关系数据库关键字查询结果排序方法
2018-01-15王瑛琦周连科王念滨
王瑛琦, 周连科, 王念滨
(哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
随着关系数据库中信息量的快速增长,访问、查询关系数据库成为人们获取信息的重要途径之一[1]。关键字查询以其简单易用的特点受到广泛关注,相比于传统的结构化查询方法(如SQL查询),该方法不需要用户了解复杂的查询语言和数据库底层模式,为用户查询带来诸多便利[2-3]。然而,关键字查询作为一种模糊查询方法,并不能精确地锁定数据库中与用户需求最相关的信息,而是将包含查询词的所有元组(元组单元)返回给用户。用户需要在大量查询结果中进一步筛选出自己所需要的信息。因此,按照重要性及相关性对查询结果进行排序显得尤为重要,成为关系数据库关键字查询领域的重要组成部分和研究热点之一[4]。
近年来,一些学者已经对该领域进行初步研究,并提出多种关系数据库关键字查询结果排序方法。例如,Vagelis Hristidis等[5]提出一种简单且直接的排序方法,根据查询结果所包含的元组数对结果进行排序。该方法虽然简单但排序准确率较低。Liu Fang等[6]在此基础上将信息检索中成熟的相关性排序机制引入关系数据库中,进一步提高排序准确率。然而,随着排序结果的影响因素不断增多,排序函数日趋复杂。关于影响因子权重的调节缺少一种理论化指导方案,需要在大量实验和经验积累的基础上手动进行设置。因此,排序模型的准确率受到人为因素和实验环境等外界条件的影响。与此同时,学习排序作为一种新兴排序方法在信息检索和机器学习领域得到了广泛应用[7]。该方法基于训练数据集,使用机器学习算法自动化排序过程。相对于传统排序方法而言,该方法避免了定义排序函数所需要的人力劳动并使排序模型在效率和准确率方面均有显著提高。受到信息检索中学习排序方法的启发,Joel Coffman等[8]将学习排序方法SVM Rank应用到关系数据库关键字查询结果排序领域。然而,该方法也存在较为突出的问题。首先,SVM Rank是一种典型的虚拟文档对级排序方法[9],并未考虑到排序是对一列虚拟文档的预测工作;其次,当面对海量训练数据时,该方法的训练过程需要大量时间开销。因此算法的效率和准确率均存在较大的提升空间[10]。
在上述研究的基础上,本文将学习排序模型引入关系数据库领域,并作进一步的改进与完善,提出一种基于虚拟文档列表的并行学习排序方法Parallel AdaRdbRank-Hierarchy(PARR-H)用以解决关系数据库关键字查询结果的排序问题。
1 基于虚拟文档列表的学习排序算法
算法ARR-H是一种虚拟文档列表级的学习排序算法,与文献[8]中基于虚拟文档对的算法相比,该算法充分考虑虚拟文档间的序列关系并直接对虚拟文档列表进行优化,因此在排序模型的准确率方面有了较大提高。另外,该算法使用分层的弱排序器构建策略:首先,根据特征的重要性及特征间的相似性,使用贪婪算法构建候选弱排序器集合Sk;其次,根据候选弱排序器的排序性能从集合Sk中选取得分最高的候选弱排序器作为本次迭代的弱排序器。使用以上分层思想构建弱排序器,能够有效地避免冗余弱排序器的产生。具体实现如算法1所示。
算法1ARR-H

输出:f(x)=fT(x);
步骤:
1)初始化D(i)=1/n,S0=φ;

5)Fori=1 tokdo

7)E(xj)←E(xj)-A(xgxj)*2c,j≠g
8)Si=Si-1∪{xg},Gi=Gi-1{xg};
9)EndFor
10)Fort=1 toTdo
11)计算
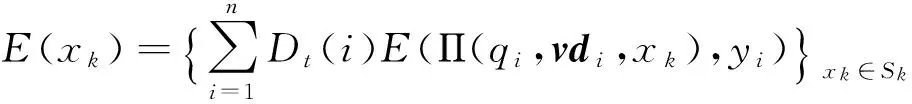

13)选择∂t
14)

15)构建ft
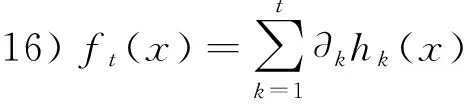
17)更新D(t+1)
18)

