基于深度学习的大规模人脸图像检索
2018-01-22卢宗光刘青山孙玉宝
卢宗光,刘青山,孙玉宝
(南京信息工程大学 a.信息与控制学院,b.江苏省大数据分析技术重点实验室,南京 210044)
人脸检索的目标是将数据库中人脸图像和输入人脸图像按照相似性进行搜索,并依据相似程度由高到低进行排序输出。人脸图像检索方法主要包括人脸特征表示及针对所提特征的高效索引两个步骤。当前大多数人脸检索方法通过计算人脸几何属性(如两眼之间的距离,两眼与鼻尖之间的角度,两嘴角与鼻尖构成三角形的面积等)或面部显著特征点(如眼睛、鼻子、嘴巴等)处的局部特征之间的相似性[1-2]。BACH et al[3]先对人脸图片进行标注,然后从标注点提取人工设计特征进行人脸相似性匹配,即实现了一种半自动化的人脸检索系统。EICKELER et al[4]率先采用2DPHMM方法进行人脸检索,并取得了不错的结果。GUDIVADA et al[5]受人脸匹配启发,首次将人脸匹配过程中使用的特征应用于人脸检索系统。WANG et al[6]提出了一种使用LBP[7](local binary pattern)的多任务学习架构来解决人脸验证和人脸检索问题。近年来,通过使用深度学习来学习人脸特征表示取得了一系列重大突破[8-13]。文献[14]首次提出将两张图片的匹配程度映射到一个度量距离,并用距离的大小表示匹配程度的高低。
文献[16-17]创新性地改变了卷积神经网络监督学习时的验证信号(softmax loss),使得深度学习特征包含了更丰富的身份信息。文献[18]更进一步,在之前网络的每一个卷积层之后添加一层全连接层并计算损失函数,但此时网络层数较浅,训练样本量较少,需要进行复杂的样本扩充操作。文献[9-10,19]展现了三元组损失(triplet loss)函数在人脸特征深度学习上的优势,通过深度嵌入(deep embedding),使锚点(anchor)和正样本(positive)之间的距离最小,锚点和负样本(negative)之间的距离最大直到两者达到预设的阈值,由于训练样本为三元组,这对样本的选取提出了很高的要求,选取过程操作复杂。
本文采用Inception-ResNet-v1网络并借鉴了WEN et al[20]的Center loss对网络损失函数进行修改,且损失函数计算较简单,不需要对训练样本选择做过多操作。首先,使用约四百万训练样本对网络进行训练,得到了优秀的人脸特征表示模型。然后,对百万级人脸图像检索库进行特征提取。最后,对所获特征采用由粗到细的分层匹配进行相似性检索得到检索结果。
1 人脸检测特征提取及人脸图像检索
人脸检测是一切人脸分析技术的基础,准确、鲁棒的人脸检测器是人脸检索的前提。本文采用MTCNN检测器。
该检测器人脸检测主要分为以下3个步骤:
1) Proposal网络(P-Net)对输入图像产生大量候选人脸框。
2) Refinement网络(R-Net)对上一步产生的候选框进行细化,舍弃多余和不正确的人脸候选框。
3) 输出网络(O-Net)产生最终的人脸框和5个人脸关键点。
1.1 特征提取网络设计
由于卷积神经网络在多项应用中有着优异的表现,其在计算机视觉领域里扮演着越来越重要的角色。本文采用的33层Inception-ResNet-V1网络结构如图1所示,其中包含了一个输入原始图片,输出35×35×256(35×35为特征图大小,256为卷积核数量,下同)的stem结构;5个输入输出为35×35×256的Inception-resnet-A(细节见图2)结构;一个输入为35×35×256输出为17×17×896的Reduction-A结构;10个输入输出为17×17×896的Inception-resnet-B(细节见图3);一个输入为17×17×896输出为8×8×1792的Reduction-B结构;5个输入输出为8×8×1792的Inception-resnet-C(细节见图4);全连接层以及最终的损失函数层。该网络结构结合了当前最优秀的两个深度卷积神经网络Inception[21]和深度残差网[22]的优点,在大数据量训练集条件下有着十分优异的表现,本文训练集包含了3 942 599张来自82 360位个体的人脸图片,故选用了此网络。

