基于数学表达式特征的科技文档检索模型
2018-01-05田学东崔晓娟
田学东,崔晓娟
(河北大学 计算机科学与技术学院,河北 保定 071002)
基于数学表达式特征的科技文档检索模型
田学东,崔晓娟
(河北大学 计算机科学与技术学院,河北 保定 071002)
现有全文检索技术多是以文本信息为处理对象,对于以数学表达式为主要成分的科技文档检索还处在探索阶段.为了使用户可以方便地以数学公式作为查询语言对科技文档进行检索,提出了一种基于数学表达式特征的科技文档检索模型.首先通过将公式解析为二叉树得到数学表达式的子式信息,利用数学表达式及子式构造检索特征向量;在索引阶段,利用所提取的文档特征向量构建分层结构的索引表;在匹配阶段,对文档向量采用tf-idf进行加权操作,利用余弦相似度对检索向量和文档向量进行相似度计算,得到一个有序的文档检索结果.实验选取了来自不同领域的期刊、学术网站以及公共数据集的5 017篇科技文档,其中包含了96 362条数学公式,平均检索时间为0.428 s,表明该模型达到了实现较高效率科技文档检索的目标.
科技文档;数学表达式;检索;索引;匹配;二叉树;特征
数学表达式是科技文献的重要组成部分,以数学表达式为线索获取文档信息,对于科技工作者来说,是较为理想的科技信息获取方式之一.目前,全文信息检索技术已较为成熟,而以数学表达式检索为核心的科技文档信息检索还处于研究阶段.国内外针对数学表达式检索的研究已经取得了一定的成果,其中MathDex[1]、LetAciveMath[2,3]、EgoMath[4]、MathSearch[5-7]、MIas[8]、DLMFSearch[9-11]、WikiMirs[17]等是已经出现的具备数学检索功能的方法和原型系统.
DLMFSearch[9-11]是基于DLMF(Digital Library of Mathematical Functions)构建的数学表达式检索系统,以TeX/LaTeX格式的数学内容作为检索对象,采用由Shatnawi和Youssef提出的Parse-tree作为索引结构,将特殊字符和数学符号与字母表中字母相对应,使数学对象线性化、定界,并序列化,即按顺序将各表达式元素转换为标准形式;然后利用传统的全文搜索引擎实现面向数学表达式的检索.Líška等[12]采用扩展传统文本检索方法实现数学信息检索的策略,提出了一种将文本信息和表达式信息进行混合查询的方法.这种方法采用查询分解策略,判断构成一次完整查询的查询项的个数,若查询项较多,则对所有查询项进行归类并建立子查询组,然后对所有子查询组进行处理.对于各查询组的检索结果,则需要进行权重分配,通过有效的权重计算算法将各组结果进行合并处理.孙净等[13]利用Trie树构建索引,实现了对数学表达式的结构检索.卢托等[14]提出一种基于表达式分层索引的方法通过抽象出表达式的关键特征,实现了子结构查询和语义相似性查询.在数学表达式相似度计算方面,Kamali和Tompa[15]提出了一种基于结构相似度的数学检索方法,采用“树编辑距离”计算Presentation MathML格式的数学表达式的相似度,并设计了top-k选择算法和索引算法来减少查询处理时间.Zanibbi和Yuan[16]将传统的面向文档排序的TF-IDF算法应用到数学表达式相似度计算中,将每一个表达式视为一个单独的文档建立索引,这一方法在进行数学表达式相似度计算时避免了由文本和相似公式导致的噪声.Hu等[17]采取改进的TF-IDF算法计算数学表达式相似度,将表达式转化为树并进行正规化,结合该关键词的层次与是否正规化等信息,计算得出表达式间的相似度.Lin等[18]在该方法的基础上,考虑查询表达式被匹配表达式匹配到的关键字数目与查询表达式中关键字总数的比例,对表达式相似度计算方法进行了改进.Schellenberg[19]用五元组表示数学表达式,通过计算表达式所对应的五元组的距离作为相似度.
国内外专家学者对于文档检索以及数学公式检索的理论和方法进行了有益的尝试,但目前以数学表达式为基础的科技信息检索尚处于发展阶段,还没有成熟、实用的数学表达式检索系统和搜索引擎问世.通过对数学表达式检索和文档检索的研究,提出一种基于向量空间模型、以数学公式特征为查询依据的科技文档检索模型,以满足科技工作者对科技文档的检索需求.
1 科技文档检索模型
根据科技文献中数学公式的特点以及向量空间模型理论,构建科技文档的检索模型如图1所示.
1)文档特征抽取
针对科技文档的特征,确定检索特征及相应的提取算法.包括由文档特征构建的文档信息表和文档中包含的数学公式特征组织构建的公式信息表.
2)索引构建
根据所提取的特征构成科技文档检索的特征向量.借助分层索引模型[21]的方法构建数学索引.

