网络谣言文本句式特征分析与监测系统
2018-01-06姜赢张婧朱玲萱渠畅
姜赢,张婧,朱玲萱,渠畅
(北京师范大学珠海分校管理学院,广东珠海519087)
网络谣言文本句式特征分析与监测系统
姜赢,张婧,朱玲萱,渠畅
(北京师范大学珠海分校管理学院,广东珠海519087)
基于实现网络谣言自动识别的目的,从地域、时间和传播形式3个维度分析了收集到的网络谣言基本情况。网络谣言以文本传播形式为主,而且在文本句式上有一定的共通点和相似之处。本文采用了五类网络谣言文本句式特征分析方法,结合LanguageTool构建了一系列基于XML的网络谣言句式匹配规则。通过对收集到的网络谣言实验测试,得出此方法能够实现网络谣言的自动识别和监测,可以减少50%以上的人工识别工作量的结论。
网络谣言;句式特征;LanguageTool;XML
网络谣言传播者善于运用富有煽动性的句式和语气来扩大传播面积和影响力。例如“请把它转达给每一个你珍惜和喜爱的人”、“是中国人就应该转”等都是网络谣言经常使用的语句。网络谣言传播者往往首先把自己撇清,把信息来源指向不确定的某个地方,常用些“信不信由你”的词语。另外,在网络上感叹号密集、疯狂煽情、强调语句聚集,以及“是。就顶楼主”之类的的语句也往往是谣言。由此可见,谣言文本句式的特征具有一定规律,而且有迹可循。总结、分析这些与特征与规律,并用于提高网络谣言的识别率,对实现网络谣言实时监测和主动预警有重要意义。
1 研究现状分析
在网络谣言分类方面,近年来国内学者经过调研发现[15-16],网络谣言主要包括医疗卫生、社会政治、灾害安全等类型,以及一些广受关注热点问题[2,5,14]。北京师范大学心理学院孙嘉卿[10]通过对新浪微博辟谣信息的统计分析,总结出有6种被反复使用的微博谣言辟谣方式。在网络谣言的治理方面,武汉大学马克思主义学院周润[3]、徐州师范大学安仲森[6],湖南水利水电职业技术学院刘河元[8],不约而同的提出应在政府(法制建设与信息公开)、单位(网络监管与思想教育)[11]和个人(个人素质提高与自律)等多个部门和层面多管齐下进行标本兼治;上海对外贸易学院姚福生[4]认为谣言治理的基础在于信息透明,必须进一步推进信息公开,而对谣言治理必须及时,掌握最佳时间,要做“第一定义者”的及时性;武汉工业学院胡频伟提出,防范和处置网络谣言首先要认识到建立监测系统在早期预警系统中的作用,包括网络谣言监测、识别、系统、评价、处置和反馈系统。北京邮电大学公共管理学院王欢等[7]提出网络谣言的治理框架建包括6个“止于”:信源控制止于智者、内容控制止于公开、过程控制止于及时、社会环境控制止于机制与法制、网络环境控制止于技术。另外,广东白云学院[9]对于学生工作网络舆情信息监控工作进行了实证研究。
综上所述,网络谣言传播原因主要有:1)网络准入门槛低:一台连接网络的设备,就可以轻松申请到一个微博账号,缺乏监管,微博上出现一类群体“网络水军”,他们人数众多,出于某种商业目的,会对某一言论一边倒评论,为达到雇主需求而捏造事实。因此,网民很难判断出某一微博信息是否真实。2)从众心理导致趋向传播:人们在接受信息时,会考虑信息是否与自己认知保持一致,当认知一致时,大多会进行传播。从众心理使得网民在群体压力下产生群体自我膨胀的现象,以群体的决策为正确的,经常造成谣言的肆意传播。当面对外部大量信息的刺激,个体容易随波逐流,表现出强烈的从众行为。3)网民约束力较差:由于因特网协议的开放性和管理方式的分散性,互联网上的信息传播和交流是很少受政府管制的,在网络空间中,先进的科技造就了一批迷失的“网络人”,“网络人”长期活动在互联网上,丧失道德判断能力和责任感。容易被谣言所捕获,成为谣言传播的载体。4)“把关人”缺失:“把关人”词义是“是在向受传者传递信息的过程中,有权控制信息的流量和流向,影响着对信息的理解,决定让哪些信息通过以及如何通过的人或机构”,这个“把关人”一般由政府,媒体担任,他们的职责是对信息进行选择和筛选,并防止个人意志通过媒体传达给大众,尽力保持客观,公证,平衡的准则。新兴媒体不断加入,纷纷创办各自的网站,但网络的采编和渠道审核程序不同,缺乏“守门人”的监管机制,这样会让一些大型门户网站会出现虚假信息,并且利用自己的权威和力量,使得小道消息快速传播开来,为网络谣言打开一道大路。同时,在微博上,每个人都是信息的传播者和发布者,“把关人”的角色几乎消失无存,登陆微博发布信息,不需要经过任何审查和等待,所发布的内容就会出现在网上,并可以被网民所看到。根据我们所调查的数据,几乎有80%的校园谣言和社会谣言是通过个人发布端发送出来,所以“把关人”的缺失是导致谣言信息传播迅速的原因之一。
