学习,导致没有挖掘到适合输入数据的特征表示,从而使得该网络在测试集中的泛化性能最差。

图3 不同自编码网络的训练集重构误差Fig.3 Reconstruction error in training set for different AE network
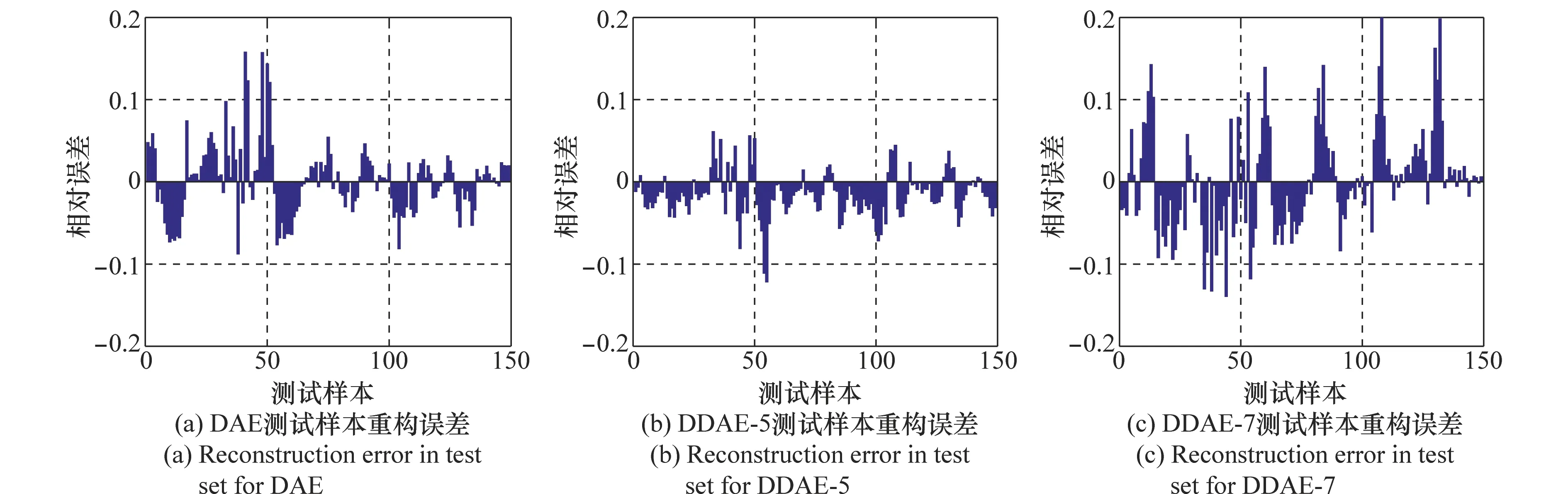
图4 不同自编码网络的测试集重构误差Fig.4 Reconstruction error in test set for different AE network
进一步,选取误差平方和(sum of squares for error,SSE)作为数据重构效果好坏的定量评价指标。3种自编码网络在训练集和测试集的SSE结果如表1所示。明显地,DDAE-5在训练集和测试集的SSE均取得了最小值,也进一步说明DDAE-5的隐层特征提取结果最好,能够在一定程度上代替原始输入数据。
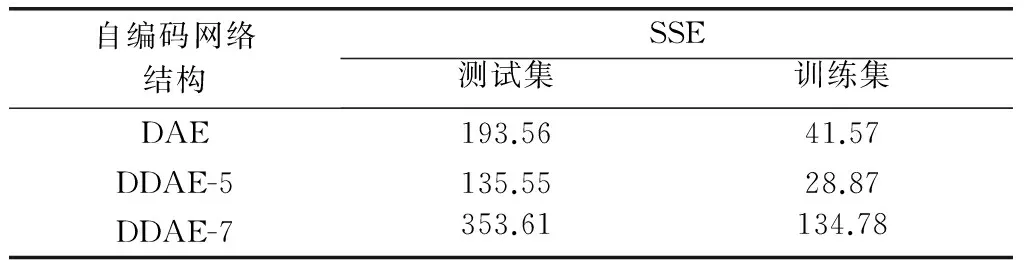
表1 不同自编码网络的SSE
2 基于深度降噪自编码网络的数据修复模型
结合DDAE网络的隐层特征提取方法及SVR预测算法,提出了一种新的数据修复模型,利用基于DDAE网络的SVR预测(简称DDAE_SVR)算法,将预测值作为异常数据修复的结果,DDAE_SVR算法主要步骤如下。
步骤1给定样本个数为ntr训练样本集Tr={(x1,y1),(x2,y2),…,(xntr,yntr)}和样本个数为nte测试样本集Te={(x1,y1),(x2,y2),…,(xnte,ynte)},并设置候选DDAE网络层数M={m1,m2,…,mk}。
步骤2从M中选择一个mi模型,并初始化DDAE网络权重θmi={W,b}~N(0,1)。
