一种基于本体的有趣Co-location模式的交互式挖掘算法
2018-01-22包旭光王丽珍赵家松
包旭光,王丽珍,肖 清,赵家松
(云南大学 信息学院,昆明 650091)
空间数据挖掘是从空间数据库中挖掘未知的有趣模式的过程。因为空间数据的海量性、多维性、相关性等特点,从空间数据集中挖掘有趣模式比从事务数据集中挖掘要困难得多[1]。
传统数据通常是相互独立的,而空间上分布的数据则是相关的,或者更确切地说是空间并置的(co-located),即两个对象的位置越近,就越有可能具有相似的性质。空间co-location模式是空间特征的一个子集,它们的实例在空间中频繁关联[2]。
空间co-location模式在许多应用领域发挥着重要的作用。例如,移动服务运营商根据不同需求用户的分布,搭配相应的服务套餐以增加收入;广告运营商根据特定人群的聚集地段,投放相应的广告;银行根据不同地域人群的不同收入设定相应的信用卡服务和理财产品。空间co-location模式的应用领域还包括地球科学、公共卫生、公共交通、生物信息处理、基于位置的服务、GIS信息系统等[3]。
空间co-location模式挖掘是空间数据挖掘的一个重要分支,已经涌现了大量的高效算法。通常,这些co-location模式挖掘算法仅用一个主观的参与度阈值来衡量co-location模式的频繁性,如果这个数值设置得太小,会产生非常多的频繁co-location模式,这会给用户带来很大的选择困扰;如果这个数值设置得太高,某些用户感兴趣的稀有co-location模式[4]可能会被遗漏。特别地,如果空间数据集中有n个特征,则可能会产生最多2n-n-1个频繁co-location模式,随着n的增大,频繁co-location模式的数量呈指数增长,而实际上,用户真正感兴趣的co-location模式可能只是几个或者几类co-location模式,从这种海量co-location模式中挑选几个感兴趣的co-location模式就变得非常棘手。
为了解决上面提到的问题,以减少频繁co-location模式数量为目的的挖掘算法受到关注,如模式的精简表示[5-7]、模式冗余处理[8]以及二次挖掘[9-10]。这些算法虽然可以减少频繁co-location模式的数量,但是无法保证得到用户真正感兴趣的模式。我们注意到,模式的有趣程度与用户的领域知识有着很大的关联性,一个模式对某个用户是有趣的,但是另外一个用户可能根本不感兴趣。因此,要得到用户真正感兴趣的模式,就需要与用户进行交互。
另一方面,用户领域知识也可以指导有趣模式的挖掘。在语义网领域,本体[11-13](ontology)被认为最适合表示复杂的用户领域知识,且本体语言也可以更好地表达复杂的用户领域知识。
鉴于此,本文提出了一个基于本体的有趣co-location模式的交互式挖掘算法OIICM(ontology-based interactive interesting co-location miner).OIICM以一组候选co-location模式集(例如:频繁co-location模式集)为原始输入,通过与用户的交互,选取用户真正感兴趣的co-location模式。OIICM只需要与用户进行有限次的交互,每次交互送给用户一组数量较少的代表co-location模式(例如:5个),用户只需要在每次交互中对这一组代表co-location模式进行喜好的选择即可。图1给出了OIICM的交互过程。每次交互,OIICM从候选co-location模式集中选择几个co-location模式作为代表co-location模式集提供给用户,用户对该代表co-location模式集中的每个co-location模式进行喜好的选择并提交自己的反馈, OIICM利用本体将对用户的反馈进行分类并更新候选co-location模式集,同时,将有趣的co-location移动到结果集,然后再从候选co-location模式集中选择新的代表co-location模式集供用户选择,一直循环到候选co-location模式集为空。交互过程结束之后得到的有趣co-location模式集称之为结果集。最后,在不丢失结果集语义的前提下,OIICM提供了一个有效的过滤器对结果集进行过滤,得到最终的有趣co-location模式集。

图1 交互过程描述Fig.1 Description of the interactive process
与用户交互地挖掘有趣co-location模式需要解决两个基本的问题:第一,怎样利用本体来更新候选co-location模式集?第二,为了减少交互次数,OIICM应该怎样选择代表co-location模式集?为了解决第一个问题,本文利用本体来度量两个co-location模式的相似度,如果用户对某个co-location模式c感兴趣,则对与c相似的co-location模式也同样感兴趣,这样可以有效地减少候选co-location模式集的数量;为了解决第二个问题,本文提出了一个贪心策略选择尽可能不同的co-location代表模式。下面分别讨论。
1 基本概念