19)EndFor
20)输出排序模型:f(x)=fT(x);
算法ARR-H采用虚拟文档列表级的学习排序思想,同时结合分层弱排序器构建策略,初步解决了关系数据库关键字查询结果的排序问题。然而,随着训练样本规模的不断扩大,该算法的训练效率面临严峻挑战,需要对以上算法作进一步改进,以提高算法的效率。因此,提出并行学习排序算法PARR-H。
2 并行学习排序算法
在算法ARR-H的基础上,加入并行框架如图1所示。
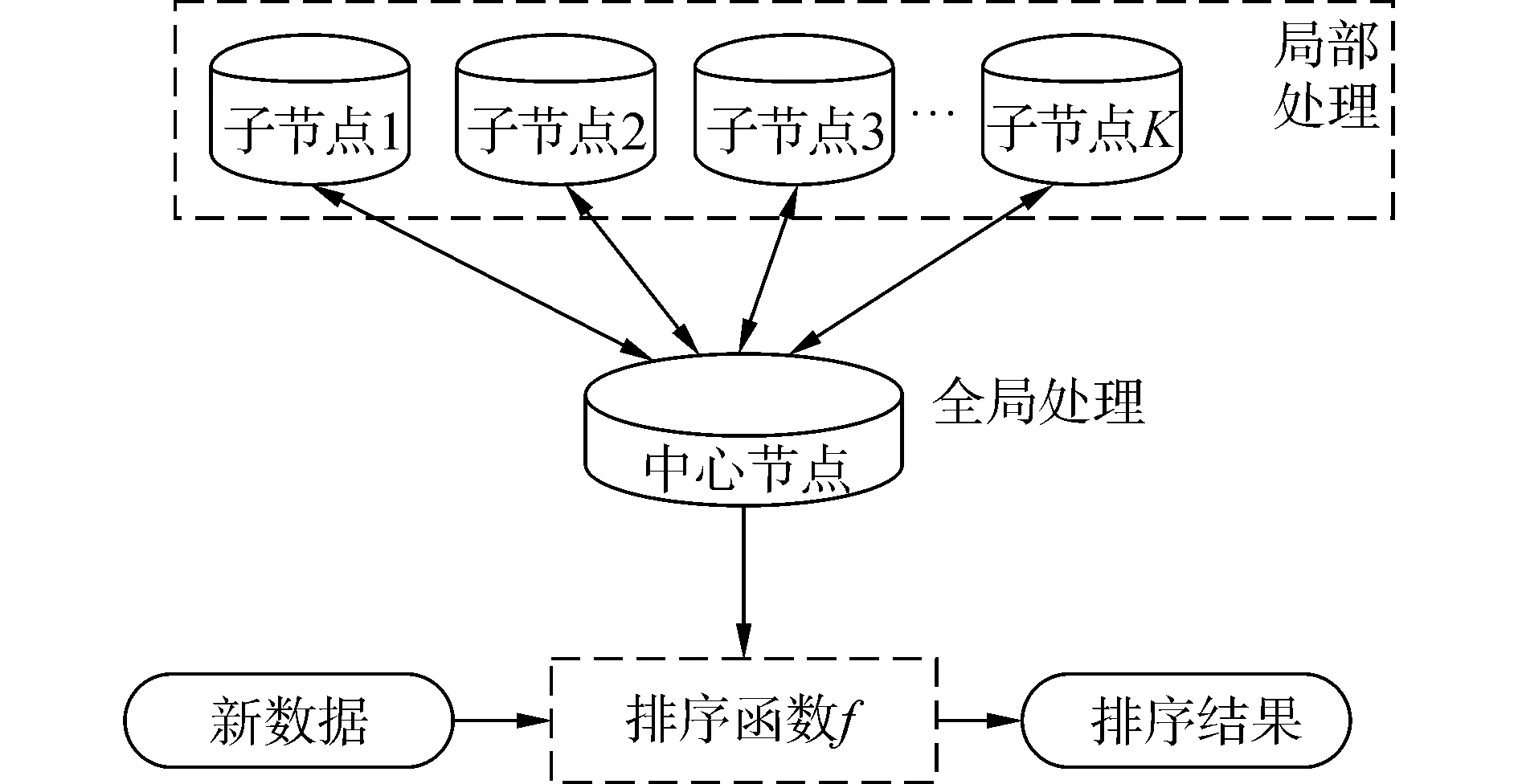
图1 并行学习排序架构图Fig.1 Architecture of the parallel learning-to-rank
假设有K个节点,每个节点并行地在各自的局部数据上训练局部弱排序器并计算所需要的信息。中心节点收集所有节点上的信息,并进行统计综合,得到整体弱排序器。中心节点将得到的排序模型返回给每个子节点,子节点使用此排序模型进行训练以得到下次迭代所需要的信息。经过T次循环后,得到最终的排序公式f,当新数据到来时使用公式f对其进行排序得到排序结果。由于训练实例分布在K个节点上同时进行训练,使得训练效率有了显著提高。具体实现见算法2。
算法2PARR-H
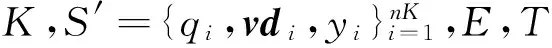
输出:f(x)=fT(x);
步骤:
1)初始化D1(i)=1/nK;
2)调用算法3并行构建候选弱排序器集Sk;
3)Fort=1 toTdo
4)Forj=1 toK(in parallel) do
5)计算