步骤3对训练数据xtr={x1,x2,…,xntr}采用贪婪算法逐层训练DDAE网络参数θ(j)(j=1,2,…,mi),利用梯度下降法根据损失函数的梯度值迭代更新权重,得到学习后的参数值θmi。
步骤4对测试数据xte={x1,x2,…,xnte}根据式(4)计算mi模型的数据重构误差Rmi。
步骤5令M=M{mi},如果M=∅跳转到步骤6,否则跳转到步骤2。
步骤6从Rmi(i=1,2,…,k)中选取值最小的模型mmin。分别提取xtr和xte在mmin模型中的隐含深度特征dtr和dte。
步骤7利用ε-SVR回归预测算法对(dtr,ytr)进行训练并得到回归预测模型。
步骤8根据步骤7学习到的回归预测模型,利用测试数据的隐含深度特征dte预测yte。
3 实验与评价
利用第1.3节提到的机场噪声监测数据,并根据上述建立的基于DDAE网络的数据修复模型,进行了监测数据的预测实验。由于该方法属于结合相关关系和回归预测模型的数据修复方法,为了对比回归预测效果,设置了4组实验。其中,基于皮尔逊系数的回归预测(简称CORR_SVR)模型是此类方法的基本模型,基于DTW相似性度量[19]的回归预测(简称DTW_SVR)模型是该类方法中适用范围最广预测效果最好的模型。同时,为了对比深度网络对回归预测效果的影响,设置了基于DAE网络的回归预测(简称DAE_SVR)以及基于DDAE网络的回归预测(简称DDAE_SVR)两种模型。其中DAE网络和DDAE网络采取第1.3节训练好的DAE网络和DDAE-5网络。4种模型在测试集上的预测结果如图5所示。
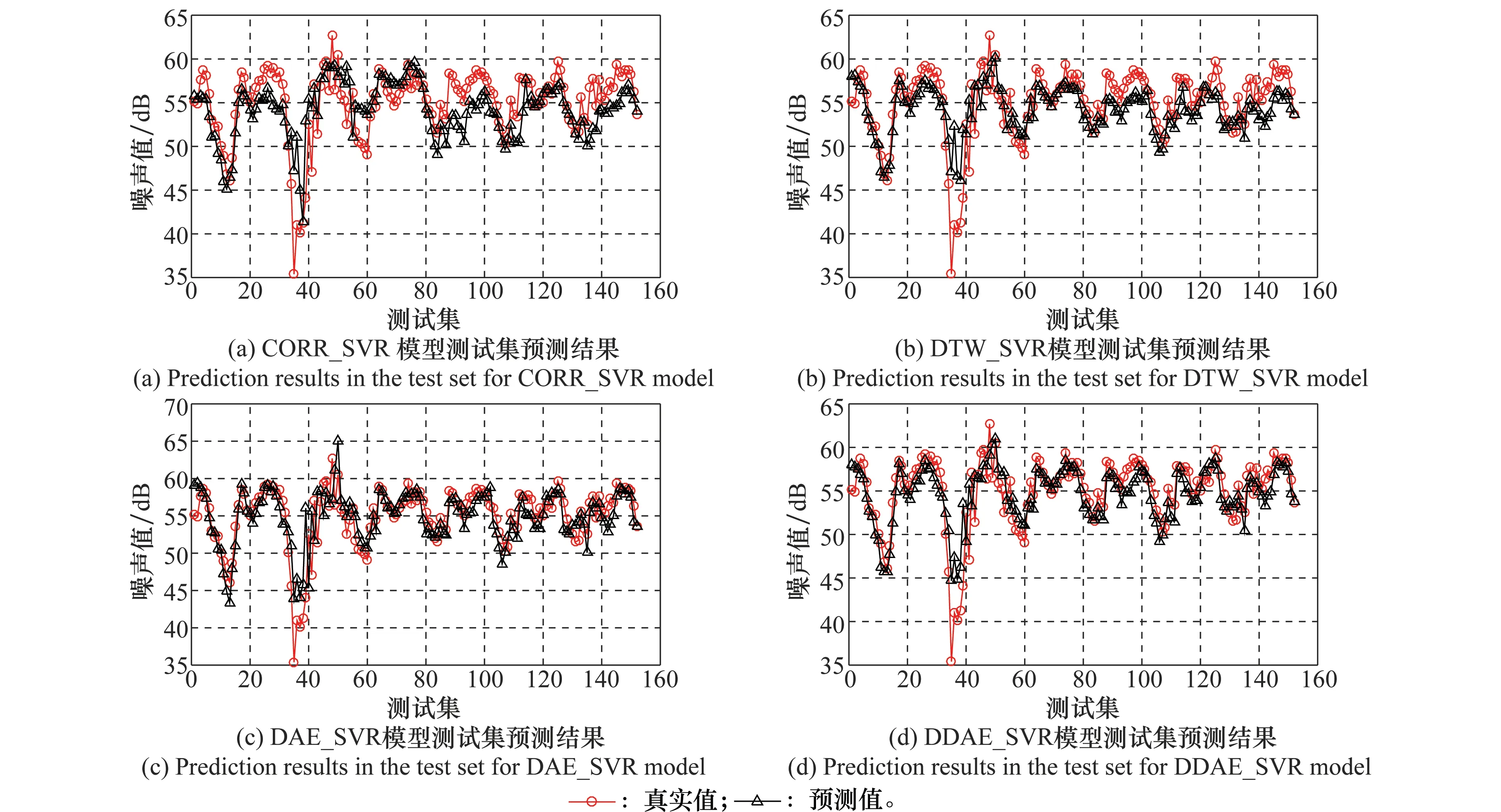
图5 各模型在测试集中的噪声预测结果Fig.5 Prediction results in the test set for different models