空间特征代表了空间中不同种类的事物,空间特征在空间位置上的一次出现称为该空间特征的一个实例。给定空间特征集F及其实例集S,S上的空间邻近关系R,即如果两个不同实例之间的欧式距离不大于给定的距离阈值d,则这两个空间实例满足空间邻近关系R.一个co-location模式c(c⊆F)是一组空间特征的集合,c中空间特征的个数称为c的阶(size).如果一个实例集中的任何一个实例都与该实例集中的其他实例满足R关系,则该实例集中的实例形成一个团。如果一个团T’包含了co-location模式c的所有特征,且T’中没有任何一个子集可以包含c中的所有特征,T’称作co-location模式c的一个行实例,所有行实例的集合称为表实例。空间co-location模式挖掘采用参与度PI(Participation Index)来衡量co-location模式的有趣程度,当一个co-location模式c的参与度不小于用户给定的最小参与度阈值min_prev时,称c是频繁co-location模式。
图2给出了一个空间实例分布的例子,包含5个特征A、B、C、D和E,其中A.1表示A特征的第1个实例;该空间共有5个A的实例,4个B的实例,4个C的实例,4个D的实例以及3个E的实例;连线表示两个空间实例满足邻近关系,例如A.1和B.1是互相邻近的。{B.4,C.1,D.2}形成一个团,且是一个3阶co-location模式{B,C,D}的一个行实例。因为再无其他同时包含B,C,D这3个特征的实例形成团,则co-location模式{B,C,D}的表实例为{{B.4,C.1,D.2}}.如果{B,C,D}的参与度大于给定的参与度阈值,则{B,C,D}为频繁co-location模式。

图2 空间实例分布Fig.2 An example neighbor graph
本体这个概念由Gruber提出,他认为本体是对共享概念模型的明确的规范的说明。可以简单地认为本体是领域知识的一种抽象化,把一个领域知识转化为一个概念模型,这个模型里包括了各种类型的概念描述。本体可表示为5元组O={C,E,Z,H,A},其中C是一组本体概念的集合;E是定义在C上的本体概念关系集合;Z是本体概念的实例集;H是一个表示本体概念间包含关系(is-a关系,≤)的有向无环图,如果本体概念C1包含本体概念C2,则C2is-aC1,在H图上则表示为C1指向C2的有向线段;A为加在本体上的额外定理的集合。
本文将本体的概念C分为3种类型,分别为叶概念、广义概念和约束概念,叶概念即为本体H图中的叶节点,广义概念为包含叶概念的概念,约束概念是定义在其他本体概念上的逻辑表达式。
图3为一个本体的H图,其中鸟类和庄稼为约束概念,虚线表示了约束概念之间的映射关系。得到的概念集如下:
所有概念集合:{生物,鸟类,动物,植物,真菌,庄稼,麻雀,松鼠,蛇,麦子,松树,柏树,香菇,树菇}
叶概念集合:{麻雀,松鼠,蛇,麦子,松树,柏树,香菇,树菇}
广义概念集合:{生物,动物,植物,真菌}
约束概念集合:{鸟类,庄稼}
箭头表示了包含与被包含关系,假设z(C)表示本体概念C所包含的本体概念映射,则:
z(生物)={动物,植物,真菌}
z(植物)={麦子,松树,柏树}
z(动物)={麻雀,松鼠,蛇}
z(庄稼)={麦子}
……

图3 本体H图示例Fig.3 An example H of ontology
本文将本体应用到空间co-location模式挖掘,首先将空间特征映射到本体的叶概念,然后利用本体的语义将叶概念分类并在高层提取更加有意义的co-location模式,而不像经典co-location挖掘,仅仅只考虑本体叶概念之间的共生关系。
2 基于本体的候选模式集更新策略
本节主要讨论第一个问题:怎样利用本体来更新候选co-location模式集?包括怎样利用本体度量两个co-location模式之间的语义距离,以及怎样基于这个度量准则更新候选co-location模式集。
2.1 两个co-location模式间的语义距离
本体将一些拥有相似属性的特征聚集成一个类。例如,麦子、松树和柏树它们都属于植物,有着植物的一些共性,于是,本体将它们向上概括成一个“植物”的本体概念。在“植物”这个广义概念下,麦子、松树和柏树是相似的。但在“庄稼”这个约束概念下,麦子、松树和柏树就不是相似的。因此,可以通过本体找到任何一个空间特征的相似特征集。
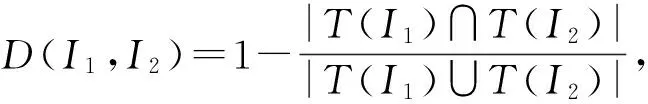
为了更好地解释本文中的相关定义及算法,图4给出了图2的本体H图。图2中的空间特征被映射到图4的叶概念,C4为约束概念,C1,C2,C3和C5为广义概念。

图4 图2的本体H图Fig.4 H of ontology of Fig.2


2.2 候选co-location模式集的更新策略
OIICM每一次交互都会选择一些代表co-location模式提交用户进行选择,用户对这些代表co-location模式做出选择之后,OIICM根据co-location模式间的语义距离,从候选co-location模式集中找到每个代表co-location模式的“相似”模式,以便进行下一步的更新操作。
定义2 给定一个co-location模式c,以及语义距离阈值sdt(semantic distance threshold,简写为s,0≤s≤1),如果存在一个co-location模式c’满足SD(c,c’)≤s,c’被称作是c的相似模式。特别地,如果SD(c,c’)=0,则c’被称作是c的绝对相似模式。
例如,在图4中,co-location模式{A,D}的绝对相似模式集为{{B,D}}.
