基于Hadoop的陶瓷信息网个性化推荐平台的设计
2018-01-15罗新
罗新
(韩山师范学院计算机与信息工程学院,潮州521041)
0 引言
随着网络信息量的不断增长,人们从互联网获取自己感兴趣信息变得越来越困难。于是各种个性化推荐系统相继产生。但是对于传统的运行于单机模式的推荐算法,在面临海量用户数据的时候,在可行性、效率上都变得越来越不适应。所以必须开发出能对大数据进行并行计算处理的个性化推荐平台[1-2]。
Hadoop[3]作为开源的并行计算机平台,提供了HDFS和MapReduce两大核心功能。HDFS是分布式存储系统,可以冗余存储海量的数据。而MapReduce则是构建在HDFS上的分布式并行计算架构。
本文在开发的陶瓷信息网站的基础上,根据用户对网站的访问日志,对产品的关注度、评分,以及发布的产品供需等信息,对它们进行预处理后,得到一个用户对产品的兴趣度文件,然后在Hadoop平台上运行推荐算法进行计算,最后得出一个产品推荐列表。
1 网站数据处理
陶瓷信息聚合平台网站是一个前端采用BootStrap框架,应用HTML5、AJAX、jQuery等相关技术,后台采用Struts+Hiberate+Spring框架技术的网站。系统的功能包括:用户注册与管理,陶瓷产品的上架与展示,供求信息的发布,各类信息的搜索等功能。网站的布局如图1所示。
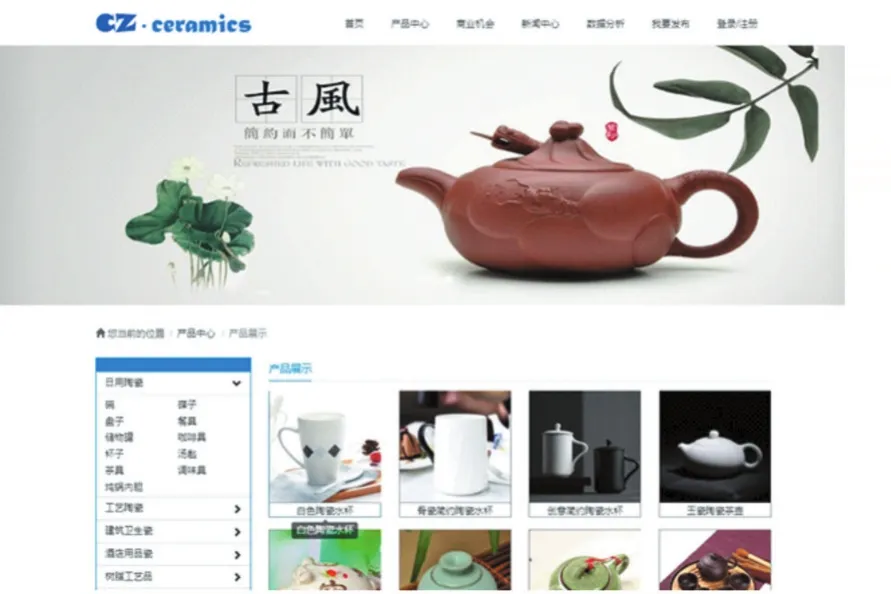
图1 陶瓷信息聚合平台网站界面
为了获取用户对产品的兴趣度文件,可以对几种数据源进行处理。一种是用户访问日志文件,另一种是保存在数据库中的用户对产品的评分、用户发布的供需信息等。
为了更深入的了解网站访客的使用习惯,可以对网站的访问日志进行分析。例如下面一条是Tomcat服务器上记录的访问日志的信息。
127.0.0.1--[01/Nov/2017:13:37:09+0800]"GET/cz_ceramics/images/product/no-photo.jpg HTTP/1.1"200 77537 http://localhost:8080/cz_ceramics/chances_findAll.action?page=1 Mozilla/5.0(Windows NT 6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/61.0.3163.100 Safari/537.36,其表达的信息如表1所示。
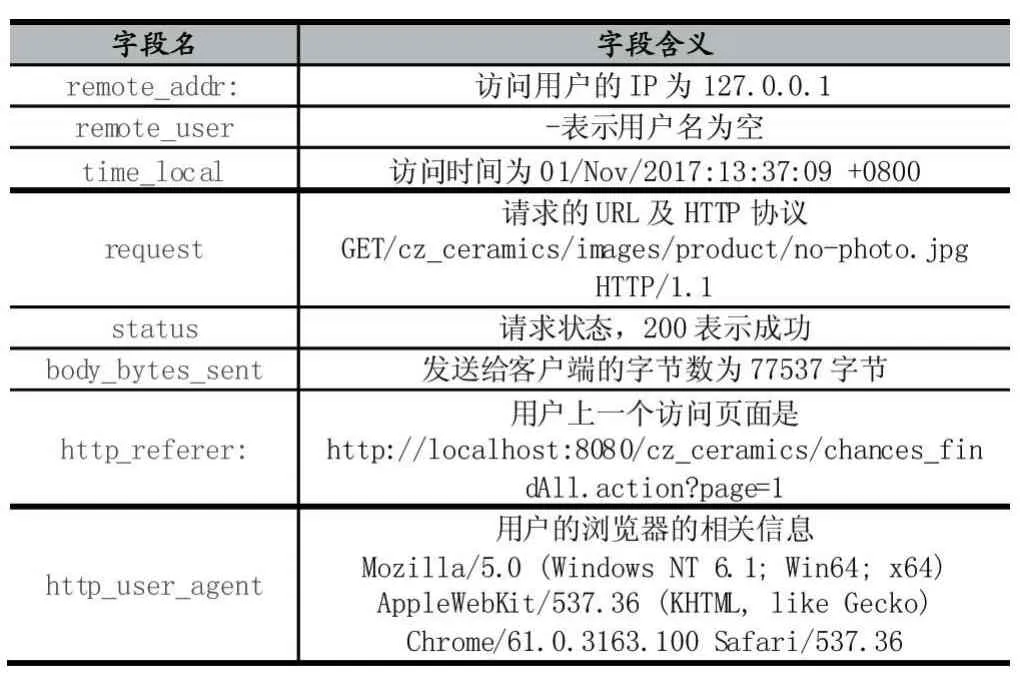
表1 日志字段信息
通过日志分析,可以统计出一个用户的对某个产品页面的访问频度。而用户对某种产品的评分或者是否进行了评论,可以从另一个侧面反映了用户对该产品的兴趣度。用户如果对某件产品发布了供货或者需求信息,这足以证明用户对该产品具有高兴趣度。最后综合这三个方面,给每一个维度一个权值,综合计算出一个用户对某件产品的兴趣度。兴趣度的值由0至5,以0.5相隔,即分为11个等级。用户兴趣度文件是由格式为
2 用户推荐算法
在Hadoop平台根据用户兴趣度文件计算推荐列表,需要进行如下五步。
Step1:生成用户兴趣度向量,它的格式是
Step2:计算产品与产品之间的相似度。根据第一步的输出的评分矩阵,对Item与Item之间相似度进行计算。这里我们采用余弦相似度计算公式,公式如下:
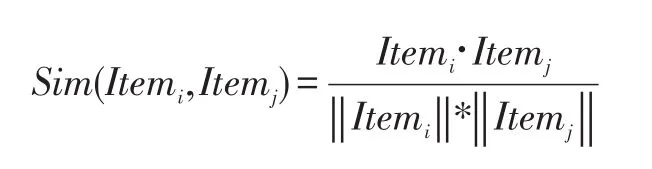
Itemi表示所有用户对ID为i的产品的评分向量,其形式为
