基于Sqlserver2008数据库下的报表服务方案探析
2018-01-22刘建军
刘建军
(吉林省教育学院 网络信息中心,长春130022)
1 报表服务方案
1.1 报表服务方案
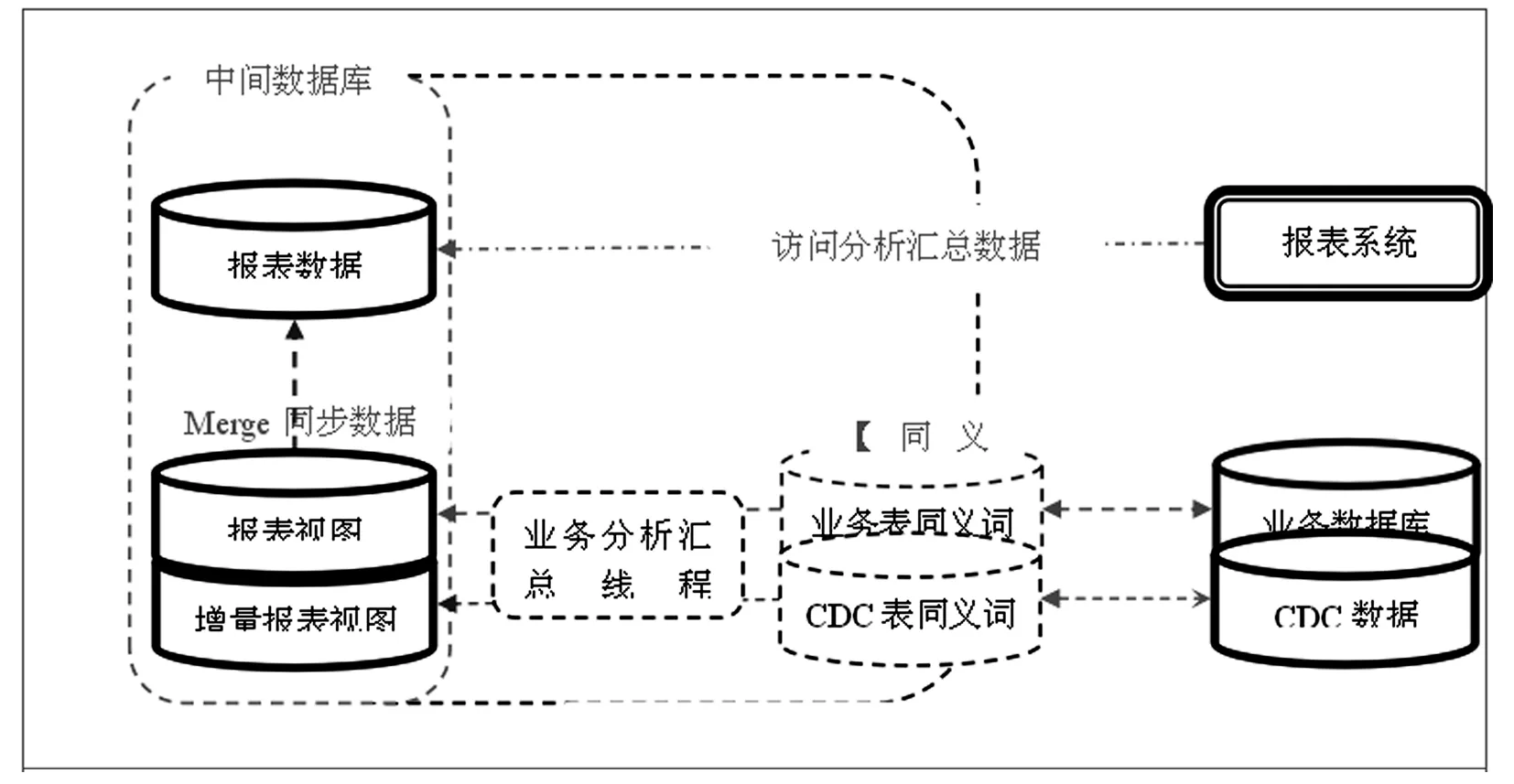
图1 报表服务整体流程
针对业务数据库报表数据情况不同,采用两种方式进行数据同步。
(1)同步增量报表。对数据基数大且数据更新频繁的业务表,则采用同步增量统计分析结果的方式,即同步增量报表。