个性化推荐系统中相似度计算的优化
2018-01-06潘磊
潘磊
(江苏科技大学计算机科学与工程学院,江苏镇江212003)
个性化推荐系统中相似度计算的优化
潘磊
(江苏科技大学计算机科学与工程学院,江苏镇江212003)
个性化推荐系统能够比较有效的解决我们获取信息时遇到的信息过载问题,发展至今产生了许多经典的推荐算法,其中最成熟应用最为广泛的是协同过滤算法。相似度的准确计算在协同过滤算法中起到了非常重要的作用,为了进一步提高推荐系统的推荐准确率,本文对相似度计算方法进行了研究。通过项目相似度和评分差异性对计算结果影响的大小,计算时给予不同的权重,并在MovieLens上对推荐结果进行预测,试验结果显示,MAE值降低了2.5%,优化后的相似度计算方法可以提高个性化推荐系统的推荐准确率。
推荐系统;项目相似度;评分差异性;协同过滤;准确率
随着Web2.0时代的到来,网络给人们日常生活带来便利的同时也制造了麻烦。在信息的汪洋大海中,用户寻找感兴趣的信息变得异常困难,往往把宝贵的时间和精力浪费在过滤无用的信息上。对于信息过载问题[1]通常的解决办法有3种:第一种是搜索引擎,谷歌是其中的代表;第二种是分类目录,有代表性的有雅虎和Hao123等网站;第三类是个性化系统。本文主要研究的是第三类解决方案,在基于协同过滤的个性化系统中,优化相似度的计算方法,从而提高推荐结果的准确性。
协同过滤算法中相似度计算在找到相似用户或者物品时起到很重要的作用,影响着最终推荐结果的准确度和用户满意度[2]。因此,本文在研究传统的相似度计算方法基础之上,引入物品相似度,并且根据数据集的特点,细粒度的考虑了不同用户评分之间的差异性。
1 常用的相似度计算方法介绍
协同过滤算法中邻居的兴趣能在一定程度上反映用户的兴趣,因此通常要找到用户或者物品的邻居[3],据此给出推荐列表。根据邻居的挑选原则,我们通常可以把他们分成两类:一类是固定数量的邻居(K-neighborhoods):不论邻居的“远近”,只取最近的K个,作为其邻居。另一类是基于相似度门槛的邻居(Threshold-based neighborhoods)。不论采用哪一种方法,要获得近邻首要的问题就是计算相似度,然后再根据相似度确定邻居集合,本文主要是以基于用户的协同过滤算法为例。
1.1 传统的用户相似度计算

1)欧几里德距离(Euclidean Distance):

2)皮尔逊相关系数(Pearson Correlation Coefficient):

3)Cosine相似度(Cosine Similarity):

4)Jacard系数余弦相关系数的扩展:

1.2 传统的用户相似度计算的分析
欧几里德定义的相关系数利用评分矩阵中用户a,b对共同评分项目Tab的项目评分的二范数来计算用户的相似度,分母中的平方项放大了用户a,b评分差异带来的计算误差。皮尔逊相关系数P取值在-1与+1之间,若P>0,表明两个变量是正相关;若P<0,表明两个变量是负相关。余弦相似度利用利用a,b用户评分向量的余弦夹角来计算相似度,取值为0到1,取值越大代表相关性越大。Jacard系数是对余弦系数的扩展,考虑了Ra,Rb长度。传统的相似度计算应用到具体的数据集上,例如Movelens数据集,我们可以充分利用数据集自身的特点进行优化,传统相似度计算没有考虑:
1)两个用户对同一个物品评价分值的差异对物品的影响。如果两个用户同时给高分或者同时给低分,在某种程度上更能反映用户间兴趣的相似性,但是如果两个用户对同一物品评分的分值差异比较大,更能说明不同用户间的兴趣偏好的差异性较大,在计算用户相似度时应该细化考虑,分别给予不同的权重值。
2)两个用户评价的项目的相似度对最终计算结果的影响。评分矩阵的行向量,也即用户对公共评分项目的评分向量,如果两个用户之间评分的项目更加相似,那么在计算用户相似度时应该适当的增加权重。
2 相似度计算方法的改进
针对上述相似度计算的讨论可以对算法进行相应的改进,考虑项目相似度[4],利传统的相似度计算方法计算得到所有项目之间的相似度矩阵Mnn,代表项目之间的相似度,定义:

代表a,b用户间共同评价项目与目标项目之间的相似度之和,w1越大说明用户评价的物品越相似,计算用户相似度时应该适当增加权重。同时考虑不同用户的评分差异性,定义权重因子,假设在评分值区间为1~5分的系统中,认为小于等于2分为低评分,大于等于4分认为是高评分,评分差值大于3分的认为评分差异较大,给出如下定义:

综合起来考虑定义权重因子:
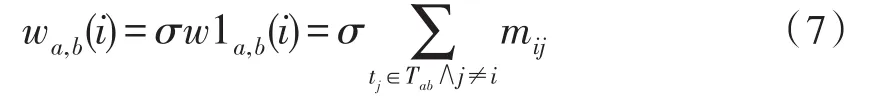
根据公式wa,b(i)给出算法的描述和过程。
算法:计算用户相似度权重
输入:用户A,B、用户-项目评分矩阵R、项目之间的相似度矩阵Mnn、A,B共同评分项目Tab
输出:wa,b(i)
Step1:wa,b(i)=0,T=Tab;
Step2:从T中取出uj,T=T-{uj};
Step3:Mnn查找mij;
Step4:查找评分矩阵R,计算|raj-rbj|,根据公式(6)确定参数σ;
Step5:wa,b(i)=wa,b(i)+σmij;
Step6:T=∅结束,否则跳转到第二步。
根据上面得到的wa,b(i)改进后的皮尔逊相关系数为:

改进后的Jacard相似度为:

3 实验结果与分析
本文采用MovieLens数据集进行实验,对改进前后的相似度采用MAE值进行评测比较。每个用户对已经看过的电影根据个人满意度给予不同的评分值,不同的评分值代表用户兴趣度的不同,评分值的区间为1~5分,评分值高低代表了用户的偏好,最后通过MAE对改进后的系统推荐结果评测。MAE是现在被广泛认可的评价指标之一,可以真实的反映实际评分与预测评分之间的误差大小,公式如下:
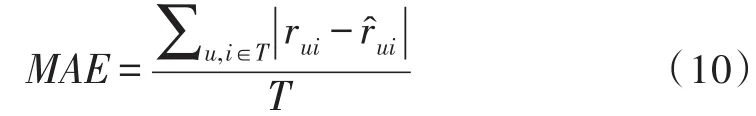
实验通过MATLAB完成,经过多次试验调优,发现(σ1,σ2,σ3)=(1.1,1.1,0.8)时,实验效果最佳,实验结果如图1、2所示。
图1对比了基于Jacard系数优化前后的协同过滤算法的MAE值,从图上可以看出,随着邻居集的个数增加MAE值也随之下降,直到邻居个数达到80以上,MAE值趋于稳定。实验结果显示,采用优化后的Jacard系数的协同过滤算法,推荐结果的MAE值有明显的降低,推荐准确率更高。
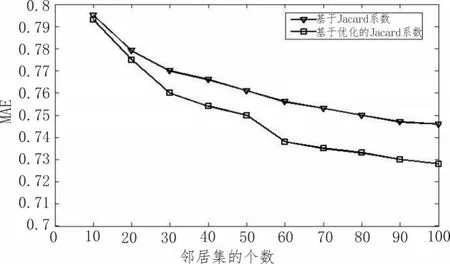
图1 基于优化的Jacard系数的协同过滤算法的MAE