Step3:对第一步生成的用户兴趣度矩阵进行转置,得到矩阵的行向量的形式为
Step4:用第二步输出的Item相似度矩阵乘以第三步输出的用户兴趣度矩阵。就可以得到用户对于那些并未评分产品的推荐度。原理就是用户已经对某些产品进行评分,而其它没有评分的项目可以根据与那些已经评分的产品的相似度,得到一个推荐的分值。
Step5:对第四步产生的推荐矩阵与第三步的输出矩阵进行对比,对那些用户已经评分的Item,在对应的矩阵位置0,然后再对Item按分值按从高到低进行排序,就可以为用户生成对应的推荐产品Top n列表。
以上的每一步都可以用一个MapReduce作业来实现。例如第一步的输入是一个用户评分文件,Map/Reduce的流程可表示如下:
Map:
Reduce:
下面是第二步实现的Map过程的核心代码:try
{
String row_matrix1=value.toString().split(" ")[0];
String[]column_value_array_matrix1=value.toString().split(" ")[1].split(",");
double denominator1=0;
for(String column_value:column_value_array_matrix1)
{
String score=column_value.split("_")[1];
denominator1+=Double.valueOf(score)*Double.valueOf(score);
}
denominator1=Math.sqrt(denominator1);
for(String line:cacheList)
{
String row_matrix2=line.toString().split(" ")[0];
String[]column_value_array_matrix2=line.toString().split(" ")[1].split(",");
for(String column_value:column_value_array_matrix2)
{
String score=column_value.split("_")[1];
denominator2+=Double.valueOf(score)*Double.valueOf(score);
}
denominator2=Math.sqrt(denominator2);
double numerator=0;
for(String column_value_matrix1:column_value_array_matrix1)
{
根据形势任务的需要,结合辖区地理位置和气候条件,密切关注辖区社会动态,按照“组织健全,训练有素,规模适当,反应迅速”的要求,建立民兵应急队伍,提升应急分队“平时服务、急时应急、战时应战”的能力。针对“人员分散集中难、外出务工在位少、岗位职责协调难”等现实问题,按照“专业对口、因地制宜、就地取材、就近支援”的原则,及时调整优化结构,确保配齐建强应急队伍。
String column_matrix1=column_value_matrix1.split("_")[0];
Stringvalue_matrix1=column_value_matrix1.split("_")[1];
for(String column_value_matrix2:column_value_array_matrix2)
{