图1 Inception-ResNet-V1网络结构总览Fig.1 The overall schema of Inception-ResNet-V1 network
图2为图1网络结构总览中连接输入层和Inception-resnet-A层之间的stem网络结构,它包含7层网络。输入层为299×299的RGB三通道图片,分别经过3次卷积、1次最大池化和3次卷积之后得到35×35×256的特征图。图中Conv为卷积层,MaxPool为最大池化层。括号内第一个数字为卷积核数量;stride 2表示卷积或池化是步长为2没有特殊表明的则步长为1;带有字母‘V’的表示该层采用valid padding,此时该层输出严格根据输入特征图大小、卷积核大小和步长来确定;没有字母‘V’的层采用same padding,此时会自动根据输入特征图尺寸对特征图进行填充使得输出特征图和输入特征图具有相同尺寸。
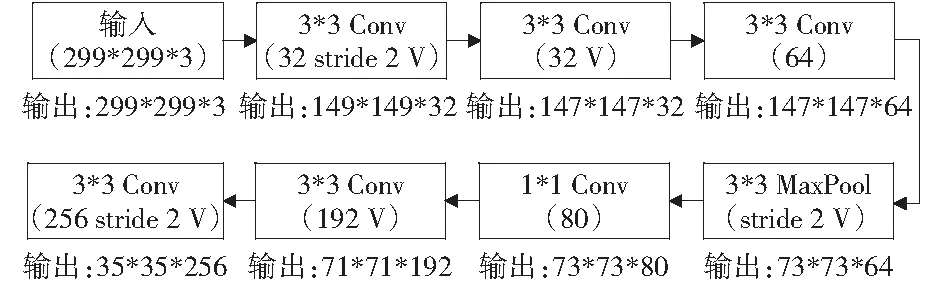
图2 stem网络结构Fig.2 The schema of stem network
图1中的Inception-resnet-A,Inception-resnet-B,Inception-resnet-C结构是该网络结构的主要卷积层,该结构结合了GoogLeNet和残差网络的优点,既降低了深层神经网络的参数量又解决了深度神经网络梯度容易消失的问题。
该网络起初是针对分类任务设计,其损失函数为Softmax loss, 如公式(1):
(1)
式中:xi∈Rd表示类别为第yi类的第i个深度特征,d为特征维度;Wj为最后全连接层权值矩阵W∈Rd×n的第j列,b∈Rd为偏置项;n为样本类别数量,m为当前训练批次内样本数量。该损失函数在多目标分类问题中有着优异的表现。人脸特征表示对网络泛化能力提出了更高的要求,故借鉴WEN et al[13]的Center loss,对网络损失函数进行修改。Center loss函数如公式(2):
(2)
式中:cyi∈Rd表示类别为第yi类的深度特征的特征中心,该中心损失函数能够有效降低人脸图像的类内差,cyi会随着训练的迭代进行更新。
因此,最终的损失函数为:

(3)
λ用于平衡两种损失函数。
Softmax loss可以增大不同类别之间的类间差(inter-class),同时,Center loss降低了同类样本之间的类内差(intra-class).通过综合,最终得到维度为128的人脸表示特征向量。
1.2 由粗到细的人脸快速检索
尽管已经获取到维度低、鲁棒性强的人脸表示特征,但是在百万级人脸数据库中通过线性检索仍耗时大约5 s,这在某些快速检索场景下显然是不能容忍的。为了加速检索,我们对提取的人脸特征数据进行聚类分析,将数据进行拆分。在我们的实验中,每类约10万条数据时,可以牺牲最少的检索准确率达到提升一个数量级的检索速度。
2 实验与分析
2.1 实验数据及预处理
实验采用以下数据集:CASIA-WebFace(后称CASIA)[23],MS-Celeb-1M(后称MSCeleb)[24],LFW[27]以及FaceRetrieval-A,FaceRetrieval-B,FaceRetrieval-C.这6个数据集详细信息见表1.
