基于卷积神经网络的场景图像文本定位研究
2018-01-06熊海朋陈洋洋陈春玮
熊海朋,陈洋洋,陈春玮
(杭州电子科技大学 计算机学院,浙江杭州310018)
基于卷积神经网络的场景图像文本定位研究
熊海朋,陈洋洋,陈春玮
(杭州电子科技大学 计算机学院,浙江杭州310018)
针对由于自然场景的复杂性,从自然场景图像中提取出文本信息较困难的问题,文中提出了一种基于深度学习卷积神经网络的文本定位算法。通过对场景图像进行预处理得到候选文本区域,在此基础上结合深度学习中的卷积神经网络来自动提取文本特征进行进一步的定位。通过实验验证,定位的准确率可达86%,综合性能较好。
文本定位;二值化;自然场景图像;卷积神经网络
自然场景图像中包含着许多高层次的语义信息,例如交通路标、门牌号、街道名称等,是对场景内容的重要反映。提取自然场景中的文本信息需要经过3个步骤:定位出文本区域、对文本区域进行分割,对分割区域进行识别。文本定位作为提取文本信息的第一步,定位效果至关重要。因为场景图像自身背景复杂,并且由于光照变换,字体等客观因素的影响,导致文本定位问题至今仍是一个难题。
目前来说,采用的定位研究方法主要有基于图像连通区域[1-3]、基于图像的纹理特征[4-6]、以及基于图像中的角点[7-8]这3种方法。以这些基本方法针对具体应用取得了较好的效果,但是在复杂的场景下通常存在虚警率较高的问题,为解决这一问题,把这些基本方法进行合理的组合再结合机器学习进行定位是一种有效的思路[9-12],大幅提高了复杂场景文本定位的鲁棒性和效率。但是这些方法都需要人为提取图像中文本区域的特征,导致算法性能的优劣与人的主观因素密切相关。通过对上述研究现状的分析,本文提出了一种基于深度卷积神经网络(Convolutional Neural Network,CNN)的图像文本定位算法,首先通过预处理措施得到图像中的候选文本区域。然后基于卷积神经网络的自学习特点,准备好训练样本集,通过有监督的学习自动提取文本特征得到分类模型,最后利用该模型对候选文本区域进行进一步的定位。在自建图像数据库上,对本文算法进行了综合测试。
1 文本定位方法
图1 说明了本文算法的整体流程,主要包括预处理(灰度化,二值化)、生成候选文本区域(形态学运算,连通区域分析与限制)以及最终使用卷积神经网络进行进一步的分类。

图1 场景图像文本定位算法的整体流程
2 预处理阶段
对场景图像进行一系列的预处理,尽量去除图像中像素的冗余信息,减少后续步骤的计算量。
2.1 灰度化处理