定义3 如果某个co-location模式c在候选co-location集及代表co-location模式集中均找不到其绝对相似模式,称c为孤立co-location模式。
例如,图4中{A,B}是一个孤立co-location模式。
在一次交互中,用户对代表co-location模式集中的每个co-location模式进行喜好的选择并反馈给OIICM,OIICM得到用户的反馈并从候选co-location模式集中提取每个代表co-location模式的相似模式集。如果用户对某个代表co-location模式c感兴趣,OIICM将c及其所有的相似模式加入结果集,并从候选co-location模式集中移除c的所有相似模式;如果用户对c不感兴趣,则OIICM从候选co-location模式集中移除c的所有相似模式。例如,如果有一个候选co-location模式集合为{{A,B},{A,C},{A,D},{B,C},{B,D},{B,E},{C,D},{D,E},{B,D,E}},语义模式距离阈值为s=0,假设某个代表co-location模式c={A,E},则c的相似模式集为{{B,E},{B,D,E}},如果用户对c感兴趣,则将{B,E}和{B,D,E}加入结果集,并从候选co-location模式集中删除这两个co-location模式,即更新完毕后的候选co-location模式集为{{A,B},{A,C},{A,D},{B,C},{B,D},{C,D},{D,E}};如果用户对c不感兴趣,则将{B,E}和{B,D,E}从候选co-location模式集中删除。
当s设置为0时,每个代表co-location模式c的相似模式c’都是该代表模式的绝对相似模式,它们拥有完全相同的上层语义(G(c)=G(c’)),此时可以完全正确地得到用户感兴趣的co-location模式。
如果s>0,则会产生这样一种情形:对于两个代表co-location模式c1和c2,用户对c1感兴趣但是对c2不感兴趣,在候选co-location模式集中存在一个候选co-location模式c满足SD(c,c1)≤s且SD(c,c2)≤s,即c同时是c1和c2的相似模式。首先,c1和c2不可能同时是c的绝对相似模式,否则就与用户的反馈出现了矛盾。如果c1和c2中有1个是c的绝对相似模式,则c和与其互为绝对相似模式的代表模式的有趣性保持一致,即如果c1是c的绝对相似模式,因为c1是有趣的,所以c是有趣的;如果c1和c2都不是c的绝对相似模式且c不是孤立co-location模式,则c放回候选co-location模式集中不做任何处理;如果c是孤立co-location模式,在这种情况下,为了减少交互次数,c的有趣性取决于与c语义距离最近的代表模式的有趣性,即如果SD(c,c1) 如果某个co-location模式c是孤立co-location模式,则对其有趣度的判定可能会产生错误,其实对于该模式c也可以采用放回候选co-location模式候选集的策略,但是过多的交互次数会加重用户的负担,所以为了减轻用户负担及追求效率舍弃了小部分的准确度。实际上,孤立co-location模式出现的概率比较小,而且这种co-location模式通常是已知的冗余模式,因为这种模式的组成几乎都是同一类的特征,即|G(c)|=1,如图4中的模式{A,B},因此,算法仍能保持高准确率。 算法1给出了每次交互过程中候选co-location模式的更新过程。首先,得到用户对代表co-location模式集的反馈(第1行),如果反馈不为空(第2行),则对每个候选co-location模式集中的co-location模式进行处理(第3-18行):如果代表co-location模式集中包含当前候选co-location的绝对相似模式(第4-5行),则将该模式的有趣度设置为其在代表模式集中绝对相似模式的有趣度(第6行)并删除该候选co-location模式(第7行)。如果代表co-location模式集中不含当前候选co-location模式的绝对相似模式(第8行),则从候选co-location模式集中寻找该候选co-location的绝对相似模式集(第9行),若该集合为空,说明该候选co-location模式是孤立co-location模式(第10行),则从代表co-location模式集中寻找与其语义距离最近的相似模式(第11行),若存在该相似模式Lmp(第12行),则设置该孤立co-location的兴趣度为Lmp的兴趣度(第13行)并删除该候选co-location模式(第14行)。 算法1 更新候选co-location模式集输入:P:包含m个co-location模式的集合sdt:语义距离阈值E:本体中本体概念之间的关系L:代表co-location模式集Fb:用户对代表co-location模式集的反馈变量:Pp:P中模式p的绝对相似模式集Lp:L中模式p的绝对相似模式Lmp:L中与模式p语义距离最小的相似模式步骤:1:Fb=feedback_from_user(L);2:IF(Fb!=null)THEN3: FOREACH(patternpinP)DO4: Lp=find_hard_similar_co-locations(p,L,E,s);5: IF(Lpisnotempty)THEN6: setp’sinterestingnessasLp;7: P.remove(p);8: ELSE9: Pp=find_hard_similar_co-locations(p,P,E,s);10: IF(Pp=null)THEN11: Lmp=find_nearest_co-locations(p,P,E,s);12: IF(Lmp!=null)THEN13: setp’sinterestingnessasLmp;14: P.remove(p);15: ENDIF16: ENDIF17: ENDIF18: ENDFOR19:ENDIF 在最好情况下,每个候选模式都能在代表co-location模式中找到其绝对相似模式。这种情况下,算法不会执行第8行及以后的语句,算法的主要时间消耗在第4句,时间复杂度为O(km).从最好情况和最坏情况的时间复杂度分析可以看出算法1拥有较低的时间复杂度,在用户提交反馈之后能够在短时间内更新候选co-location模式集。 