6)EndFor

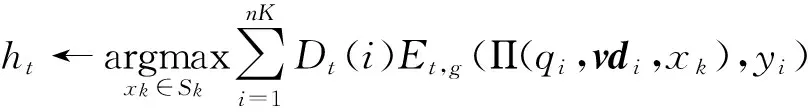
9)选择∂t

11)创建ft
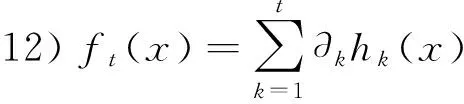
13)Forj=1 toK(in parallel) do
14)更新D(t+1),j
15)D(t+1),j(i)=
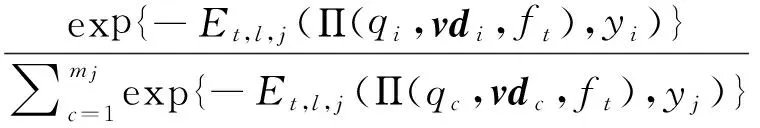
16)EndFor
17)更新D(t+1)
18)

19)EndFor
20)输出排序模型:f(x)=fT(x);
在算法2中,数据被随机分布在K个节点上,这样训练任务可并发执行,从而减少训练的时间开销;2)步调用算法3并行地构建候选弱排序器集合Sk,包含k个候选弱排序器,其详细的实现过程将在第3节算法3中具体介绍;3)~6)步在子节点上并行计算候选弱排序器的局部重要性,并将此信息发送给中心节点;7)~8)步中心节点整合从子节点获得的所有信息,构建此次迭代的整体弱排序器;9)~12)步根据整体弱排序器的排序性能E计算弱排序器的权重,并将其加入现有的排序模型;13)~16)步,中心节点将此次迭代后形成的排序模型返回到每个子节点,子节点根据此排序模型对训练实例的局部权重分布进行更新;17)~18)步对训练实例的全局权重分布进行更新;经过T次循环,最终得到排序模型f(x)=fT(x)。算法1)步的时间复杂度为O(n);2)步的时间复杂度为O(n+m2);3)~19)步的时间复杂度为O((m+n)T);因此算法2的时间复杂度为O(nT+m2),其中n为子节点上的训练实例数,T为循环次数,m为特征总数。
3 弱排序器分层构建策略
通过对算法PARR-H的分析可知,经过T次循环,该算法最终输出的排序模型f(x)=fT(x)是多个弱排序器及其权重的线性组合。而在每次循环中,弱排序器的选择直接影响了训练效率和排序模型的有效性。因此,本节将会对弱排序器的构建进行深入研究,并提出一种基于贪婪算法和整体排序性能的分层构建策略。该策略既能保证较高的排序性能,同时可有效避免冗余排序器的产生。分为两个阶段:1)构建候选弱排序集合Sk;2)根据弱排序器的排序性能,从集合Sk中进一步选择每次循环中的弱排序器。在阶段1中,子节点并行地计算特征的局部重要性和局部相似性。并将其传送给中心节点,中心节点整合以上信息得到每个特征的全局重要性及特征间的全局相似性。以特征为顶点,全局重要性为节点权重,全局相似性为边权重构建全局特征关联图G0。使用贪婪算法在图G0上进行搜索得到候选弱排序器集合Sk。特征的全局重要性和全局相似性计算过程如下:
1)特征的全局重要性。

