xk-split:基于k-medoids的分裂式聚类算法
2018-01-03陈逸斐虞慧群
陈逸斐, 虞慧群
(1.华东理工大学计算机科学与工程系,上海 200237; 2.上海市计算机软件重点测评实验室,上海 201112)
xk-split:基于k-medoids的分裂式聚类算法
陈逸斐1,2, 虞慧群1
(1.华东理工大学计算机科学与工程系,上海 200237; 2.上海市计算机软件重点测评实验室,上海 201112)
近年来互联网数据规模呈爆炸式增长,如何对大数据进行分析已成为热门话题。然而,采集的数据很难直接用于分析,需要进行一定程度的预处理,以提高大数据质量。通过使用分裂式的迭代过程,可以逐步将数据集分裂为子集,避免了传统聚类算法聚类开始时需要确定集群数的限制,并降低了算法的时间复杂度。此外,通过基于阈值的噪声数据过滤,可以在迭代过程中剔除噪音数据,提升了聚类算法对脏数据的忍耐力。
数据挖掘; 聚类; k-means; k-medoids; 分裂
数据的聚类算法是机器学习与数据挖掘中的一大命题,广泛应用于机器学习、数据挖掘、图像分析、模式识别等领域中。而聚类算法又可分为硬聚类和软聚类算法,其中硬聚类算法将目标数据明确地划分为不同集群,代表算法为k-means算法;而软聚类算法又称模糊聚类算法,数据点可能属于一个或以上的集群,且数据点与集群通过成员水平互相联系,代表算法为模糊C-均值(FCM)算法。本文针对聚类算法中的硬聚类算法展开讨论。
聚类分析的主要工作是将较大规模的数据通过静态分析的手段划分为更小的子集,每个子集内部的对象有共同的特征。聚类分析的手段主要分为结构型与分散型算法。结构型算法需要使用已经存在的聚类器进行数据分析,而应用较为广泛的是分散型聚类算法,其特征是一次性确定所有分类,而且需要指定聚类结果的个数,不明确聚类个数的情况下需要给出估计值。
分散型聚类算法k-means具有简单、快速的特点,可以在短时间内完成初步的聚类分析。自从该算法被提出后被不断地改进、完善,出现了例如k-medoids等高效且可靠的聚类算法,一定程度上改进了k-means算法对脏数据敏感的缺点。近年来,除了传统的模式识别[1-3]、用户行为分析等领域[4]外,k-medoids还被使用在防范SSDF攻击[5]等场景中。k-means及其衍生算法的改进也越来越重要。
本文分析研究了现有的分散型聚类算法,使用分裂式的迭代方法替代一开始就确定所有聚类的手段,获得了时间复杂度和噪声忍耐度上的提升。另外,基于分裂式的聚类思想,提出了不需要给定聚类数量,而由程序自动完成聚类的新算法。
1 相关工作
1.1 k-means算法
最简单也是应用最为广泛的分散型数据聚类算法是由MacQueen提出的无监督聚类算法k-means[6]。k-means的主要实现方法是在数据集中随机选取k个中心点,随后循环迭代2个步骤:
(1) 集群。对集合内所有点分别计算其与每个中心点的欧氏距离,选择最近的一个中心点并加入其集群。
(2) 重新选择中心点。计算各个集群的质心,将其作为新的中心点。
对整个数据集不断地重复执行以上步骤,直至集群分布不再改变。
k-means算法以较低的时间成本解决了数据无监督集群问题,但是存在很多问题:
(1) 需要指定k个起始点,即最终集群数量,若要使用k-means算法则知晓数据集共有几个集群是先决条件。
(2) 在选择中心点的步骤中使用质心作为新的中心,对脏数据较为敏感。
(3) 其本质是一种贪心算法,仅仅能求得局部最优解。加之起始点是随机选取的,往往为了获得一个较为优秀的解,需要重复执行多次k-means算法。
1.2 k-medoids算法
为了解决上述第2个问题,k-medoids算法被提出。该算法对k-means的改进仅仅在于选择中心点时并不选用质心,而是选用离开集群中所有其他点最近的点。这样虽然提高了一些对脏数据的宽容度,却大大地增加了算法的时间复杂度,并且是一个NP-难问题。同时,也并没有解决k-means存在的其他两个问题。
