基于深网图像识别模型的语音认证模式
2018-01-19潘树诚章坚武
潘树诚 章坚武

摘 要:目前,互联网身份认证普遍采用单一的固定密码认证模式,认证安全性非常低,因此迫切需要一种安全系数高又能普及的身份认证方式。声纹作为一种高活性生物特征,用于身份认证具有十分广阔的应用前景。基于深度学习(DL)的语音认证系统包含两个模型:声纹辨别(VI)模型和声纹文本匹配(VTM)模型,都基于卷积神经网络(CNN)。其中,VI模型是一个二分类模型,主要用于确认当前说话人是否为恶意(录音)攻击者;VTM模型是一个多分类模型,主要用来匹配用户预先设定的身份认证信息。通过实验,两个模型在ASVD数据集的识别率分别达到100%和98.3%,相比caffe-net模型,VTM模型的识别率提高了10.8个百分点。
关键词关键词:VI模型;VTM模型;深度学习;卷积神经网络
DOIDOI:10.11907/rjdk.181193
中图分类号:TP301
文献标识码:A 文章编号:1672-7800(2018)010-0022-05
英文摘要Abstract:The current Internet anthentication mode is generally in the form of single fixed passwords with very low security. Therefore it is urgent to have a new anthentication mode with high security and extensive adaptibility. As a highly active biometric feature, voiceprint has broad application prospect in identity anthentication. The vocie anthentication system based on deep learning includes two models:vocie identification model (VI) and vocie text matching model (VTM), which are both based on convolutional neural network (CNN). VI model is a binary-classification model mainly used to confirm if the current speaker is a malicious attacker or a recording. VTM model is a multi-classification model mainly used to match the preset users′ identity anthentication. According to the experiment, the two models achieve 100% and 98.3% recognition rates resepectively in the ASVD dataset. The recognition rate of VTM model has 10.8 percentage increase than that of CaffeNet model.
英文關键词Key Words:VI model; VTM model; deep learning; convolutional neural network
0 引言
在当今移动互联网时代,人与人之间的通信大部分是在线上完成的,比如通话、游戏、购物等。要在线上实现使用者的身份验证,传统的解决方案是通过设置密码,运用系统自带的加解密算法实现身份验证。然而现在网上的应用非常多,如果每个账户都设置一个新密码,显然是不可取的;所有账户都使用一个密码,又保证不了信息安全,很容易被黑客攻击。根本原因是密码验证类似于非生物活性特征的指纹识别验证,是“非活性”、容易被复制的。由于每个人的声纹特征不一致并难以被仿制,采用声纹识别技术可以较好解决上述密码验证安全问题。