2)特征的全局相似性。
将每个特征作为一个排序模型,并由此得到不同的排序结果。使用排序结果间的相似性作为特征间的相似性,本文选取皮尔森相关系数对排序结果相似性进行度量。相似性的计算:
Al,j(xkxf)=
(1)
式中:xk和xf为任意两个不同的特征,K为节点数,Al,j(xkxf)表示在节点j上特征xk和xf间的局部相似性,Ag(xkxf)表示在K个节点上特征xk和xf间的全局相似性。cov(vdxk,vdxf)为根据特征xk和xf所得排序结果的协方差,var(vdxk)为根据特征xk所得排序结果的方差。
算法3PCAWR(parallel construction algorithm of candidate weak rankersSk)
输入:K,Dj,k,c;
输出:候选弱排序器集Sk;
步骤:
1)初始化Dj=1/n(每个节点包含n个实例),S0=φ;
2)Forj=1 toK(in parallel) do
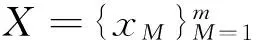
4)得到


5)EndFor
6)计算
;

8)Fori=1 tokdo
9)对Eg(xM)降序排序,xg←argmaxEg(xM);
10)Eg(xj)←Eg(xj)-Ag(xgxj)*2c,j≠g
11)Si=Si-1∪{xg},Gi=Gi-1{xg};
12)EndFor
13)输出Sk
算法3描述了弱排序器构建的第一阶段:并行构建候选弱排序器集合Sk。算法1)步初始化,分别为每个节点上的训练实例赋予相同的权重分布,初始化候选弱排序器集合S0=φ;2)~5)步在每个子节点上并行地计算特征的局部重要性和特征间的局部相似性,并将结果返回给中心节点;6)~7)步中心节点计算特征的全局重要性和全局相似性,进而构建全局特征关联图G0;8)~12)步选择全局重要性最大的特征,将其加入候选弱排序器集合S,并对特征全局关联图进行更新。k次循环后得到包含k个特征的候选弱排序集合Sk。算法1)步的时间复杂度为O(n);第2~5步的时间复杂度为O(m)+O(m(m-1)/2);6)~7)步的时间复杂度为O(m)+O(m(m-1)/2);8)~12)步的时间复杂度为O(k·m)。综上所述算法3的时间复杂度O(n+m2),其中n为子节点上的训练实例数,m为特征总数。
4 实验结果与分析
在数据集IMDB[11]和Wikipedia[12]上进行实验,通过与基准方法SVM Rank进行比较分析,验证算法ARR-H和PARR-H的有效性和效率。选择SVM Rank算法作为基准方法,因为该算法是关系数据库领域中最为经典的学习排序方法,并且Joel Coffman等[8]已经通过多组对比实验验证了该学习排序方法在排序准确率方面优于传统的信息检索式排序方法。
4.1 实验设置
分别抽取原始数据集IMDB和Wikipedia的子集作为本次实验的数据集。表1记录了关于该数据集的统计结果。另外,实验包括1个主节点和4个子节点。其中每个节点的配置为Intel(R)Core(TM)i5-4570 CPU 3.20 GHz,内存容量4G,硬盘容量1 TB,操作系统WIN 10(64 bit)。在进行实验之前,需要对原始数据集进行预处理。分别在数据集IMDB和Wikipedia上随机生成250个查询,基于三个系统BANKS、DISCOVER、SPARK得到与查询相关联的查询结果,这里统称为虚拟文档。针对每个查询,从3个系统返回的结果中选取top-100虚拟文档放入数据池,并由此产生实验所需的训练实例。使用五折交叉验证实验减小评分函数过拟合的风险。将数据池中的数据随机分为5个子集合,每个子集合包含50个查询及其对应的虚拟文档。其中4个子集合用于训练,剩余1个子集合用于测试。注意,在算法PARR-H执行过程中,训练集的4个子集合被分布在4个子节点上,主节点使用测试集对训练结果进行测试。表2和表3分别显示实验中的查询划分以及五折交叉验证中的数据集划分,其中QID为查询ID号。

