基于双字哈希结构的最大匹配算法机制改进
2018-01-08魏光泽
刘 勇,魏光泽
(青岛科技大学 山东 青岛 266061)
基于双字哈希结构的最大匹配算法机制改进
刘 勇,魏光泽
(青岛科技大学 山东 青岛 266061)
中文分词是计算机进行文本分析的关键技术。基于提高分词效率以满足日益增长的文本分析需求,通过分析常用的基于词典的机械分词算法与词典机制的优缺点,在对最大匹配算法进行改进的同时,采用双字哈希词典设计了适合此算法的双字哈希余字分组的词典结构,提出了基于双字哈希结构的最大匹配改进算法。该算法在保证原最大匹配算法分词精度的前提下,大大提高了分词速度。经实验证明,改进后的算法性能明显提升。
中文分词;最大正向匹配算法;词典;哈希结构;哈希函数
中文分词[1]技术是中文信息处理最基础、最核心的技术。该技术在搜索引擎、检索翻译、智能输入法等多个领域广泛应用且担纲重任,任何中文语言处理应用都需要中文分词,其性能优劣对中文信息处理尤为重要[2-3]。快速、准确的进行中文分词被越来越多的人关注和研究。
中文与英文不同,英文单词与单词直接有空格划界,分词相对容易。而中文句子中是连续的汉字串,词与词之间没有分隔符,机械分词困难得多,必须借助复杂的分词算法将词语分隔开[4]。目前中文分词算法大致可以分为基于词典的机械分词算法、基于统计的分词算法和基于理解的分词算法3种[5],其中基于词典的机械分词算法最为常用。
基于词典的机械分词方法按照扫描方向的不同,可分为正向匹配算法和逆向匹配算法;按照不同长度优先匹配的方式,可分为最大匹配算法和最小匹配算法。其中占主流地位的分词方法是正向最大匹配算法和逆向最大匹配算法[6]。对于基于词典的机械分词算法,分词速度除跟算法本身的运行流程有关系外,合适的词典结构也对效率有举足轻重的作用。机械分词算法与分词词典的有效配合才能保证良好的分词性能。
文中以最大正向匹配算法为例,通过针对待匹配文本首字合理设置初始最大词长及根据词典中以某字为首字的词长序列逐次更改匹配长度,对算法流程加以优化。并根据改进算法设计双字哈希余字分组的词典结构,明显改进了原算法的性能。最大逆向匹配算法改进途径与之相通,只需设计相应逆序词典即可,文中不再赘述。
1 最大正向匹配算法分析
最大正向匹配算法FMM(Forward Maximum Matching method)遵循“长词优先”原则[7],定义如下:假设一个已知词典中,最长的词条有m个汉字,则截取待匹配文本中前m个字作为匹配字段与分词词典进行匹配。若词典中存在该词则匹配成功,将匹配字段切分出去,然后从切分出去的字符串的下一字开始在待匹配文本中再取前m个字作为匹配字段重新与词典匹配。若匹配不成功,则去掉待匹配字符串的最后一个字,用剩下的m-1个字组成的字符串与分词词典进行匹配,直到匹配成功为止。
通过对最大正向匹配算法分析可知其存在以下不足[8]:
1)在最大匹配算法中,匹配的初始最大词长是所用词典中最长词的词长。而根据文献[9]统计,汉字词中二字词占比最多,三字词、四字词较多,五字以上词所占比例很少,这样在匹配较短词语时,会造成多次无意义的匹配循环,极大的增加了时间和空间开销。
2)因匹配失败而对最大词长进行更改时,逐一递减的方式会产生多次无效循环影响效率。以使用最大正向匹配算法切分“中文与英文不同”为例,切分结果为“中文/与/英文/不同”,假设词典中最长词长度为7,则初始匹配长度为7,显然切分结果中并无7字词,程序需进行多次无意义匹配才能匹配成功。且词典中以“与”为首字并无长度为6、5、4的词,匹配词长逐一递减的方式也造成了时间浪费。