根据实验结果分析,使用DTW相似性度量方法比使用皮尔逊相似性度量方法的预测结果更精确,这说明了DTW相似性度量方法的优越性。对比传统相似性度量方法,本文提出的DDAE_SVR模型在整体的预测趋势来看,更好地捕获了测试集的变化趋势;在对峰值的预测情况来看,使用DDAE_SVR模型的预测结果更为理想。对比上述4个实验结果,一定程度上说明了基于DDAE网络提取到的隐层特征能够较好地代表原始数据进行回归预测,同时也体现了隐层特征具有较好的抗噪性和鲁棒性。
表2显示了4个模型在测试阶段的表现能力,评价指标有均方误差和决定系数。均方误差(mean squared error,MSE)直接反应了预测结果的好坏程度。决定系数(squared correlation coefficient,SCC)是相关系数的平方,反映了列入模型的所有解释变量对因变量的联合的影响程度,表征模型的拟合优度,取值范围在0~1,值越接近于1,表明拟合模型的参考价值越高;相反越接近0,表明参考价值越低。通过定量的对比发现,本文提出的DDAE_SVR模型相比传统的回归预测模型更好,较DTW_SVR模型在MSE和SCC评价指标上分别提高了25.1%和11.4%。
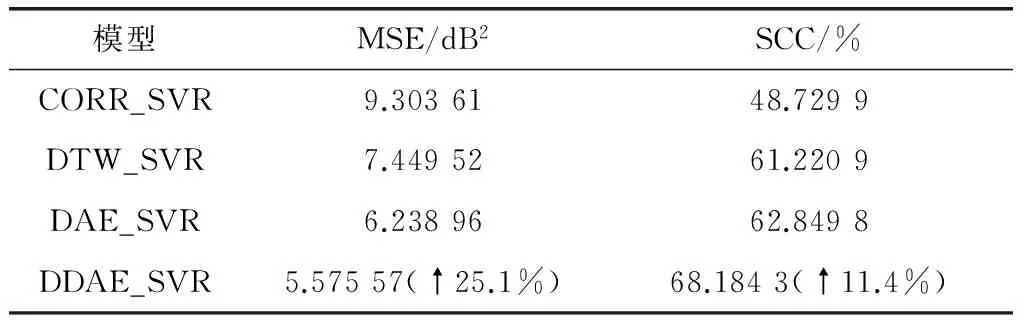
表2 测试集中的性能指标
对于DDAE_SVR模型,分别可视化了测试集中的预测误差和相对误差。如图6所示,测试数据的预测误差大部分都在2 dB左右,误差控制在5%以内,这较好地符合当前对机场噪声预测的要求,也进一步表明了本文提出的基于DDAE网络的SVR预测算法在预测精度上的优越性。
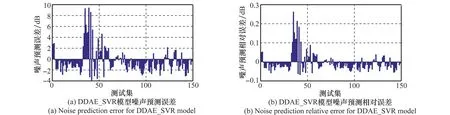
图6 DDAE_SVR模型误差分析Fig.6 Error analysis for DDAE_SVR model