表1 实验数据集

表2 查询划分
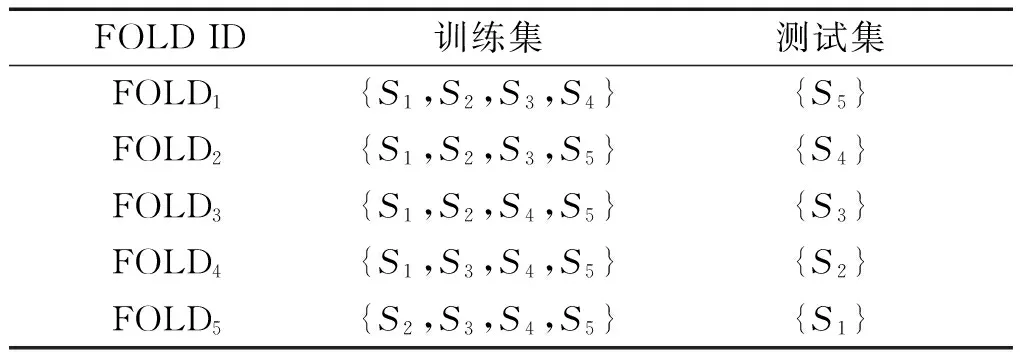
表3 交叉验证的数据集划分
4.2 有效性
使用MAP和NDCG两种度量指标作为排序模型的效果评估标准。给定查询q,第i位上的NDCG值计算如下
式中:r(j)为第j位虚拟文档的相关度等级,ni为归一化因子。
查询q的平均准确率计算如下:
式中:P(j)为排在前j位虚拟文档的查准率;pos(j)为二值函数,当第j位虚拟文档为相关文档时pos(j)=1,反之pos(j)=0;N为通过查询q返回的虚拟文档数;Nq为查询q相关的虚拟文档数。多个查询的AP值取平均即可得到MAP值。
4.2.1 数据集IMDB上的实验
本节使用数据集IMDB验证算法ARR-H和PARR-H的性能。这里,将算法SVM Rank记为‘SVM-R’。图2中x轴为虚拟文档在文档序列中所在的位置,y轴为三种排序算法在各个位置上所对应的NDCG@n值。由图2可知,算法ARR-H和PARR-H在NDCG@n上均优于算法SVM-R。具体来讲,当n=1时相对于SVM-R,ARR-H和PARR-H分别提高13.3%和8.2%。而关于NDCG@5,ARR-H和PARR-H相对于SVM-R分别提高9.1%和7.0%。另外,在该实验中算法SVM-R的MAP值为0.309,而ARR-H和PARR-H的MAP值分别为0.335、0.317,相对于SVM-R分别提高约8.4%和2.6%。产生上述实验结果的原因是:本文提出的算法ARR-H和PARR-H为虚拟文档列级的学习排序方法,与文档对级的排序方法SVM-R相比,以上两种方法不再将排序问题归纳为二元分类问题,而是直接优化排序评价指标,从而提高排序模型的精度。另外,算法ARR-H和PARR-H使用分层式弱排序器构建策略IS-BGEM(importance & similarity-based on global evealvation measure),避免了冗余弱排序器的产生,进一步提高了排序模型的精度。而ARR-H的实验结果优于PARR-H,其主要原因是:将训练数据分散在不同节点上进行并行化处理,对排序模型精度方面造成一定程度的影响,一方面节点间的数据通信降低了模型的可靠性。另一方面,算法中特征的全局重要性和全局相似性以及训练样本的全局分布,均和实际单节点上的算法运行有所差异。本文方法在NDCG@1上的提高幅度最为显著,说明该方法适用于Web数据库,此应用环境强调位置靠前的结果。

图2 数据集IMDB上的NDCG@n值Fig.2 Ranking performance NDCG@n on IMDB
4.2.2 数据集Wikipedia上的实验
在数据集Wikipedia上同样进行五折交叉验证实验。由图3可以看出在数据集Wikipedia上的实验结果与数据集IMDB上的结果相类似。ARR-H的NDCG@n值优于其他两种排序算法。例如,与SVM-R相比,ARR-H的NDCG@5值提高6.6%,PARR-H的NDCG@5值提高5.2%。另外,SVM-R、ARR-H、PARR-H所对应的MAP值分别为0.443、0.473、0.452。其中,ARR-H的MAP值最大,相比于SVM-R提高6.8%。PARR-H的MAP值相比于SVM-R提高2.0%,而与ARR-H相比,有所降低。

