基于LLE算法和SVM的心理健康预警研究
2018-01-29叶明全黄道斌
杨 利,叶明全,黄道斌
(皖南医学院公共基础学院,安徽芜湖241002)
1 引言
随着社会竞争的日益激烈,大学生群体正面临着如学业、情感、就业、生活等多重压力,心理健康问题频频发生,为避免一幕幕悲剧的发生,高校均定期对大学生心理健康进行评估,但是,目前所采用的心理健康预警系统大部分是基于传统机器学习算法,如BP(Back Propagation)神经网络[1]、决策树算法[2]等,计算量巨大且预警的准确率不高。
通过症状自评量表采集到的大学生心理健康数据通常是高维数据集,在预警的过程中,所处理的数据量是巨大的,而心理健康数据之间存在着一定的关联性,即存在着冗余数据。近年来,大量研究学者对流形学习算法展开了深入研究,该算法已作为特征提取、数据降维的有效方法并迅速发展,且在多个领域有了成功的应用,如人脸识别[3]、图像检索[4]、植物叶片识别[5-6]、文本分类[7]等。因此,本文首先通过症状自评量表获取大学生心理健康数据并进行预处理;然后采用一种非线性流形学习算法--局部线性嵌入算法(Locally linear embedding,LLE)对多维心理健康数据进行降维,提取心理健康数据主要特征;最后采用(Support Vector Machine,SVM)分类器识别提取到的心理健康数据主要特征,从而确定学生的心理健康状况。通过将本文提出的系统与目前采用BP神经网络和决策树算法的心理健康预警系统进行实验结果比较,采用LLE结合SVM的大学生心理健康预警系统能够明显提高预警的准确率。
2 局部线性嵌入(LLE)
局部线性嵌入(LLE)是一种非线性流形学习算法,该算法主要通过寻找高维数据集中所潜藏的低维流形结构来实现数据的降维,复杂度低,易于实现。
若存在高维空间的数据集X={x1,x2,…,xn}⊂RD,LLE算法对其进行降维的具体步骤为:
(a)计算数据集X中所有样本点之间的欧式距离,对与样本点xi欧式距离的其他样本点进行逆序排序,选取前K个样本点作为xi的邻域,K的取值具有很大的不确定性,需要在实验过程中调节;
(b)计算样本点xi的局部重构权值矩阵W,矩阵元素Wij与样本点xi的K邻域线性重构xi,最小化重构误差函数ε(W);
其中,
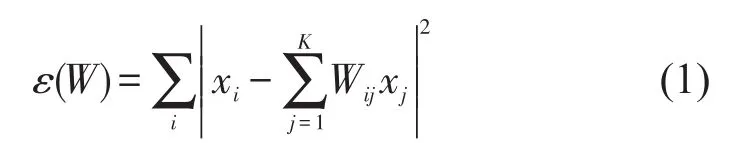
权值矩阵W的单个元素为Wij,当xj∉{xi的K邻域}时,Wij为0。Wij满足约束条件

(c)在Wij不变的前提下,计算样本点xi在低维空间的嵌入yi,最小化加权误差函数εi(W);其中,
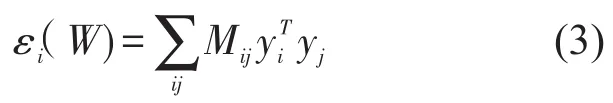
式(3)中,
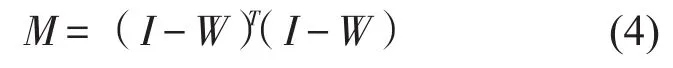
低维嵌入yi∈Rd(d≪D)且满足条件

(d)对矩阵M进行非稀疏对角化,舍去第1个为0的特征值,计算出2-(d+1)个特征值对应的特征向量,即可得到高维样本集X所对应的低维输出Y。
3 支持向量机(SVM)
3.1 支持向量机简介
支持向量机(SVM)[8]是一种分析数据、识别模式的学习模型,该模型基于统计学习相关理论,应用领域很广,特别擅长处理小样本、高维度和非线性数据。支持向量机的核心在于核函数,通过对核函数映射,将低维空间中的样本非线性转换到高维空间,选择合适的核函数,在高维空间中找寻找最优的分类超平面,支持向量机的最优分类函数为:

3.2 支持向量机的学习算法
该学习模型的学习步骤:
(1)给定支持向量机的输入数据,一组训练样本xi和yi,其中yi是训练样本xi的类别,yi∈{+1,-1},i=1,2,…,n;
(2)计算函数Q(α)的最大值,得到;该过程需要满足如下约束条件:

