一种改进的聚类目标融合算法
2018-01-05刘佳媛邵立琴
刘佳媛,邢 朦,邵立琴
(中国船舶重工集团公司第七二四研究所,南京 211153)
一种改进的聚类目标融合算法
刘佳媛,邢 朦,邵立琴
(中国船舶重工集团公司第七二四研究所,南京 211153)
多源目标数据融合技术是雷达辐射源关联融合中的一项关键技术。以K均值算法为基础,对簇中心初始化方法进行优化,提出了基于空间密度与欧氏距离结合的聚类初始化算法,对聚类方法进行改进,并将其应用于多源目标融合领域。仿真结果验证了该算法可以有效地提高多源融合性能。
雷达;目标融合;K-均值;簇中心
0 引 言
雷达多目标融合系统需要接收各个雷达传感器送来的多源目标信息并进行实时融合处理,获得综合目标特征信息。这些多源目标信息的数据量大,并且具有多种形式。在处理时首先需要对其进行转换,以提取共同特征参数,并对特征参数相似的目标完成关联、融合处理。
在多雷达传感器侦测多种辐射源目标时,由于不同雷达具有不同的数据采集时间、通信时延以及测量精度,所以在一段时间内采集到的辐射源目标信息,包括载频、脉宽、重复周期、方位等多种参数[1],会在一个高维空间中以簇的形式呈现出来。理想情况下,各个簇会集中于各个观测目标的周围,以实际目标所在位置为簇的中心,并以一定的密度分布于目标四周。但是,在实际情况下,由于杂波和其他干扰的影响,不同雷达的测量精度,以及多个目标源的空间聚集程度不同,会导致簇呈现不同的分布情况。区分同一平台观测的不同目标,同时对不同平台观测的同一目标进行融合关联,是目标融合的工作重点。当目标辐射源数量较多且位置较近,会使得这些目标在融合处理过程中被判为同一目标,加之不同雷达的测量精度不同,进一步导致观测数据的弥散程度提升,严重影响融合效果。
聚类(Clustering)[2]算法是将一个多维观测集划分到自然组成或者模式。聚类主要分为分割聚类和层次聚类两种。分割聚类算法通过优化评价函数把数据集分割为K个部分,需要K作为输入参数。典型的分割聚类算法有K-means(K均值)算法[3]、 K-medoids算法和CLARANS算法,其中应用范围最广的是K-means算法。该算法广泛应用于数据挖掘、模式识别和机器学习等多个领域[4-7]。本文首先将K-means算法应用到多源多目标融合领域,充分考虑多传感器系统的特殊性,为提升多传感器融合性能提出了一种改进的基于空间密度聚类的多目标融合算法,最后对K均值融合算法与改进的算法进行仿真,验证了所提出的多目标融合算法的有效性。
1 传统K-means聚类方法
聚类是非监督学习的一种形式,是将一个观测集(即数据点)划分到自然组成或者模式聚类。聚类的途径是测量分配给每个聚类的观测对之间的相似性以最小化一个指定的代价函数。
