基于增量聚类的协流识别系统研究
2018-01-29任群
任 群
(亳州学院 电子与信息工程系,安徽 亳州 236800)
云计算中的集群计算应用需求满足各种计算需求.例如,某些应用程序对吞吐量敏感,它们必须尽快地处理每一个输入(例如,MapReduce[1]);某些应用程序是对延迟敏感的,它们可能不需要精确的答案(例如,Google或Bing的搜索结果).为了能够描述数据中心级别应用程序的通信需求,提高分布式数据并行应用程序的通信性能,协流(co-flow)这一抽象概念便出现了.与传统的数据流(例如,TCP流)相比,协流可以描述两个节点之间的流的集合,仅在所有流完成之后两个节点之间的通信阶段才算完成.本文设计了一个应用透明的协流识别机制,并对其进行进一步的优化.对于协流识别,利用机器学习中的聚类算法,探讨了协流的各种属性,同时无需手动修改任何应用程序,以达到高精度的识别.为了提高识别系统的性能,提出了优化措施.最后,利用仿真实验来评估算法的性能.
1 协流识别系统
协流识别系统主要包括3个步骤:
(1)属性选择
每一个流可以用一系列的属性表征,表示为一个属性元组.
(2)距离计算
已知属性元组,计算元组之间的距离来得到流之间的关系.其中,属于相同协流的流将具有较小的距离.
(3)基于聚类的识别策略
采用无监督的聚类来识别协流.之所以使用无监督的学习,是因为协流不能被预定义的类别标记.
1.1 属性选择
我们首先探讨一组可能在协流识别中有用的流级别、社区级别和应用程序级的属性.
(1)流级别属性
流程级的属性包扩了[2]:(i)Start_time流的生成时间;(ii)Size流中数据包的平均大小;(iii)Interval流内的数据包的平均到达时间.
(2)社区级别属性
最近对数据中心流量的研究表明,流量矩阵是稀疏的,大多数数据流会在一个稳定的节点集合内[3-4].这就表明了数据流是具有社区属性的,即数据中心可以被分成一个个的社区,同一个社区内通信频繁,不同社区之间的通信很少.这样,如果两个数据流是属于不同社区的,这两个数据流就不太可能在一个协流中.定义社区距离Dcom(fi,fj),如果Dcom(fi,fj)为0,流fi,fj就属于同一个社区.
(3)应用程序级别属性
如果两个数据流拥有相同的IP地址以及端口号,则这两个流就属于同一个聚合流.因此,定义端口距离Dport(fi,fj),如果Dport(fi,fj)为0,流fi,fj就属于同一个聚合流.
1.2 距离计算
给定两个流的属性元组,两个流fi,fj之间的初始距离度量可以被定义为它们之间的欧几里得距离.但是每个属性的重要性都不一样,不能赋予同样权值.因此,我们需要一个能够有效反映协流关系的距离度量.
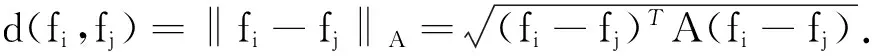
(1)
该优化问题可以使用牛顿法求解[5].
1.3 增量聚类协流识别
DBSCAN[6]方法能够快速准确地识别协流,但是DBSCAN算法最坏情况下的时间复杂度是O(n2),其中n是流的数量.因此,为了进一步减少算法的复杂度,本文使用R-DBSCAN[7].R-DBSCAN的复杂度是O(nk+k2),其中k是领导者的数量.在许多情况下,k远小于n.R-DBSCAN算法的步骤如下:
(1)扫描数据集,在数据中找到领导者(leaders)及其追随者(followers);
(2)对领导者集合运用DBSCAN算法;
(3)根据领导者-追随者的关系,推导出数据流的聚类.
为了更进一步优化R-DBSCAN,本文提出了增量R-DBSCAN,进一步加速聚类过程,并考虑了数据流的动态性,即新数据流的产生以及旧数据流的离开.增量R-DBSCAN具有仅O(mk+k2),其中m是产生/离开数据流的数量.增量R-DBSCAN算法如表1所示.