考虑到模型在实际应用场景中噪声较多的情况,为了验证模型对噪声的鲁棒性,针对不同噪声水平进行了对比实验。通过对测试阶段的输入数据增加不同程度的高斯噪声,获得含不同噪声水平下DDAE_SVR模型的MSE情况。如图7所示,相比不含噪声的DDAE_SVR预测模型的测试结果,在噪声程度较小时,该模型的MSE仅有少量增加,模型具有较好的抗噪能力;当噪声程度较大时,尽管MSE有一定程度的增加,但相比较其他模型仍具有较小的MSE。对比实验结果表明,本文提出的DDAE_SVR模型具有一定的鲁棒性和抗噪能力。
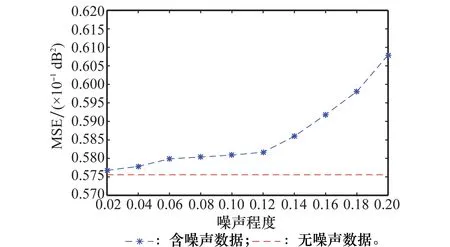
图7 DDAE_SVR模型鲁棒性分析Fig.7 Robustness analysis for DDAE_SVR model
4 结 论
针对物联网实时监测数据的异常修复问题,提出了一种基于深度降噪自编码网络和支持向量回归算法的异常监测数据修复方法。该方法通过重构输入数据和学习输入数据的压缩表示,获得样本集深层特征的新表达形式,不仅充分反映了输入数据的特性,还极大地减少了相关信息之间存在的冗余。比较了3种不同深度的自编码网络在重构数据上的性能差异。在实测的首都机场噪声监测数据集上进行的实验表明,所提出的基于深度降噪自编码网络的异常监测数据修复方法具有较好的抗噪性和鲁棒性,能有效提高异常数据的预测精度。
本文所提出的方法主要针对物联网中单监测点失效或少量监测数据缺失而需修复的场景。对于多监测点同时失效而导致的大面积数据缺失问题,由于关联数据的缺失,可能无法较好地提取数据的隐含特征,进而使得预测数据准确率不高。该问题将作为未来的研究内容之一。
[1] BARALDI A N, ENDERS C K. An introduction to modern missing data analyses[J]. Journal of School Psychology, 2010, 48(1): 5-37.