K-Means算法是最常用的聚类算法。作为期望最大化(Expectation-Maximization)算法的一个特例,其主要思想是在给定簇数k和k个初始簇中心点μj,j=1,…,k的情况下,把每个观测样本按照相似度(空间距离)逐一归类到与其最相似的簇中,根据聚类结果重新计算每个簇的中心,通过迭代不断优化样本分类并更新簇中心直至聚类误差收敛。收敛准则为簇内误差平方和最小,即
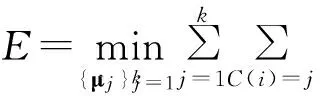
(1)
对于给定的C,分类准则为

(2)
观测数据可定义为X=[x1,…,xn],其中n为观测数据的样本总数,xi为第i个观测样本,且为1×m维观测列向量,m表征了观测目标的参数维度,目标参数可包含载频、脉宽、重复周期、方位、多普勒等多种参数。
基本的K-Means算法如下:
(1) 确定迭代终止条件ε,最大迭代次数L,初始化迭代次数l=0,初始化簇数k以及簇中心μj,j=1,…,k;
(2)l=l+1,对每一个观测数据xi,分别计算其与k个簇中心μj,j=1,…,k的距离,并将该观测数据归类到与其距离最近的簇中。即
(3)
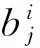
(3) 根据步骤2的分类结果重新计算簇中心,并计算簇内误差El。
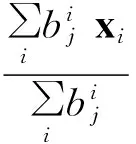
(4)
(4) 判断是否满足迭代终止条件|El-El-1|<ε或最大迭代次数l=L,若满足退出循环,否则执行步骤2。
2 基于空间密度的聚类初始化算法
K均值聚类算法本身思想比较简单,但是合理的确定簇数k和k个簇中心点对于聚类效果的好坏有很大的影响。错误的簇数和簇中心的选择会导致聚类算法无法获得最优解。对于簇数的选择,传统的方法是尽可能遍历合理的簇数取值,比如依次在k=2,…,K的情况下进行聚类运算,之后选择具有簇内误差最小的簇数作为最终簇数。Calinski-Harabasz准则就是用于进行簇数评估的方法,实际应用中可较好地完成最优簇数选择,另一方面簇中心初始化也会严重影响聚类算法的性能。除了传统的随机选择簇中心方法,常用的初始类簇中心算法还包括最大最小距离法、最大距离积法、层次聚类法等,但仍然依赖于样本和簇中心的欧氏距离,当具有相似的欧式距离时无法获得理想的效果。即便有文章[8]将空间密度引入到簇中心初始化中,但是仍然需要为算法提供基于经验的参数输入。这些参数的选择同样会影响簇中心的确定。本文旨在对簇中心初始化方法进行优化,提出了新的基于空间密度的聚类初始化算法,对聚类方法进行改进,并将其应用于多目标融合领域。
