基于帕累托改进的多机器人动态任务分配算法
2018-01-08姜栋,徐欣
姜 栋,徐 欣
(杭州电子科技大学 通信工程学院,杭州 310018)
基于帕累托改进的多机器人动态任务分配算法
姜 栋,徐 欣*
(杭州电子科技大学 通信工程学院,杭州 310018)
针对多机器人系统动态任务分配中存在的优化问题,在使用合同网初始任务分配的基础上提出了一种使用帕累托改进的任务二次分配算法。多机器人系统并行执行救火任务时,首先通过初始化任务分配将多机器人划分为若干子群;然后,每个子群承包某一救火任务,子群在执行任务的同时与就近子群进行帕累托改进确定需要迁移的机器人,实现两子群之间帕累托最优;最后,使用后序二叉树遍历对所有子群进行帕累托改进实现全局帕累托最优。理论分析和仿真结果表明,相较于强化学习算法和蚁群算法,所提算法的救火任务时间分别减少26.18%和37.04%;相较于传统合同网方法,所提算法在时间方面能够高效完成救火任务,在系统收益方面也具有明显优势。
多机器人;救火任务;任务分配;合同网;帕累托改进;帕累托最优
0 引言
多机器人系统越来越多地应用到军事、未知环境和灾区等领域,包括无人飞行器(Unmanned Aerial Vehicle, UAV)、自动地面车辆(Automatic Ground Vehicle, AGV)、无人水下航行器(Unmanned Underwater Vehicle, UUV)。多机器人通过协作来交流和分享信息改进了单个机器人的性能,如任务执行效率、健壮性、灵活性和容错性[1-5]。因此,多机器人系统的研究成为机器人研究热点,近年来,多机器人系统涵盖了分布式决策,编队控制、区域覆盖及其相关应用[6]。Gerkey等[7]对多机器人系统在不同领域的任务分配问题进行特定分类,包括运筹学、经济学、调度问题、网络流量问题和组合优化问题。当分派多个机器人执行任务时,第一步就是任务分配,任务分配决定各个机器人在何时执行何种任务, 任务分配的目的是使整体性能最大化尽快完成任务、提高整个系统的运行效率。多机器人的任务分配问题在不同情况下可分别看作最优分配问题(Optimal Allocation Problem, OAP)、整数线性规划问题、调度问题、网络流问题和组合优化问题[8]。
根据任务情况一般将任务分配分为静态任务分配和动态任务分配。当任务执行之前,机器人是已知的任务执行,它们可以被称为静态任务分配。对于动态任务分配来说,机器人任务分配是一个动态的过程,需要根据任务环境的变化和子群对利益的需求处于不断调整变化的状态。
市场经济的原则非常适用于资源分配,在多机器人系统任务分配中应用取得了很多的成果。Sandholm[9]通过使用基于边际成本的个体理性机制,将传统合同应用到多机器人竞争系统,引入基于边际成本的个体理性机制,将传统的扩展合同网协议应用于竞争性系统,通过采用多种类型的任务合同消除传统合同网协议仅协商单个任务分配的限制,在理论上可以实现最优任务分配,但是实现最优任务分配的计算代价和通信代价将随问题的规模指数级增加。Kartal等[10]提出了一种基于蒙特卡罗树搜索的算法,利用分支和绑定范例来解决空间、时间和其他边界约束条件的多机器人系统任务分配问题,但是该方法不能够完全并行处理任务分配。李明等[11]提出一种改进的合同网协议,首先建立Agent能力模型和Agent执行的任务描述,在此基础上改进合同网中的招标阶段,Agent通过对正在执行的任务进行招标来动态改变自身能力以进行任务的再分配。