其中,
(3)计算出W*和b*,计算公式如下
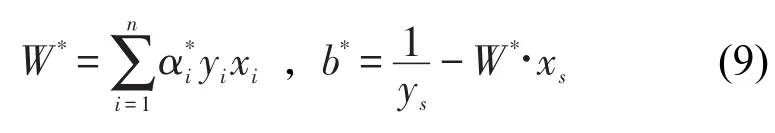
其中xs是一个特定的支持向量;
(4)选择某种核函数K(x,xi),计算测试样本x的支持向量机最优分类函数:
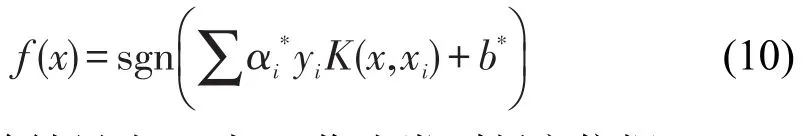
计算结果为+1或-1,作为类别判定依据。
4 基于LLE算法和SVM的心理健康预警系统
4.1 心理健康数据采集和预处理
向某学院500名学生发放症状自评量表(SCL-90),进行心理数据采集,为量化每个学生的心理状态,构建大学生的心理健康数据结构为(学号,躯体化,人际关系敏感,强迫症状,抑郁,焦虑,恐怖,敌对,偏执,精神病性,其他)。实验中,随机从这500份大学生心理健康数据中选取300份作为训练样本,剩余200份数据作为测试样本。
将采集到的每个学生心理健康数据结构表示成含有11个元素的一维列向量,因此,实验中的训练样本和测试样本均可由含有11个元素的一维列向量表示。
4.2 心理健康数据特征提取
在对大学生心理健康进行调研的过程中,调研项目越多,越能真实体现该学生的心理健康状况,但是较多的调研项目也扩充了学生心理健康数据结构,增加最终的心理健康评估计算量及评估时间。同时,采集到的心理健康数据结构中包含着冗余特征信息,为了减少计算量,本文利用LLE算法对提取到的大量学生心理健康数据进行维数约简,降低每个学生的心理健康数据维数,实现心理健康数据特征提取。
4.3 心理健康状况预警实验
本实验结合LLE和SVM对大学生心理健康数据进行预警,由于LLE算法含有近邻参数K和嵌入维数d两个参数,因此实验过程中要解决这两个参数的取值问题。若K过小,则会打破流形的全局特性;K过大,数据降维后原有的非线性特性就不存在了。若d过小,低维空间中数据可能会重叠;若d过大,会给降维后的数据集引入噪声,从而影响最终的心理健康评估结果。
实验中保持样本数据集固定不变,由于每个学生心理健康数据结构由11个元素的一维列向量组成,最大维度为11,因此可选取d的取值区间为[2,10],步长为1;近邻参数K的取值区间为[3,10],步长为1[6]。实验中,利用SVM作为分类器,其核函数为C-SVC,所涉参数具体值为degree=3,gamma=0.5,coef0=0,惩罚因子C=1。表1为不同K、d情况下大学生心理健康数据预警的准确率。
经过在实验中不断调整参数K和d,力求使得评估准确率最高,通过观察实验结果表1,最终确定K的取值为5,d的取值为8。
4.4 实验结果
利用LLE算法结合SVM方法和目前常用的心理健康预警方法BP神经网络、决策树对大学生心理健康数据进行预警,每种方法进行10次实验,每次实验所用的训练样本和测试样本都是随机选取的,大学生心理健康状况取10次实验的最佳预警准确率和平均预警准确率。表2为大学生心理健康状况预警结果。
5 结论
本文提出一种基于LLE算法和SVM的大学生心理健康预警方法,实验表明该方法可以有效提高大学生心理健康预警的准确率。实验过程中,涉及到近邻参数K和降维维数d的取值问题,本文不断调整K和d的值,使得心理健康评估准确率达到最优,综合性的选取K和d,因此本方法不具备自适应性。下一步的研究工作着重于K和d的选取,使得本文提出的预警方法具备自适应性。
[1]李春意.基于BP神经网络的大学生心理状况预测及分析[D].天津:天津大学,2012.
[2]亓文娟,晏杰.决策树算法在大学生心理健康测评系统中的应用[J].计算机系统应用,2015,24(11):230-234.
[3]Hao W,Wen Y.Face Recognition Using Spatially Smooth and Maximum Minimum Value of Manifold Preserving[J].Chinese Journal of Electronics,2013,22(1):71-75.
[4]贺广南,杨育彬.基于流形学习的图像检索算法研究[J].山东大学学报(工学版),2010,40(5):129-136.
[5]杨利,叶明全.基于S-WLLE算法和SVR的植物叶片图像识别方法[J].宿州学院学报,2014,29(11):69-74.
[6]阎庆,梁栋,张晶晶.基于Fisher变换的植物叶片图像识别监督LLE算法[J].农业机械学报,2012,43(9):179-183.
[7]夏士雄,李佑文等.一种半监督局部线性嵌入算法的文本分类方法[J].计算机应用研究,2010,27(1):64-67.
[8]张浩然,韩正之,李昌刚.支持向量机[J].计算机科学,2002,29(12):135-137.