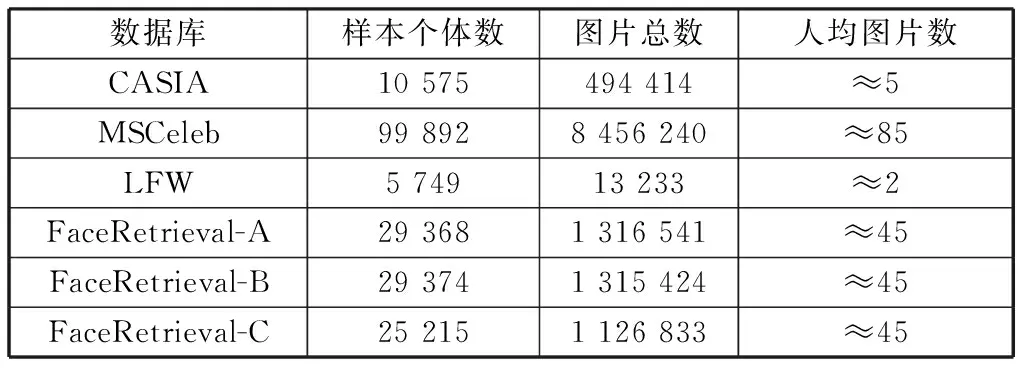
表1 实验数据库信息Table 1 Details of the datasets
CASIA是由中科院整理发布的大规模人脸数据集,MSCeleb是微软公司发布的百万级人脸数据库,这两个数据库也是目前公开人脸数据库里拥有图片数量最多的,因此,本文采用这两个数据集作为网络训练数据。LFW是目前较主流的人脸验证测试评估数据集,该人脸验证数据集分为多种验证模式,本文对人脸特征性能评估皆是在非限制条件下外部标记训练集模式下进行。FaceRetrieval-A,FaceRetrieval-B,FaceRetrieval-C 3个百万级人脸数据库用作人脸检索测试库。图4展示了这6个人脸数据库中的部分图片,其中CASIA和MSCeleb中的人脸图片均根据人脸位置进行了裁剪,并且CASIA中图片尺寸均被缩放为,而MSCeleb没有被统一缩放。
2.2 模型训练及分析
2.2.1 数据预处理
由于CASIA和MSCeleb数据库中均存在一些错误样本,为了提升训练数据的纯度,我们采用了文献[28]中的人脸特征提取模型,对这两个数据库进行过滤,具体步骤如下:
1) 使用MTCNN进行人脸检测并根据人脸位置和网络输入要求对图片进行剪切缩放,删去未检到人脸图片。
2) 使用文献[25]中的网络提取人脸特征。
3) 使用步骤2)中的人脸特征进行人脸识别。首先随机从每一类人脸图片中选择一张作为探针;然后,对该类剩余人脸图片一一执行人脸验证操作,删除验证结果不相同的图片;最后,删去总数少于5张图片的人脸类别。

图4 本文使用数据库的部分示例图片Fig.4 Some examples of the used datasets
经过此过滤操作之后两个数据库信息如表2所示。
2.2.2 模型训练及分析
实验分别针对损失函数设计及λ选择、数据集大小、人脸特征维度设计了4组对比试验。均在LFW数据库上进行外部训练数据模式的人脸验证评估。所有模型训练使用相同硬件环境,主要配置为两块英特尔Xeon E5-2640 CPU, 两块英伟达Pascal GPU和128 GB内存。

表3 网络训练固定参数Table 3 The fixed parameters of the training procedure
为了验证Center loss对网络提取人脸特征性能有提升作用,设计了一组对比试验:分别使用Softmax loss 以及Softmax loss加Center loss深度网络的监督学习并在LFW测试库上进行人脸验证评估。训练数据库均为MSCeleb,输出人脸特征维度设置为128维,分别取0和0.000 1,结果见表4.实验结果表明,添加了Center loss的损失函数对特征性能提升有促进作用。
λ取值对模型效果影响的实验中,分别使用CASIA和MSCeleb数据库作为网络训练样本,输出人脸特征维度设为128维,分别取0.1,0.01,0.001,0.000 1.其它固定训练参数见表3.分别对得到的模型在LFW测试库上进行人脸验证评估,结果如表4,通过加入Center loss一定程度上提高了验证准确率。
表4同时反映了数据集大小对模型效果影响,训练数据规模的提升大幅度提升了模型性能,这充分证明了大数据是驱动深度学习的一个重要条件。

表4 不同规模训练数据集下不同值的验证准确率Table 4 The verification accuracy of different λ under different scale training datasets %
MSCeleb数据库是网络训练时的训练集,在人脸特征维度对模型效果影响的实验中,分别设置输出人脸特征维度为96,128,256维。其它训练参数见表3,此时λ=0.000 1.同样的,分别用这3种维度的特征在LFW数据库上进行了人脸验证评估,结果如表5.我们发现特征维度为128维时既有很高的识别准确率,又降低了后续人脸检索时的检索复杂度。因此,我们设置网络输出特征维度为128维。

表5 不同特征维度的验证准确率Table 5 The verification accuracy of different feature dimensions
通过对以上三组对比实验结果,最终选择训练样本为MSCeleb数据库,λ=0.000 1且输出特征为128维的模型作为人脸特征表示模型。