现实生活中已对k-medoids有了非常广泛的应用。由于其随机性,需要迭代多次以获得最优解,这个过程具有并行的特性,所以非常适合用户Hadoop等平台的大数据分析[7]。同时因为其较为优秀的脏数据耐受能力,也经常被用于用户行为分析等工作上[8]。
1.3 其他改进的k-means算法
其他针对k-means的改进算法也经常被提出[9]。Xu等[10]提出了F2-k-means (Farest2-k-means)算法,该算法先找出数据集中距离最远的两个点,分别形成集群,在数据集中寻找接近集群的点并加入其中,直至到达阈值,再寻找新的点。这两个算法有一个共同的特点,就是依赖阈值来判断是否结束迭代,同时,最接近点对的比较也会大幅增加算法的时间复杂度,集群算法的准确度也依赖于阈值的选择,如图1所示,选择阈值为10时,会导致源数据被过度分类。

图1 阈值为10的F2-k-means算法Fig.1 F2-k-means algorithm with threshold value of 10
Zhou等[11]提出的自适应k-means算法可以使k-means拥有一定的学习能力,用较少的代价增加算法对脏数据的耐受能力,不过也较依赖于数据的规模,仅仅在有充足的数据进行训练的前提下才会有较好的输出。Cui等[12]提出了一种k-means的优化方案,在寻找中心点的过程中同时考虑集群内的凝聚度和集群间的分离度,以解决k-means算法仅仅能求得局部最优解的问题,但这个方法同样大大增加了算法的时间复杂度。
本文在k-medoids算法和F2-k-means的基础上提出了分裂式自适应聚xk-split算法,具有以下特征:
(1) 可以选择指定或不指定k个初始点,在集群的过程中判断出数据最佳的集群数量。
(2) 比k-medoids更稳定,受随机选点的影响更小。
(3) 对脏数据不敏感,并且可以在集群过程中识别并排除噪声数据。
(4) 时间复杂度低,在得到更低平均方差集群的同时,比多次执行k-medoids算法需要的时间更少。
2 分裂式自适应聚类算法xk-split
2.1 xk-split算法的迭代单元
xk-split算法不同于k-means和k-medoids算法,迭代开始时并不会确定k个初始集群,而是先确定2个集群,然后再将其逐步分裂成k个小集群。在分裂过程中,xk-split算法会根据阈值自动判断分裂是否应该结束,从而达到了自动确定聚类数量的目的。
F2-k-means算法是对k-means算法的一种改进,其缺点是需要确定阈值。本文采用F2-K-means和k-medoids算法相结合的F2-k-medoid算法作为迭代的基本单元。由于一次迭代仅将源数据集分为两个子集群,则F2-k-medoid算法并不需要接受阈值,而是将源数据的点全部划分完毕,然后根据k-medoids的思想,在集群内选取距离所有点最近的点作为中心点,再进行下一步迭代直至聚类结果不再改变。
2.2 算法设计
xk-split算法结构如图2所示。算法步骤如下:
步骤1 为了尽可能减少受随机选取初始点的影响,对数据集执行一次k=2的k-medoids算法,将数据集分为两个较大的待分裂集群。当k=2时,k-medoids算法受随机选点的影响最小,往往执行多次能获得较为接近的结果。除了待分裂集群集合S之外,还存在一个分裂完毕集群集合Sdone,在这一阶段该集合仍是空集合。
步骤2 开始迭代。根据式(1)将方差最大的集群选出并从点集中剥离,待执行分裂操作。
Csplit=S[max(D(C1),D(C2),…,D(Ck)))]
(1)
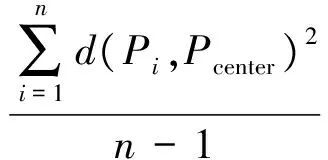
(2)
其中:S表示当前集群的集合;Cx表示现有的某个集群;Csplit为待分裂的集群;n和k分别为集群和数据集中数据点的数量;D(x)为方差,由式(2)求得;Pi为集群中的某个数据点;Pcenter为集群当前的中心点;d(X1,X2)为求取两点间欧氏距离。
由于k-medoids是按照某点离集群内其他点欧氏距离大小来选取中心点,对集群中任意点Pi来说,d(Pi,Pcenter)2为已知值,为了便于聚类以及方差计算,本文中所有k-medoids的点之间距离计算都取距离的平方值,即不对距离做开平方根处理,所以计算各集群方差并不会带来额外的计算量。