近年来,人工智能深度学习技术开始慢慢进入人们的视野,成为当下最热门的话题之一。自从2006年Hinton等[1]提出深度学习(Deep Learning,DL)的概念,并基于深度置信网络(Deep Belief Networks,DBN)提出非监督贪心逐层训练算法以来,国内外掀起了深度学习的研究热潮[2]。2012年6月,斯坦福大学机器学习教授Andrew Ng和大规模计算机系统专家Jeff Dean共同主导了Google Brain项目[3];2014年3月,Facebook的Deep-Face项目基于9层深度网络的人脸识别模型其识别率达到97.35%[4];2016年3月,基于深度学习卷积神经网络的人工智能-Alpha Go大战世界围棋冠军李世石,并以4∶1的战绩取得胜利,举世震惊;2016年10月,硅谷推出的无人驾驶汽车在美国加州正式上路。语音识别技术随着深度学习的热浪得到了高速发展,目前国内外很多公司都在积极推动语音识别技术的应用。亚马逊于2011-2013年相继收购Yap、Evi和Ivona Software,增强语音识别在商品搜索上的技术;Facebook于2013年相继收购Mobile Technologies和Mit.ai,加强了定向广告中的语音技术;苹果于2010-2015年相继收购Siri Inc、Novauris Technologies、VocallQ和Emotient,进一步完善了Siri的功能;微软研发Skype、Contana和微软小冰,其中Contana在Win10系统中应用较为成功;国内华为、阿里巴巴、百度和科大讯飞等互联网、通信巨头也都纷纷在语音识别领域投入巨资进行大量应用性研究。
目前,深度学习技术被广泛应用到各个领域,其中发展最为迅速的属图像领域。图像识别技术被广泛应用到实际生活中,比如支付宝的“刷脸”功能、汽车车牌识别功能及交通人流量的控制功能等。图像识别在大数据分类、统计、识别等方面有很好的效果,但是作为一种非生物活性特征,其安全性系数比较低,所以在安全认证方面有很大的不足。为解决该问题,阿里巴巴提出用户在识别阶段通过多个角度的脸部姿态增加人脸识别的安全性,但是对用户体验有很大的影响。鉴于此问题,本文提出基于语音信号的识别-匹配安全认证模式系统,将语音信号转换成语谱图和声谱图,通过图像分类模型进行分类,并经过系统的二次判决保证认证系统的安全性。结合图像识别技术高识别率和语音特征高生物活性系数两个优点,加强了认证模式的安全性和适用性。
1 认证模式
近年来不断出现单口令密码认证系统被暴力破解[5-6]和字典分析[7]事件,说明单口令密码认证系统的安全系数有待提高。本文针对该问题,提出以表征生物特征活性系数最高的声纹为基础的二次判决识别匹配模式。该模式由3个模块构成:声纹辨别(Voiceprint Identification,VI)模块、短语句文本匹配模块和系统判决模块。
单独的短语句文本匹配VTM模型在原声和录音声的多分类任务中效果不是很理想,而聲纹辨别VI模型和VTM模型分别在二分类问题及多分类问题上有很好的表现。首先将转换后的语谱图数据输入二分类VI模型,分析模型输出数据并传递参数给下一个环节,如果识别失败,系统输出为警报状态,反之则进入短语句匹配模块。再将转换后的声谱图数据送入VTM模型,分析模型输出数据并传递参数给系统输出。
1.1 声纹特征优势
声纹[8-10]是一种“活性”系数非常高的生物非表征特征,具有很广泛的应用。在安全性方面,具有其它生物特征不具备的优势,其它一些生物特征如人脸、指纹、掌型、指静脉和虹膜等都属于表征特性,很容易被复制并落入第三方手中,而声纹作为一种非表征特性,具有无法被完全复制的特点。在实用性方面,语音信号采集只需要一个录音模块,移动终端都具备该功能,所以声纹识别的应用价值非常高。声纹特征与其它生物特征比较如表1所示[11]。