即在中间数据库上,对业务表的cdc数据的同义词按业务逻辑进行报表分析汇总,获得增量报表,同步该增量报表到报表数据。同步过程主要为合并过程,可理解为两个二维统计表的逻辑加。
(2)同步报表。对数据基数比较小或数据更新频率较低的业务表,则采用同步统计分析结果,直接同步报表的方式。即在中间数据库上,对业务表的同义词直接按业务逻辑进行分析汇总后,同步报表到报表数据。同步过程主要为替换过程,可理解为先删除再新增。
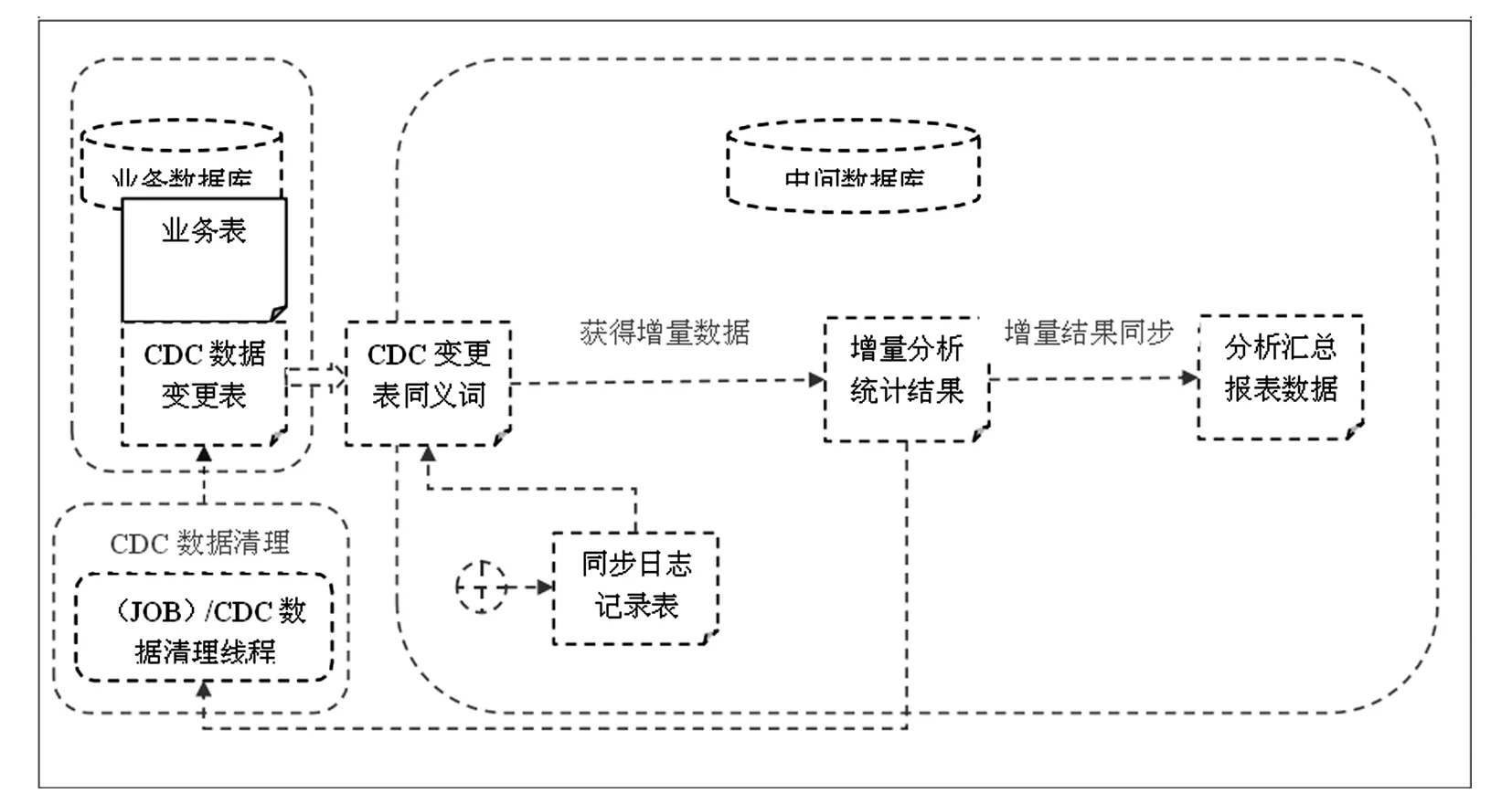
图2 同步增量报表