步骤3 对步骤(2)中剥离出来的集群进行k=2的F2-k-medoids算法。完成操作后获得两个新集群。将这两个新集群的规模与规模阈值θ和方差阈值γ进行判断。θ和γ由式(3)、式(4)确定
θ= (N/K)α
(3)
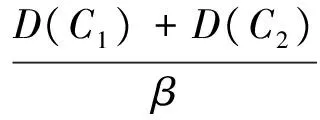
(4)
式(3)中:N为整个数据集的规模;K为最终期望获得的集群数量;α为控制参数,范围为[0,1]。
式(4)中,D(C1)和D(C2)分别为由步骤2获得的初始集群方差,β为控制参数。需要注意的是,当β=2时,γ为初始集群方差的平均值,该值应为γ的上界。此时按照下文确定的划分规则,该数据集只能被分为约3个集群。为了使β的范围控制在(0,1),进行如下变换:
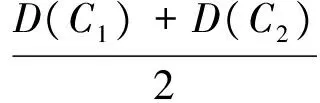
(5)
式(5)即为最终阈值γ与参数β的对应关系。根据判断的结果,这两个新的数据集可能会被插入回S中,插入到Sdone或者被作为噪声集群从数据集中删除。
步骤4 重复上述步骤2、步骤3,直到集合S为空集为止。集合Sdone即为求解的聚类结果。
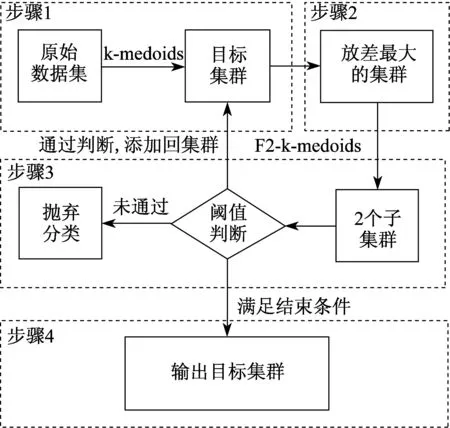
图2 xk-split算法结构Fig.2 Structure of xk-split algorithm
2.3 xk-split算法的参数确定
2.3.1 接受参数k的xk-split算法 xk-split算法需要2个参数来辅助确定最终聚类结果中集群数量k。如果集群的k已知,则可以省去方差阈值γ的判断,只需要使用规模阈值θ控制噪声点的过滤即可,从而形成了接受参数k的xk-split算法。由于不需要自动确定集群数k,算法的复杂度大大简化,并减少了一个阈值的学习成本,算法的阈值θ由式(3)确定。
随后根据阈值进行判断,对于规模小于阈值的集群,直接将其判断为噪声点集并抛弃;规模大于阈值的集群会被重新添加到数据集中。如果抛弃了噪声点集,意味着这些数据永远地从数据集中被删除,所以需要用新的N来重新计算阈值θ。同时,将过多的数据点判断为噪声点会导致算法无法进行,需要重新调整参数α的值。
随着α的上升,数据集中被排除的噪声点增加,而平均方差下降。α越大所获得的聚类效果越好,但是当α>0.4时,由于不断地进行降噪和抛弃而使算法无法结束。α的最优值可能由于数据分布和噪声点数量不同而不尽相同,具体使用时可以先从数据集中抽取一定的训练集来确定α的值。α取值过小对聚类的完成并没有影响,只会降低聚类的最终效果使其不理想,而过高的α值会使聚类操作无法继续进行。所以本文算法在聚类结束之前检测到现存的数据点数量不足原来的一半时会强制将α值设为0,以完成聚类。α从0.4上升到0.5的过程中,算法删除的噪声点数量急剧上升而平均方差急剧下降,即存在突跃变化。本文将α设为突跃变化发生前的最大值0.4。
2.3.2 阈值θ,γ和参数α,β的确定
(1)θ与α的确定。xk-split算法中,系统并不知道最终会有多少个聚类产生,θ的初始值由第1次分裂后2个集群的规模决定。
θ=αN/(Ndone+Nsplit)
(6)
式中:Ndone和Nsplit分别是分裂完毕集合Sdone和待分类集合S的集群数。Ndone+Nsplit为当前集群总数。一般来说该值比最终聚类结果的集群数k要小,所以α应比接受参数k的算法α小,才能保持对脏数据相同的宽容度。本文将前者的α取为后者的一半,即0.2,而后者的值可通过机器学习算得。
(2)γ与β的确定。xk-split能够在不给定集群数k的情况下完成聚类算法,主要是由于算法中包含了方差阈值γ。其基础值由第1次分类完成后所得的2个集群平均方差决定,这个值一定程度上反映了整个数据集中数据的分布状态,然后通过一个(0,1)的参数β来最终确定γ。β越接近1,则γ越接近上限,对阈值的判断就越为宽松,最终所获得的集群数就越少。