基于最大匹配算法的传统中文分词词典机制主要有以下4种:基于整词二分、Trie索引树、逐字二分和双字哈希[5]。文献[10]提出了一种改进整词二分法的词典机制。该词典将以某字为首字的词按词长分组,匹配时只需在对应词长的组内进行二分查找,通过缩小查找范围提高分词效率。文献[11]根据中文词单字词和二字词占绝大多数的特点,设计了双字哈希的词典结构。该结构与首字哈希词典结构相比,可更快速的搜索词语,大大提高了分词效率。文献[12]基于最大逆向匹配算法,设计记录词长的双哈希结构尾字词典,有效降低了词条匹配时间复杂度。文献[13]提出一种基于多层哈希的词典机制,并在首字哈希后标记对应词条长度;文献[14]提出一种基于全哈希的整词二分词典机制;文献[15]提出了一种具有三级索引的新词典结构。以上改进的词典结构都在一定程度上加快了分词速度。
2 算法改进及词典设计
2.1 最大正向匹配算法的改进
针对最大正向匹配算法的不足,若根据当前待匹配字符串的首字确定合适的最大词长,且当匹配失败时根据词典中以该字为首字的词词长递减设置下一待匹配字符串长度,该算法的效率会提高很多。改进如下:
1)根据在词典中以当前待匹配字符串首字为词的词长度m与待匹配文本长度s做比较,选择不大于s的m值作为初始最大词长,其中s根据程序运行阶段动态变化(初始值为待匹配文本长度,每切分成功一次对应减小)
2)当匹配失败需对最大词长m进行更改时,选择在词典中以当前待匹配字符串首字为词的下一最大词长度对m重新赋值。假设初始待匹配文本长度为12,当前已切分字符串长度为6,词典中以当前待匹配字符串首字为首字的词长序列为7、5、3,则当前待匹配字符串长度s为6,根据当前待匹配字符串首字设置的初始最大词长为5,当5字词匹配不成功时,直接选择3字词继续进行匹配。
2.2 基于改进算法设计词典
传统的汉字分词词典中,词长以2为主,且普遍存在不定长的现象。选用文献[16]对人民日报语料库进行的统计和分析可知,二字词所占比例很大,使用频率很高,四字以上多字词词语占比较低,使用频率也较低。统计与分析如表1所示。
汉字在计算机内以内码的形式进行存储[17],通过哈希函数可以快速的定位汉字。基于汉字词中二字词所占比例较大,为了提高词典中词条的查找速度,本文选用双字哈希的词典机制,并根据算法需求加以优化。该机制吸纳了“整词二分”和“TRIE索引树”的优点,只对词条的前两个字建立Hash索引,构成深度为2的TRIE子树,而词的剩余字串则按词长降序排列组成词典正文,这样既可以提高匹配效率又可以兼顾空间利用率。
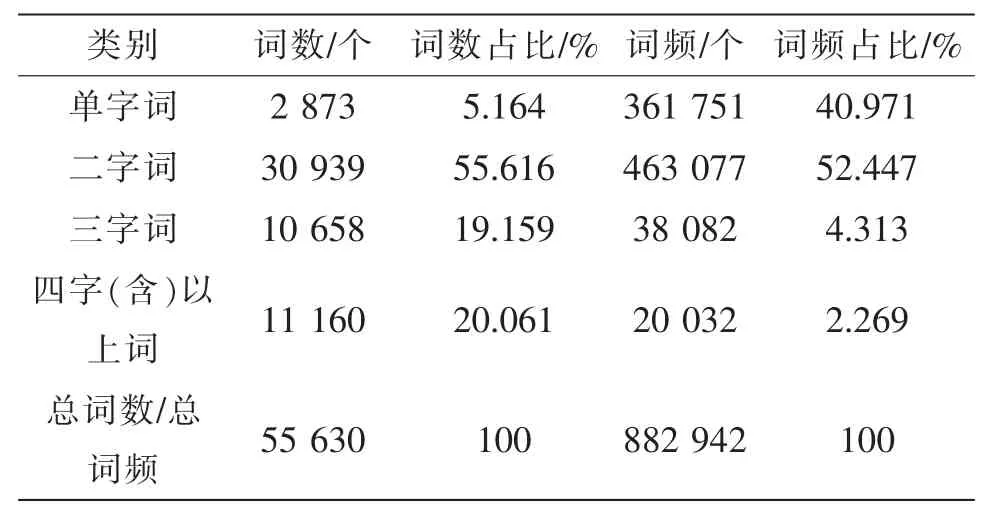
表1 人民日报语料库词语统计信息
为进一步提高查询效率,词典采用分组思想,将首字、次字相同的所有词条按照不同的词长进行分组,且标记长度。这样情况下最小组是首字、次字相同且词长相同的词条集合,查找范围更加小的同时满足了算法动态选择最大词长的要求。改进后的词典结构如图1所示。
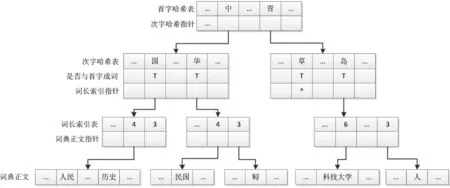
图1 改进的词典机构图
由图可知,改进的词典结构分为4部分:首字哈希表、次字哈希表、词长索引表、词典正文。
1)首字哈希表。由散列表的关键字及次字哈希指针构成,用于确定词语首字的具体位置。
汉字在计算机中以内码形式存在,将内码计算后转为为区位码,再将区位码转换为一个十进制的数字,这个数字就是该汉字在哈希表中的序号。该序号指示了以该字为首字的词的词长表的入口地址。根据Hash函数[18],入口地址的计算,如公式(1)所示。

其中,Offset为该字在哈希表中的序号,ch1、ch2分别为该字机内码的高字节和低字节。
2)次字哈希表。包括关键字、是否能与首字组合成词、以此首字次字开头的词长索引指针3部分。