但是,本研究所考虑的任务由单个Agent完成,并没有考虑到任务由多个Agent共同完成的情况。在多机器人任务分配问题中为了得到帕累托(Pareto)最优或者是纳什均衡[12],谈判机制可以应用于机器人对之间,但是该方法只实现机器人对之间帕累托最优没有得到全局帕累托最优。Cui等[13]在传统合同网的基础上提出一种选择谈判机器人和构造谈判组的新方法,并提出适用于分布式任务分配的协商机制,但是该系统的协商机制是基于机器人对的协商,没有在子群中进行协商,导致该方法适用性较弱。沈莉等[14]通过交换树竞拍和改进Dijkstra的方法解决机器人任务负荷不平衡的问题,来提高多机器人工作效率,但是没有从多机器人收益的角度来进行考量。
多机器人系统现有研究在对分配结果进行优化时没有从收益的角度出发,同时多机器人全局最优是任务分配中的难点,针对以上问题本文提出一种基于帕累托改进的协商策略实现子群之间帕累托最优,保证多机器人系统在执行任务时子群之间更加均衡,在减少完成任务时间的同时增加整体收益。多机器人任务分配可以将任务作为资源在机器人之间进行分配,也可以将机器人作为资源在子群之间进行分配。考虑到多机器人的设计简单、分布性好的特点,将机器人作为资源进行分配具有更好的实用性。
1 问题描述
救火任务具有高度动态性,起火的位置、时间和大小都会实时随机发生变化,因此救火任务是研究多机器人动态任务分配的理想模型。
使用四元组[15]来描述多机器人系统救火任务:
1)机器人信息集合:Datas={Ld,Fd,E,Loc,Fire,Hi,SetB};
2)多任务Tasks={t1,t2,…,ta},a≥1;
3)多机器人Robs={r1,r2,…,rb},b≫a;
4)封闭二维环境。
所有机器人为同构机器人即各机器人功能、属性均相同,机器人具备通信能力、移动能力、感知能力和灭火能力。其中:通信能力可以用于机器人之间信息集的交互,信息集包括招标信息Ld、投标信息Fd、自身能量E、自身位置Loc、火势状况Fire、历史灭火信息Hi和机器人投标信息集SetB;移动能力作为机器人自身属性包括移动速度和转向能力;机器人通过火势探测器和射频(Radio Frequency, RF)传感器来监测周边火势情况和周边机器人情况;此处对火势进行量化,机器人的灭火能力代表单位时间内消灭的单位火势。
2 初始化任务分配
救火任务具备动态性、紧急性等特点,需要多机器人系统尽快完成任务分配参与到任务中控制火势蔓延。市场方法有良好的分布性和鲁棒性,因此非常适用于救火任务,其基本思想[16]为:领导机器人(Leader Robot, LR)有任务需要跟从机器人(Follower Robot, FR)共同完成时,LR对FR进行广播信息进行招标,然后接收到招标信息的FR根据自身任务情况进行选择性投标,LR对接收到的投标信息进行权衡选择FR参与到任务当中。
2.1 确定领导机器人
多机器人系统使用自身带有的火势探测器对二维平面进行全覆盖并实时监控。当二维平面内有火势发生时,首先监测到任务的机器人对此任务进行承包,如果起火位置处在多个机器人共同覆盖区域则根据机器人信息集中的历史灭火信息Hi进行竞争性协商。
Hi=φL+ωF
(1)
其中:L为该机器人作为LR的历史次数;F为该机器人作为FR的次数;φ、ω则对应着不同的加权系数。
2.2 建立子群