但是目前未见专门针对网络谣言文本句式特征分析的相关研究报道。在此背景下,本文提出在网络谣言文本句式特征分析基础之上,利用基于Languagtool[13]的XML[12]模式匹配识别技术实现网络谣言的自动识别和监测。
2 网络谣言数据来源及特征
本文研究的网络谣言数据主要来自3个渠道:1)采用网络调研和文献分析等方法,从人人网、腾讯微信、腾讯QQ、新浪微博、百度贴吧以及相关BBS网址等收集到网络谣言相关公开的373个相关链接、340个谣言事件;2)通过分组调研,从微信朋友圈、腾讯QQ等自媒体等途径收集了345条朋友间转发的网络谣言私密信息。3)利用新浪微博虚假消息辟谣官方账号“微博辟谣”收集了6个月(2015年7月1日至2015年12月15日)该平台公布的453个社会谣言事件。笔者对这些不同渠道的数据进行了人工筛选、去重、分类和汇总,最终建立了包含345条网络谣言的案例库。以下从地域、内容和传播形式3个维度对这些网络谣言数据基本情况进行介绍。
2.1 地域维度
网络谣言具有明显的地域指向,即发生在某地某市,或者是针对某市某省所散布的谣言。例如,“扬州曲江公园砍人、江都金牛湾发生武力事件多人倒地”、“湛江到广东9 570头家禽感染”和“深圳有多人被感染”等等。如表1所示,与地域相关的网络谣言有289条,其中与中国大陆相关的有272条。

表1 网络谣言指向地区分类汇总表
2.2 内容维度
网络谣言内容上依据按一般传统媒体的新闻分类法分为:政治、经济、法律、军事、科技、文教、卫体、社会等等新闻。如表2所示,此处所称的社会新闻内容很多,包括民生新闻、新闻热线中读者、听众、观众提供的新闻线索等。社会新闻大多数以负面的表达出现,如“特警暴力执法强拆,侵占老百姓田地”、“廉江一产妇在分娩时身亡,家属聚集妇幼保健院门口烧黄纸讨说法!”等等。
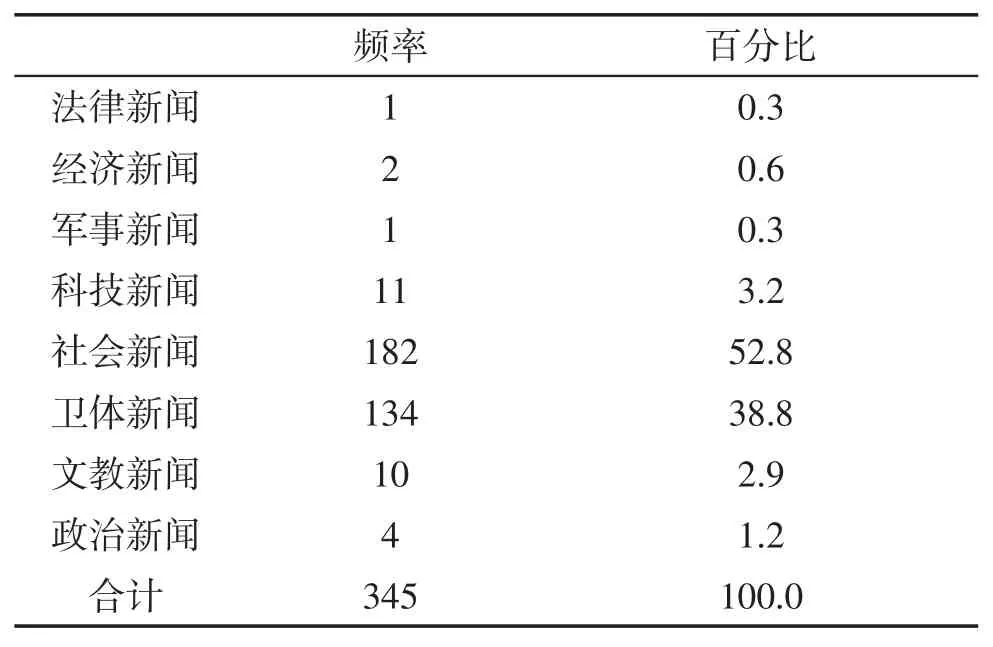
表2 网络谣言内容分类统计表
2.3 传播形式维度
如表3所示,网络谣言传播形式非常集中,接近九成是以文字直接进行传播。极少数谣言是以视频、图片、图文、文视进行传播。且这些网络谣言中,内容也集中在与社会人群息息相关的社会新闻和卫体新闻。

表3 网络谣言传播形式分类统计表
3 网络谣言文本句式特征
笔者在对收集到的309条以文字为传播形式的网络谣言的分析过程中,发现网络谣言在句式上都会有一定的共通点和相似之处,主要存在以下这些较为显著的句式。
3.1 通知警示类
句式:“温馨提示|紧急通知|宣布|最新消息|注意:|,……否则|以免|请|别|不要”;“今天才得知|现在才发现……竟然|会|可以”;“最近|近日|这段时间……”。例如:“温馨提示:按照我省交警总队要求,2016年七月一日起将增加科目五考察(高速公路的安全驾驶),请大家最好在七月一日前考完科目四,否则考试结束时间将无法确定!”,“最新消息,根据中央电视台发布的消息,由于微信红包被利用成赌博工具,将会在10月20日正式取消微信红包,请各位把微信的零钱取现,否则将无法取出。”这类句式是通过一些警示或通知的语句来引起他人的注意从而达到谣言的传播。
3.2 请求转发类
句式:“……请|求|……扩散|转发|群发|散播”;“……收到马上发给|转发”;“……转发……可以|得到”;“……互相转告|一定要转发|中国人就转发”。例如:“注意了!!!粤CJJ217,黑色轿车,在小学门口抢小学生!!!警方已经初步证实了!!已经在全省范围内通缉!!不求点赞只求扩散!请看好自己的小孩!看见了转下,提醒下大家,否则留下就是终身的遗憾了”,“紧急通知,暂时别吃鸡肉,鸭肉,因河南省安阳市5570头家禽已感染。收到马上发给你关心的人,预防永远胜过治疗。看到,群发扩散!!!”。这类句式一般情况下会结合句式1一起使用,通过呼吁他人转发从而使谣言大规模扩散。
3.3 针对人群类