1.2 CNN模型介绍
深度学习技术在语音、图像领域得到了快速发展。一些基于深度学习的识别模型渐渐取代了以UBM-MAP-GMM[12]模型(Douglas Reynold)、Joint Factor Analysis[13-16]模型(Patrick Kenny)和i-vector[17-18]模型(NajimDehak)为代表的传统识别模型。在语音领域,递归神经网络[19-21](RNN、DRNN、LSTMs)模型因为具有时序上元素关联程度的表达能力,在语音长文本识别中大放异彩。在图像领域,卷积神经网络[22-25](CNN)模型因为具有局部感知区域、权值共享的优势,在图像处理方面取得了非常大的成功。
识别验证系统需要短时、安全的识别模式,要求系统能够快速获得短语音的识别结果,而RNN模型对短语音识别效果不是很理想。鉴于CNN模型在图像领域的巨大成功,本文借用图像处理的方式进行语音识别。系统中用到了两个模型:Binary-Classification(二分类)声纹辨别模型和短文本匹配(Phrase-Matching)模型,都属于卷积神经网络(CNN)模型。
CNN模型可分为输入层、卷积层、池化层、softmax分类层、全连接层以及输出层,其中核心层是卷积(convolution)层和池化(pooling)层,属于隐层。卷积层通过调整卷积核的大小和卷积步长,可以大大减少模型网络的节点参数,提高模型的效率;池化层通过调整池化核的大小和模式进一步减少模型参数,并能够锐化图像特征。多层CNN模型一般都是由多个卷积层和池化层组合构成的(见图2)。
CNN模型结构中有3个要素:局部感知域、权值共享及pooling。该3个要素是卷积神经网络的核心思想,也是卷积神经网络能够在图像领域被广泛应用的关键。
1.2.1 局部感知域
CNN模型的每个卷积层中,都会有不同的卷积核窗口对输入图像进行局部卷积,并将结果作为下一层的输入图像,如图3所示。图3中前一层的绿色区域被称作局部感知域,大小由卷积核窗口的大小决定。每个局部感知域通过卷积核窗口映射到下一层的一个神经元。
1.2.2 权值共享
在卷积层中,卷积核需要对整个输入图片进行局部感知域的卷积扫描,卷积核内的值与bias值被称为该卷积核的权值。权值共享就是用同一个卷积核扫描整个图片,它有两个很重要的作用:其一,能够大幅度减少输出训练参数,从而大幅度减少计算量;其二,能够提取到无关特征位置的图片底层边缘特征,解决目标特征空间位置变换的问题(见图4)。
1.2.3 pooling层
pooling层的主要功能是聚化图像特征、减少训练参数以及保持图像(平移、旋转、尺度)不变性。常见的池化方法有均值池化法和最大值池化法,并且池化窗口一般不会重叠。本文采用最大值池化法处理卷积后的图片(见图5)。
1.3 VI模型
声纹辨别是指通过语音频谱图信号确定说话人的身份信息。本系统中的声纹辨别模块采用一个二分类模型,主要作用为检测是否有攻击性录音信号与确定是否为目标说话人。这个模型的输出结果为3类:一是检测是否有攻击性录音信号,如果有则系统发出安全预警;二是确认是否为目标说话人,如果是则进入下一环节;三是判断是否非前两类,如果是则提示重新输入。该模型由8层卷积神经网络构成。
2 实验及结果分析
实验中,训练数据采集方法如下:在实验室环境下,一个人说10个短语音片段,每个短语音片段分别说10次(训练)+1次(系统测试),分成10类;在采集该110个语音信号的同时,用另一个录音设备将其录下来,再经过麦克风播放并用同一个设备第二次采集,得到新的110个语音信号;第三次采集10个非本人发音的语音片段,就得到了200个训练数据和30个系统测试数据。本次实验中两个模型训练数据和测试数据,比例都是4∶1,即160个模型训练数据和40个模型测试数据。30个系统测试数据则通过任务要求进行不同的搭配,实现系统的性能测试。