图2 基于优化的皮尔逊相关系数的协同过滤算法的MAE
图2对比了基于皮尔逊相关系数优化前后的协同过滤算法的MAE,从图上可以看出,随着邻居集的个数增加MAE值也随之下降,直到邻居个数达到80以上,MAE值趋于稳定。实验结果显示,采用优化后的皮尔逊相关系数的协同过滤算法,推荐结果MAE有明显的下降,推荐准确率较高。
对比两幅实验结果图可知,随着邻居集的增加,两条曲线的MAE的差值增大,直到邻居集的个数达到80以上MAE值趋于稳定。实验结果表明,本文改进后的相关性计算方法,在某种程度上可以有效地降低基于协同过滤的推荐系统的MAE值,提高系统的准确度和用户满意度。但是由于本实验只是在MovieLens数据集上取得可比较好的结果,在其他数据集上的表现仍待进一步验证。
4 结束语
传统的推荐系统的不足在于没有衡量用户间评分的差异性和项目相似性的差异对相似度计算结果的影响。本文针对这两点进行改进,提升了推荐结果的准确率,但是由于引入了项目相似度的计算,增加了系统的时空复杂度,影响系统的性能。σ参数的确定需要多次试验获才能获得,同时由于增加了相似物品在相似度计算中的权重,有可能会导致覆盖率的下降,产生长尾效应[7],如何增加对长尾商品的推荐,这些问题仍然需要进一步讨论和研究。
[1]项亮.推荐系统实战[M].北京:人民邮电出版社,2012.
[2]周涛.个性化推荐的十大挑战[EB/DL].http://blog.sciencenet.cn/blog-3075-588779.html,2012-07-04.
[3]李春,李珍民,高晓芳,等.基于邻居决策的协同过滤推荐算法[J].计算机工程,2010,36(13):34.
[4]荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
[5]汪静,印鉴,郑利荣,等.基于共同评分和相似权重的协同过滤推荐算法[J].计算机科学,2010(2):99-104.
[6]冯媛媛,王晓东,姚宇.电子商务长尾物品的推荐[J].计算机应用,2015,35(S2):151-154.
[7]杨博,赵鹏飞.推荐算法综述[J].山西大学学报,2011,34(3):337-350.
[8]孙辉,马跃,杨海波,等.一种相似度改进的用户聚类协同过滤推荐爱算法[J].小型微型计算机系统,2014,35(9):1967-1970.
[9]刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述,计算机科学,2012,39(2):8-13.
[10]冷亚军,梁昌勇,陆青,等基于近邻评分填补的协同过滤推荐算法[J].计算机工程 2012,38(21):56-60.
[11]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[12]徐文龙,严泳键.结合项目相似度的协同过滤算法[J].计算机应用与软件,2013,30(9):293-295.
[13]朱文奇.推荐系统用户相似度计算方法研究[D].重庆:重庆大学,2014.
[14]陈如明.大数据时代的挑战、价值与对应策略[J].移动通信,2012,36(17):14-15.
[15](奥地利)Dietmar Jannach等著.推荐系统[M].蒋凡译.北京:人民邮电出版社,2013.
[16]徐翔,王煦法.协同过滤算法中的相似度优化方法[J].计算机工程,2010,36(6):92-95.
Optimized similarity calculation in personalized recommendation system
PAN Lei
(School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang212003 ,China)
Personalized recommendation system can effectively solve the information overload problem.Many classic recommendation algorithms have came into our world with the development of the recommendation system technology.Collaborative filtering algorithm is the one most widely used.Similarity plays a very important role in collaborative filtering algorithm.In order to improve the recommendation accuracy of recommendation system,we research the similarity calculation method in this paper.We optimize the traditional similarity calculation method,considering item similarity and difference in score,give different weights when we calculate the similarity.At last,we forecast the result of the recommendation on the data set named MovieLens.The result of the exprement shows that the value of MAE decreases by 2.5%and the optimized method increases recommendation accuracy.
ecommendation system;item similarity;score difference;collaborative filtering;accuracy
TN0
A
1674-6236(2017)23-0055-04
2016-11-21稿件编号:201611156
潘磊(1988—),男,江苏泗洪人,硕士研究生。研究方向:数据挖掘,个性化推荐。