确定LR之后需要在LR的基础上建立子群,这定义单个子群对应单个任务,并在任务完成后解散子群,子群内机器人数量根据系统内任务数量进行设定。市场方法作为协商式的任务分配方法,这就需要LR和FR确定统一的出价公式,出价公式采用以下计算式进行描述:
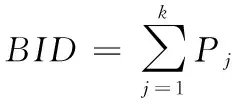
(2)
其中:Pj表示FR出价公式中所涉及到的各项属性;μj是对应属性的加权系数;FR根据LR的招标信息计算出相应的出价公式,LR则对出价公式进行筛选并确定参与到该子群的FR。确定救火任务具有紧急性的特点,因此需要尽可能快地进行任务分配以控制火势蔓延,使用就近原则进行招标和投标。领导机器人根据任务情况进行招标,招标算法步骤如算法1所示。
算法1 领导机器人招标算法。
步骤1 LR在初始化通信半径rint覆盖范围内广播招标信息(Bidding Information, BI)。
步骤2 接收到招标消息的机器人进行选择性投标发出投标信息(Sending Information, SI)。
步骤3 LR对接收到的投标消息进行筛选并传播确定性招标消息。
步骤4 接收到确定性招标消息的机器人成为该LR所领导的FR并参与到LR所承包的任务中。
步骤5 LR根据当前承包任务情况及子群内FR数量判断是否需要继续招标。
步骤6 若需要则扩大通信半径ri=ri-1+λ进行招标,执行步骤4,若ri达到该机器人最大通信半径则停止招标,子群建立完成;若不需要则停止招标,子群建立完成。
跟从机器人根据招标信息进行投标并最终确定参与到哪个任务中。跟从机器人投标算法步骤如下:
步骤1 机器人处于无参与任务状态,将接收到的任务信息存入投标信息集SetB中。
步骤2 若SetB=∅,则继续监测所覆盖区域内火势,否则进行计算筛选,选择最有利的任务进行投标。
步骤3 若接收到LR的确定性招标消息则直接参与到任务中;若接收到LR的拒绝消息则将该招标信息从SetB中删除。
建立子群算法流程如图1所示。
3 任务再分配
3.1 函数定义
3.1.1 代价函数
系统中单个子群g完成单个任务t,在完成任务的过程中会损耗移动能力,耗费通信量,同时在参与灭火任务过程中损耗灭火能力,定义代价函数即机器人执行任务过程中所要付出的代价。
Cost(g)=λ1Ecost+λ2Ccost+λ3Fcost
(3)
其中:Cost(g)表示子群内所有机器人完成任务所需要付出的总代价;Ecost为子群内所有机器人所损耗的移动能力;Ccost为子群内所有机器人损耗的通信量;Fcost为子群内所有机器人损耗的灭火能力;λ1、λ2、λ3代表的是权重。这里的Cost(g)是机器人子群代价,那么整个多机器人系统的代价为:
SCost(g)=Cost(g1)+Cost(g2)+…+Cost(gm)
(4)
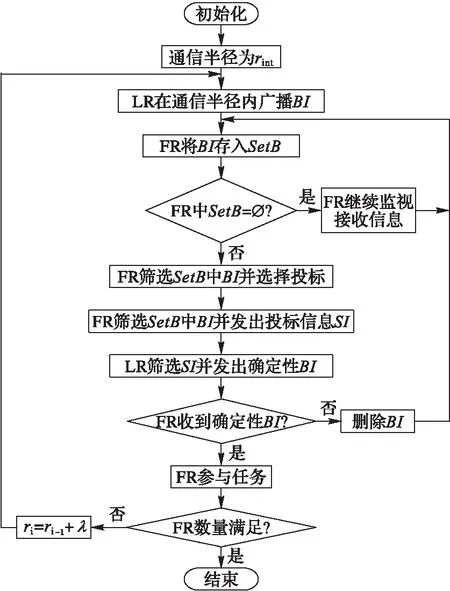
图1 建立子群算法流程Fig.1 Flow chart of building subgroup algorithm
一般通过子群代价函数来求得局部优化,通过整体代价则追求更好的全局优化效果。代价函数随着时间推进任务的完成度增长会呈现一个单调递增的趋势,同时子群中的任务个数增加时也会增加子群付出的代价。
3.1.2 奖励函数
多机器人系统在完成任务后,会根据任务情况得到奖励,这里的奖励函数描述为Rew(g,t),奖励函数包括任务完成奖励和时间奖励,使用火势情况量化描述任务奖励,同时任务完成时间越短时间奖励就越高。多机器人系统Rew整体奖惩函数则可以表示为:
(5)
其中a代表任务数量。
3.1.3 收益函数
假定多机器人系统中每一个多机器人追求利益最大化,完成任务的子群内所有机器人平分收益,因此子群LR同样追求子群利益最大化,每个子群根据代价函数和奖励函数可以得到最终的子群收益。
Pro=Rew(g,t)-Scost(g)
(6)
子群收益根据子群内机器人数量进行平均分配这样就得到子群内单个机器人的收益。
3.2 协商策略
3.2.1 两子群协商
合同网任务分配方法在一定程度上可以保证局部最优解,然而在整个系统层面上存在效率不高的情况,这里对多机器人系统进行任务再分配,实现多机器人系统整体上的帕累托最优(Pareto Optimality)。帕累托最优是一种资源分配的理想状态,它从全部机器人收益的角度来衡量多机器人资源配置的结果。假定固有的多机器人和可进行任务分配的火势情况,初始任务分配之后进行帕累托改进,在没有使任何子群收益变坏的前提下,使得至少一个子群收益变得更高,最终实现子群之间的帕累托最优状态。
定义子群g的当前执行救火任务的机器人集合为g={R1,R2,…,Rm},如果有新的机器人Rn加入到子群中,将子群g的收益函数定义为:
(7)
相反,如果子群内机器人Rn脱离子群g,则将子群g的收益函数定义为:
(8)
初始化任务分配结束之后,选择距离最近子群进行两两协商,实现两个子群之间的帕累托改进。定义一个效用函数F以保证帕累托改进过程的合理性和优化性,子群g={R1,R2,…,Rm},该集合为子群g所包含的所有机器人,θ为协商结果,即可与其他子群交换的FR,因此可以将对应于任务i的效用函数描述为:
Fi(θ)=Prog-Proi(θ)
(9)
1)协商的目的是为了优化子群收益,因此效用函数需要保证以下两个约束条件。
所有的子群LR都是追求子群利益最大化即保证该协商是合理的,因此在进行协商解决时必须要满足∀FI(θ)≥0,即:
(F1(θ),F2(θ),…,Fa(θ))≥(0,0,…,0)
该约束条件是保证协商结果的合理性。
2)子群之间协商的目的是实现帕累托最优解,协商结果θ属于帕累托改进,最终实现帕累托最优属于所谓的帕累托最优解,因此对于∀θ≠θ′满足:
(F1(θ),F2(θ),…,Fa(θ))≥(F1(θ′),F2(θ′),…,
Fa(θ′))
该约束条件是保证协商结果满足帕累托改进。
通过上述两个约束条件进行约束,协商子群之间提供各自的当前子群内机器人数量及收益函数,然后进行谈判,谈判双方交换信息同时储存对方信息,子群领导者LR两两进行信息交互同时可以将谈判信息进行分享。两个子群之间具体信息交互算法如下:
输入 初始化子群gi、gj;
输出 子群gi、gj之间转移机器人{Rij}。
1)
Rij=∅
2)
∀Rn∈gido
3)
4)
5)
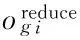
Fj(Rn)>Fi(Rn)
6)
Then {Rij}←{Rij}∪Rn
3.2.2 全局子群协商
机器人子群两两协商完成帕累托改进之后的信息保存在相互双方的信息集中,为了实现多次帕累托改进实现全局帕累托最优,使用后序二叉树遍历算法如图2所示。首先将协商之后的两个子群的当前信息集由一个子群LR保管并与其他协商后的子群进行协商改进,两者的信息由获得机器人的子群来保管并与其他子群进行协商,若无机器人添加或减少则随机选择其中一个机器人,最终实现全局帕累托最优。