采集自然场景图像,对其进行灰度化处理,本文采用加权平均法来进行处理,该方法计算方式较合理,灰度化效果较好。
2.2 二值化处理
本文对经典的自适应二值化算法Niblack进行了改进,为了减少图像中噪声的干扰,把灰度图像分割成n×n个不重叠的子图像,在计算每个子图像的像素阈值时,加入整幅场景图像的像素均值信息,阈值计算方式为
T=k1×Mean+k2×Variance
(1)
其中,k1,k2分别为对应的权值,介于0~1之间;Mean为整幅图像的像素均值;Variance为子图像的像素标准差。
根据式(1)计算出阈值T后,通过观察发现,场景图像中背景通常标准差较小,而文本区域标准差较大,因此按照式(2),将图像划分成黑色层,白色层以及灰色层图像,来加快后续的处理速度,并且不影响最终的定位结果。
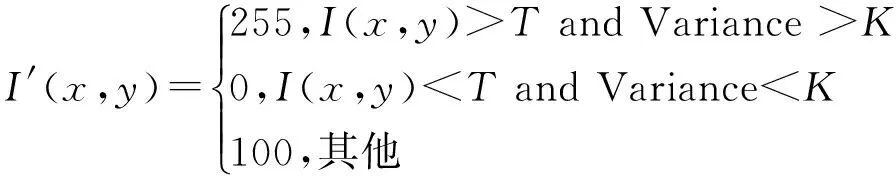
(2)
经过多次实验发现,当K取15而k1,k2分别取0.75和0.8时,图像二值化效果最好,并且可以有效的抑制噪声的影响。
3 生成候选文本区域
3.1 形态学运算
由于图像中文本区域的标准差较大,所以最终的文本区域只可能在白色层和黑色层图像中。接下来分别对得到的白色层和黑色层二值化图像进行水平和垂直方向的膨胀运算使得同一字符的各个结构连接在一起,然后再进行闭运算,平滑字符的边界,填充字符内的小空洞,有利于接下来的连通区域标示与限制分析。
3.2 连通区域限制分析
接下来分别对形态学运算之后的黑色层和白色层图像进行连通区域标示与限制分析,本文利用根据连通体本身计算的形态特征,包括连通体的宽高比,黑像素密度特征,边界限制以及根据待判别的连通体与其他连通体之间的空间排列计算出来的特征来判别文本/非文本连通体,去除明显不是文本的区域,得到候选文本区域。
通过连通区域标示与限制分析,在保留所有文本区域的前提下,可以去除掉大量的非文本区域,便于接下来使用卷积神经网络进行进一步的定位。
4 卷积神经网络细分类
经过上述步骤处理后,在得到的候选文本区域中可能仍然存在一些非文本区块,特别当图像中存在一些图形的特征与文本字符的边缘、形状等特征相似时,非文本区块可能就更多,所以对得到的候选文本区域还需要进行更细致的分类。通过对现有分类方法的研究,本文选用卷积神经网络[13]进行进一步分类。
目前来说,常用的深度学习框架有Caffe, CNTK, Theano等,通过对现有的学习框架进行分析比较,选择了Caffe框架[14]来进行本文所需要的卷积神经网络的搭建。该框架可以通过配置文件对网络的层数,类型以及卷积核的个数等进行方便的设置,对训练过程中的一些必须参数给出了详细的说明,使用时根据实际需要进行相应的初始化即可,简单高效。