本节主要讨论第二个问题:为了减少交互次数,怎样选择代表co-location模式集?包括最佳模式选择的标准,以及代表co-location模式集的选择策略及算法。 例如,某个co-location模式集合s={{A,C},{B,C,E}},G({A,C})={C1,C2,C4},G({B,C,E})={C1,C2,C3,C4},则s的语义信息量为|G({A,C})∪G({B,C,E})|=|{C1,C2,C3,C4}|=4. 本文给出选择最佳代表co-location模式集的两个标准。第一个标准为选择的代表co-location模式之间应该没有冗余。如果有两个代表co-location模式在模式组成(比如:空间特征)上存在某种相似性(比如:语义相似性),这两个代表co-location模式之间就存在冗余。因为冗余co-location模式之间是相似的,为用户提供冗余的co-location模式会增加交互次数且会增加用户的负担;第二个标准为选择的代表co-location模式集应该包含尽可能多的语义信息量。如果某个co-location模式c={A,D}被选为第一个代表co-location模式,c1={C,D}比c2={A,E}更适合作为第二个代表co-location模式,因为G(c)={C1,C3},G(c1)={C2,C3,C4},G(c2)={C1,C3,C4},c与c1的语义信息量|G(c)∪G(c1)|=|{C1,C2,C3,C4}|=4,c与c2的语义信息量|G(c)∪G(c2)|=|{C1,C3,C4}|=3,c与c1的语义信息量要比c与c2的语义信息量大。 基于这两个标准,本文设计了一个贪心算法来高效地选择代表co-location模式集。贪心的选择策略为当前待选择的代表co-location模式c应该与当前代表co-location模式集组合后语义信息量最大。该贪心策略满足选择最佳代表co-location模式集的两个标准:首先,该算法选择会增加当前代表co-location模式集语义信息量的co-location模式,若选择了冗余模式,代表co-location模式集的语义信息量不会变;其次,该算法选择能最大程度增加当前代表co-location模式集的语义信息量的co-location模式,这与第2个标准完全一致。该策略首先选择包含最多语义信息量的候选co-location模式作为第一个代表co-location模式,因为语义信息量多的模式被用户接受的概率会比较大,接着与第1个代表co-location模式组合后语义信息量最大的候选co-location模式被选定为第2个代表co-location模式,第3个代表co-location模式应该是候选co-location模式集中与前两个代表co-location模式组合后语义信息量最大的co-location模式,以此类推。例如,候选co-location模式集合为{{A,B},{A,C},{A,B,C},{D,E}},每次交互需要选择2个代表co-location模式。则第1个代表模式选择{A,C},因为{A,C}的语义信息量最大(C({A,C})={C1,C2,C4}),第2个代表co-location模式会选择{D,E}(C({D,E})={C3,C4}),因其与{A,B,C}组合之后的语义信息量最大。 算法2给出了代表co-location模式集的选择算法。首先,算法中需要维护一个最大语义信息量的变量max_information用来保存迭代中候选项与当前代表co-location模式集合的最大信息量值,初始为0(第1行),第1个代表co-location模式是候选co-location模式集中包含上层本体概念最多的co-location模式,如果满足条件的co-location模式有多个,则取第一个满足该条件的co-location模式(第2行)。接着用一个repeat-until循环寻找剩下k-1个代表co-location模式(第3-15行)。变量p保存了当前满足贪心策略的co-location模式,将p加入到代表模式集中并从候选co-location模式集中删除p(第4-5行)。接着遍历候选co-location模式集中的每个模式pp(第6行),如果当前候选co-location模式与代表co-location模式集中的任何一个代表co-location模式包含的上层概念是一致的(第7行),则跳过该候选co-location模式(第8行),否则计算该候选co-location模式与代表co-location模式集组合后的语义信息量,如果该语义信息量值大于max_information(第10行),则修改max_information的值并将p指向该候选co-location模式(第11-12行),经过循环,可以保证p指向当前候选co-location模式集中与代表模式集合并后语义信息量最大的候选co-location模式。 算法2 选择代表co-location模式输入:P:包含m个co-location模式的集合k:代表co-location模式集的模式数量E:本体中本体概念之间的关系输出:L:代表co-location模式列表步骤:1:max_information=0;2:patternp=get_maximal_information(P,k,E)3:REPEAT4: L.add(p);5: P.remove(p);6: FOREACH(patternppinP)DO7: IF(have_same_concepts(pp,L))THEN8: CONTINUE;9: ENDIF10: IF(get_infor(L,pp)>max_information)THEN11: max_information=get_infor(L,pp);12: p=pp;13: ENDIF14: ENDFOR15:UNTILL.count>=k 当候选co-location模式集中剩下的模式数量小于需要提交给用户反馈的co-location模式数量时,系统结束交互过程。此时得到的co-location模式集即为结果集,其中存放着系统认为用户感兴趣的co-location模式,这个结果集中的模式数量还可以进一步缩减。本节首先讨论结果集的缩减方法,以保证提交给用户的有趣co-location模式是最简的。