一种基于数据一致性的记录比较方法
2018-01-18冉德彤游宏梁
冉德彤,游宏梁
(中国国防科技信息中心北京1001421)
实体分辨(Entity Resolution)中,记录比较的准确性直接影响能否准确、完整地识别相似重复记录,如何得到更为准确的记录比较结果一直是相关领域的研究热点[1-2]。
传统的记录比较方法又被称为基于特征的方法(Feature-Based Similarity methods,FBS methods)[3-4],该方法将记录看作属性的集合,逐属性地进行比较,以得到记录对的相似度向量[5-6]。有研究表明,FBS方法中的相似度算法一般存在适用范围[7],而选择最合适的算法又是NP难问题[8],故准确相似度的获取成为了一个难题。
针对该问题,文献[8]提出了依据训练数据选择最优算法的方法,但该方法依赖训练数据,在实际应用中获取难度较大。文献[9]提出了相似度调整的算法,利用数据集中的函数依赖关系调整相似度,以提高结果的准确性。然而,该算法以标准的函数依赖为基础,所能表达的约束条件有限,当数据集中的约束超出其表达范围时无法进行调整。
针对记录比较的准确性问题,本文利用数据集中的条件函数依赖(Conditional Functional Dependencies,CFDs)关系,提出了一种基于数据一致性的记录比较方法(Consistence-Based Similarity method,CBS方法)。介绍了条件函数依赖的概念,所提方法的总体思想及关键步骤,并给出了实验过程和结果。
1 CFDs的基本概念
条件函数依赖是函数依赖的扩展,可表达更为具体的约束关系,是数据一致性研究中的一个重要概念[10-12]。下面介绍其定义。
定义1条件函数依赖的符号表示(CFDs Syntax)[13]。对于关系模式R,R上的一个条件函数依赖可记作φ:(R:X→Y,Tp),其中,1)用attr(R)表示R的属性集合,X,Y∈attr(R);2)R:X→Y表示一个标准的函数依赖;3)Tp是X、Y间的模式组(pattern tableau),由若干条模式元组tp构成,∀A∈X⋃Y,tp[A]定义了属性A的取值,既可以是A定义域中的某个常数a,也可以定义域中的任意值(用"_"表示)。
根据定义1,标准的函数依赖可看作CFDs的一个特例。此外,对属性值有限制的约束也可用CFDs表达。
定义2条件函数依赖的语义(CFDs Semantics)[13]。给定一个CFD:φ:(R:X→Y,tp),若实例I中任意两个数据元组t1,t2都满足如下条件,那么称I满足φ。其中,"Ⓒ"是匹配符号,表示数据元组t与模式元组tp相匹配。为方便描述,下文将数据元组的属性集X称为左部,属性集Y为右部。

根据定义2,CFDs的违例检测可利用SQL语句,查询不满足条件的数据元组来完成。给定一个CFD:φ:(R:X→Y,tp),其违例的查询分为以下两步进行[13]:
1)检测单元组违例(single-tuple violations),即当tp[Y]=a时,查询左部与tp匹配,而右部与tp不匹配的数据元组t。这样检测出的每个违例是一条记录。
2)检测多元组违例(multi-tuple violations),即当tp[Y]="_"时,查询左部与tp匹配,而右部不相等的数据元组集合。此时的每个违例是一组记录。
2 结合数据一致性的记录比较
本文将以数据一致性为依据获得的属性相似度简称为基于一致性的相似度(Consistence-Based Similarity,CBS),并将其定义如下:
定义3基于一致性的相似度(CBS)。给定一个CFD:φ:(R:X→Y,tp),若两条记录t1,t2左部与tp相匹配,说明其右部t1[Y],t2[Y]有一定概率是匹配的,将这一概率称为基于一致性的相似度CBS。
由定义3可知,对于一致性违例的右部属性,可依据其对应的左部属性计算出CBS。CBS的优势在于其不受右部属性中错误和变体的影响,当所选择相似度算法处理错误的能力不足时,结合CBS进行记录比较有利于得到更准确的相似度向量。
结合数据一致性进行记录比较的基本思想如下:依据条件函数依赖发现数据集中的一致性违例,计算违例中右部属性的CBS,并与传统记录比较得到的相似度向量相结合,即可得到结合了数据一致性信息的记录比较结果。
2.1 记录比较中的一致性检测
第1节介绍了修复数据一致性时检测一致性违例的方法,但该方法没有考虑到数据集中存在的错误,仅查询t1[X]=t2[X]Ⓒtp[X]会降低一致性检测的完整性。对此,本文在一致性检测中引入了近似匹配符"≈θ"[14]。"≈θ"的含义是若两个属性值的相似度不低于阈值,则认为两属性值匹配。特别的,当ti[X]与tp[X]比较时,若tp[X]取值为"_",则认为两个值匹配。这里的相似度可通过FBS的方法进行度量。
用Qφ表示基于近似匹配符的一致性检测方法,其语句如图1所示。图1中,V是FBS方法得到的相似度矩阵,每一行都是两条记录t1,t2的相似度向量;φ:(R:X→Y,tp)是给定的CFD,θ是近似匹配阈值。
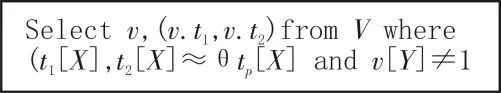
图1 记录比较中的一致性违例查询
经Qφ检测出的违例以二元组{相似度向量,记录对id}的形式表示,接下来需计算这些记录对的右部CBS。
2.2 CBS的计算
先考虑一个简单的情况。给定两条记录t1,t2和φ(:R:B→A,(_||_||_)),在t1[B]≈θt2[B]的情况下,一般可认为t1[B],t2[B]相似度越高,t1[A],t2[A]越有可能描述同一属性值。此时,可将t1[B],t2[B]的FBS作为t1[A],t2[A]的一致性相似度。用sf表示两个属性的FBS相似度,sc表示两属性的一致性相似度,可得到公式(1):