本文使用卷积神经网络的过程如下:(1)基于Caffe学习框架,结合本文的二分类问题确定好网络结构;(2)对训练样本集合中的正负样本图像进行标记,正样本标记为1,负样本标记为-1,按照需要的数据格式准备好训练与测试数据,输入网络进行训练;(3)选用适当的权重参数调节方法进行参数调节,最终得到满足要求的神经网络模型。使用该网络模型进行进一步的分类。
5 实验结果与分析
5.1 数据库的建立与评价方法
目前对于自然场景图像中的文本定位问题来说,没有统一的标准图像数据库,所以根据需要建立了一个由大约900幅数码相机拍摄的具有代表性的自然场景图像测试数据库,尽可能多的的包含了自然场景中文本的各种情况,例如字体大小、排列方式等。ICDAR文本定位竞赛采用准确率与召回率[15]作为评价标准,本文采用同样的标准。
5.2 卷积神经网络的构建
本文基于Caffe深度学习框架搭建了一个8层的深度卷积神经网络,具体结构如图2所示。
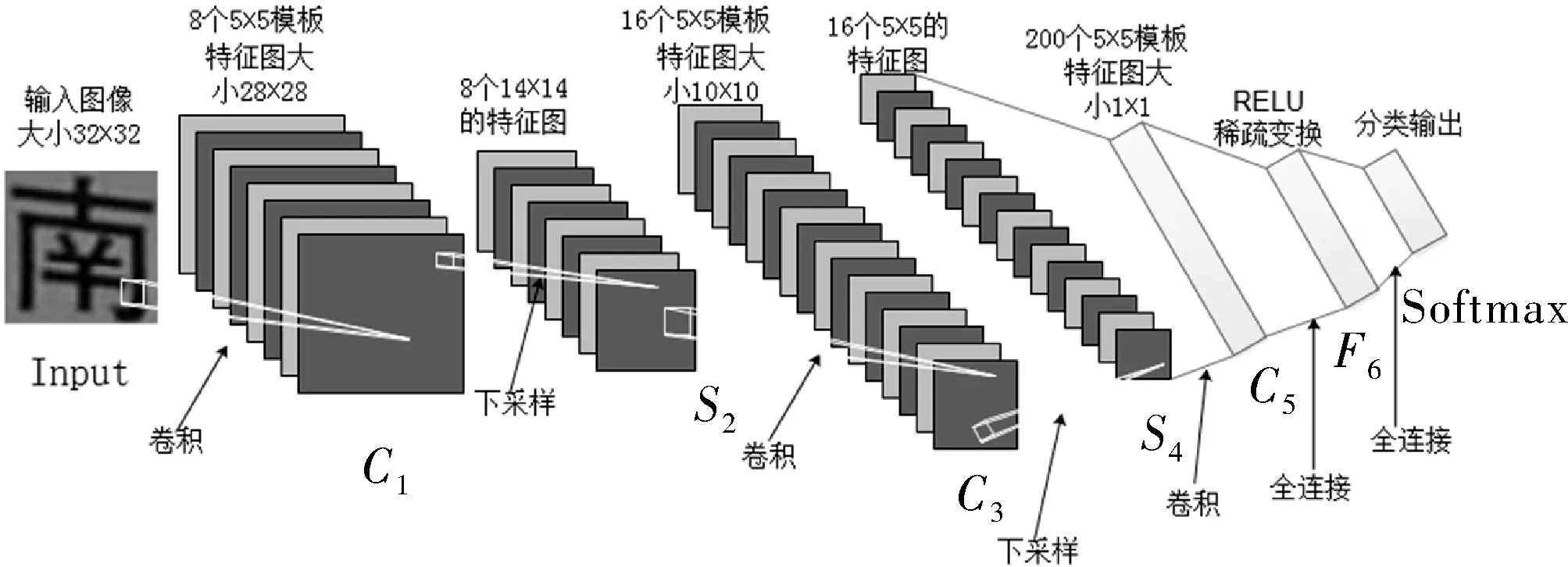
图2 卷积神经网络结构图
其中第一层Input为数据输入层,输入的为灰度化图像;C1为卷积层,卷积核的个数为8,卷积核的大小也就是卷积模板为5×5邻域,通过卷积层C1之后,将会得到原图像的8个特征图;S2为下采样层,选用最大池化算法根据图像局部相关性原理对得到的8个特征图进行下采样操作,卷积核大小设置为3×3邻域,池化步长设置为2来保证采样区域不重叠,将会得到8个特征映射图;C3为卷积层,卷积核个数为16个,卷积核大小为5×5邻域,通过对得到的8个特征映射图分别进行组合、卷积之后,将会得到16个特征图,这样做来破坏网络的对称性,因为不同的特征图对应的输入不同,使得抽取的特征可以互补;S4为下采样层,采用和S2同样的方法进行下采样操作,将会得到16个特征图;C5为卷积层也可以称为全连接层,卷积核个数为200个,卷积核大小为5×5邻域,可以得到200个1×1的特征图,也就是一个200维的特征向量。本文特别加入了激活层F6,对得到的特征向量进行稀疏变换,使数据拥有较好的稀疏性,通过实验对比,选择了RELU函数作为激活函数;最后一层为Softmax层来对输入样本进行分类。
5.3 采集训练样本
本文采用的训练样本集中的负样本是通过对自建图像库中的图像背景通过程序随机切割得到的,并且为了更有针对性,把获取候选文本区域时去除掉的非文本区域也加入其中。正样本是通过对图像中的文本区域进行手工分割得到的,尽可能的包含文本的各种情况。采集的正负样本如图3所示,对正负样本进行灰度化然后来训练网络模型。