β的取值与最终集群个数呈负相关而与集群的平均方差呈正相关。一个较小的β会将原数据集分为较多的集群,每个集群的规模和方差也相对较小,由于参数α采用了保护机制,在数据点过少的情况下不再过滤噪声点,所以一个较小的β也不会使算法没有足够的数据点而终止,所以β的取值在(0,1)内都是安全的,β取值越小,算法聚类的精度越高。本文中β的取值为0.3,刚好能保证α不进入保护措施的值。
使用阈值γ进行判断后,被判断的集群可能会有以下3种处理方法:
(1) 继续。集群被判断为未达到要求,被添加回数据集,需要继续进行分裂操作。
(2) 完成。集群已经达到要求,将该子集群标记为分裂完成,并终止对该子集群的分裂。
(3) 删除。集群被判断为噪声集,从数据集中删除。
表1列出了xk-split算法阈值行为的判断结果。表中L(Ci)为集群Ci的规模,L(Ci)小于阈值θ时,无论方差阈值判断结果如何,该集群都被判定为噪音数据被删除,而满足规模判断的情况下,一旦集群方差D(Ci)小于阈值γ,则判定为满足条件,结束该集群的分裂,否则将继续进行分裂。
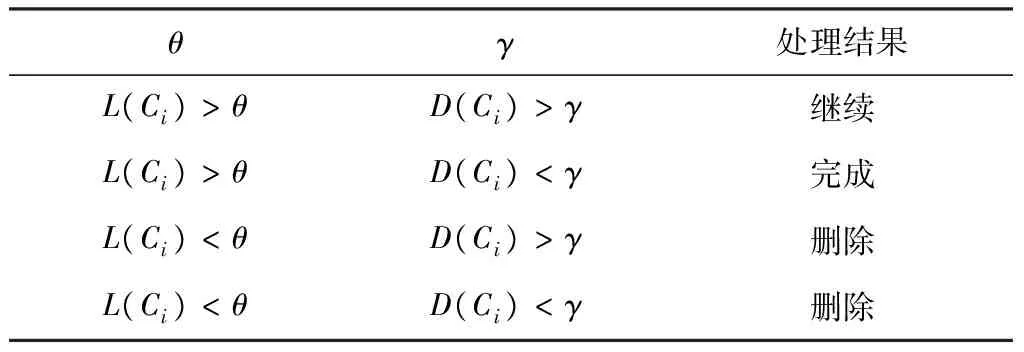
表1 xk-split算法阈值行为判断
α和β都确定后就可以运行xk-split算法了。针对同一数据集连续进行100次实验,结果表明xk-split算法的稳定度较高,能将数据集稳定地分为均值的±1个集群,其中87次结果为7个集群,8次结果为6个集群,剩余5次实验结果为8个集群。其主要原因就是使用了F2-k-medoids和两个阈值来控制噪声点的排除,使聚类的结果最大程度稳定,随机性仅仅来源于第1次分裂操作。
2.4 算法实现与分析
xk-split算法伪代码如下:
function xk-split (dataSet){
resultClusters ← new Array
θ← (dataSet.length/k) *α
currentClusters ← k-mediods(dataSet):k=2
γ← currentClusters.averageVariance *β
while (currentClusters.length > 0){
splitCluster ← cluster with max
variance in currentClusters
currentClusters.remove(splitCluster)
splitedClusters ←
f2-k-mediods(splitCluster):k=2
for(cluster insplitedClusters){
if(cluster.length <θ){
continue
else if(cluster.variance <γ)
resultClusters.push(cluster)
else
currentClusters.push(cluster)
refreshθ
returnresultClusters
xk-split算法的特征是并不在一开始就确定k个中心,而是通过不断地将方差最大的集群分裂以获得目标集群。由于每次分裂都使用k=2的F2-k-medoids算法,所以相较于直接多次执行k-medoids来说稳定性高。
若输入数据规模为N,目标集群数为k,迭代次数为T,则k-medoids和k-means的时间复杂度为O(NkT),空间复杂度为O(n+k)。对于xk-split而言,若每次分裂平均需要迭代t次,参与分裂的数据点数为k,则时间复杂度为O(ktK)。分裂操作是在单个簇中进行的,而平均每个簇含有N/K个数据点,所以k可以用N/K来表示,时间复杂度变为O(Nt)。对单一簇进行分裂迭代仅将其分为两个子集群,其迭代次数t远小于将整个数据集划分为k个子集群的迭代次数T,即t< 在一组基于位置信息的数据集上进行实验分析,该数据集共含有700个数据点,每个数据点包含2个属性,分别是经度和纬度。数据采集程序使用Cordova和Ionic框架,基于Angular.js 编写,运行于iPhone6(iOS 9.3.5)上。