一种基于深度学习的静态手势实时识别方法
2018-01-15张勋陈亮胡诚孙韶媛
张勋,陈亮,胡诚,孙韶媛
(东华大学信息科学与技术学院,上海201620)
0 引言
根据最新全国人口普查资料表明,我国有1.5亿听力言语障碍人群,而听力言语残疾人群已达到2057万人,约占全国总人口的1.57%。手势是聋哑人用手势代替正常言语进行交流的一种有效方式。研究手势识别能帮助聋哑人,尤其是一些未得到良好教育的聋哑人之间的交流,同时也能帮助聋哑人与正常人之间的交流;其次,手势识别是人机交互的一种便利的方式,研究手势识别能促进机械智能运作、移动设备终端的操作、门禁系统、远程控制等其他领域的发展;手势识别的进一步研究,还可以提高计算机在人类语言理解的程度。
研究者在静态手势识别领域有着许多探索。2011年Reyes[1]等人从基于Kinect深度图像对不同骨骼节点训练对应权重,利用特征加权的DTW算法,在5类手势上通过交叉验证得到68%的识别率。2013年Chai等人[2]通过对手的三维轨迹匹配的方法进行239个中国手势词汇的识别,达到了83.51%的准确率。2016年中国科学技术大学的张继海[3]在对手势轨迹处理后利用HOG提取手型特征后利用改进的隐马尔可夫模型(HMM)进行建模,最后在用基于帧平均概率融合与支持向量机的融合方法实现手势识别,准确率方面也取得了比较不错的效果。
以上方法在准确率方面取得了不错的进步,但要满足静态手势的实时识别要求、识别速度和准确率有待提升。因为人手骨架不统一、手型多变、手势词汇量大的特点,其特征信息很难灵活的获得,人工通过建模等方式设计手势描述特征的过程十分繁琐、无法深度挖掘更高层次、更多维度的特征信息,这就导致基于传统方法的模型范性差、很难达到实时检测目的。
深度学习模型[4]是一种突破性的技术,尤其是它在机器学习领域的表现。为了达到模式分析和分类这样的目的,它的有监督和无监督的特征提取和转换是由多层非线性的组合去完成的。许多国内外科研机构的研究人员在深度学习领域进行了广泛的研究,其应用方面也做了大量的拓展,效果突出的领域主要表现在语音、图像等领域。Ross B.Girshick等人提出区域卷积神经网络(R-CNN)[5],快速区域卷积神经网络(Fast R-CNN)[6],加速区域卷积神经网络(Faster R-CNN)[7]。这些方法成为深度学习中检测识别领域的里程碑。
尽管以上方法在某些单一方面表现不错,例如准确率方面,但对于单个常规嵌入式系统来讲,计算负荷还是过大,即使用上高端硬件的嵌入式系统,要满足实时或接近实时的应用难度也相当大,再或者是以牺牲检测精度来换取时间。2016年Wei Liu等人[8]在ECCV提出了SSD(Single Shot MultiBox Detector)方法。该方法没有采用区域建议(RPN),而是用小卷积核去预测特征图上一组默认边界和类别分数及位置偏移,并且从额外卷积层及基础网络层VGG16网络的最后一层的特征图上生成不相同的预测,最后分离的预测结果是依据不相同的的宽高来完成。
1 本文算法流程
本文受Wei Liu文献的方法启发,针对实时手势检测要求对SSD网络进行优化,提出ASSD模型:将原SSD网络中用于特征提取的基础网络VGG16更改为去掉最后两层全连接层的AlexNet网络,并对AlexNet网络结构做了修改。因为手势识别的目标相比自然图像识别的目标而言没有那么复杂,采用略浅层次的深度学习特征提取网络在会保证识别准确率的同时可提升整个网络的识别速率。本文第2小节给出了ASSD网络的结构图,并给出了修改的特征提取网络AlexNet的结构;第3小节给出了实验过程及结果分析,第4小节为结论。
图1为算法流程图:将静态手势训练集及对应的真实标签文件送入ASSD网络进行迭代学习,通过调整参数,找到效果好的模型作为最终模型,用于手势识别。