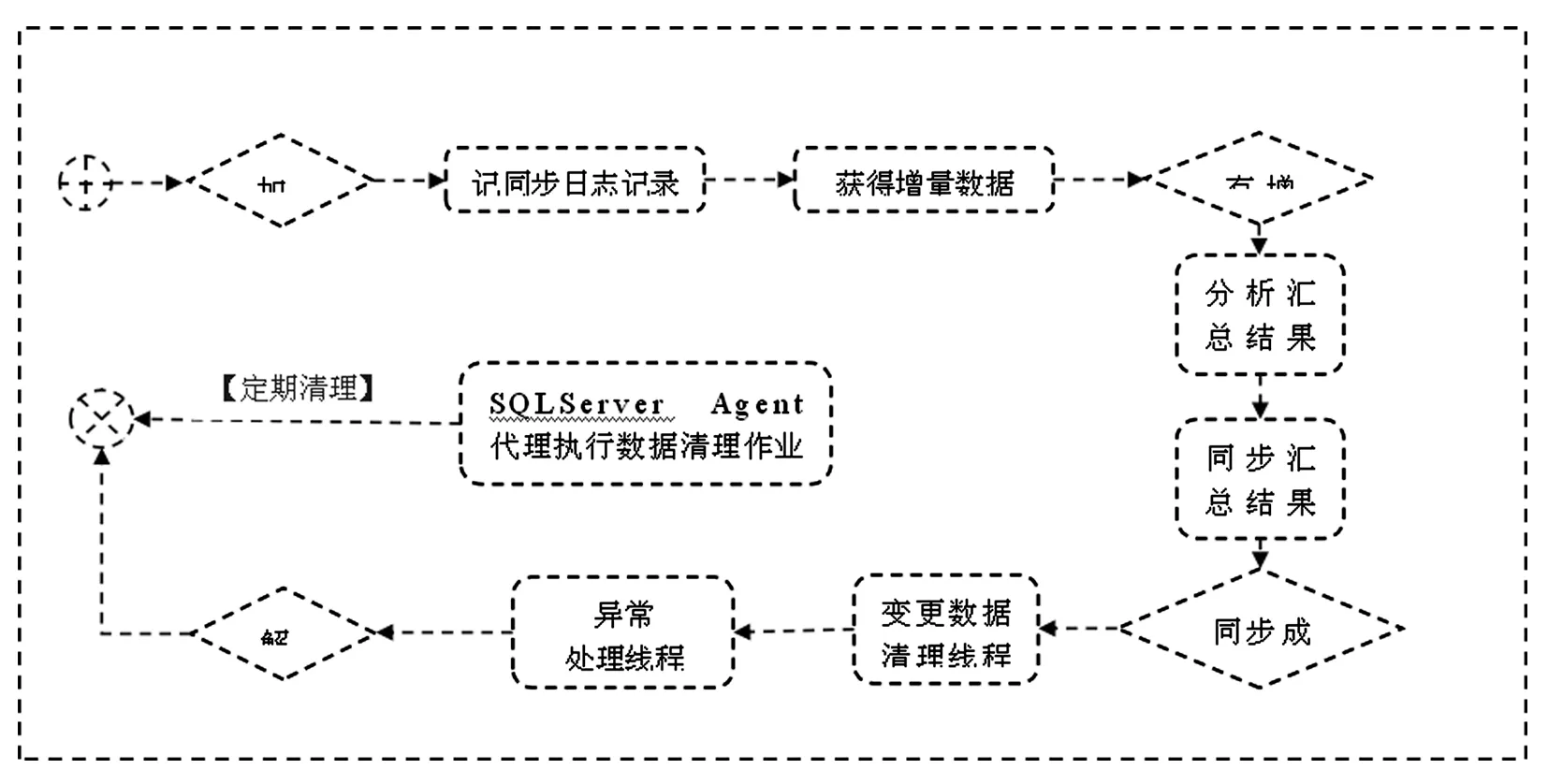
图3 同步增量报表服务业务流程

图4 同步报表
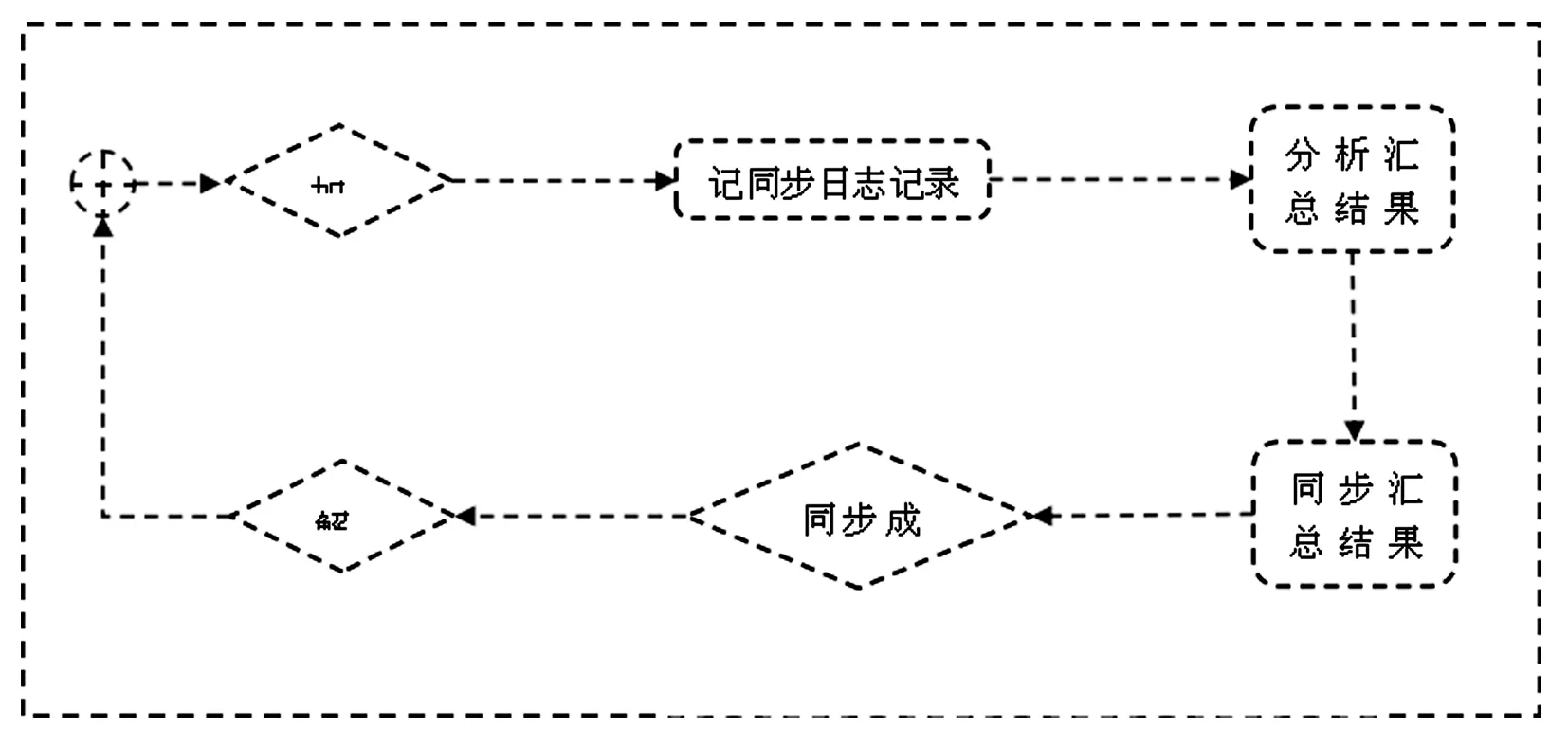
图5 同步报表服务业务流程
1.2 报表服务表结构
1.3 报表服务过程及其描述

表2 报表服务存储过程
2 报表服务使用步骤
2.1 初始准备
(1)启用sqlserver数据库的SQL Server Agent代理服务。
(2)对sqlserver数据库的对应业务数据库启动CDC即变更数据捕捉功能。
执行SQL代码为:EXEC sys.sp_cdc_enable_db。
(3)分析原报表服务统计分析SQL语句中涉及的对象范围、数据量级别来确定是否对该对象启用CDC。
例如:
报表服务对A1,A2,A3表统计汇总,A1、A2表数据量很大,A3表数据量很少,数据均有频繁变动,则需要对A1,A2,A3表均启用变更数据捕捉。
报表服务对A1,A2,A3表统计汇总,A1、A2表数据量很大并有数据变化,A3表数据量很少且数据变化不频繁,则只需对A1,A2表均启用变更数据捕捉.