3)词长索引表。对应以前述二字开头的词的剩余部分,包括以前述二字开头的词的长度及该长度词集合构成的词典正文指针两部分。
4)词典正文。顺序存储某长度词语除首字、次字外的剩余部分。
该词典采用了双字哈希的结构。为适应改进的算法需求,词典在两层哈希结构后增加了词长索引表,满足了最大匹配算法更合理的选取最大词长的需求,同时根据词长对词语进行了恰当的分组,使匹配的范围进一步缩小,大大降低了算法的时间开销。
3 改进后的算法及改进机制分析
3.1 最大正向匹配算法的改进
3.1.1 初始最大词长选择
对于每一个待匹配字符串首字设置初始最大词长时,首先计算当前待匹配字符串长度s,然后将词典中以该字为首字的所有词长从大到小依次与s比较,直到得到不大于s的最大词长m,以m作为当前状态的初始最大词长。本文采用双字哈希的词典结构,所用词典词词长索引表中标记的最小词长为3。
3.1.2 算法描述
改进后的算法流程图,如图2所示。
假设待匹配字符串Str=W1W2…WiWi+1…Wn(i,n∈N),
1)待匹配字符串首字为Wi,字符串的长度s=ni+1,若 s=1,切出 Wn结束循环;否则转 2)。
2)计算Wi的哈希值,确定其在哈希表中的位置。在以Wi为首字指向的次字哈希表中确定Wi+1的位置,若存在 Wi+1,则转向 3),否则进入 5)。
3)计算以Wi Wi+1为首二字对应的词长序列表中的最大值 m(3<=m<=s)作为初始匹配长度,转 4);若不存在m转7)。
4)当前选择匹配的字符串为Wi Wi+1…Wi+m-1,取除Wi Wi+1外的剩余字符串与m对应的词典正文进行匹配,若匹配成功则切出Wi Wi+1…Wi+m-1,i=i+m 转向 1);否则转向 6)。
5)从 Str中切出 Wi,若 i+1=n,则切出 Wn结束循环;否则 i=i+1,进入 1)。
6)设k为以Wi Wi+1为首二字对应的词长序列表中的最小值,若m>k,取词长序列表中小于当前m的最大值重新赋值转m并转4);否则转7)。
7)判断Wi Wi+1是否成词,若成词则切出Wi Wi+1,i=i+2 转向 1),否则转 5)。

图2 改进的最大匹配算法流程图
3.2 改进机制分析
文中对最大正向匹配算法进行了两处优化:1)是根据不同首字设置恰当的初始最大词长;2)是在当前最大词长匹配失败时动态的获得下次匹配的最大词长。
根据算法要求采用双字哈希结构的分词词典并加以改进。查找某个词语时,首先根据哈希函数对首字进行查找,而后哈希查找次字,然后获得以该二字开头对应的词长序列表,最后在某词长组内查找剩余部分。在匹配过程中,上一步能否成功与下一步是否进行紧密关联,若前一步匹配不成功,则查找停止,系统重新进行新的查找。
如此设计的查找方式可以快速的定位待查找的内容并进行比较,大大减少了无效流程,提高了分词效率。
4 实验结果
分别使用基于整词二分的分词词典机制、基于逐字二分的分词词典机制、基于Trie索引树的分词词典机制和本文设计的双子哈希余字分组的词典机制四种词典机制对不同类型的测试文本进行若干组实验,每组实验采用相同的测试文本,实验结果如图3所示。

图3 各词典机制分词时间分布图
5 结 论
文中算法实现了合理设置初始最大词长及动态选择匹配词长,并结合算法设计了双字哈希余字按词长分组的词典机制,在不影响原最大匹配算法分词质量的前提下大大提高了分词效率。
文中只针对算法流程及词典结构加以改进,提高了运算速度,对于最大匹配算法产生的分词歧义问题并未涉及。下一步的研究重点是通过改进算法有效解决分词歧义问题,进一步提高算法分词性能。
[1]奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011,55(2):41-45.