图1 算法流程图
2 网络结构
本文提出的网络整体结构如图2所示。

图2 ASSD整体框架示例
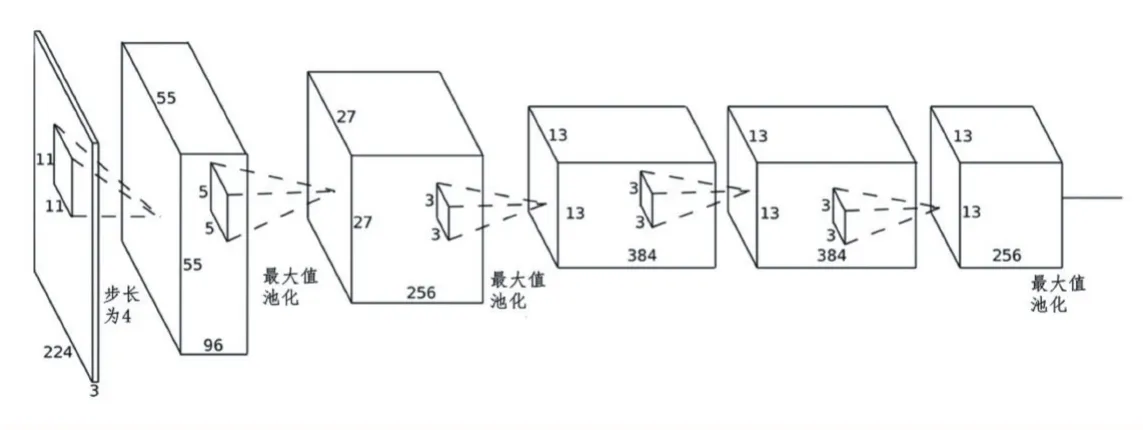
图3 网络基础层:改进的AlexNet
该网络结构有两个部分组成:基础网络层(特征提取层)和额外卷积特征层。
网络基础层是一个类似AlexNet[9]网络的结构,去掉了最后的全连接层,共有5层,调整策略有:更改部分卷积核大小;使用更小的卷积核可以提取到手型的细节变化;使用1x1大小的卷积核,步长为1,填充边界为0,这样可以保证网络深度、减小模型误差。该网络结构示意图如图3所示。
额外特征提取连接网络添加到截断的基础网络末尾,为一个多层网络,其中有8层为卷积层和1层下采样池化层(均值池化)。这些层的尺度逐渐减小,用以得到多尺度的预测值。
ASSD方法基于前馈卷积网络,除基础网络特征提取层改变外,其他沿用了SSD方法的特征选择和匹配策略。
2.1 ASSD模型
ASSD架构图,如图4所示。