[2] HUANG J, SUN H. Grey relational analysis basedknearest neighbor missing data imputation for software quality datasets[C]∥Proc.of the IEEE International Conference on Software Quality, Reliability and Security, 2016: 86-91.
[3] BERTINI J R, DO CARMO NICOLETTI M, ZHAO L. Imputation of missing data supported by complete p-partite attribute-based decision graphs[C]∥Proc.of the IEEE International Joint Conference on Neural Networks, 2014: 1100-1106.
[4] 马茜,谷峪,李芳芳,等.顺序敏感的多源感知数据填补技术[J]. 软件学报, 2016, 27(9): 2332-2347.
MA Q, GU Y, LI F F, et al. Order-sensitive missing value imputation technology for multi-source sensory data[J]. Journal of Software, 2016, 27(9): 2332-2347.
[5] SOVILJ D, EIROLA E, MICHE Y, et al. Extreme learning machine for missing data using multiple imputations[J]. Neurocomputing, 2016, 174(PA): 220-231.
[6] GAO S, TANG Y, QU X. LSSVM based missing data imputation in nuclear power plants environmental radiation monitor sensor network[C]∥Proc.of the 5th IEEE International Conference on Advanced Computational Intelligence, 2012: 479-484.
[7] AYDILEK I B, ARSLAN A. A hybrid method for imputation of missing values using optimized fuzzy C-means with support vector regression and a genetic algorithm[J]. Information Sciences, 2013, 233(4): 25-35.
[8] XU S, HU C, WANG L, et al. Support vector machines based on K nearest neighbor algorithm for outlier detection in WSNs[C]∥Proc.of the 8th IEEE International Conference on Wireless Communications, Networking and Mobile Computing, 2012: 1-4.
[9] ZHANG L, LU C, TAO L. Curve similarity recognition based rolling bearing degradation state estimation and lifetime prediction[J]. Journal of Vibroengineering, 2016, 18(5):2089.
[10] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[11] SUK H I, LEE S W, SHEN D, et al. Latent feature representation with stacked auto-encoder for AD/MCI diagnosis[J]. Brain Structure and Function, 2015, 220(2): 841-859.
[12] 刘扬, 付征叶, 郑逢斌. 基于神经认知计算模型的高分辨率遥感图像场景分类[J]. 系统工程与电子技术, 2015, 37(11): 2623-2633.
LIU Y, FU Z Y, ZHENG F B. Scene classification of high-resolution remote sensing image based on multimedia neural cognitive computing[J]. Systems Engineering and Electronics, 2015, 37(11): 2623-2633.
[13] WILLIAMS D, HINTON G E. Learning representtations by back-propagating errors[J].Nature,1986,323(6088):533-536.
[14] VINCENT P, LAROCHELLE H, BENGIO Y, et al. Extracting and composing robust features with denoising autoencoders[C]∥Proc.of the 25th ACM International Conference on Machine Learning, 2008: 1096-1103.
[15] VINCENT P, LAROCHELLE H, LAJOIE I, et al. Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research, 2010, 11(12): 3371-3408.
[16] CAMASTRA F. Data dimensionality estimation methods: a survey[J]. Pattern Recognition, 2003, 36(12): 2945-2954.
[17] GEHRING J, MIAO Y, METZE F, et al. Extracting deep bottleneck features using stacked auto-encoders[C]∥Proc.of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2013: 3377-3381.
[18] RIFAI S, VINCENT P, MULLER X, et al. Contractive auto-encoders: explicit invariance during feature extraction[C]∥Proc.of the 28th International Conference on Machine Learning, 2011: 833-840.
[19] BERNDT D J, CLIFFORD J. Using dynamic time warping to find patterns in time series[J]. KDD Workshop,1994, 10(16): 359-370.