图1 科技文档检索模型Fig.1 Scientific document retrieval model
3)文档检索匹配与结果排序
解析输入的LaTeX格式的数学表达式得到公式的检索特征向量,设计匹配算法,得到符合查询需求的所有文档,依据相似度计算结果得到符合用户需求的文档排序.
2 检索特征的提取及数学特征向量的构建
从科技文档中抽取的信息包括2部分:一部分是以文档属性构造的文档信息表,方便用户查询到更多的科技文档信息;另一部分是公式属性构造的公式信息表,用于构建索引检索科技文档,如表1、表2所示.文档信息表和公式信息表的组织结构如图2所示.

表1 文档信息表结构

表2 公式信息表结构

图2 文档信息组织结构Fig.2 Document information organization structure
数学表达式在互联网上的格式有MathML、OpenMath、LaTeX、图像等[7],由于多数格式都可以方便地转换为目前主流的数学文档描述语言LaTeX,故采用LaTeX格式数学表达式作为系统的查询输入形式,利用数学表达式特有的二维结构特征及运算符和运算数属性对其进行解析.
LaTeX描述的数学表达式解析生成二叉树的递归算法如表3所示.
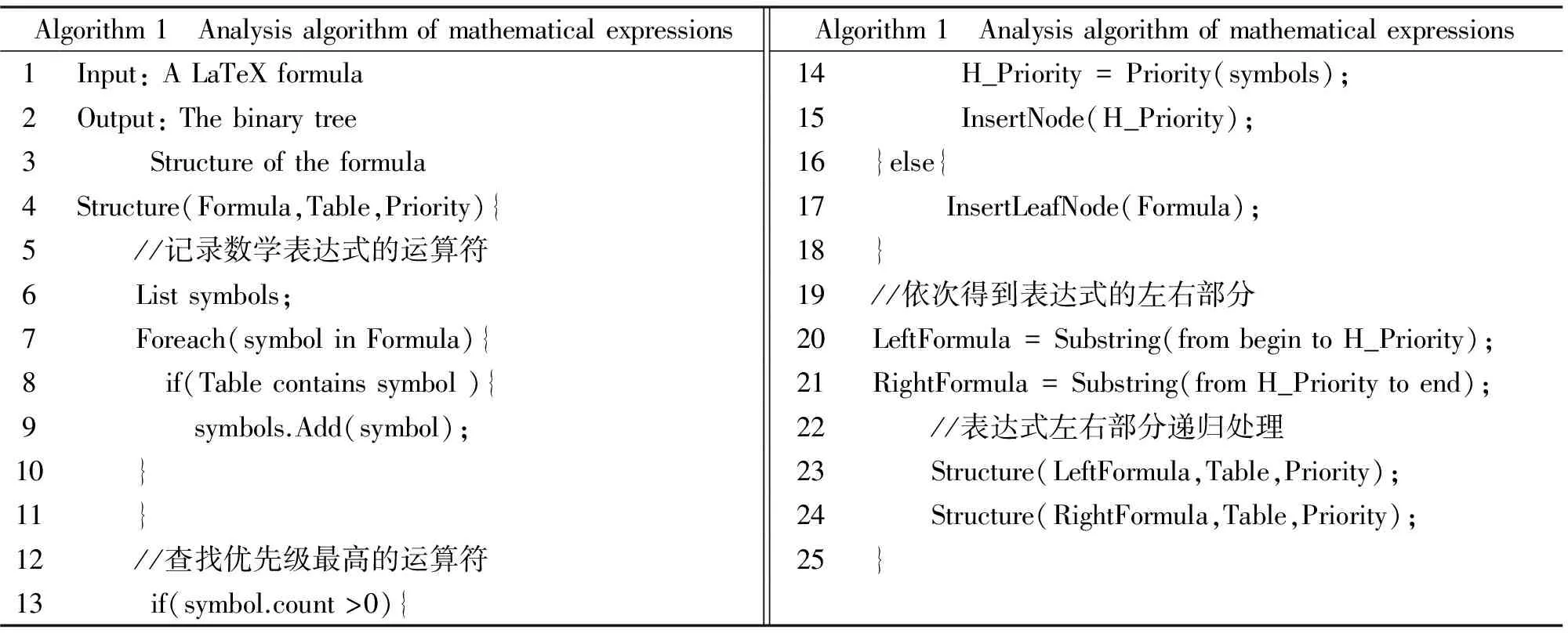
表3 算法 1 数学公式解析算法