图4 SSD架构
在训练网络期间,输入ASSD网络的仅是每个对象的图像和对应的真实标签框,如图4(a)所示。卷积部分,ASDD网络会在不同尺度的特征图中估测各个位置上不同横宽比的小集合(如4个)默认框,如图4(b)和图(c)所示。各个默认框中,需要得到全部形状偏移和置信度,那就要预测全部对象的类别((c 1,c2,...,cp))。在训练时,首先完成的是默认框与真实标签框匹配动作。(例如,猫和狗被两个默认框匹配到,这些匹配到的框视为正,其余视为负)。对于整个模型,用位置信损失(如Softmax)和置损失(如Smooth L1)的加权和的形式来表示总损失L。
基于前馈卷积网络的ASSD方法,会产生固定大小的边界框集合以及框中对象类别的分数,再通过一个非最大化抑制步骤产生最终的检测。网络如图2所示,本文提出的ASSD网络基础网络为改进的AlexNet网络;辅助网络产生以下主要特征的检测:
(1)多尺度特征图检测:在去掉全连接层AlexNet的基础网络末尾增加额外的卷积特征层,其特征是在逐渐减小的特征层中产生不同尺度检测预测值。各个特征层与检测的卷积模型不是一一对应的关系。
(2)检测使用卷积预测器:如图2中所示,在各个额外卷积特征层和去全连接层的AlexNet网络特征层上使用一组滤波器去卷积这些特征层从而生成预测集合。预测集合具体生成规则是:对于m×n大小的、并且具有p个通道的特征层,卷积核大小则为3×3×p,卷积操作后,生成该框中目标类别分数、或是代表相对于默认框的坐标偏移量,并在每个m×n大小区域上进行卷积操作,产生一个输出值。测量的边界框偏移输出值是相对于默认框的,而默认框位置则是相对于特征图的。
(3)默认框与宽高比:默认框如图4,关联一组默认边界框与顶层网络每个特征图单元。固定各个框实例相对于其对应单元格的位置是通过在特征图中用默认框作卷积运算实现的。相对于单元格中的默认框形状的偏移和每个框中实例的每类分数,是可以在各个特征映射单元中预测的。
2.2 ASSD训练
训练ASSD关键在于训练图像中的真实标签需要赋予到那些固定输出的默认框上:
(1)匹配策略:训练时,需建立真实标签和默认框之间的对应关系,通过默认框与真实标签Jaccard匹配重叠程度来确定这一默认框,例如匹配重叠程度高于某阈值0.5。
(2)训练目标:ASSD训练的目标函数,源自Multi-Box[10-11]的目标函数。第i个默认框与p类别目标第j个真实标签的匹配用表示,相对的若不匹配则通过这个匹配策略可知,必然这就表示第j个真实标签有可能匹配多个默认框。总目标损失函数L(x,c,l,g)是位置损失Lloc和置信损失Lconf的加权和,如式1所示:
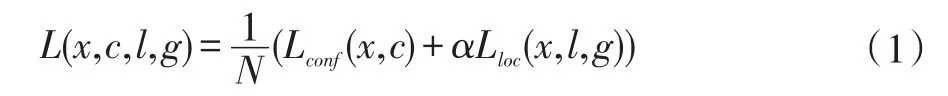
式中,N表示匹配默认框的数量,x表示是以图像作为输入的变量。
位置损失Lloc是一个Smooth L1[6]损失,它介于预测框(l)和真实标签值框(g)参数之间,回归边界框d的中心(cx,cy)以及其宽度w和高度h的偏移量,如式(2)所示:

Softmax损失对多类别置信(c)和权重项α设置为1的交叉验证构成了置信损失Lconf,如式3所示:

(3)选择默认框的比例以及横宽比:单个网络中不同层的特征图进行预测以及在所有对象尺度上共享参数可以减少计算与内存需求,并且,本网络中特征图的特定位置来负责图像中特定的区域和物体特定尺寸,这样默认框不必与每层中感受野对应。通过预测多组分别在许多特征图的所有位置上不同尺寸和宽高比的所有默认框的组合,来产生多样化的预测集合,这样就可避免输入对象的尺寸和形状就不敏感。
3 网络训练和结果分析
3.1 实验软硬件配置介绍
配置见表1,使用Caffe深度学习计算框架,算法网络在修改部分开源项目中train.prototxt,test.prototxt,solver.prototxt文件,用以训练ASSD网络。

表1 实验软硬件配置
3.2 实验数据及流程
本实验数据是由高清单目摄像头采集完成。实验中进行静态手势识别的26个字母手势中选取5个字母为代表,分别为A、B、C、D、E。实验数据由8个人完成,每人对每个字母分别录制视频,再由MATLAB视频抽帧程序完成抽帧,去除模糊严重重影的图像,得到的数据集数量如表2所示,图片大小均为640×480。用LabelImg程序进行人工标记得到真实目标标签文件。
训练集由一组组的训练图像及其对应的真实标签文件组成,通过微调训练参数不断迭代使得模型收敛并存储模型参数。选取测试集准确率最高的模型作为最终模型,用于识别分类。实验流程图可参照图1。