算法2 全局子群协商算法。
步骤1 初始化任务分配子群gi、gj,协商后得到两者之间帕累托最优。
步骤2 根据交换信息选择一个子群LR作为两子群与其他子群LR进行信息交流。
步骤3 两个LR进行帕累托改进。
步骤4 重复执行步骤2和步骤3直到所有子群均进行帕累托改进。
步骤5 得到子群之间全局帕累托最优。
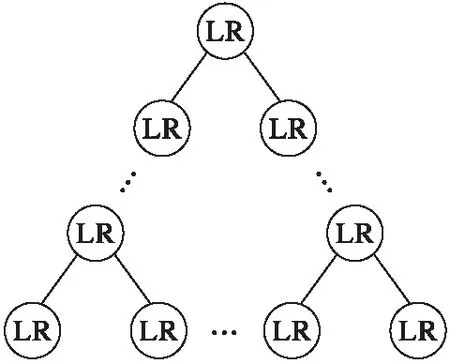
图2 后序二叉树遍历算法示意图Fig. 2 Schematic diagram of posterior binary tree traversal algorithm
4 实验结果与分析
本文在Netlogo仿真平台[17]中建立了多机器人救火仿真模型,该模型中可以设定机器人感知火势情况、机器人灭火速度、移动速度、通信能力、以及机器人及起火数量,同时可以通过能量展示模块跟踪观察救火任务完成情况。在仿真过程中,当机器人检测到有火势发生时,多机器人进行任务分配,在灭火过程中子群之间进行任务再分配。多机器人对二维环境的覆盖状态如图3所示,其中,人形状代表救火机器人,星状代表火势情况,根据形状大小来表示火势情况紧急程度和火势大小。
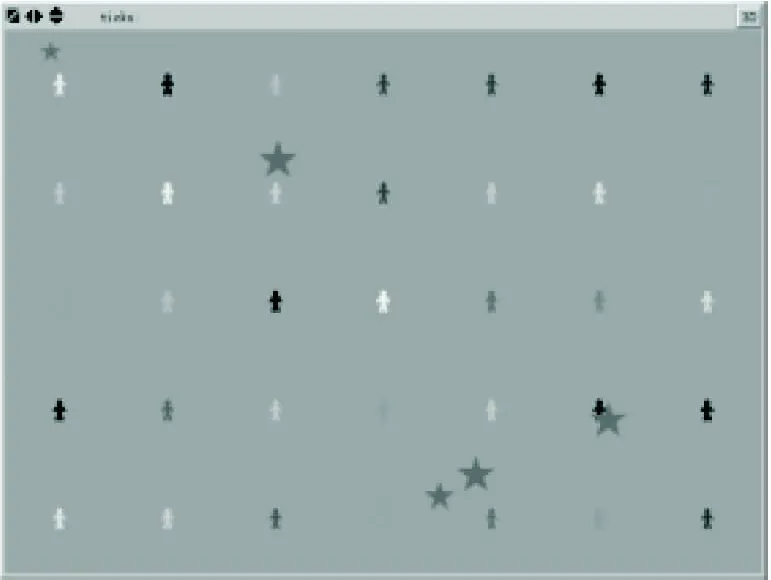
图3 二维环境覆盖状态Fig. 3 Two-dimensional environment coverage state
这里对使用帕累托改进的二次分配和传统合同网方法进行分析对比,考虑到算法的随机性和火势的随机性,针对两种方法分别进行50次重复实验。对仿真实验中的各项参数进行设置如表1所示。
4.1 使用帕累托改进算法效率结果
为了对比帕累托改进算法的任务执行效果,进行了5组对比实验分析,每次实验重复50次。时间统计使用Netlogo中自带时钟计数器ticks和秒表计算来作为实验完成时间上的评价指标,使用帕累托改进和传统合同网的时钟计数器的对比如表2所示,相应的时间对比如图4所示。结合表2和图4可以看出,实用帕累托改进后的多机器人系统完成任务的速度优于无帕累托改进算法,随着任务数量的上升效果更加明显。实验结果表明,使用帕累托改进算法能够将时间复杂度将低20个百分点,验证了帕累托改进算法能够有效地提高任务执行效率。

表1 主要仿真参数Tab. 1 Main simulation parameters
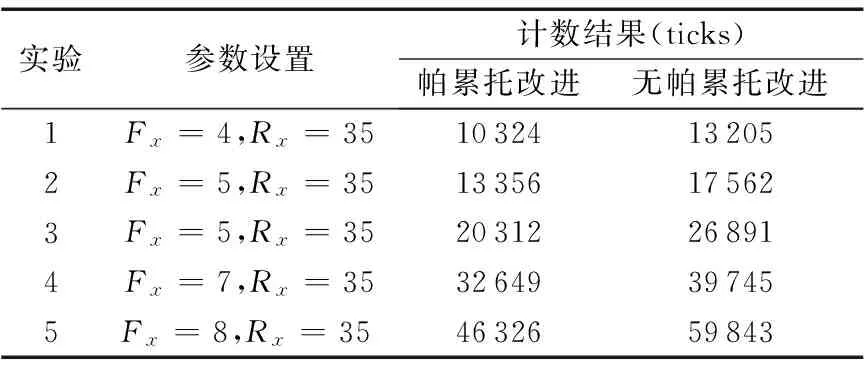
表2 不同算法时钟计数器结果Tab. 2 Clock counter results of different algorithms

图4 不同算法时间对比Fig. 4 Time comparison of different algorithms
4.2 使用帕累托改进收益结果
同样使用上述实验方式进行多次对比实验,对救火任务进行量化,将单个火势的收益根据火势大小设置为500~2 000,多机器人每移动一个单位所损耗的能量设置为0.1,参与救火任务时每消灭一个单位的火势损耗的能量设置为0.4,能量统计及收益情况由Netlogo中设计的海龟观测图进行展示,使用帕累托改进的多机器人执行任务的收益结果如图5所示。
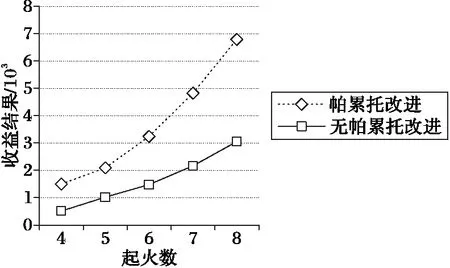