然后给出OIICM的整体算法。 因为参与度满足向下闭合性[3],即如果某个co-location模式是不频繁的,那么它的任何超集都不是频繁的。或者,如果某个co-location模式是频繁的,则其任何子集都是频繁的。基于这个性质,本文设计了一个在不遗漏任何语义的前提下进一步缩减结果集的过滤器。 极大co-location模式[6]是co-location模式的一种压缩表示。极大co-location模式是指其任何超集都不可能频繁的co-location模式。例如模式集{{A,B},{A,C},{B,C},{A,B,C}}可以压缩为{{A,B,C}},因为{A,B,C}是频繁的,其任何子集都是频繁的。由于结果集中的每个co-location模式都加入了语义,若只取结果集中的极大co-location模式则可能产生错误结果。例如用户对{A,B,C}感兴趣,用户未必对{A,B}感兴趣,因为{A,B,C}和{A,B}所包含的语义概念是不同的。所以,为了进一步压缩结果集,过滤器需要加一个限定条件:在相同语义环境下的模式集中,求该集合的极大co-location模式不会造成语义的遗漏。 过滤器的过滤过程为:首先,将结果集中的co-location模式按语义分组,每个co-location模式与其绝对相似模式构成一个分组;然后,在每个分组内求其极大co-location模式集;最后,将每个分组内求得的极大co-location模式集进行合并,即得到最终的有趣co-location模式结果集。 例如,若结果集为{{A,C},{B,C},{A,B,C},{A,C,D},{B,C,D},{A,B,C,D}},该结果集的极大co-location频繁模式为{A,B,C,D},但实际上,该结果集包含了2个语义(见图4):{C1,C2,C4}和{C1,C2,C3,C4},所以该结果集按语义分成两组:在语义{C1,C2,C4}组的模式集为{{A,C},{B,C},{A,B,C}},这个模式集的极大co-location模式为{A,B,C};在语义{C1,C2,C3,C4}组的模式集为{{A,C,D},{B,C,D},{A,B,C,D}},这个模式集的极大co-location模式集为{A,B,C,D},所以,经过过滤器之后得到的有趣co-location模式集合为{{A,B,C},{A,B,C,D}}. 算法3给出了OIICM的整体算法描述。首先,系统从本体文件中找到本体概念之间的关系(第1行),在本体概念关系确定之后,开始对候选co-location模式集进行循环地选择代表co-location模式并进行更新操作(第2~9行)。在循环中,如果当前候选co-location模式的数量少于需要提交给用户的模式数量,则系统将所有候选co-location模式作为代表模式集提交用户进行反馈(第3~4行),这也意味着进行最后一次交互,否则,利用第4节给出的算法选择代表co-location模式集(第6行)。用户将对代表co-location模式集的喜好反馈给OIICM,OIICM则利用本体对候选co-location模式集进行更新操作(第8行),这个算法在第3节有详细介绍,需要注意的是更新操作的过程中会将所有有趣的co-location模式全部放在Res中,交互过程结束之后,Res中保存了所有的有趣co-location模式(结果集)。最后,利用过滤器对结果集进行压缩(第10行),并输出最终的有趣co-location模式结果集(第11行)。 算法3 挖掘有趣co-location模式(OIICM)输入:P:包含m个co-location模式的集合k:代表co-location模式集的模式数量sdt:语义距离阈值o:XML形式存放的本体文件变量:E:本体中本体概念之间的关系L:代表co-location模式列表F:用户对代表co-location模式集的反馈输出:Res:有趣co-location模式结果集步骤:1:E=generate_relations_by_ontology(o);2:WHILE(P.count>=0)DO3: IF(P.count<=k)THEN4: L=P;5: ELSE6: L=sample_selection(P,k,E);//算法27: ENDIF8: update_candidtes(P,sdt,E,L,F);//算法19:ENDWHILE10:Res=do_filter(Res);11:output(Res); 前面的章节已经分析了算法1和算法2的时间复杂度,在算法3中,时间消耗主要在第2行到第9行的while循环中。从算法3中可以看出,OIICM整体算法与本体概念的数量及候选co-location模式的语义组成有很大的关系。在极限情况下,即所有候选co-location模式都属于同一个语义组合,即使设置k=1也可以一次将所有的co-location分类,在这种情形下,过滤器就变成了一个简单的极大co-location模式的提取器。 为了更好地分析OIICM算法的效率,假设输入的候选co-location模式一共有n个本体语义组合,则可以近似地认为第2行的while循环将总共执行ceil(n/k)次,其中“ceil(q)”表示取大于某个浮点数q的最小整数,例如ceil(4.2)=5.在算法3中,第3行和第4行最多只执行一次且只在最后一次循环中执行,算法1和算法2的执行次数是近似相同的(最多相差1次),近似为ceil(n/k)次,第10行的时间复杂度为O(w),w为结果集中co-location模式的数量,则算法3的整体时间复杂度为O(ceil(n/k)[(m+k2+n)m]+w).由此可见候选co-location模式所包含的语义个数n对OIICM有着很大的影响,若n≤k,则OIICM执行效率最高,1次交互就可以得到用户感兴趣的co-location模式,若n很大,假设某个本体含有v个非叶概念,则最多可能会产生2v个语义组合,当v比较大的时候,n有可能会等于m,即每个候选co-location之间的语义各不相同,在这种最坏情况下,OIICM的时间效率将会达到O(m3)级别。这个分析是假设没有用户的参与,而实际中,每次交互OIICM都会等待用户的反馈,在两次交互之间的时间复杂度为O(m+nm),OIICM可以在短时间内分析用户的反馈并再次提供代表co-location模式集。 