基于强化学习的游戏自动化测试技术
2018-01-15朱以汀
朱以汀
(四川大学计算机学院,成都 610065)
0 引言
强化学习(Reinforcement learning)是深度学习的一个重要分支,简单来说,强化学习中分为两个概念,一个是Agent,即控制算法代理,第二个是环境,Agent每做出一个决策,都会形成一定的效果,而环境会根据效果来给Agent一个反馈(reward),Agent根据这个反馈来不断调整自己,直到一个收敛的状态。这就是强化学习的基本思想,由强化学习引申出来的具有代表性的算法就是DeepMind在2015年提出的DQN算法,以及后来针对DQN做的一系列优化,例如Double-DQN以及Dueling-DQN。
强化学习也并非一个领域的产物,它分为决策迭代和值迭代,在各个领域中运用都很广泛:
●在计算机科学中,主要表现为算法,机器学习方向的;
●在工程中,在决定有关序列的行为是,能够得到最优解;
●在神经科学中,与神经网络像素,体现为大脑做出的决策,用于反馈系统;
●在心理学中,与人类类似,研究动物的决策、什么驱动动物的行为;
●在经济学中,提现于宏观经济以及博弈论。
所以总而言之,强化学习就是为了研究最有决策的,为什么人类能够做出最优的决策。
1 强化学习模型(DQN)
Q值是状态价值,Q Learning算法的思想完全根据value iteration得到。但要明确一点是value iteration每次都对所有的Q值更新一遍,也就是所有的状态和动作。但事实上在实际情况下我们没办法遍历所有的状态,还有所有的动作,我们只能得到有限的系列样本。因此,只能使用有限的样本进行操作。那么,怎么处理?Q Learning提出了一种更新Q值的办法:
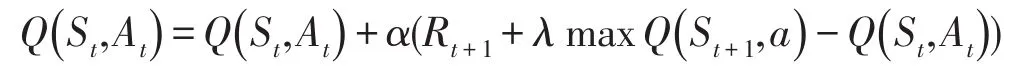
虽然根据value iteration算出target Q,也就是标签Q值,所以神经网络会根据Q值和target Q值做梯度下降,不断地更新神经网络的权值,直到收敛,也就是神经网络能够做比较满意的决策了,这个过程就是DQN的迭代过程。
具体的算法如下:
初始化Q(s , a),∀s∈S,a∈A(s),任意的数值,并且Q(terminal-state,·)=0
重复(对每一节episode):
初始化状态S
重复(对episode中的每一步):
使用某一个policy比如(ε-greedy)根据状态S选取一个动作执行
执行完动作后,观察reward和新的状态S’
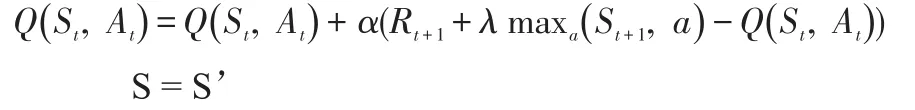
循环直到S终止
网络模型结构:
输入是经过处理的4个连续的84x84图像,然后经过两个卷积层,两个全连接层,最后输出包含每一个动作Q值的向量。对于这个网络的结构,针对不同的问题可以有不同的设置。具体结构如图1所示:

图1
2 强化学习应用
综上所述,强化学习可以应用于游戏中,即输入游戏的连续4帧画面,通过一次网络的前馈输出动作,同时给出其动作对应的reward值,在反馈至神经网络,不断迭代更新其参数。常用于画面简单的游戏,有利于前两层卷积层的特征提取,例如Atari或者flappy bird,都能够在一天的时间内收敛,Agent能玩到一个比较高的分数。

图2
也能用于比较复杂的3D游戏,在理论上是可以收敛的,但是其收敛速度比较慢,有可能一个月都无法收敛到一个比较满意的结果,所以可能还需要在神经网络中间插入其他游戏数据。
这样就能实现Agent自动玩游戏,从而达到游戏自动化测试的目的。
3 结语
本文给出了强化学习的介绍以及DQN网络模型的结构与介绍,阐述了DQN在游戏自动化测试中的应用,提出了游戏自动化测试的新技术。
[1]Mnih V1,Kavukcuoglu K1,Silver D1,Rusu AA1,Veness J1,Bellemare MG1,Graves A1,Riedmiller M1,Fidjeland AK1,Ostrovski G1,Petersen S1,Beattie C1,Sadik A1,Antonoglou I1,King H1,Kumaran D1,Wierstra D1,Legg S1,Hassabis D1.Human-Level Control Through Deep Reinforcement Learning,2015.
[2]Hado van Hasselt,Arthur Guez,David Silver.Deep Reinforcement Learning with Double Q-learning,2015.
[3]Ziyu Wang,Tom Schaul,Matteo Hessel,Hado van Hasselt,Marc Lanctot,Nando de Freitas.Dueling Network Architectures for Deep Reinforcement Learning,2016.
[4]Volodymyr Mnih,Adrià Puigdomènech Badia,Mehdi Mirza,Alex Graves,Timothy P.Lillicrap,Tim Harley,David Silver,Koray Kavukcuoglu.Asynchronous Methods for Deep Reinforcement Learning,2016