图5 不同算法收益对比Fig. 5 Revenue comparison of different algorithms
由图5可以看出,在所有起火数量相同的对比实验中,帕累托改进后算法收益结果优于无帕累托改进的算法;随着起火数量的增加,两种算法的收益结果差距明显增大。实验结果表明,多机器人系统使用帕累托改进算法进行二次分配后收益效果要明显好于基于合同网的任务分配算法,这种优势随着任务数量的增加更加明显。
4.3 对比蚁群算法和强化学习算法
为对比帕累托改进算法与其他任务分配算法的任务执行效率,三种算法使用相同的表1中参数进行对比实验,按照起火数量进行5组对比实验分析,每次实验重复50次。将任务分配分为初始化任务分配阶段和任务完成阶段,系统中所有机器人均参与到任务中定义为初始化任务分配完成,初始化任务分配完成到所有火势消灭定义为任务完成阶段。分析对比三种算法所用的两阶段时间如表3所示,帕累托改进算法相较于蚁群算法和强化学习算法在初始化任务分配阶段和任务执行阶段的效率都有明显提升,尤其是初始化任务分配阶段有很大的提高,这对于具有紧急性特点的救火任务来说能够第一时间有效控制火势的蔓延非常重要。实验结果表明,帕累托改进算法在救火任务时间上相较于强化学习算法下降26.18%,相较于蚁群算法下降37.04%。帕累托改进算法在整个救火任务效率明显好于强化学习算法和蚁群算法。
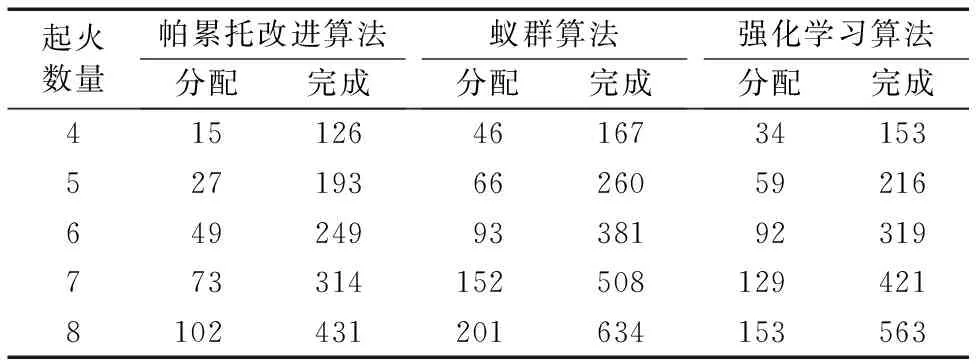
表3 不同算法两阶段时间对比 sTab. 3 Time comparison of two stages of different algorithms s
5 结语
为研究多机器人领域内的动态任务分配问题,本文在Netlogo仿真平台上建立多机器人救火任务模型,提出在合同网初始任务分配基础上进行基于帕累托改进的二次任务分配的算法,针对任务模型的特点构造收益函数,并设计相关协商策略。仿真实验结果表明,使用帕累托改进对任务分配进行再次分配可以有效提高多机器人系统工作效率,同时可以增加系统总收益。本文的策略都是基于协商的,因此在通信量控制方面有所不足,对通信要求高,下一步工作在保证高效、高收益的情况下控制通信量,保证多机器人系统各项属性更加平衡。
References)
[1] YANG C, LI J, LI Z. Optimized adaptive control design and NN based trajectory planning for a class of wheeled inverted pendulum vehicle models [J]. IEEE Transactions on Cybernetics, 2013, 43(1): 24-35.
[2] YANG C G, GANESH G, HADDADIN S, et al. Human-like adaptation of force and impedance in stable and unstable interactions [J]. IEEE Transactions on Robotics, 2011, 27(5): 918-930.
[3] CUI R X, GE S S, HOW B V E, et al. Leader-follower formation control of underactuated autonomous underwater vehicles [J]. Ocean Engineering, 2010, 37(17/18): 1491-1502.