本节将在实际数据和合成数据上验证OIICM的准确率、压缩率和算法有效性。 实际数据下的实验分析主要用来验证OIICM的准确率。 5.1.1 实验设计 实际数据集选取北京市与旅游有关的城市元素分布数据。该数据集包含16个空间特征(标识从A到P),空间实例个数为90 458个,空间范围为18 km×18 km,为了不遗漏稀有的有趣co-location模式,参与度设置为0.1,距离阈值设置为100 m.在此参数设置下共产生947个频繁co-location模式。 实际数据上定义的本体H图如图5所示,在本体H图下方给出了每个概念所代表的具体含义。假设本系统是针对第一次到北京旅游的用户而开发的,那么如果某个用户想知道美食周围是否有一些景点,他可能认为co-location模式{A,B,G}是有趣的,而如果另外一个用户想知道在景点周围是否会有宾馆,他可能会认为co-location模式{D,G}是有趣的。 为了更好地评估OIICM的准确性,用1个模拟过程来进行准确率的度量。一次模拟过程如下:模拟算法首先从图5所示的本体中随机选取2~5个不同广义概念的组合(语义),再在每个语义的指导下从947个频繁co-location模式选择满足该语义的所有co-location模式,最终得到的co-location模式集合即为用户感兴趣的模式集;接着模拟过程启动OIICM开始进行交互,每次的反馈由模拟过程完成:若OIICM提供的代表模式中存在感兴趣的模式,则进行反馈。实验中默认的代表co-location模式集的数量k设置为5,默认的语义距离阈值s设置为0.1.实验中每一个测试项的准确率为10次模拟过程的均值。 图5 实际数据的本体H图Fig.5 H of ontology using real data set 5.1.2 OIICM的准确率分析 图6显示了OIICM在不同k值和s值下的准确率以及与其他算法的比较。在实验中,设置Top-kClosed[7]算法产生所有的闭co-location模式,Order-Clique[6]算法则产生所有的极大co-location模式。在图6(a)中,系统所需的交互次数随着k的增大而减少,例如在k=8时,系统只需要交互4次就可以得到完整的有趣co-location模式集。同时,k=5时系统得到的有趣co-location模式的准确率最高,将近90%,而k=3时交互6次后的准确率为70%左右,这是因为每次提供的代表co-location数目过少,候选co-location模式集更新速度比较慢,交互过程还未完成;而当k=8时最终准确率变少为80%左右,这是因为提供过多的代表co-location模式会有更大机会误判孤立co-location模式。在图6(b)中,随着s阈值的增大,准确率逐渐降低,当s=0时,准确率达到了100%.对于非孤立模式,OIICM对其兴趣度的判断不会出现差错,当s=0时,因为孤立模式不可能有相似模式,每个孤立模式都会被作为代表模式由用户判断,因而需要更多地交互次数,随着s的增大,孤立模式会出现与其相似的代表模式,判错的概率会加大,因为s的增大会使得模式间的语义的关联度降低。在图6(c)中,可以看到单纯地从统计方面压缩co-location模式并不会得到令用户满意的结果。这两种压缩方式都仅仅是从模式组合的角度对结果进行压缩,而没有考虑用户的主观意愿。 图6 OIICM的准确率实验Fig.6 Experiments on accuracy ratio 合成数据下的实验分析主要用来验证OIICM产生的有趣co-location模式相对于原始输入co-location模式集的压缩率、代表模式选择算法的效率、过滤器的压缩效率以及本体非叶概念个数对算法的影响。 5.2.1 实验设计 合成数据的空间范围为10 000*10 000,空间特征个数为50个,空间实例个数为50万个,按照泊松分布来分配每个空间特征下的实例个数,空间实例的位置随机生成,距离阈值为50,参与度阈值为0.15,本体设置了10个广义概念,且每个概念下有5个特征,在这种分布下,产生了1 022 211个频繁co-location模式,用户要在这么多co-location模式中选择感兴趣的模式是几乎不可能的事情,利用OIICM,用户可以在几分钟之内得到感兴趣的模式。在合成实验中默认的代表co-location模式集的数量k设置为15,默认的语义距离阈值s设置为0.1,在某些极限情况下,若某个用户只想知道某几类概念之间的关系,这样选出来的有趣模式可能只有几十个,为了表示一般情况,在每轮的代表模式选取中,至少会选择2个代表模式为有趣模式。因为数据量比较大,为了更快地得到相应的结果信息,在实验过程中,OIICM会模拟用户行为进行代表模式的喜好反馈,且兴趣度选择策略符合本文的语义环境。每一个试验项均进行10次并取平均值。 5.2.2 OIICM压缩率分析 5.2.3 代表模式选择策略的有效性分析 本文的第4节给出了两个代表模式最佳选择标准,并根据这两个标准设计了一个贪心算法寻找最佳代表co-location模式集。本节实验主要用来验证该贪心算法的有效性,并设计了一个随机选择算法来与之进行对比。该随机算法每轮从候选co-location模式集中随机地选择k个模式提交用户进行交互。 图7 OIICM压缩率实验Fig.7 Experiments on redundancy ratio 图8给出了不同k值和s值下两个算法的交互次数。可以明显地看出,贪心算法比随机算法所需要的交互次数要少很多,且贪心算法比随机算法更加稳定。图8(a)中,随着k值的增加,两个算法的交互次数都在减少,这是因为k值越大,代表模式集的语义信息量就越大,就会更多地减少候选co-location模式的数量;图8(b)中随机算法的次数非常不稳定且远高于贪心算法的交互次数。由图8可以看出,贪心算法寻找代表co-location模式是有效的。 图8 贪心算法有效性实验Fig.8 Experiments on the effectiveness of selection strategy 5.2.4 过滤器的压缩效率分析 本节主要验证过滤器的压缩效率。在合成数据的实验中,OIICM在完成交互之后,依然还有将近40万的有趣co-location模式,这同样会给用户的选择带来很大负担。