对于给定观测数据可定义为X=[x1,…,xn],其中n为观测数据的样本总数,xi为第i个观测样本,且为1×m维观测列向量,m表征了观测目标的参数维度。则观测数据集中每个点相对于其他点的密度为
(5)
其中δ表示归一化半径,其定义为
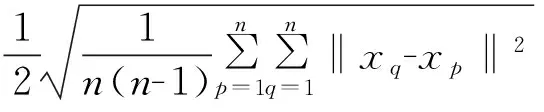
(6)
则基于密度的初始化簇中心算法可概括为:
(1) 计算观测数据集中每个点相对于其他点的密度fi,并找到密度最高的点作为第m个簇的中心(初始值为1),同时初始化簇数k。
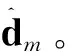
(7)

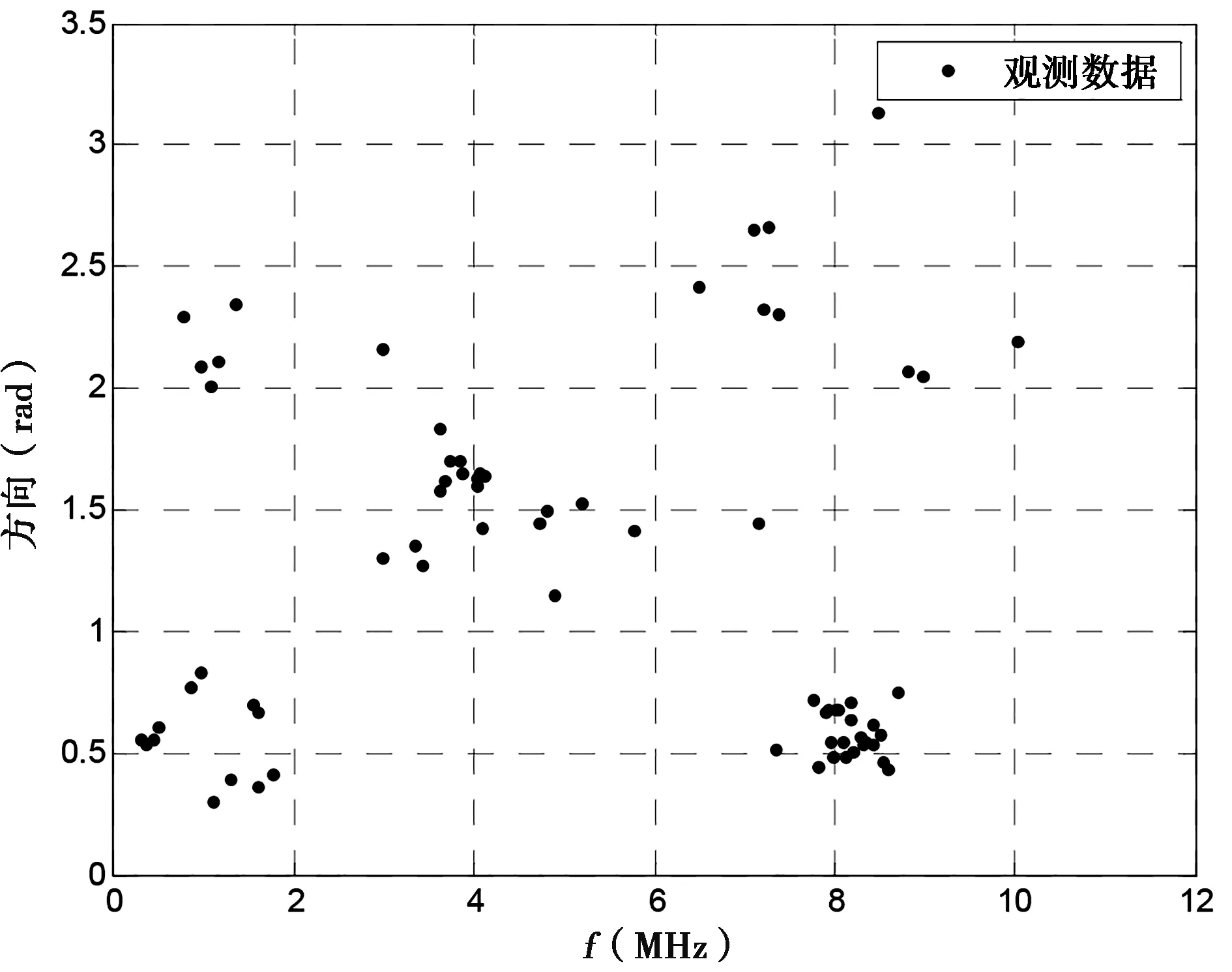
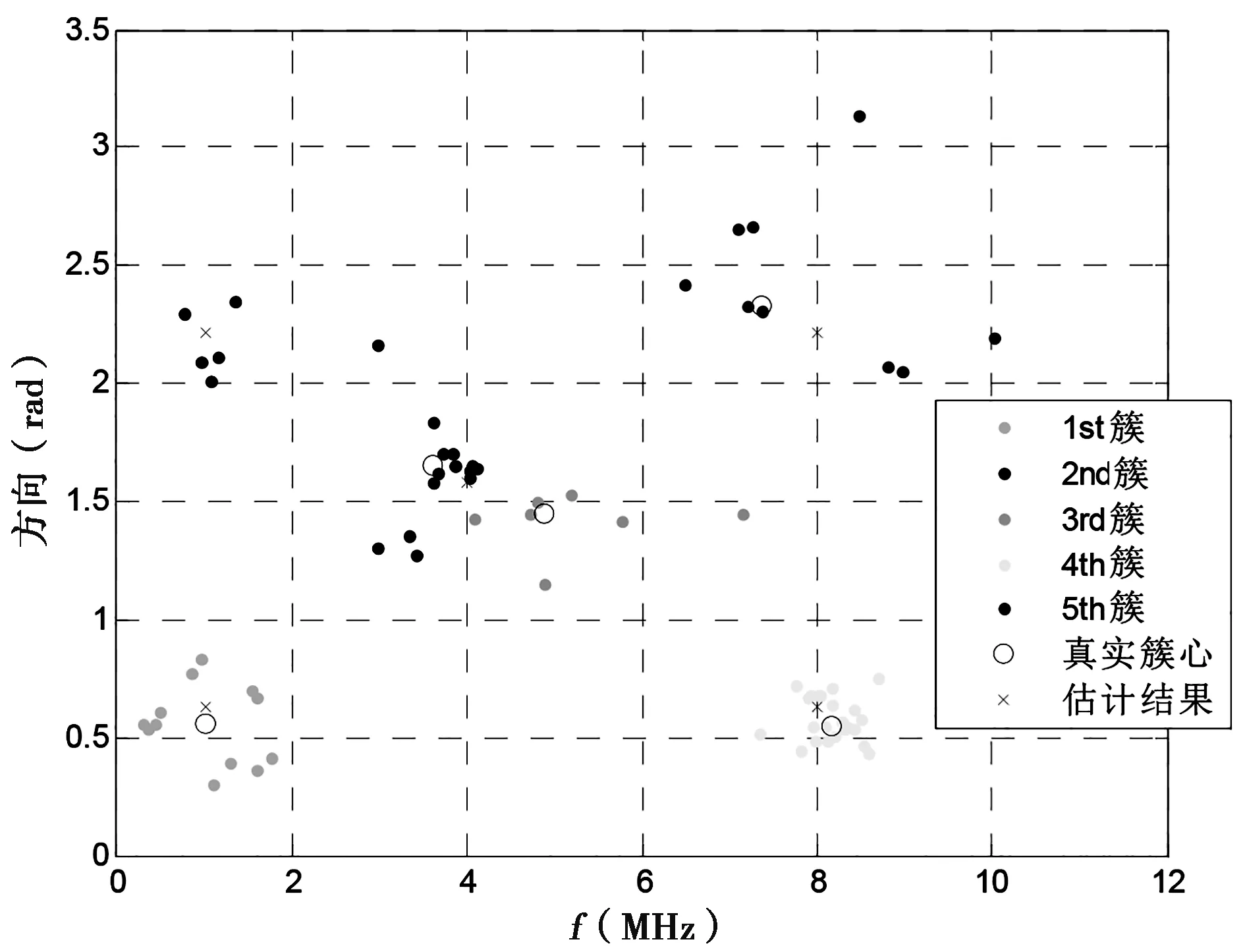
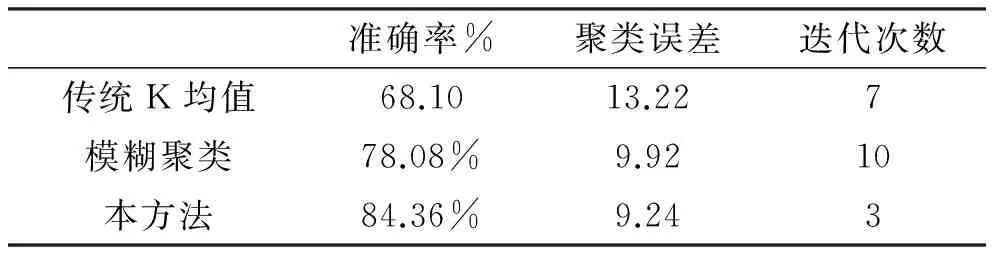
(4) 若m (5) 完成k个簇的初始化过程。 上一节阐述了传统的K均值聚类方法以及基于空间密度的聚类初始化算法。为了加快簇中心初始化迭代速度,将上述方法用于多目标融合算法,具体算法如下: 步骤1确定迭代终止条件ε,最大迭代次数L,最大簇数K。初始化迭代次数l=0,初始化簇数k,令k=2。 步骤2利用前一章所述的初始化方式,对给定的簇数k和给定的观测数据集X,确定簇中心μj,j=1,…,k。 步骤3l=l+1,对每一个观测数据xi,分别计算其与k个簇中心μj,j=1,…,k的距离,并将该观测数据归类到与其距离最近的簇中。即 (8) 步骤4根据步骤2的分类结果重新计算簇中心,并计算簇内误差El。 (9) 步骤5判断是否满足迭代终止条件|El-El-1|<ε或最大迭代次数l=L,若满足退出循环,否则执行步骤3。 步骤6若k 为验证上述的多源融合算法进行仿真验证,通过对随机初始化的K均值算法以及基于空间密度的聚类初始化的目标融合算法完成性能比对。 图1给出了观测数据集在二维空间中的分布情况,二维空间由频率-方向域组成。目标融合的目的就是将所有的观测数据进行关联匹配,以从观测数据中识别出多个目标,以及每个目标的特征参数。 图1 观测数据集在频域—方向域的分布情况 图2给出了利用随机初始化的K均值方法得到的分类结果。由于在初始化阶段每个簇的簇中心都是随机生成,导致聚类的结果会以一定的概率收敛到局部最优的,而非全局最优,从而影响结果的可靠性,导致目标识别出现错误。 图2 利用随机初始化的K均值算法分类结果 图3给出了改进的方法得到的分类结果。由于采用了空间密度与欧氏距离结合的方式来对簇中心进行初始化,避免了随机初始化的不可靠性,也避免了过多的输入参数,最终得到的簇中心更接近真实的簇中心。