[4] LI Z J, LI J X, KANG Y. Adaptive robust coordinated control of multiple mobile manipulators interacting with rigid environments [J]. Automatica, 2010, 46(12): 2028-2034.
[5] LI Z J, CAO X Q, DING N. Adaptive fuzzy control for synchronization of nonlinear teleoperators with stochastic time-varying communication delays [J]. IEEE Transactions on Fuzzy Systems, 2011, 19(4): 745-757.
[6] ELANGO M, NACHIAPPAN S, TIWARI M K. Balancing task allocation in multi-robot systems usingK-means clustering and auction based mechanisms [J]. Expert Systems with Applications, 2011, 38(6): 6486-6491.
[7] GERKEY B P, MATARIC M J. A formal framework for the study of task allocation in multi-robot systems [J]. International Journal of Robotics Research, 2003, 23(9): 1-17.
[8] 吴军,徐昕,连传强,等.协作多机器人系统研究进展综述[J].智能系统学报,2011,6(1):13-27.(WU J, XU X, LIAN C Q, et al. A survey of recent advances in cooperative multi-robot systems [J] . CAAI Transactions on Intelligent Systems, 2011, 6(1): 13-27.)
[9] SANDHOLM T. An implementation of the contract net protocol based on marginal cost calculations [C]// Proceedings of the 1993 Eleventh National Conference on Artificial Intelligence. Menlo Park: AAAI, 1993: 256-262.
[10] KARTAL B, NUNES E, GODOY J, et al. Monte Carlo tree search for multi-robot task allocation [C]// Proceedings of the 2016 Thirtieth AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2016: 4222-4223.