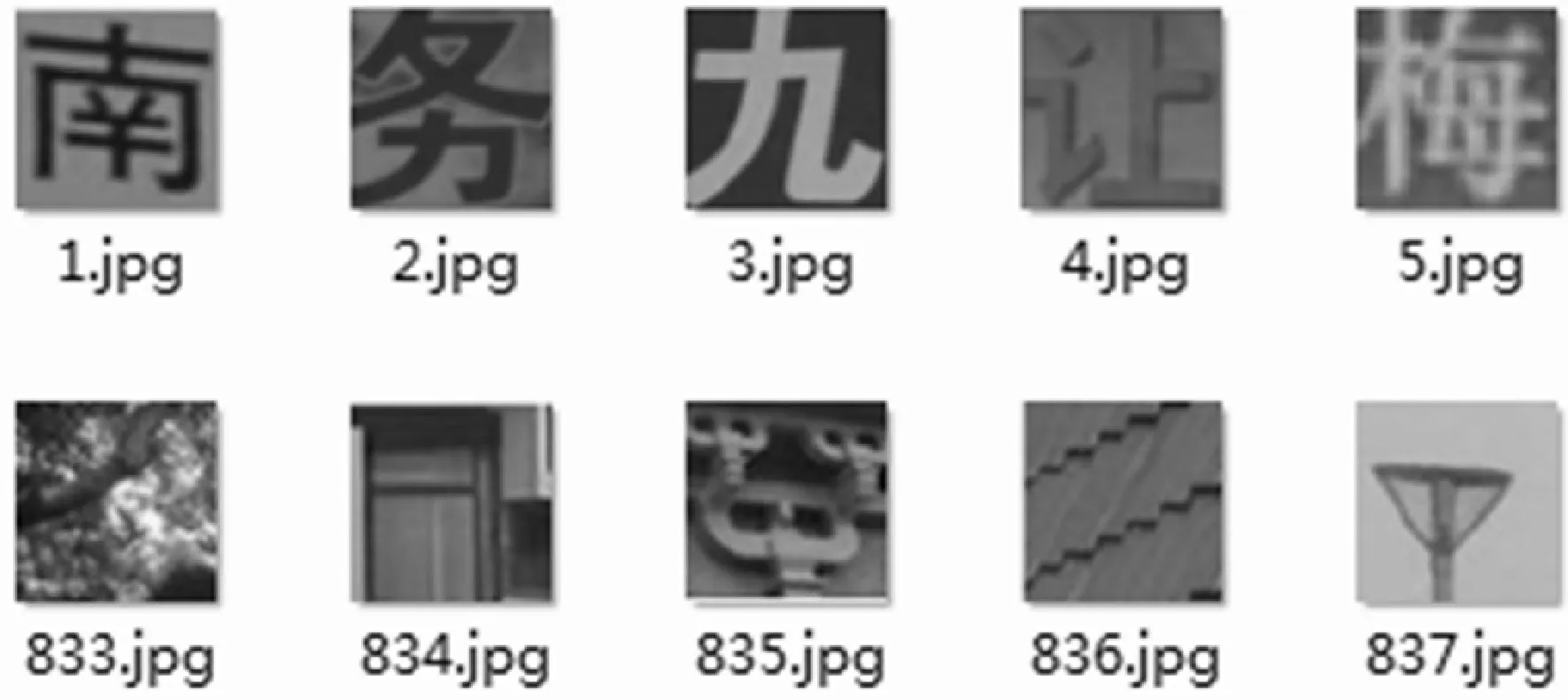
图3 正/负样本示例
本文分别采集了3 000个正样本和5 000个负样本,其中80%作为训练样本,20%用于训练过程中对网络进行测试。通过观察与分析,将样本图像大小调整为32×32像素大小时,保证字符结构清晰的同时减少计算量。按照Caffe框架要求的训练数据格式准备训练数据,其中正样本打标签为1,负样本为-1,训练数据的格式如图4所示。测试数据按照同样的格式进行准备。

图4 训练数据格式
5.4 卷积神经网络的训练
准备好训练数据后,需要对网络模型中重要的权值参数进行初始化,Caffe框架对整个训练过程中需要用到的一些重要参数给出了详细说明,如表1所示。

表1 实验所需主要参数
test_ter: 表示训练数据分多少批次执行。对于准备的训练数据,一次性全部执行效率较低,与配置文件中的batch_size结合起来,test_iter×batch_size=训练数据总量,本文设置batch_size为320,test_iter为20,训练数据总量为6 400。
test_iterval:训练迭代N次之后对网络模型进行一次测试。本文将该参数设置为500,即每迭代500次对网络模型进行一次测试。
base_lr: 网络模型的基础学习率,与选择的参数调节方法相关。本文选择目前使用较广泛的SGD(Stochastic Gradient Descent)随机梯度下降法来对网络模型的权值参数进行调节。通过实验观察发现,base_lr的初始值要尽可能小,整个训练过程才能更快的趋于稳定、准确率高,本文设置初始值为0.005。
momentum: 上一次梯度更新的权重,通过实验发现,当momentum的初始值在0.5~0.99之间时,SGD参数调节方法更加的快速稳定,因此本文设置momentum为0.85。
type:选择的参数调节方法,可选的参数有AdaDelta , Adam等6种,本文选择了SGD参数调节方法。
weight_decay:权重衰减项,用来防止网络模型陷入过拟合,本文设置其初始值为0.0005。
max_iter:网络模型的最大迭代次数,设置太小,得到的准确率较低,设置太大,会产生振荡现象,通过实验,当设置为10 000时,效果较好。
solver_mode:整个学习框架的运行模式,默认为GPU,也可以设置为CPU,本文选择GPU模式来运行。