与当前最优秀的人脸验证方法做了对比,结果如表6.
在下一步的人脸检索中,基于CASIA数据库训练λ=0.000 1且输出特征为128维的模型将作为人脸检索实验的基准。
2.3 人脸检索评估及分析
2.3.1 实验设定及评估标准
人脸检索实验的数据库分别为FaceRetrieval-A、FaceRetrieval-B、FaceRetrieval-C.

表6 与当前优秀方法的准确率对比Table 6 Verification performance of different methods on LFW datasets %
对每一类抽取该类最后一张人脸图片作为检索目标。因此,三个数据库检索目标数量分别为29 368,29 374,25 215.另外,表1中这三个数据库的图片总数已经是剔除检索目标后的图片数量。在下面的检索实验中,分别评估Top1,Top5,Top10检索准确率(PTopk)。具体计算方式为:
(4)
式中:n表示检索目标数量,C(Xi,Yi)表示第i个检索目标的真实类别Xi与检索结果类别Yi的比较结果。若Xi=Yi,则C(Xi,Yi)=1;若Xi≠Yi,则C(Xi,Yi)=0.在Top1模式下Yi为相似性最高的结果,而Top5和Top10分别为相似性位列前5和前10的检索结果且这些结果里只要有一个与真实类别Xi相同则C(Xi,Yi)=1.
2.3.2 实验结果及分析
对于3个人脸检索测试集,分别采用了两种检索方法:线性检索和分层检索。线性检索首先计算目标检索图片特征和检索测试集中所有图片特征之间的欧氏距离;接着对得到的距离由低到高进行排序;最后,根据排序结果获取Top1,Top5,Top10检索结果。
分层检索是先对3个人脸测试集特征进行聚类分析,将每个测试集特征拆分为10个子集,并记录下每个子集的特征中心。分层检索的具体步骤如下:
1) 计算目标检索图片特征与10个子集特征中心的欧式距离并选择最近的一个子集;
2) 计算目标检索图片特征与第一步得到的最近子集中所有图片特征的欧式距离并进行排序;
3) 根据排序结果获取Top1,Top5,Top10检索结果。
表7,8,9分别是FaceRetrieval-A、FaceRetrieval-B、FaceRetrieval-C三个人脸检索测试集上的人脸检索结果,这里基于CASIA数据库训练的模型作为对比实验基准。
在FaceRetrieval-A数据库上,取得了较高的检索准确率。其中在线性检索方法下:基于MSCeleb训练集模型的Top1,Top5,Top10检索准确率较使用CASIA训练集的检索基准分别提高1.71%,0.76%和0.48%,达到92.78%,95.69%和96.79%.此时,单次检索时间约为5.2 s.为了提高检索速度,在分层检索方法下,基于MSCeleb训练集模型的Top1,Top5,Top10检索准确率相比检索准确率分别提升了2.54%,1.42%和1.11%,达到90.19%,93.21%和94.38%.此时,单次检索时间约为0.6 s,较线性检索速度提升了8.7倍。

表7 FaceRetrieval-A数据库上的人脸检索结果Table 7 Result of face retrieval on FaceRetrieval-A datasets
在FaceRetrieval-B数据库上,检索实验同样有着优秀的表现。其中在线性检索方法下,基于MSCeleb训练集模型的Top1,Top5,Top10检索准确率较使用CASIA训练集的检索基准分别提高1.19%,0.59%和 0.45%,达到92.54%,95.61%和96.74%.此时,单次检索时间约为5.4 s.在分层检索方法下,基于MSCeleb训练集模型的Top1,Top5,Top10检索准确率相比检索准确率分别提升了2.02%,1.29%和1.03%,达到89.93%,93.19%和93.40%.此时,单次检索时间约为0.6 s,较线性检索速度提升了9倍。
与前两个检索测试集相比,FaceRetrieval-C数据库数据量略小。检索实验依然有着不俗的表现。其中在线性检索方法下,基于MSCeleb训练集模型的Top1,Top5,Top10检索准确率较使用CASIA训练集的检索基准分别提高1.49%,0.55%和0.31%,达到93.19%,95.81%和96.89%.此时,单次检索时间约为4.3 s.为了提高检索速度,在分层检索方法下,基于MSCeleb训练集模型的Top1,Top5,Top10检索准确率相比检索准分别提升了2.21%,1.23%和0.73%,达到90.37%,93.19%和94.27%.此时,单次检索时间约为0.46 s,较线性检索速度提升了9.3倍。