[11] 李明,刘玮,张彦铎.基于改进合同网协议的多Agent动态任务分配[J].山东大学学报(工学版),2016,46(2):51-56.(LI M, LIU W, ZHANG Y D. Mulit-agent dynamic task allocation based on improved contract net protocol [J]. Journal of Shandong University (Engineering Science), 2016, 46 (2): 51-56.)
[12] BARILE F, ROSSI A, STAFFA M, et al. A market mechanism for qos-aware multi-robot task allocation [EB/OL]. [2017- 04- 06]. http://ceur-ws.org/Vol-1382/paper20.pdf.
[13] CUI R, GAO J G B. Game theory-based negotiation for multiple robots task allocation [J]. Robotica, 2013, 31(6): 923-934.
[14] 沈莉,李杰,朱华勇.基于交换树的多机器人任务协调与负荷平衡方法[J].计算机应用,2016,36(11):3127-3130,3135.(SHEN L, LI J, ZHU H Y. Task coordination and workload balance method for multi-robot based on trading tree [J]. Journal of Computer Applications, 2016, 36 (11): 3127-3130, 3135.)
[15] 张云正,薛颂东,曾建潮.群机器人多目标搜索中的合作协同和竞争协同[J].机器人,2015,37(2):142-151.(ZHANG Y Z, XUE S D, ZENG J C. Cooperative and competitive coordination in swarm robotic search for multiple targets [J]. Robot, 2015, 37(2): 142-151.)
[16] SANDHOLM T. Algorithm for optimal winner determination in combinatorial auctions [J]. Artificial Intelligence, 2002, 135(1/2): 1-54.
[17] TISUE S, WILENSKY U. Netlogo: a simple environment for modeling complexity [EB/OL]. [2017- 04- 06]. http://www.ccl.sesp.northwestern.edu/papers/netlogo-iccs2004.pdf.
This work is partially supported by the National Defense Pre-Research Foundation of China (GFZ17040406004).
JIANGDong, born in 1990, M. S. candidate. His research interests include information security, collaborative multi-robot, distributed instant messaging, block chain.
XUXin, born in 1975, Ph. D., professor. His research interests include information security, solid state storage, distributed instant messaging.
Multi-robotdynamictaskallocationalgorithmbasedonParetoimprovment
JIANG Dong, XU Xin*
(CollegeofCommunicationEngineering,HangzhouDianziUniversity,HangzhouZhejiang310018,China)
In order to solve the optimization problem of dynamic task allocation in multi-robot system, a new quadratic task allocation algorithm based on Pareto improvement was proposed based on the initial task allocation of contract net. When the fire fighting task was performed by the multi-robot system in parallel, firstly, the multiple robots were divided into several sub-group through the initialization of task allocation. Then, a fire fighting task was undertook by a subgroup, and the robots needed to be migrated were determined by the Pareto improvement of the subgroup and its nearest subgroup while the subgroup performing the task to achieve the Pareto optimality between the two subgroups. Finally, the global Pareto optimality was achieved by the Pareto improvement of all subgroups with posterior binary tree traversal. The theoretical analysis and simulation results show that, compared with reinforcement learning algorithm and ant colony algorithm, the fire fighting time of the proposed algorithm is reduced by 26.18% and 37.04% respectively. And compared with the traditional contract net method, the proposed algorithm can perform the fire fighting task efficiently in time, and also has the obvious advantage in system revenue.
multi-robot; fire fighting task; task allocation; contract net; Pareto improvement; Pareto optimality
2017- 06- 29;
2017- 09- 05。
国防预研基金资助项目(GFZ17040406004)。
姜栋(1990—),男,山东泰安人,硕士研究生,主要研究方向:信息安全、协作多机器人、分布式即时通信、区块链; 徐欣(1975—),男,浙江缙云人,教授,博士,主要研究方向:信息安全、固态存储、分布式即时通信。
1001- 9081(2017)12- 3620- 05
10.11772/j.issn.1001- 9081.2017.12.3620
(*通信作者电子邮箱jaedong1126@foxmail.com)
TP242.6
A