报表服务对A1,A2,A3表统计汇总,A1,A2,A3表数据量均很小,A1,A2,A3数据变化频率低且变化数据范围较小,则不需要启用变更数据捕捉,而采用报表服务方式二处理.
(4)确定变更捕捉字段,确定捕捉源表中哪些字段的数据变化到变更捕获表中。
(5)执行EXEC sys.sp_cdc_enable_table并调整相应参数对表及相应字段启用变更数据捕捉,随即在系统表下生成cdc架构下的对应该表的变更数据捕获表。
(6)在报表数据库下建立报表服务涉及表的同义词,启用cdc有变更捕获表则建立变更捕获表的同义词,没有启用cdc,则直接对该表建立同义词。
(7)在报表数据库下建立报表数据存储表,用作存储执行报表、或者增量报表数据。报表服务采用MERGE方法同步数据该报表数据存储表。
2.2 报表服务实现步骤
(1)调用过程Prcd _Reg,注册报表服务信息到日志记录表。
(2)调用过程Prcd_AppLock,对业务存储过程加应用程序锁,以保证该过程执行的唯一性。
(3)调用过程Prcd_ClearCDC,清理变更表中失效数据。
(4)调用过程Prcd_GetLSN,获得变更捕获表中的最大最小LSN。
(5)同步增量统计报表结果到报表数据存储表。
获得增量数据方法:
第一类,例如报表服务业务SQL:
select a.column1,sum(a.column2),sum(b.column3) from a join b on a.column1=b.column1 .
其中column1为业务主键,column2,column3为数值类型字段
只需要将表a,b替换,
select a.column1,sum(a.column2),sum(b.column3) from
(select column1,sum(case __$operation when 1 then -column2 when 2 then column2 when 3 then - column2 else column2 end) from a where __$start_lsn >0 and __$start_lsn< ? group by column1) a
join
(select column1,sum(case __$operation when 1 then -column3 when 2 then column3 when 3 then - column3 else column3 end) from a where __$start_lsn >0 and __$start_lsn< ? group by column1) b
on a.column1=b.column1 .
另外需要加条件加以控制增量统计范围,__$start_lsn为LSN事务序列号。
第二类,例如报表服务业务SQL:
Select column1,sum(column2) from a group by column1
其中column1为字符类型字段,column2为数值类型字段,且column1不一定为主键。Column1字段可能会变更并影响报表结果。
Select column1,sum(column2) from
(select column1,sum(case __$operation when 1 then -column2 when 2 then column2 when 3 then - column2 else column2 end) from a where __$start_lsn >0 and __$start_lsn< ? ) a
group by column1
MERGE同步数据:
示例SQL脚本如下(需要将上述增量计算SQL替换【源结果集】位置,将报表数据存储表名替换到【目标表】位置):
merge 目标表 as t
using( 源结果集 ) as s
on(s.关联键值 = t. 关联键值)
when matched then
update set t.字段 = s. 字段+ t.字段
when not matched then
insert values(s.字段) ;
(6)根据业务复杂度可能重复上述同步增量统计数据过程。
(7)调用过程Prcd_RunLog,将执行信息写入到日志表。
(8)调用过程Prcd_AppUnLock,对业务存储过程解应用程序锁。
(9)如对数据基数小且变更不频繁的报表服务业务表作统计分析,因为未开启变更数据捕捉,则使用步骤类似但有所区别,所不同的是不需采用获得增量数据过程,而是直接执行merge同步统计分析数据过程。
(10)当报表存储过程业务流程处理过程中出现异常,则调用存储过程Prcd_ErrorLog存储过程记录异常到异常记录表。
[1] 杨志国.SQL Server2005数据库管理精讲[M].北京:电子工业出版社, 2007.
[2] Kalen Delaney.Microsoft SQl Server 2005技术内幕:存储引擎[M].北京:电子工业出版社,2010.
[3] 陈振.基于日志分析的SQL Server数据库变更数据捕获方法的研究与实现[D].广州:暨南大学,2010.
[4] 孙燕.异构数据库数据同步的关键技术研究[D].唐山:华北理工大学,2015.