句式:”……小孩|男孩|女孩|儿童|孩子|学生|老人……被|注意|死|伤|遭……”;“抢|走失|抱|杀|丢|找……小孩|男孩|女孩|儿童|孩子|学生|老人”;“太原四岁小女孩被晋中牌照面包车抢走”;“一条三岁多小女孩在锦绣花园小区附近被拐”;“贵港大将宏名中学有女学生被迷奸。”。这类句式主要是通过人们对这么群体的关注和特殊情感,从而吸引人们的眼球达到传播谣言的目的。
3.4 健康科普类
句式:“……可以|能够预防|导致|治疗|治愈|造成……”;“……通过|使用……可以|能|导致……”;“专家|科学家|实验|研究指出证明|称……可|能|导致|造成……”。例如:“权威科学杂志消息:用花生油或橄榄油等植物油炒菜,有导致包括肿瘤在内的各种病症的可能。所以,推荐使用芝麻油、牛油、椰子油或者猪油取代一般的植物油。”;“地热供暖有一定辐射危害,使用地暖还会导致小孩白血病、诱发肿瘤、破坏循环系统、严重影响儿童智力、危害心血管健康、导致视力低下等6大危害……”。
3.5 概数类
句式:“余|多|数|上万”。例如:“福建有一艘偷渡到美国的船沉了,10余名福建人淹死。”;“有100多个新疆人,现已经到了监利县附近,专来偷小孩抢小孩,监利县一带已丢了20多个小孩。”。这一类多数用一下不准确、夸大、大概的数值来吸引人们的注意,形成一种以假乱真的效果。
4 基于LanguageTool的网络谣言监测系统
LanguageTool是一款集合英语、法语、德语、中文等多国语言的新型、开源、可扩展式自然语言监测系统[1]。LanguageTool专注于检测复杂的字词形态结构错误、用词错误和句法错误等自然语言的抽象逻辑错误,并最大限度提供最具可能性的匹配结果。笔者利用LanguageTool构建基于XML[12]的网络谣言句式匹配规则,并对收集到的网络谣言进行了测试。
4.1 XML匹配规则设计
笔者将五类网络谣言文本句式分别设计了五个匹配规则组rulegroup。如图1所示,请求转发类谣言包含两个匹配规则rule。每个rule又由一系列的token逐个进行匹配。每个token可以使用正则表达式(regex=“yes”)和词性标注(postag)进行条件匹配。其中min的值代表可以重复的此token最少次数,如果等于0则表示可以有这个token也可以没有。skip的值代表可以跳过的下一个token的个数,如果等于1则表示可以跳过至多1个token。另外,message是针对匹配监测到的谣言文本的警告语言。
4.2 实验测试结果
笔者使用Languagetool自带的testrules.bat工具对每个规则进行测试,被测试的实验数据为收集到的345条网络谣言。经过测试发现,监测匹配到“通知警示类”的网络谣言句式的有50条网络谣言,匹配“请求转发类”句式的有38条,匹配“针对人群类”句式的有34条,匹配“健康科普类”句式的有58条,匹配“概数类”句式的有10条。总之,345条网络谣言数据中的190条被监测到了,识别率达超过了50%。而另外一部分网络谣言文本句式特征并不明显,未能监测匹配到。如果将此方法和技术用于网络谣言监测实践,至少可以减少50%以上的人工识别的工作量。

图1 请求转发类谣言XM匹配规则
5 结论
本文在总结前人网络谣言理论研究基础之上,以文本句式特征分析为切入点,研发出基于LanguageTool的网络谣言自动检测系统。该方法说明网络谣言自动检测是可以实现的,能够大幅减少人工检测工作量。该系统还可以根据不同领域的应用需要通过扩展XML匹配规则库来进一步优化网络谣言识别和监测的效率和效果。
[1]姜赢,曾杰,林启红,等.LanguageTool中文语法校对XML规则定制方法[J].图书情报工作,2014(5):86-92.
[2]张薇,张雷.大学生网络谣言问题的探因与对策研究[J].金田,2012(10):322-323.
[3]周润,张斌,黄巧仙,等.网络谣言对高校网络思想政治教育工作的挑战及对策研究——从重庆交大学生“针刺”谣言事件说起[J].湖北第二师范学院学报,2013,30(1):50-52,68.
[4]姚福生.校园谣言透析与治理[J].思想理论教育(上半月综合版),2013(2):86-89,94.
[5]孙丽.网络谣言的类型与特征[J].电子政务,2015(1):18-23.