同时,根据空间密度与欧式距离迭代簇中心的方法也会进一步降低迭代次数,加快收敛过程。 图3 利用改进的基于空间密度聚类的 通过蒙特卡洛仿真方法对上述聚类方法进行对比仿真分析可以得到准确率以及聚类误差的比较结果。由表1各算法在仿真数据集上的准确率和误差的比较可见,由于传统聚类算法和模糊聚类算法是随机选择初始聚类中心且对聚类结果影响较大,所以迭代多次后聚类结果具有不稳定性从而导致平均准确率较低,聚类误差较高。本算法在仿真数据集中的准确性明显优于前两种聚类算法。由于在初始化过程中将样本密度考虑到聚类初始化过程中,并同时结合AIC准则可以有效提高聚类的准确性,并降低迭代次数。 表1 各算法在仿真数据集的性能比较 本文针对原始的K均值算法的初始化簇中心采用的随机选取问题,提出了基于密度和欧氏距离相结合的簇中心优化的K均值算法,以此提升了K均值聚类算法的不稳定性,在加快迭代收敛速度的同时获得了聚类准确率的大幅提升。 [1] 赵国庆.雷达对抗原理[M].西安: 西安电子科技大学出版社, 1999. [2] Trevor Hastie, Robert Tibshirani, Jerome Friedm-an.The Elements of Statistical Learning: Data Mining, Inference, and Prediction [M]. New York: Springer, 2001. [3] Simon O Haykin. Neural networks and learning ma-chines [M]. Pearson,2008. [4] Zhongzhi Li, Xuegang Wang. High Resolution Ra-dar Data Fusion Based on Clustering Algorithm [C]//Database Technology and Applications (DBTA), 2010 2nd International Workshop, 2010.11:27-28. [5] Hao Wang, Tangxing Liu, Qing Bu, Bo Yang. An algorithm based on hierarchical clustering for multi-target tracking of multi-sensor data fusion[C] //2016 35th Chinese Control Conference (CCC),2016.7. [6] 李向东,张月磊,刘存超. 基于聚类和统计理论的雷达组网融合方法[J].