上述对本文中用到的一些重要参数进行了介绍,并对网络模型的权重参数通过编程用一些小的不同的随机数进行了初始化,初始值小使得网络模型不会过早的进入饱和状态,导致训练失败;不同的初始值可以保证网络正常的对训练样本进行学习。使用准备好的训练数据对网络模型进行训练,最终得到网络模型,进行进一步分类。
5.5 实验结果与分析
在自建图像数据库中选取300幅具有代表性的图像对本文算法进行综合测试,对于待处理的图像,先按照预处理的方法从图像中得到候选文本区域,其中文本连通区域有6 352个,非文本连通区域有16 728个,同时记录这些区域在图像灰度图上的位置,接下来的处理针对图像灰度图上对应的候选文本区域,以提高卷积神经网络的处理效率。使用训练得到的网络模型对候选文本区域进行进一步分类,分类结果如表2所示。

表2 细分类结果
通过表2可以看出,使用卷积神经网络进行进一步的分类时,能正确分类的区域个数为19 848个,其中正确分类的区域中文本区域的个数为5 337个,分类的准确率为86%,召回率为84%,同时可以看出本文算法对于文本的字体、排列方式、中英文语种等有一定的通用性,综合性能较好。
5.6 与相似算法比较
CART[9]中的整体算法与本文算法相似,首先对图像进行预处理得到候选文本区域,然后采用分类器方法对图像区域分类。所以在测试时,将本文算法与其方法在自建的图像测试库上进行对比测试,实验结果如表3所示。
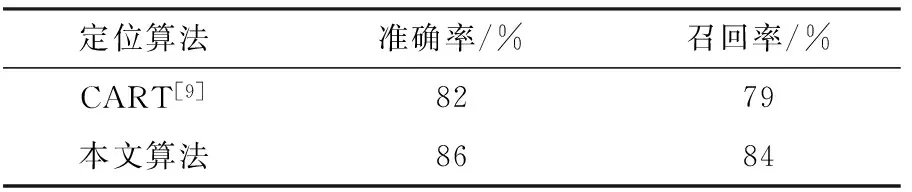
表3 与CART[9]比较结果
从表3中可以看出,与CART[9]相比,本文算法定位效果有明显提高。主要原因是得到候选文本区域后,CART[9]中需要人为的选择特征并进行提取,而利用深度学习卷积神经网络自动提取特征,避免了人为因素的干扰,因此可以有效的降低定位虚警率,准确率更高。
6 结束语
通过对现有文本定位方法进行综合分析后,本文提出了一种结合深度学习卷积神经网络的文本定位方法,通过在自建图像库上进行实验,本文算法的定位准确率较高,有较强的适用性。同时本文还有许多可以改进的地方,例如,改进预处理算法来得到更精确的候选文本区域,完备的训练集合使网络模型的学习更加完善,以及对网络模型进行进一步优化等。
[1] Epshtein B, Ofek E, Wexler Y. Detecting text in natural scenes with stroke width transform[C].MA,USA:IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2013.