图3 数学表达式的解析过程Fig.3 Analytical process of mathematical expressions

图4 表达式(1)的二叉树结构Fig.4 Binary tree structure of expression(1)
通过上述一系列操作得到数学表达式的二叉树表示形式,利用队列先进先出的特点,进行二叉树结点入队和出队的操作,层次化遍历二叉树,得到二叉树的所有节点信息.首先,将二叉树的根结点进行入队操作,然后进行队列的出队操作,得到根节点的左子树结点和右子树结点的所有节点信息,将得到的信息保存到List表中.上述操作递归进行,可以得到数学表达式的所有子式信息.

表4 表达式的子式信息
定义1对查询公式Q的子式qn-1,…,q0进行划分,构造查询公式的检索向量F(fn-1,…,f0),其中,n表示查询公式的子式个数,fi为子式qi对应的检索特征.
文献[20]对数学公式的子式划分做了一定的研究,提出了对数学公式的N-grams划分,研究得到对N值的选择,将N值的下界定义为2-gram,上界定义为15-gram,即N∈[2,15],这样索引表的规模将大大减小.在本文中对提取到公式的所有子式,除去其中的1-gram的子公式,这样将大大降低检索特征向量的维度.
降维后的检索特征向量为
q(FN-gram,FN-1-gram,…,F2-gram)(N=2,3,…,n).
定义2通过检索向量F检索得到的文档向量为dj(DFn,DFn-1,…,DF1)(n=1,2,…,m)(j=0,1,…,i),其中,DFn表示查询公式在科技文档中的特征信息,DFn-1,…,DF1表示查询公式子式在科技文档中的特征信息.文档向量的维度由检索向量的维度决定.检索向量降维后,通过检索得到降维后的文档向量为
dj(DFN-gram,DFN-1-gram,…,DF2-gram),
其中(N=2,3,…,n)(j=1,2,…,i).由此可以通过一个查询公式构造的检索向量q检索出多篇科技文档d1,d2,…,dn.
3 科技文档索引的构建



表5 数学表达式的特征编码

图5 科技文档索引结构示例Fig.5 An example of scientific document indexing structure

f索引结构f1d1(Code(f1)),d1(Code(f1))→d2(Code(f1),d2(Code(f1)))→…→dn(Code(f1),dn(Code(f1)))…fnd5(Code(fn),d5(Code(fn)))→d6(Code(fn),d6(Code(fn)))→…→dm(Code(fn),dm(Code(fn)))
4 科技文档检索的匹配过程及结果排序
4.1 检索特征向量的构建
根据查询公式构造的检索向量中的公式及子式的特征信息,检索出包含其特征的所有文档向量构成文档向量集.匹配过程如图6所示.

图6 基于数学向量的科技文档的匹配过程Fig.6 Matching process of scientific documents based on mathematical vector
图6中,Root表示的是根节点,Leftsubtree表示的是左子树节点,Rightsubtree表示的是右子树节点,Leafnode表示的是叶子节点.Key(X)(X表示R、L1等)表示生成的关键码.Formulan(n=1,2,…,N)表示检索出的公式集,Documentj(j= 1,2,…,M)表示检索出的文档集.

图7 科技文档匹配过程示例Fig.7 Examples of scientific document matching process
以上述方式匹配可能会出现检索文档结果重复的问题,其解决方法如表7所示.

表7 算法2 科技文档去重算法
4.2 科技文档检索结果的排序
计算文档相关度常用的模型主要包括向量空间模型和集合运算模型等,集合运算模型的局限性比较大,所以最常用的还是向量空间模型.对TF-IDF加权赋予新的含义.

(1)
其中,fi代表的是所要查询的特征公式在所在文档中出现的频率,∑f代表的是特征公式所在文档的所有公式出现的频率.

(2)
其中,|D|代表的是文档集中所有文档的个数,{f∈di}表示的是所要查询的数学公式在文档集中出现的文档个数.
TF-IDF=tf-idfi=tfi×idfi.
(3)
由此得到文档向量中每个分量的加权值.
利用文档向量中每个特征公式DFi计算出其TF-IDF,并利用TF-IDF对其特征项加权,可以得到文档向量中每个特征分量加权后的向量表示.最后,利用余弦相似度公式得到结果.