[2]来斯惟.徐立恒,陈玉博,等.基于表示学习的中文分词算法探索[J].中文信息学报,2013,27(5):8-14.
[3]张桂平,刘东生,尹宝生,等.面向专利文献的中文分词技术的研究[J].中文信息学报,2010,24(3):112-116.
[4]德根,焦世斗,周惠巍.基于子词的双层CRFs中文分词[J].计算机研究与发展,2010,47(5):962-968.
[5]袁津生,李群.搜索引擎基础教程[M].北京:清华大学出版社,2010.
[6]梁桢,李禹生.基于Hash结构词典的逆向回溯中文分词技术研究[J].计算机工程与设计,2010,31(23):5158-5161.
[7]张彩琴,袁键.改进的正向最大匹配分词算法[J].计算机工程与设计,2010,31(11):2595-2633.
[8]康晨阳.基于避免交集型歧义的最大匹配算法改进的研究与实现[D].西安:西安电子科技大学,2012.
[9]王瑞雷,栾静,潘晓花,等.一种改进的中文分词正向最大匹配算法[J].用与软件,2011,28(3):195-197.
[10]谭骏珊,吴惠雄.一种改进整词二分法的中文分词词典设计[J].信息技术,2009(5):40-42,45.
[11]张科.多次Hash快速分词算法[J].计算机工程与设计,2007,28(7):1716-1718.
[12]张贤坤,李亚南,田雪.基于双哈希结构的整词二分词典机制[J].计算机工程与设计,2014,35(11):3956-3960.
[13]莫建文,郑阳,首照宇,等.改进的基于词典的中文分词算法机. 计算机工程与设计,2013,34(5):1802-1807.
[14]彭焕峰,丁宋涛.一种基于全Hash的整词二分词典机制[J].计算机工程,2011,21:40-42.
[15]叶继平,张桂珠,中文分词词典结构的研究与改进[J].计算机工程与应用,2012(23):139-142.
[16]褚敬年.面向企业信息检索的中文分词系统的研究与实现[D].沈阳:东北大学,2008.
[17]姚兴山.基于哈希算法的中文分词算法的改进[J].图书情报工作,2008,52(6):60-62.
[18]张庆扬,柴胜.使用二级索引的中文分词词典[J].计算机工程与应用,2009,45(19):139-141.
Improvement on maximum matching method mechanism based on double character Hash indexing
LIU Yong,WEI Guang-ze
(Qingdao University of Science&Technology,Qingdao 266061,China)
Chinese words segmentation is the key technology for computers to carry out text analysis.To improve efficiency of segmentation to meet the growing requirement for text analyzing,we have improved the maximum matching algorithm through analyzing the advantages and disadvantages of several commonly-used mechanical word segmentation algorithm based on dictionary and dictionary mechanism.In view of this,we have designed a dictionary structure,double character hash left words grouped for the maximum matching algorithm on the basis of double-character-hash dictionary,and also proposed improved method on maximum matching based on double character hash structure.This algorithm can be able to effectively avoid the invalid matching of maximum matching algorithm,and significantly improve the rate of segmentation for words under the condition of without influencing the accuracy of primary algorithm.Experimental results show that performance of improved algorithm is greatly improved.
Chinese segmentation; forward maximum matching algorithm; dictionary; Hash structure;Hash function
TP301
A
1674-6236(2017)16-0011-05
2016-05-20稿件编号:201605195
刘 勇(1971—),女,山东青岛人,博士,副教授。研究方向:中文分词,智能家居。