[2] Yi C,Tian Y.Text string detection from natural scenes by structure-based partition and grouping[J].IEEE Transactions on Image Processing,2011,20(9):2594-605.
[3] Pan Y F,Hou X,Liu C L.A hybrid approach to detect and localize texts in natural scene images[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society,2011,20(3):800-13.
[4] Lee J J,Lee P H,Lee S W,et al. AdaBoost for text detection in natural Scene[C].Macro:International Conference on Document Analysis & Recognition, 2011.
[5] Mao W,Chung F L,Lam K K M,et al. Hybrid Chinese/English text detection in images and video frames[C].Hangzhou:International Conference on Pattern Recognition,2002.
[6] 丁亚男.基于图像分解的车牌定位算法[J].电子科技,2014,27(1):42-46.
[7] Zhao X,Lin K H,Fu Y,et al. Text from corners: a novel approach to detect text and caption in videos[J].IEEE Transactions on Image Processing,2011,20(3):790-799.
[8] Uchida S,Shigeyoshi Y,Kunishige Y,et al. A key point-based approach toward scenery character detection[C]. Beijing:International Conference on Document Analysis & Recognition,2011.
[9] 徐琼,干宗良,刘峰,等.基于提升树的自然场景中文文本定位算法研究[J].南京邮电大学学报:自然科学版,2013,33(6):76-82.
[10] Ma Wenping,Lin B Q,Wu Xiaoqiang, et al.Scene text secondary location algorithm based on HOG+SVM mode[J].Video Engineering,2015(6):933-945.
[11] Wang C, Zhou Y.A new approach for text location based on SUSAN and SVM[C].Hong Kong:International Conference on Information Science and Cloud Computing Companion,IEEE Computer Society,2013.
[12] 曾泉,谭北海.基于SVM和BP神经网络的车牌识别系统[J].电子科技,2016,29(1): 98-103.
[13] Schmidhuber J,Meier U,Ciresan D. Multi-column deep neural networks for image classification[C].Soul:Computer Vision and Pattern Recognition,IEEE,2012.
[14] Jia Y,Shelhamer E,Donahue J,et al. Caffe:convolutional architecture for fast feature embedding[C].CA,USA:ACM International Conference on Multimedia,ACM,2014.
[15] Shahab A,Shafait F,Dengel A. ICDAR reading text in scene images[J].Robust Reading Competition Challenge,2011,2(2-3):1491-1496.
Text Location in Image Based on Convolution Neural Network
XIONG Haipeng,CHEN Yangyang,CHEN Chunwei
(School of Computer Science,Hangzhou Dianzi University,Hangzhou 310018,China)
Due to the complexity of the natural scene image, it is still difficult to extract the text information from the image, Based on the research and analysis of image text localization algorithm, a localization algorithm based on convolution neural network is proposed. Firstly, the image is preprocessed to obtain the candidate text region,On this basis, combined with convolution neural network to extract the text features for further positioning automatically。Through the experimental verification, the positioning accuracy can reach %86 and has better performance.
text localization; binarization; natural scene image; convolution neural network
2017- 03- 07
浙江省科技计划项目(GK090910001)
熊海朋(1991-),男,硕士研究生。研究方向:人工智能与模式识别。陈洋洋(1990-),男,硕士研究生。研究方向:人工智能与模式识别。陈春玮(1990-),男,硕士研究生。研究方向:人工智能与模式识别。
TN957
A
1007-7820(2018)01-050-04