if(column_value_matrix2.startsWith(column_matrix1+"_"))
{
String value_matrix2=column_value_matrix2.split("_")[1];
numerator+=Double.valueOf(value_matrix1)*Double.valueOf(value_matrix2);
}
}
}
double cos=numerator/(denominator1*denominator2);
if(cos==0)
{
continue;
}
outKey.set(row_matrix1);
outValue.set(row_matrix2+"_"+df.format(cos));context.write(outKey,outValue);
在主函数中,首先把第一步的输出添加到HDFS的cache上,然后在Mapper类的setup方法中,把cache文件上的数据读入到ArrayList类型变量cacheList中。而第二步的Job的Map过程的Input文件也是第一步的输出。通过计算两个矩阵每一行之间的余弦相似度,最终得到Item相似度矩阵。
3 实验设计与分析
为了证明推荐算法的可行性,我们架设了一个具有1个NameNode,5个DataNode的Hadoop完全分布式平台。其中DataNode的硬件配置为Intel Core i7 4790,内存5G。Hadoop平台版本为2.5.4。经过数据预处理后,生成用户兴趣度文件,其行格式为

表2 算法各个阶段的运行状况
通过分析表2的数据,我们可以看出对于一个较小的输入数据集,算法最终会都会产生一个较大的数据输出。尤其是在Step4中,是计算用户对各个Item的兴趣度,它的输入是Step2及Step3的输出,这是相当于两个维度分别为[89649,11589]的矩阵相乘,所以输入数据集大小为22.6M,输出却为1.4G。从运行过程来看,小数据集并且算法运算密集度大的作业运行在Hadoop平台上并无优势。因为涉及到数据分片、容器分配的问题,Hadoop平台运行小数据集,并不能发挥集群的最佳性能。对于Step5的运算,它把Step1和Step4的输出作来输入,对用户的兴趣度进行筛选,去除用户已经评分过的项目,剩下的就是用户以前没有评分过的Item的推荐度。因为Step5运算的输入是较大的数据集(1.4G),这时Hadoop平台会对数据自动分片,一共创建11个Container。通过观察各个数据结点CPU、内存、文件I/O的占用率,可以看到集群运算能力的利用率得到了很大的提高。这说明应用Hadoop平台运行推荐算法处理大数据集是具有可行性的,而且能发挥性能上优势。
4 结语
本文在开发的陶瓷信息网站的基础上,通过用户访问日志、用户发布的相关信息的基础上,整理出用户对产品的兴趣度文件,然后在Hadoop平台上运行推荐算法,得到为用户推荐的产品列表。为了更好利用Hadoop平台进行推荐算法的运算,应该在Hadoop平台参数调优,推荐算法的改进等方面进行加强,这是下一步的努力方向。
[1]肖强,朱庆华.Hadoop环境下的分布式协同过滤算法设计与实现[J].现代图书情报技术,2013(1):83-89.
[2]魏晓航.大数据平台下的互联网广告点击率预估模型[J].计算机工程与设计,2017,38(9):2504-2508.
[3]Tom White.Hadoop权威指南[M].华东师范大学数据科学与工程学院.译.北京:清华大学出版社