表1 增量R-DBSCAN算法
2 优化措施
尽管基于增量聚类的协流识别策略具有较高的准确性,该策略仍然有可能会产生误判.这样的错误会影响程序的性能.因此,需要对上一节提出的策略进行优化.
首先,给出关于“延误数据流”的定义.所谓延误的数据流,是指当某些数据流被错误地识别为属于同一协流时,这些数据流中的一部分数据流由于调度时间晚,导致其完成时间晚,从而增加了该协流的完成时间.
为了解决此问题,在聚类的过程中,采取了后绑定的方法来识别协流.例如,假设数据流f可能属于协流C1,也可能属于协流C2,即在聚类的过程中f是位于C1和C2的边界上.此时,不是任意地将其分配给C1或C2,而是将其视为暂时在C1和C2中.在调度的过程中,会将数据流f分配给C1和C2中具有较高优先级的并行流.首先,将原有的协流集合C以距离d扩展为C’,也就是将到C的距离为d的数据流都加入C’中.后绑定的算法如表2所示.

表2 后绑定算法
3 仿真实验及结果分析
实验网络是由40台服务器组成,服务器与以太网交换机连接.服务器的配置是:4核Intel E5-1410CPU,8G内存,500 GB硬盘以及配置有千兆以太网网卡.服务器的操作系统是CentOS 7.0.
对于基于聚类的协流识别系统,主要考察识别的精确度、召回率、准确度、协流完成时间和任务完成时间.实验的测试结果有4种:预测为正,实际为正(用TP表示);预测为正,实际为负(用FP表示);预测为负,实际为负(用TN表示);预测为负,实际为正(用FN表示).精确度的计算如下所示:
(2)
召回率的计算如下所示:
(3)
准确度的计算如下所示:
(4)
精确度、召回率以及准确度的结果如图1所示.基于聚类的协流识别的精度达到了99.3%,召回率则是97.5%.
在协流完成时间的对比实验中,将本文的基于聚类的协流识别与Aslo[8]和Per Flow Fairness(PFF)方法进行对比.结果如图2所示.实验结果通过公式(5)进行了归一化.

(5)
由此可知,如果某个方法的归一化完成时间大于1,则该方法的完成时间长于本文方法,即该方法的性能比不上本文的方法.因此,由图2可知,本文方法要明显优于PFF方法,稍稍好于Aalo方法.

图1 精度、召回率以及准确度结果

图2 平均完成时间结果
4 结论
本文提出了基于增量聚类的协流识别系统,采用增量聚类算法来执行快速、应用透明的协流识别,并提出优化措施来提高系统的性能.仿真实验结果表明,基于增量聚类的协流识别具有较高的精确度和召回率,整体表现与Aalo相当.
[1] DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[C]∥ Conference on Symposium on Opearting Systems Design & Implementation.USENIX Association,2004:10-16
[2] NGUYEN T T T,ARMITAGE G.A survey of techniques for internet traffic classification using machine learning[J].IEEE Communications Surveys & Tutorials,2009,10(4):56-76.
[3] MENACHE I,CHOWDHURY M,MANI P,et al.Surviving failures in bandwidth-constrained datacenters[J].Acm Sigcomm Computer Communication Review,2012,42(4):431-442.
[4] BAGGA J,BAGGA J,BAGGA J,et al.Inside the social network’s (datacenter) network[C]∥ ACM Conference on Special Interest Group on Data Communication.ACM,2015:123-137.
[5] XING E P,NG A Y,JORDAN M I,et al.Distance metric learning,with application to clustering with side-information[C]∥ International Conference on Neural Information Processing Systems.MIT Press,2002:521-528.
[6] ESTER M,KRIEGEL H P,XU X.A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]∥ International Conference on Knowledge Discovery and Data Mining.AAAI Press,1996:226-231.
[7] VISWANATH P,BABU V S.Rough -DBSCAN:A fast hybrid density based clustering method for large data sets[J].Pattern Recognition Letters,2009,30(16):1477-1488.
[8] CHOWDHURY M,STOICA I.Efficient coflow scheduling without prior knowledge[C]∥ ACM Conference on Special Interest Group on Data Communication.ACM,2015:393-406.