(4)
其中dj(j=0,1,2,…,n-1).计算出检索向量与文档向量之间的相似度.公式(4)中q表示的是查询公式的特征构成的检索向量,dj表示的是科技文档的特征构成的文档向量.通过上述计算,可以得到与查询公式相似度较高的文档集.根据相似度大小进行文档排序.

表8 dm文档向量tf-idf加权操作表

表9 dn文档向量tf-idf加权操作表
计算出每篇文档向量中每个分量的TF-IDF.然后根据余弦相似度,计算文档的相似度,如文档dm=0.829 39比文档dn=0.820 27更相似,从表中分析可以看出,文档dm包含查询公式子式的个数虽然不多,但包含有公式本身的信息,dn文档中虽然查询公式的子式较多,但没包含公式本身信息,dm确实更为接近检索结果,所以把检索到的文档dm排在靠前的位置,而把文档dn排在靠后的位置.
5 实验结果及分析
实验在Microsoft Visual Studio 2013平台上实现,在浏览器/服务器模式下,利用.NET平台和C#语言以及MVC框架进行操作.实验环境:Intel Corei5-4 570,IIS服务,CPU 3.20GHz,RAM 8.00 GB,系统环境为64位Windows 7操作系统.
本文用于实验的数据来自公共数据集(如NTCIR数据集等)以及不同领域期刊(如知网等)与学术网站(如科学空间网站以及英文预出版网站arxiv等),共5 017篇文档,96 362条测试数据,对其进行以数学公式为检索词的科技文档检索.
本文与文献[18]的索引文件情况如表10、表11所示.

表10 本方法实验数据

表11 文献[18]方法实验数据
可见本方法索引文件占用空间较小.
随机选取121条公式进行检索效率实验,结果如表12所示.文献[18]方法的检索效率如表13所示.

表12 本方法检索效率

表13 文献[18]方法检索效率
可以看出检索文档的时间随着文档及公式数量增加而增加,但增幅相对平稳.
采用基于数学公式特征向量的科技文档检索模型,在相同数据集的情况下,选取20个数学公式(表14),与查询公式直接检索科技文档的方法进行对比,结果如图8所示.