表1给出了合成数据生成的每阶co-location模式的数量和在s=0.1,k=15时通过交互得到的各阶co-location模式的数量以及经过过滤器之后最终得到的co-location模式的数量,在表格中,括号里的百分数表示压缩后的co-location模式数量与原始同阶频繁co-location模式数量的比率。 如表1所示,原始的频繁co-location模式中5阶,6阶和7阶co-location模式占了很大一部分比例,经过OIICM的多次交互之后,低阶co-location模式的压缩率明显要低于高阶co-location模式的压缩率,这是因为低阶co-location模式更容易被加进结果集或者被排除在外,例如{A,B,C,D,E}同属于一个本体概念,如果{A,B,D,E}被用户标识为有趣的,则该集合的所有组合co-location模式都被加入到了结果集之中。而过滤器的压缩效果正好相反,低阶的压缩效果明显高于高阶的压缩效果,这是因为同一语义环境下高阶co-location模式可以代表低阶co-location模式,例如{A,B,C,D,E}同属于一个本体概念,则如果c={A,B,C,D,E}被用户标识为有趣的,则c的全部子集都会被剔除掉。这两个阶段的压缩过程相辅相成,交互过程得到全部满足语义的co-location模式,而过滤器则在此基础上提取出每个语义的极大co-location模式。由表1可以看出OIICM最终的压缩率可以达到99.2%,压缩效果非常明显,有效地减轻了用户的选择负担。 表1 各阶co-location模式数量及占比Table 1 The number and proportion of each order co-location pattern 5.2.5 本体非叶概念数目对算法的影响 4.3节讨论了非叶概念数目v对OIICM算法效率的影响。本节实验主要分析非叶概念数目对OIICM算法效率的影响程度。 在试验中,分别设置本体非叶概念的数量为1,5,10及20,合成数据共有50个特征,按照泊松分布给每个叶概念分配相应的特征。每次交互送给用户代表模式的数量k=15,语义距离阈值s=0.1.实验主要分析不同v值下OIICM交互所花费的时间,而不考虑用户的反馈时间,即实验中得到的时间是每次交互从用户提交反馈到OIICM选择代表co-location模式集提交用户的时间总和。 图9给出了v值对算法的影响,可以看到随着v的增大,OIICM交互所需要的时间也急剧地增加。随着v值的增加,可以生成的语义组合数n(n最多为2v-1)呈指数性地增加,而OIICM的整体复杂度为与ceil(n/k)成正比(见4.3的算法分析),随着n指数性地增加,OIICM的耗时也会呈指数性地增加。图9中,OIICM的耗时与OIICM的时间效率分析保持一致。 图9 v值对算法的影响Fig.9 Efficiency on v value 本文提出了一个基于本体的有趣co-location模式的交互式挖掘方法。不同于之前大多数基于统计信息的挖掘方式,本文利用本体来聚合用户的领域知识,并给出了co-location模式之间语义距离的度量方式,通过语义距离,可以更快地将co-location模式进行分类,快速得到用户真正感兴趣的co-location模式;为了减少交互次数,本文提出了一个高效的贪心算法来“最大化”地提取用户感兴趣的语义;最后设计了一个过滤器可以有效地缩减结果集的数量。对算法的复杂度分析说明了本文提出的算法的高效性。通过大量实验分析并验证了所提方法的高准确率、高压缩率及高效性。 未来,我们将进一步研究本体下的用户交互性问题,对交互方式以及交互算法进行进一步的优化,加入一些约束条件,使得算法可以以更少的交互次数,更快地交互时间挖掘用户感兴趣的co-location相关模式。 [1] HAN J,KAMBER M.Data mining:Concepts and techniques.2nd ed[M].Beijing:China Machine Press,2006. [2] 王丽珍,陈红梅.空间模式挖掘理论与方法[M].北京:科学出版社,2014. [3] HUANG Y,SHEKHAR S,XIONG H.Discovering co-location patterns from spatial data sets:A general approach[J].IEEE Transactions on Knowledge and Data Engineering,2004,16:1472-1485. [4] SILBERPCHATZ A,TUZHILIN A.What makes patterns interesting in knowledge discovery systems[J].Knowledge and Data Eng,1996,8(6):970-974. [5] YOO J,BOW M.Mining top-kclosed co-location patterns[C]∥Proceedings of the IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services.Fuzhou,China,2011:100-105. [6] WANG L,ZHOU L,LU J.An order-clique-based approach for mining maximal co-locations[J].Information Sciences,2009,179:3370-3382. [7] BAO X,WANG L,ZHAO J.Mining top-ksize co-location patterns[C]∥Proceedings of the 2016 International Conference on Computer,Information and Telecommunication Systems.Kunming,China,2016:36-41. [8] XIN D,SHEN X,MEI Q.Discovering interesting patterns through user's interactive feedback[C]∥Proceedings of Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Philadelphia,Pa,USA,2006:773-778. [9] 包旭光,王丽珍,方圆.OSCRM:一个基于本体的空间co-location规则挖掘框架[J].