表2 静态手势数据集
3.3 实验结果及分析
利用本文提出的ASSD网络训练出来的模型,采用高清网络摄像头,实时采集测试者做出的A、B、C、D、E手势,其中部分帧的检测结果如图5所示:视频帧中的测试者随机做的静态字母A、B、C、D、E手势都能够检测出来并且实现字母的分类,目标边界正好框出目标,大部分结果显示了很高的概率;同时,检测画面每秒传输帧数fps(frame per second)大多数都能保持在30fps,这个可以满足实时检测的要求。由于ASSD的额外特征层采取了多尺度检测的策略,可对不同大小的特征图都做预测,所以相对对于摄像头不同远近的手势也能够准确检测并快速分类。然而本文的手势检测识别算法也存在漏检和错误分类的情况见图6。如图6(a)所示,这是一个漏检案例,这是由于手势收拾部分被遮挡,从而算法未能检测到正确手势;如图6(2)所示,这是一个错误分类,测试者所做的手势应该为字母a(字母a:单手握拳伸大拇指),由于测试者挥手的速度过快导致大拇指这种细小目标有严重残影,以至本算法以0.41的概率将该手势识别为字母d(字母d:单手仅握拳),值得注意的是这种误判在人为识别判断时也会产生。
本文也使用传统手势识HOG+SVM算法和另一个深度学习网络Fast R-CNN在同样的测试环境下进行了测试,并对比了三者结果如表3所示:传统方法方向梯度直方图+支持向量机(HOG+SVM)在检测速率(0.27fps)和准确率(0.581)方面都不及深度学习框架的方法好,因为传统在特征提取过程的计算需要大量的时间并且效果也不理想。Fast R-CNN是一个深度学习常见的网络,它的检测准确率(0.782)相比传统方法(HOG+SVM)有了很大的提高,但它采用的搜索性算法比较费时,所以检测速率(0.58fps)也不太理想,不能用于实时检测识别。本文提出的基于改进SDD网络结构的算法ASSD,是一个端到端的检测算法,检测静态手势的准确率(0.933)得到保证的同时,极大地提高了检测速率(30fps),能够满足实时检测所要求的精度和速度的要求。

表3 算法结果对比
4 结语
本文基于深度学习框架的SSD方法,提出一个用于静态手势检测识别的深度学习网路结构ASSD。用改进的卷积神经网络AlexNet作为基础网络用于特征提取,保留原SSD方法的额外特征层用以检测识别目标。该方法无需人工通过建模等手段设计目标特征,可以自动提取目标图像深层特征,用来描述复杂静态手势图像。经实验结果表明,本文网络能很好地对静态手势(字母)进行检测识别,正确率(0.933)以及检测速度(30fps以上)都满足实时检测的要求。

图5 部分检测分类结果

图6 错误案例
[1]Reyes M,Dominguez G,Escalera S.Feature Weighting in Dynamic Timewarping for Gesture Recognition in Depth Data[C].Proceeding of International Coference on Computer Vision Workshops(ICCV workshops).IEEE,2011:1182-1188.
[2]Chai X,Li Y,et al.Sign Language Recognition and Translation with Kinect[C].IEEE conf.on AFGR.2013.
[3]张继海.基于运动轨迹和手型特性的手语识别研究[硕士论文].中国科学技术大学:信息与通信工程,2016.5.
[4]LeCun Y,Bottou L,Bengio Y,Haffner P.Gradient-Based Learning Applied to Document Recognition.Processings of the IEEE,1998,86(11):2278-2324
[5]GirshickR,DonahueJ,DarrellT,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J].Conference on Computer Vision and Pattern Recognition,2014:580-587.
[6]GirshickR.Fast-RCNN[J].International Conference on Computer Vision,2015:1440-1448.
[7]Ren Shaoqing,HeKaiming,GirshickR,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].Transactions on Pattern Analysis&Machine Intelligence,2016:1-1.
[8]Wei Liu,Dragomir Anguelov,Dumitru Erhan,et al.SSD:Single Shot MultiBox Detector[C],ECCV 2016.
[9]A.Krizhevsky,I.Sutskever,G.Hinton.Imagenet Classification with Deep Convolutional Neural Networks.In Advances in Neural Information Processing Systems 25,pages 1106-1114,2012.
[10]Erhan,D.,Szegedy,C.,Toshev,A.,Anguelov,D.:Scalable Object Detection Using Deep Neural Networks.In:CVPR.(2014).
[11]Szegedy,C.,Reed,S.,Erhan,D.,Anguelov,D.:Scalable,High-Quality Object Detection.arXiv Preprint arXiv:1412.1441 v3(2015).