表14 查询表达式

图8 向量检索与公式检索结果对比Fig.8 Compare results of vector retrieval and formula retrieval
由图8可以看出,本方法扩展了以数学公式为线索对科技文档进行检索的范围.
6 结论
本文利用向量空间模型构建了以数学公式为线索的科技文档索引与匹配方法,实现了依据公式信息的科技文档检索.通过实验验证了利用运算符优先级将LaTeX描述的数学表达式构造成二叉树的解析方法和基于数学表达式特征的科技文档检索方法的有效性.但是,还存在一些不足之处,实验中的科技文档数量较少;同时,检索向量的特征还不够充分.下一步的工作是进一步完善检索特征,丰富实验样本,使检索系统能够更好地满足用户的检索需求;并设计与本文检索对象相适应的相似度计算函数,使科技文档的检索结果更准确、合理.
[1] MINER R,MUNAVALLI R.An approach to mathematical search through query formulation and data normalization[M] //Towards Mechanized Mathematical Assistants,Springer Berlin Heidelberg,2007: 342-355.DOI:10.1007/978-3-540-73086-6_27.
[2] LIBBRECHT P,MELIS E.Methods to access and retrieve mathematical content in activemath[M] // Mathematical Software-ICMS 2006,Springer Berlin Heidelberg,2006: 331-342.DOI: 10.1007/11832225_33.
[3] LIBBRECHT P,MELIS E.Semantic search in leactivemath[C] //Proceedings of the First WebALT Conference and Exhibition.Eindhoven,Holland,Jan.2006: 97-109.
[5] 景珂.网络数学搜索中的数学查询语言与索引的研究[D].兰州:兰州大学,2009.
JING K.Research on math query language and index in web-based math search[D].Lanzhou: Lanzhou University of Technology,2011.
[6] GUO W,SU W,LI L,et al.MQL: A mathematical formula query language for mathematical search [C]// Proceedings of the IEEE Conference on Computational Science and Engineering,Dalian,China: IEEE Press,2011: 245-250.DOI :10.1109/CSE.2011.52.
[7] 刘志伟.数学搜索引擎研究[D].兰州: 兰州大学,2011.
LIU Z W.The Research on mathematics search[D].Lanzhou: Lanzhou University of Technology,2011.
[9] YOUSSEF A.Methods of relevance ranking and hit-content generation in math search [M] // Towards Mechanized Mathematical Assistants,Springer Berlin Heidelberg,2007: 393-406.DOI:10.1007/978-3-540-73086-6_31.
[10] SHATNAWI M,YOUSSEF A.Equivalence detection using parse-tree normalization for math search [C]// Proceedings of the 2nd International Conference on Digital Information Management,Lyon,France:IEEE Press,2007,2: 643-648.DOI: 10.1109/ICDIM.2007.4444297.
[11] MILLER B,YOUSSEF A.Technical aspects of the digital library of mathematical functions[J].Annals of Mathematics and Artificial Intelligence,2003,38(1): 121-136.DOI: 10.1023/A:1022967814992.
[13] 孙净.基于Trie树的数学表达式运算结构检索[D].保定: 河北大学,2015.
SUN J.Operation structural retrieval of mathematical expressions based on trie tree[D].Baoding: Hebei University,2015.
[14] 卢托.科技文档中数学公式的描述与检索[D].武汉: 华中科技大学,2007.
LU T.The description and retrieval of math formulas in scientific documents[D].Wuhan: Huazhong University of Science and Technology,2007.
[15] KAMALI S,TOMPA F.Structural similarity search for mathematics retrieval [M].Intelligent Computer Mathematics,Springer Berlin Heidelberg,2013: 246-262.DOI:10.1007/978-3-642-39320-4_16.
[16] ZANIBBI R,YUAN B.Keyword and image-based retrieval for mathematical expressions[C]// Proceedings of the SPIE 7874 Conference on Document Recognition and Retrieval XVIII,California,USA: SPIE,2011,7874(6): 993-1004.DOI: 10.1117/12.873312.
[17] HU X,GAO L C,LIN X Y,et al.WikiMirs: A mathematical information retrieval system for wikipedia[C].Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital libraries.ACM,2013: 11-20.DOI:10.1145/2467696.2467699.
[18] LIN X Y,GAO L C,HU X,et al.A mathematics retrieval system for formulae in layout presentations [C]// Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval,Gold Coast,Australia: ACM,2014: 697-706.DOI:10.1145/2600428.2609611.
[19] SCHELLENBERG T,YUAN B,ZANIBBI R.Layout-based substitution tree indexing and retrieval for mathematical expressions [C]// Proceedings of the SPIE 7874 Conference on Document Recognition and Retrieval XIX,California,USA: SPIE,2012,8297(2): 263-271.DOI:10.1117/12.912502.
[20] 徐月霞.面向语义的数学公式N-grams索引结构研究[D].兰州: 兰州大学,2015.
XU Y X.N-gram index structure for semantic based mathematical formulas[D].Lanzhou: Lanzhou University of Technology,2015.
[21] 周南.LaTeX数学表达式解析与索引方法[J].计算机应用,2016,36(3):833-836,842.
ZHOU N.Analyzing and indexing method on LaTeX formulae[J].Journal of Computer Applications, 2016,36(3):833-836,842.DOI:10.11772/j.issn.1001-9081.2016.03.833.DOI:10.11772/j.issn.1001-9081.2016.03.833.
Aretrievalmodelofscientificdocumentsbasedonmathematicalexpressionfeatures
TIANXuedong,CUIXiaojuan
(College of Computer Science and Technology,Hebei University,Baoding 071002,China)
The existing full-text retrieval techniques are mostly targeting the text information.While the retrieval of the scientific documents with mathematical expressions as the main components is still in the exploration stage.In order to make the users can easily use the mathematical formula as the query language to retrieve the scientific and technical documents,a new scientific document retrieval model based on mathematical expression features was proposed.Firstly,the formulas were resolved into the subformulas forming the binary trees,which are used to generate the retrieval feature vectors.In the index phase,the index table with the hierarchical structure was constructed using the extracted document feature vectors.In the retrieval phase,the document vectors were weighted by tf-idf.The similarity between the retrieval vector and the document vector was calculated by using the cosine similarity,and an ordered document retrieval result was obtained.The experiment data was selected from different journals,academic website and public data set of 5 017 science and technology documents which contain 96 362 mathematical formulas.The average retrieval time was 0.428 s,which indicates that the proposed model achieved the goal of realizing mathematical expression retrieval with high efficiency.
scientific documents; mathematical expressions; retrieval; indexing; matching; binary tree; features
10.3969/j.issn.1000-1565.2017.06.013
2017-09-18
国家自然科学基金资助项目(61375075);河北省教育厅河北省高等学校科学技术研究重点项目(ZD2017208)
田学东(1963—),男,天津人,河北大学教授,博士,主要从事模式识别、信息检索的研究.
E-mail:xuedong_tian@126.com
TP391
A
1000-1565(2017)06-0652-10
孟素兰)