图3 数据集Wikipedia上的NDCG@n值Fig.3 Ranking performance NDCG@n on Wikipedia
4.3 训练效率
图4给出随着训练实例规模的变化,3种排序算法训练时间的变化情况。由图4可知,相对于另外两种排序算法,PARR-H的训练时间明显减少。当训练实例个数为10 000时,PARR-H的训练时间为4.9 min,而SVM-R和ARR-H的训练时间分别为25.5 min和16.1 min。通过对实验结果的分析可以发现,随着训练实例规模的不断增大,PARR-H算法效率提高越明显。当训练实例的个数达到20 000时,PARR-H的训练时间为51.2 min,而SVM-R的训练时间达到179.8 min。产生上述实验结果主要是由于PARR-H和ARR-H均为列表级的学习排序方法,其训练对象为查询相关的虚拟文档列表,更接近于实际意义上的排序操作。而SVM-R为文档对级的学习排序方法,其训练对象为查询相关的虚拟文档对,排序过程中着重考虑虚拟文档对间的偏序关系,而未考虑虚拟文档在整个文档列表中的序列关系。因此,PARR-H和ARR-H在排序性能上有较大提高。而PARR-H为学习排序加入并行框架,将训练样本分布在不同机器上并行化训练过程,因此学习排序模型的训练效率得到进一步提高。

图4 不同规模训练实例下的训练时间Fig.4 Training time for different numbers of training instances
5 结论
1)提出一种列表级的学习排序算法ARR-H。该算法充分考虑虚拟文档间的序列关系,同时结合弱排序器分层构建思想,提高排序模型的有效性。
2)构建一种并行学习排序框架PARR-H,并行化训练过程,有效解决了面对大规模训练实例时ARR-H算法训练效率低的问题。
3)通过在数据集IMDB和Wikipedia上进行实验,验证本文学习排序算法ARR-H和PARR-H在有效性和效率方面均有显著提高,尤其当训练实例规模较大时,PARR-H在训练效率上的优势更为突出。
在未来的研究中,将在更大规模的数据集上进行实验,验证排序算法的可扩展性。
[1] TRAN T, ZHANG L. Keyword query routing[J]. IEEE transactions on knowledge and data engineering, 2014, 26(2): 363-375.
[2] ZUZE H, WEIDEMAN M. Keyword stuffing and the big three search engines[J]. Online information review, 2013, 37(2): 268-286.
[3] KARGAR M, AN A, CERCONE N, et al. Meaningful keyword search in relational databases with large and complex schema[C]//Proceeding of 2015 IEEE 31st International Conference on Data Engineering. Seoul, Korea, 2015: 411-422.
[4] PARK J, LEE S G. Keyword search in relational databases[J]. Knowledge and information systems, 2011, 26(2): 175-193.
[5] HRISTIDIS V, PAPAKONSTANTINOU Y. Discover: keyword search in relational databases[C]//Proceeding of the 28th international conference on Very Large Data Bases. Hong Kong, China, 2002: 670-681.
[6] LIU F, YU C, MENG W, et al. Effective keyword search in relational databases[C]//Proceeding of 2006 ACM SIGMOD international conference on Management of data. Chicago, USA, 2006: 563-574.
[7] PAN Y, LUO H X, TANG Y, et al. Learning to rank with document ranks and scores[J]. Knowledge-based systems, 2011, 24(4): 478-483.
[8] COFFMAN J, WEAVER A C. Learning to rank results in relational keyword search[C]//Proceeding of the 20th ACM international conference on Information and knowledge management. Glasgow, United Kingdom, 2011: 1689-1698.
[9] CHAPELLE O, KEERTHI S. Efficient algorithms for ranking with SVMs[J]. Information retrieval, 2010, 13(3): 201-215.
[10] LI H. A short introduction to learning to rank[J]. IEICE Transactions on information and systems, 2011, E94D(10): 1854-1862.
本文引用格式:
王瑛琦, 周连科, 王念滨. 关系数据库关键字查询结果排序方法[J]. 哈尔滨工程大学学报, 2017, 38(12): 1937-1942, 1963.
WANG Yingqi, ZHOU Lianke, WANG Nianbin. Research on ranking method for relational databases[J]. Journal of Harbin Engineering University, 2017, 38(12): 1937-1942, 1963.