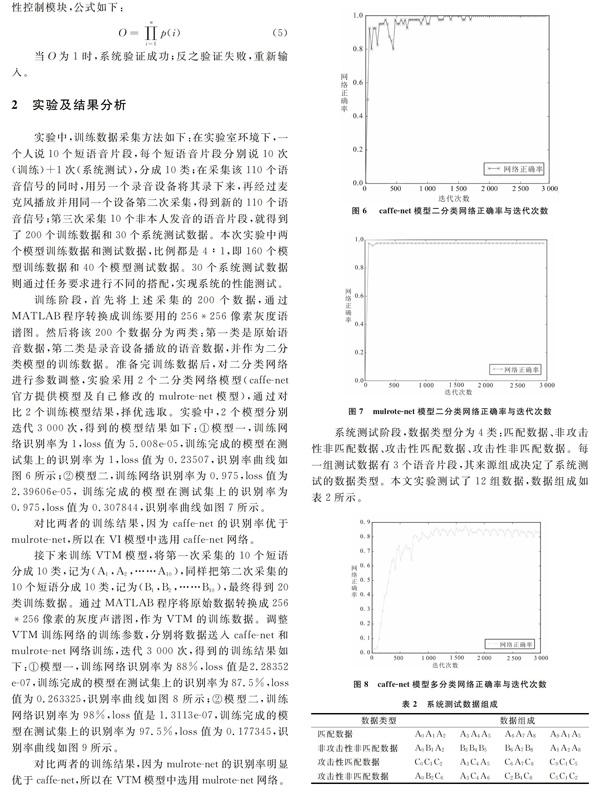
训练阶段,首先将上述采集的200个数据,通过MATLAB程序转换成训练要用的256*256像素灰度语谱图。然后将该200个数据分为两类:第一类是原始语音数据,第二类是录音设备播放的语音数据,并作为二分类模型的训练数据。准备完训练数据后,对二分类网络进行参数调整,实验采用2个二分类网络模型(caffe-net官方提供模型及自己修改的mulrote-net模型),通过对比2个训练模型结果,择优选取。实验中,2个模型分别迭代3 000次,得到的模型结果如下:①模型一,训练网络识别率为1,loss值为5.008e-05,训练完成的模型在测试集上的识别率为1,loss值为0.23507,识别率曲线如图6所示;②模型二,训练网络识别率为0.975,loss值为2.39606e-05, 训练完成的模型在测试集上的识别率为0.975,loss值为0.307844,识别率曲线如图7所示。
对比两者的训练结果,因为caffe-net的识别率优于mulrote-net,所以在VI模型中选用caffe-net网络。
接下来训练VTM模型,将第一次采集的10个短语分成10类,记为(A1,A2,……A10),同样把第二次采集的10个短语分成10类,记为(B1,B2,……B10),最终得到20类训练数据。通过MATLAB程序将原始数据转换成256*256像素的灰度声谱图,作为VTM的训练数据。
调整VTM训练网络的训练参数,分别将数据送入caffe-net和mulrote-net网络训练,迭代3 000次,得到的训练结果如下:①模型一,训练网络识别率为88%,loss值是2.28352e-07,训练完成的模型在测试集上的识别率为87.5%,loss值为0.263325,识别率曲线如图8所示;②模型二,训练网络识别率为98%,loss值是1.3113e-07,训练完成的模型在测试集上的识别率为97.5%,loss值为0.177345,识别率曲线如图9所示。
对比两者的训练结果,因为mulrote-net的识别率明显优于caffe-net,所以在VTM模型中选用mulrote-net网络。
系统测试阶段,数据类型分为4类:匹配数据、非攻击性非匹配数据、攻击性匹配数据、攻击性非匹配数据。每一组测试数据有3个语音片段,其来源组成决定了系统测试的数据类型。本文实验测试了12组数据,数据组成如表2所示。
3 结语
在被称为“第三次技术革命”的互联网时代,安全是最重要的一个环节。本文结合深度学习图像知识和声纹特征,在安全识别方面提出了一个解决方案。实验采用一种“活性”系数非常高的生物特征——声纹,因为其原始数据不能被无失真地保存下来,所以安全性非常高。也因为该特性,语音在安全领域具有很大的研究价值,同时也有很多技术难题。本实验使用的数据都是在实验室环境下采集的,并手动截取高能量语音区间,弱化了外界干扰对数据的影响。而在实际应用中,语音信号采集不可避免会受到不同程度的外界干扰。
接下来可以研究自动分离语音信息能量集中区间和外界噪音区间,并通过噪音分析对分离出来的有效语音区间部分进行去噪处理。这一技术将会对语音的实际应用起到关键性作用。
参考文献:
[1] LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7553):436-444.
[2] HINTON G E,OSINDERO S,TEH Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2014,18(7):1527-1554.
[3] HALLIE S.The man behind the google brain: andrew NG and the quest for the new AI[EB/OL].https://www.wired.com.