表8 FaceRetrieval-B数据库上的人脸检索结果Table 8 Result of face retrieval on FaceRetrieval-B datasets

表9 FaceRetrieval-C数据库上的人脸检索结果Table 9 Result of face retrieval on FaceRetrieval-C datasets
通过以上3个测试集的测试,清晰地体现出大数据对深度学习模型效果的提升。采用MSCeleb数据训练的模型在每个测试条件下,结果都优于使用CASIA数据训练的模型,并且在分层检索模式下使用CASIA数据训练的模型准确率下降幅度更大。为了提升检索速度,我们牺牲了大约2.5%的检索精度换取了提升约9倍的检索速度,使得百万级数据库单次检索时间在0.5 s左右。在某些需要快速检索的特定场景下,分层检索有相当的优势。
以上所有检索实验均在一台配置英特尔酷睿i7-4790 CPU和16 GB内存的台式机上操作。
3 结论
笔者设计了针对三个百万级人脸数据库的检索实验,并就检索精度和检索速度分别采用了不同的检索策略,即在高检索精度场景中牺牲一定的检索时间从而达到更精确的检索成功率,在快速检索场景中损失大约2.5%的检索成功率进而提升了约9倍的检索速度。所有实验均取得优秀的实验结果。另外,针对人脸特征表示模型的的训练,提出了不同的训练方法,就损失函数设计、数据集选取和特征维度设置做了详实的实验分析,并选择了最优解决方案。
[1] CHAN C H,TAHIR M A,KITTLER J,et al.Multiscale local phase quantization for robust component-based face recognition using fusion of multiple descriptors[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(5):1146-1177.
[2] WU Z,KE Q,SUN J,et al.Scalable face image retrieval with identity-basedquantization and multireference reranking[J].IEEE Transactions on Pattern Analysis and MachineIntelligence,2011,33(10):1991-2001.
[3] BACH J R,PAUL S,JAIN R.A visual informationmanagement system for the interactive retrieval offaces[J].IEEE Transactions on Knowledge and Data Engineering,1993,5(4):619-628.
[4] EICKELER S.Face database retrieval using pseudo 2dhidden markov models[C]∥IEEE.International Conference on Automatic Face and Gesture Recognition.2002: 0065.
[5] GUDIVADA V N,RAGHAVAN V V.Modeling andretrieving images by content[J].Journal of InformationProcessing and Management,1997,33(4):427-452.
[6] WANG X,ZHANG C,ZHANG Z.Boosted multi-task learning for face veri_cation with applications to web image and video search[C]∥IEEE.Conference on Computer Vision and Pattern Recognition.2009:142-149.