现实数据中,很多CFDs的左部是一个属性集合,此时由于存在多个FBS,计算一致性相似度需要对公式进行扩展。
定义2说明,对于φ:(R:X→Y,tp),当X所有属性都满足tp时,可判断t1[Y],t2[Y]描述同一属性值。故可以认为,t1[Y],t2[Y]相似的概率等于X中所有属性同时满足tp的概率。由此,本文提出公式(2),计算一致性违例记录对中属性Y的CBS。

公式(1)可看作公式(2)的特殊情况,当X中仅有一个属性时,两公式计算结果相同。此外,当记录对(t1,t2)满足多个φ时,属性对(t1[Y],t2[Y])可能会得到多个CBS。对此,本文认为:若(t1,t2)近似满足多个φ,说明有多个依据同时支持(t1[Y],t2[Y])的一致性,其 CBS应较高。因此,当(t1[Y],t2[Y])对应多个CBS时,取其中最大值作为属性对的一致性相似度,即公式(3)。其中,Sc是根据不同φ计算所得的sc集合。

2.3 加权公式
在一个CFD的多元组违例中,可能存在CBS和FBS冲突的情况:当两条记录的左部与tp匹配时,从数据一致性的角度看,其右部很有可能在描述同一属性值,可推断右部属性的相似度较高;但作为一致性违例,其右部不与tp匹配,可能会由于相似度算法的局限性得到较低的相似度。
在上述情况下,并不能保证CBS更为准确。例如,存在右部属性并非描述同一属性值,但因左部属性中存在拼写错误,使二者CBS较高的情况。此时,或可结合两种相似度度量方式,提高结果的稳定性。
基于上述考虑,本文提出通过线性加权来结合CBS和FBS的公式,以提升结果的稳定性,具体如公式(4)所示:
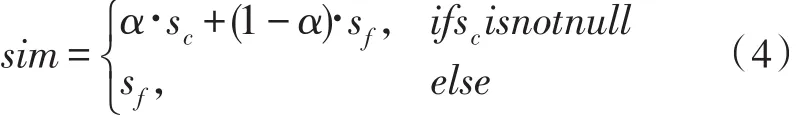
其中,α是CBS的权重。由于两条记录左部不满足tp时,没有依据判断右部的一致性,故此时只计算sf。
2.4 方法流程
如图2所示,基于数据一致性的记录比较方法(即CBS方法)流程分为4步:首先,使用传统的FBS方法进行记录比较:通过选定的相似度算法,逐属性地计算候选记录对的相似度向量,得到相似度矩阵Vf;然后,在Vf中执行查询Qφ,检测其中的一致性违例;第三,依据公式(2)和公式(3)计算一致性违例中右部属性的CBS;最后,依据公式线性加权CBS和FBS,得到结合一致性信息的记录比较结果。

图2 基于数据一致性的记录比较方法
下面分析CBS方法的时间复杂度。在图2的第2步中,对每个φ,CBS方法都需要查询一次相似度矩阵,故发现所有违例的时间复杂度为O(n|Vf|),其中n是φ的数量,|Vf|是Vf的规模。在第3步中,对每个检测出的一致性违例都需要进行一次线性加权计算和赋值,最坏情况下要进行|Vf|次,故此阶段时间复杂度为O(|Vf|)。综上,CBS方法时间复杂度为O(n|Vf|),所需时间和Vf的规模成线性关系。
3 实验分析
本文从两个方面对CBS方法进行了验证:1)效果验证,相比传统的FBS方法,CBS方法得到的相似度矩阵是否有助于获得更高的准确率(Precision)、召回率(Recal)和F值(f-score);2)效率验证,CBS方法比FBS方法多了一致性检测、计算CBS、线性加权3个步骤,这对记录比较的时间有多大影响。
3.1 实验设置
与文献[15,16]类似,实验使用实际数据"DBLPACM"进行测试。该数据为采自DBLP和ACM的文献记录,数据量分别为2 616、2 294条,两来源间有2 224条记录是相互重复的。
测试数据中,每条文献由 title,authors,venue,year 4个属性组成。易知数据中存在两个条件函数依赖:一篇文献只能在一个刊物上发表,出版方会尽量避免自己刊物上的文献重名。本文在实验中利用这两个条件函数依赖计算CBS,如φ1、φ2所示:

3.2 效果验证
首先测试CBS方法对实体分辨结果的影响。实验中以常用的Jaro-Winkler算法计算相似度,取α和θ的值为0.8、0.85,可得到图3的结果。
由图3可知,在相同匹配阈值下,CBS方法的准确率、召回率及F值均优于FBS方法,说明结合一致性信息进行记录比较可提升结果的准确性。但是,当取较低的记录匹配阈值(0.65以下)时,CBS方法的3个指标与FBS方法差距不大,这是由于一致性相似度需要在记录对左部属性的相似度均不低于θ时计算,而满足这一条件的记录对整体相似度不会太低,说明CBS方法对FBS较低的记录对处理能力存在不足。
3.3 效率验证
设置α和θ分别为 0.8、0.85,随机选取 0~3×105,以5×104为单位递增的记录对,比较CBS方法在不同规模数据中消耗的时间,可得到图4。

图3 两种方法效果对比
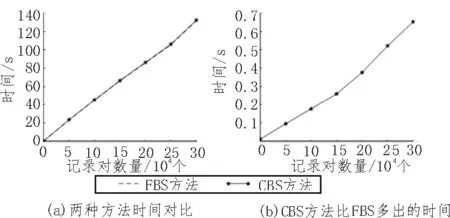
图4 两种记录比较方法运行时间对比
由图4可知,两种方法的运行时间较为接近,说明FBS方法耗时较长,而CBS方法在此基础上增加的时间较短,且基本呈线性增长。这表示在传统FBS方法的基础上使用CBS方法不会额外消耗过多时间。
4 结论
为更好地处理属性值的表述不一致,本文提出了一种基于数据一致性的记录比较方法。通过条件函数依赖,该方法可以利用更为丰富的约束条件。公开测试数据集中的实验结果显示,所提方法在准确率、查准率、F值上均优于传统方法,且不会额外消耗过多时间。但是,实验中也发现CBS方法对相似度过低的记录对处理能力不足,这在进一步的研究中还有待改进。
[1]Papadakis G,Ioannou E,Niederée C,et al.Efficient entity resolution for large heterogeneous information spaces[C]//Proceedings of the Proceedings of the fourth ACM internationalconferenceon Web search and data mining,2011,ACM,535-544.
[2]Papadakis G,Ioannou E,Niederée C,et al.To compare or not to compare:making entity resolution more efficient[C]//Proceedings of the Proceedings of the International Workshop on Semantic Web Information Management,2011,ACM,3.
[3]Zitnik S,Subelj L,Lavbic D,et al.General Context-AwareData Matching and Merging Framework[J].Informatica,2013,24(1):119-152.
[4]Nuray-Turan R,Kalashnikov D V,Mehrotra S.Adaptive connection strength models for relationship-based entity resolution[J].J Data and Information Quality,2013,4(2):1-22.
[5]Leitao L,Calado P,Herschel M.Efficient and effective duplicate detection in hierarchical data[J].Ieee Transactions on Knowledge And Data Engineering,2013,25(5):1028-1041.
[6]谭明超,刁兴春,曹建军.实体分辨研究综述[J].计算机科学,2014,41(4):9-12,20.
[7]Paradies M,Malaika S,Siméon J,et al.Entity matching for semistructured data in the Cloud[C]//Proceedings of the Proceedings of the 27th Annual ACM Symposium on Applied Computing,2012,ACM,453-458.
[8]Wang J,Li G,Yu J X,et al.Entity matching:How similar is similar[J].Proceedings of the VLDB Endowment,2011,4(10):622-633.
[9]谭明超,刁兴春,曹建军,等.一种基于函数依赖的属性相似度调整算法[J].上海交通大学学报,2015(8):1075-1083,1089.
[10]耿寅融,刘波.基于条件函数依赖的数据库一致性检测研究[J].计算机工程与应用,2012(3):122-125.
[11]李建中,刘显敏.大数据的一个重要方面:数据可用性[J].计算机研究与发展,2013,50(6):1147-1162.
[12]Saha B,Srivastava D.Data quality:The other face of big data[C]//Proceedings of the 2014 IEEE 30th International Conference on Data Engineering,2014,IEEE,1294-1297.
[13]Fan W,Geerts F,Li J,et al.Discovering conditional functional dependencies[J].Ieee Transactions on Knowledge And Data Engineering,2011,23(5):683-698.
[14]LiW, LiZ, Chen Q, etal.Discovering Approximate Functional Dependencies from Distributed Big Data[C]//Proceedings of the asiapacific web conference,2016,Springer,289-301.
[15]Xin J,Cui Z M,Zhao P P,et al.Active transfer learning of matching query results across multiple sources[J].Frontiers of Computer Science,2015,9(4):595-607.
[16]Ferreira A A,Gonçalves M A,Laender A H.A brief survey of automatic methods for author name disambiguation[J].Acm Sigmod Record,2012,41(2):15-26.