计算机研究与发展,2015,52(Suppl.):74-80. BAO X,WANG L,FANG Y.OSCRM:A framework of ontology-based spatial co-location rule mining[J].Journal of Computer Research and Development,2015,52(Suppl.):74-80. [10] MARINICA C,GUILLET F.Knowledge-based interactive postmining of association rules using ontologies[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(6):784-797. [11] GRUBER T.A translation approach to portable ontology specifications[J].Knowledge Acquisition,1993,5:199-220. [12] GUARINO N.Formal ontology in information systems[C]∥Proceedings of First Int'l Conf Formal Ontology in Information Systems.Trento,Italy,1998:3-15. [13] MAEDCHE A,STABB S.Ontology learning for the semantic web[J].IEEE Intelligent Systems,2001,16(2):72-79. [14] AGRAWAL R,LMIELINSKI T,SWAMI A.Mining association rules between sets of items in LaRPe databases[C]∥Proceedings of ACM SIGMOD.1993:207-216. [15] YOO J,SHEKHAR S.A partial join approach for mining co-location patterns[C]∥Proceedings of the 12th ACM Int'l Workshop on Geographic Information Systems (GIS 04).USA:Washington DC,2004:241-249. [16] YOO J,SHEKHAR S.A joinless approach for mining spatial collocation patterns[J].IEEE Transactions on Knowledge and Data Engineering (TKDE),2006,18(10):1323-1337. [17] GINKEL L,WORDEMAN L.A new join-less approach for co-location pattern mining[C]∥Proceedings of the IEEE International Conference on Computer and Information Technology.2008:197-202. [18] WANG L,BAO Y,LU Z.Efficient discovery of spatial co-location patterns using the iCPI-tree[J].The Open Information Systems Journal,2009,3(1):69-80. [19] FANG Y,WANG L,LU J,et al.A combined co-location pattern mining approach for post-analyzing co-location patterns[C]∥Proceedings of the International Conference on Artificial Intelligence:Technologies and Applications.2016:38-43. [20] SONG D,BRUZA P,HUANG Z,et al.Classifying document titles based on information inference[C]∥Proceedings of the Foundations of Intelligent Systems,International Symposium.Japan:Maebashi City,2003:297-306. [21] SARNOVSKY M,PARALIC M.Text mining workflows construction with support of ontologies[C]∥Proceedings of the International Symposium on Applied Machine Intelligence and Informatics.2008:173-177. [22] JAIN A,DUBES R.Algorithms for clustering data[M].USA:Prentice Hall,1998.2.3 候选co-location模式集的更新算法

2.4 算法分析

3 代表模式集选择策略及算法
3.1 代表co-location模式选择策略

3.2 代表co-location模式选择算法

3.3 算法分析
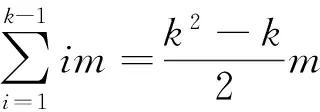
4 过滤器设计及整体算法
4.1 过滤器设计
4.2 OIICM整体算法描述

4.3 算法分析
5 实验评估
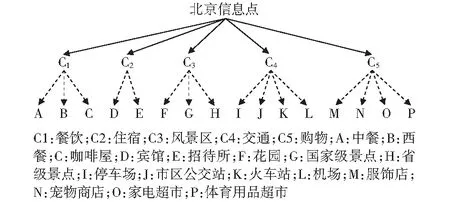
5.1 实际数据的实验分析

5.2 合成数据的实验分析




6 总结