舰船电子工程,2016(1): 37-38. [7] 舒红平, 徐振明, 邹书蓉, 何嘉. 网格聚类在多雷达数据融合算法中的应用[J]. 电子科技大学学报,2007(6): 1253-1256. [8] McQueen. Some methods of classification and analysis of multivariate observations [C]. Proceedings of Fifth Berkeley Symposium on Mathematical Statistics and Probability,1967:281:197. An improved algorithm of clustering target fusion LIU Jia-yuan, XING Meng, SHAO Li-qin (No.724 Research Institute of CSIC, Nanjing 211153) Multi-target data fusion is one of the key techniques in the association and fusion of radar radiation sources. A new initialization method for K-means clustering by utilizing spatial density and Euclidean distance is proposed, and the initialization method of clustering center is optimized and applied in the field of multi-target data fusion. The simulation results show that this algorithm can effectively improve the multi-target data fusion performance. radar; target fusion; K-means; clustering center TN957.52 A 1009-0401(2017)04-0019-04 2017-10-20; 2017-11-03 刘佳媛(1988-),女,工程师,硕士,研究方向:数据处理;邢朦(1988-),女,工程师,硕士,研究方向:终端显控;邵立琴(1977-),女,工程师,研究方向:数据处理。3 基于空间密度聚类的多目标融合算法
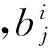
4 仿真分析

5 结束语