[6]安仲森.论网络谣言对高校德育工作的挑战与应对举措[J].湖北省社会主义学院学报,2011(5):80-83.
[7]王欢,祝阳.“微博时代”反腐败类谣言的治理策略研究[J].现代情报,2013,33(7):7-11.
[8]刘河元.网络谣言对大学生伦理道德的影响及应对策略[J].世纪桥,2012(19):51-52.
[9]李林,李建华,杨宝丽,等.高校微博舆情的监控与引导——以广东白云学院为例[J].高校辅导员学刊,2012(6):49-52.
[10]孙嘉卿.微博谣言特征及辟谣策略研究——基于新浪微博的质性研[J].中国出版杂志,2012(10):21-24.
[11]张兵.基于微博的大学生思想政治教育探索[J].枣庄学院学报,2011(1):23-25.
[12]孙温稳.XML文本的标准化[J].电子技术与软件工程,2016(7):187.
[13]Ying Jiang,Tong Wang,Tao Lin,et al.A rule based chinese spelling and grammar detection system utility[C]// In Proceedings of 2012 International Conference on System Science and Engineering(ICSSE 2012):437-440.
[14]黎慈.大学生传播网络谣言的诱因与教育管理对策研究[J].河北公安警察职业学院学报,2013(1):71-74.
[15]杨庆国,陈敬良.公共事件中大学生短信谣言传播危机意识调查[J].当代青年研究,2012(1):66-71.
[16]刘超.微博谣言防控措施研究[J].网络安全技术与应用,2012(3):75-77.
Analysis of online rumor text syntactical structure features and the monitoring system
JIANG Ying,ZHANG Jing,ZHU Ling-xuan,QU Chang
(School of Management,Beijing Normal University,Zhuhai519087,China)
In order to realize online rumors automatic identification,it introduces the collected online rumors in the three dimensions of location,time and spreading media.The main spreading media is text based on analysis,with common and similar text syntactical structure features.Five text syntactical structure features are summarized,based on which a series of online rumor text syntactical structure XML rules are constructed.Tests are performed upon the collected online rumors,which shows that it can realize the automatic identifying and monitoring the online rumors,with half of the manual work-load reduced.
online rumors;syntactical structure feature;LanguageTool;XML
TN99
A
1674-6236(2017)23-0007-04
2016-11-27稿件编号:201611217
广东省自然科学基金项目(2016A030313386);广东省教育厅省级学校德育创新项目(2015DYZD015)
姜赢(1981—),男,湖北武汉人,博士,副教授。研究方向:网络舆情监控。