[7] OJALA T,PIETIKINEN M.Multiresolution gray-scale and rotation invariant texture classication withlocal binary patterns[J].IEEETransactions on PatternAnalysis and Machine Intelligence,2002,24(7):971-987.
[8] PARKHI O M,VEDALDI A,ZISSERMAN A.Deep facerecognition[C]∥British Machine Vision Conference.2015.
[9] SCHROFF F,KALENICHENKO D,PHILBIN J.FaceNet:A unified embedding for face recognition and clustering[C]∥IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society,2015:815-823.
[10] SUN Y,WANG X,TANG X.Hybrid deep learning for face verification[J].IEEE Transactions on PatternAnalysis & Machine Intelligence,2013,38(10):1997-2009.
[11] SUN Y,WANG X,TANG X.Deep learningface representation by joint identification-verification[J].2014,27:1988-1996.
[12] TAIGMAN Y,YANG M,RANZATO M,et al.Deepface:Closing the gap to human-level performancein face veri_cation[C]∥Conference on Computer Visionand Pattern Recognition.2014:1701-1708.
[13] WEN Y,LI Z,QIAO Y.Latent factor guidedconvolutional neural networks for age-invariant facerecognition[C]∥IEEE Conference on Computer Visionand Pattern Recognition.2016:4893-4901.
[14] CHOPRA S,HADSELL R,LECUN Y.Learning asimilarity metric discriminatively,with application toface veri_cation[J].Computer Vision and Pattern Recognition,2005(1):539-546.
[15] PAPAGEORGIOU C P,OREN M,POGGIO T.A general framework for object detection[C]∥Computer vision sixth international conference.1998:555-562.
[16] SUN Y,WANG X,TANG X.Deep learning facerepresentation from predicting 10,000 classes[C]∥IEEE.Conference on Computer Vision and Pattern Recognition.USA:Columbus,2014:1891-1898.
[17] TAIGMAN Y,YANG M,RANZATO M,et al.Deepface:Closing the gap to human-level performancein face verification[C]∥Conference on Computer Visionand Pattern Recognition.2014:1701-1708.
[18] SUN Y,WANG X,TANG X.Deeply learnedface representations are sparse,selective,and robust[J].Computer Science,2014:2892-2900.
[19] LIU J,DENG Y,BAI T,et al.Targeting ultimate accuracy:face recognition via deepembedding[J/OL].[2015-07-23].http://arxiv.org/abs/1506.07310.
[20] WEN Y,ZHANG K,LI Z,et al.A discriminative feature learning approach for deep face recognition[C]∥European Conference on Computer Vision.Berlin:Springer International Publishing,2016:499-515.
[21] ZHANG K,ZHANG Z,LI Z,et al.Joint face detection and alignment using multi-task cascaded convolutional networks[J].IEEE Signal Processing Letters,2016,23:1499-1503.
[22] HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2016:770-778.
[23] YI D,LEI Z,LIAO S,et al.Learning face representation from scratch[J].Computer Science,2014.
[24] GUO Y,ZHANG L,HU Y,et al.Ms-celeb-1m:a dataset and benchmark for large-scale face recognition[C]∥European Conference on Computer Vision.Berlin:Springer International Publishing,2016: 87-102.
[25] LU Z,YANG J,LIU Q.Face image retrieval based on shape and texture feature fusion[C]∥Computational Visual Media Conference.2017.
[26] CHEN D,CAO X,WANG L,et al.Bayesian face revisited:A joint formulation[J].Computer Vision-ECCV 2012,2012:566-579.
[27] BERG T,BELHUMEUR P N.Poof:Part-based one-vs.-one features for fine-grained categorization,face verification,and attribute estimation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2013:955-962.
[28] BERG T,BELHUMEUR P N.Tom-vs-pete Classifiers and Identity-preserving Alignment for Face Verification[C]∥BMVC.2012,2:7.
[29] CAO X,WIPF D,WEN F,et al.A practical transfer learning algorithm for face verification[C]∥Proceedings of the IEEE International Conference on Computer Vision.2013:3208-3215.