[4] JOHANNES B,CHRISTIAN E.Face recognition with deep learning for mobile applications [EB/OL].http://informatikprojekt.de.
[5] VAITHYASUBRAMANIAN S,CHRISTY A.An analysis of CFG password against brute force attack for web applications[J].Contemporary Engineering Sciences,2015,8(9):367-374.
[6] 郭鳳宇,钱怡.一个密码暴力破解系统的设计[J].网络与信息,2009(8):30-31.
[7] VISHWAKARMA D,MADHAVAN C E V.Efficient dictionary for salted password analysis[C].IEEE International Conference on Electronics,Computing and Communication Technologies,2014:1-6.
[8] KERSTA L G.Voiceprint identification[J].Nature,1962,196(4861):1253-1257.
[9] KANE J A.Voice print recognition software system for voice identification and matching[P].US,US8595007B2.2013-11-26.
[10] LI L,LIN Y,ZHANG Z,et al.Improved deep speaker feature learning for text-dependent speaker recognition[C].Signal and Information Processing Association Summit and Conference,2015:426-429.
[11] 方植彬.信息与通信网络安全技术——生物识别技术[J].电子产品可靠性与环境试验,2014,32(5):55-61.
[12] SHEN Y,YANG Y.A novel data description kernel based on one-class SVM for speaker verification[C].IEEE International Conference on Acoustics,Speech and Signal Processing,2007:489-492.
[13] CHOW D,ABDULLA W H.Robust speaker identification based perceptual log area ratio and Gaussian mixture models[C].International Conference on Interspeech,2004:1761-1764.
[14] HEBERT M.Text-dependent speaker recognition[M].Springer Berlin Heidelberg,2008.
[15] VOGT R J,LUSTRI C J, SRIDHARAN S .Factor analysis modeling for speaker verification with short utterances[J].Journal of Substance Abuse Treatment,2008,10(1):11-16.
[16] VOGT R, BAKER B, SRIDHARAN S.Factor analysis subspace estimation for speaker verification with short utterances[C].Brisbane:Interspeech,Conference of the International Speech Communication Association,2013.
[17] KANAGASUNDARAM A, VOGT R, DEAN D,et al.I-vector based speaker recognition on short utterances[C].Florence:Annual Conference of the International Speech Communication Association,2011.
[18] LARCHER A,BOUSQUET P M,KONG A L,et al.I-vectors in the context of phonetically-constrained short utterances for speaker verification[C].IEEE International Conference on Acoustics,Speech,and Signal Processing,2012:4773-4776.
[19] KOUTNK J,GREFF K,GOMEZ F,et al.A clockwork RNN[J].Computer Science,2014:1863-1871.
[20] JAIN A,ZAMIR A R,SAVARESE S,et al.Structural-RNN: deep learning on spatio-temporal graphs[C].Las Vegas: IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016.
[21] TAI K S,SOCHER R,MANNING C D.Improved semantic representations from tree-structured long short-term memory networks[J].Computer Science,2015,5(1): 36.
[22] SHIN H C,ROTH H R,GAO M,et al.Deep convolutional neural networks for computer-aided detection: CNN architectures,dataset characteristics and transfer learning[J].IEEE Transactions on Medical Imaging,2016,35(5):1285-1298.
[23] ABDULNABI A H,WANG G,LU J,et al.Multi-task CNN model for attribute prediction[J].IEEE Transactions on Multimedia,2016,17(11):1949-1959.
[24] RADENOVIC′,TOLIAS G,CHUM O.CNN image retrieval learns from BoW: unsupervised fine-tuning with hard examples[C].European Conference on Computer Vision,2016:3-20.
[25] YAN Z,ZHANG H,PIRAMUTHU R,et al.HD-CNN: hierarchical deep convolutional neural networks for large scale visual recognition[C].IEEE International Conference on Computer Vision,2016:2740-2748.
(責任编辑:何 丽)