位置信息采集使用了HTML5提供的geolocation接口,并调用了移动设备的GPS。所采集到的数据上传至托管于Amazon EC2中的MongoDB中等待分析。算法程序使用Node.js编写,并运行于2.4 GHz Core i5-4258U 的OS X 10.11.6上。 将传统k-medoids算法与xk-split算法进行对比,比较其完成聚类算法的时间(ms)和聚类效果(集群平均方差)。对于k-medoids,将目标集群数k设为7(xk-split聚类的结果),并将重复次数设为7,取方差最小的一次进行对比,对于xk-split,将参数α设为0.2,将参数β设为0.3。 3.2.1 平均方差分布 图3示出了xk-split算法与k-medoids算法聚类结果的平均方差比较结果。可以看出,xk-split的平均方差比k-medoids下降了50%左右,这是由于噪声数据剔除机制、规模阈值θ的存在。实验数据为真实采集的位置数据,除了每天长时间停留的位置会形成数据集群之外,移动中所产生的数据基本为脏数据,这会对k-medoids的聚类效果产生很大的影响,如果采用k-means算法,其聚类效果可能会更差。这也说明xk-split算法相较于传统的k-medoids与k-means算法,对噪声数据的宽容度更高,不易受其影响。 图3 两种算法的平均方差对比Fig.3 Comparison of average variance of two algorithms 另外,k-medoids算法由于受到随机选择起始点的影响,方差分布范围较大,单次执行的话稳定性很差,需要多次运算取其方差最小的结果。从实验结果可知,k-medoids算法方差小于0.006的概率约为30%。要使得n次迭代后结果Sk-medoids中包含集群集合Sx,其平均方差D(Sx)落在(0,0.006)区内的概率大于等于90%,即满足式(7)。 P(D(Sx)∈(0,0.006])≥90%,Sx∈Sk-medoids (7) 需要使n满足(1-0.3)n≤1-0.9求得 n≥6.456,所以取n=7,在接下来的实验中,均对k-medoids算法迭代7次并取方差最小的结果为聚类结果。 3.2.2 算法时间效率 (1) 固定样本点数。图4示出了固定700个数据点时,两种算法的耗时比较结果。由图可知,xk-split算法的耗时比k-medoids少约40%,而k-medoids算法由于起始点是随机选取的,聚类结果较不稳定,耗时分布也较其他两个算法稍大。在该实验过程中,k-medoids算法实际的迭代次数固定为7次,而xk-split算法实际的迭代次数为8~11次,但时间复杂度却较低。这主要是因为每次迭代的数据集仅是原数据集的一小部分,且中心点为2个,随着迭代的进行,数据规模也会越来越小。另一方面,k-medoids算法在每次迭代的过程中都对整个数据集进行k个中心点的聚类,所以时间复杂度会大大上升。 图4 两种算法样本数量不变时效率对比Fig. Comparison of efficiency of two algorithms (2) 变化样本点数量。图5示出了数据集规模从100到700变化时,各个算法的时间复杂度变化曲线。由图5可知,在数据规模较小的情况下,xk-split与k-medoids算法的时间复杂度接近,但是随着数据规模的增大,两者运算的耗时逐渐拉开了差距。这也体现出了运用分裂策略的xk-split算法在应对大规模数据时的优越性。 图5 两种算法样本数量变化时效率对比Fig.5 Comparison of efficiency of two algorithms for sample number change 本文在k-medoids和F2-k-means算法的基础上提出了xk-split聚类算法。该算法以k=2的k-medoids算法作为基础的迭代单位,并运用分裂策略,有效地解决了数据聚类的问题。 (1) xk-split算法采用参数α和β指导的学习策略,在不指定k个起始点的情况下也能自动对数据集进行聚类。 (2) 本文的两个算法都包含噪音数据过滤阶段,能将游离于集群外的点过滤掉,对脏数据的耐受力有明显提升。 (3) 由于基础的运算单元是k=2的F2-k-medoids算法和分裂操作,而不是对全体数据集进行随机取点,本文算法拥有更高的稳定性,受随机数的影响较小。 此外,由于采取了分裂的策略,xk-split算法的时间复杂度较k-medoids迭代有明显的下降,更适合于真实数据的分析与聚类。不过,本文算法仍存在依赖于阈值控制的不足,为确定算法所需阈值参数需要对数据进行一定的学习过程。在进一步的研究中,会将重点放在xk-split算法参数的选择策略优化上,降低选择和学习成本,并提出高效且稳定的聚类算法。 [1] KHATAMI A,MIRGHASEMI S,KHOSRAVI A,etal.A new color space based on k-medoids clustering for fire detection[C]//2015 IEEE International Conference on Systems,Man,and Cybernetics (SMC).USA:IEEE,2015:2755-2760. [2] YABUUCHI Y,HUNG H,WATADA J.Summarizing approach for efficient search by k-medoids method[C]// 2015 10th Asian Control Conference (ASCC).USA:IEEE,2015:1-6. [3] ZHANG T,XIA Y,ZHU Q,etal.Mining related information of traffic flows on lanes by k-medoids[C]//2014 11th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD).USA:IEEE,2014:390-396. [4] PURWITASARI D,FATICHAH C,ARIESHANTI I,etal.K-medoids algorithm on Indonesian Twitter feeds for clustering trending issue as important terms in news summarization[C]//2015 International Conference on Information & Communication Technology and Systems (ICTS).USA:IEEE,2015:95-98. [5] NATH S,MARCHANG N,TAGGU A.Mitigating SSDF attack using k-medoids clustering in cognitive radio networks[C]//2015 IEEE 11th International Conference on Wireless and Mobile Computing,Networking and Communications (WiMob).USA:IEEE,2015:275-282. [6] HARTIGAN J A,WONG M A.Algorithm AS 136:A k-means clustering algorithm[J].Journal of the Royal Statistical Society,Series C (Applied Statistics),1979,28(1):100-108. [7] SHEN J J,LEE C F,HOU K L.Improved productivity of mosaic image by k-medoids and feature selection mechanism on hadoop-based framework[C]// 2016 International Conference on Networking and Network Applications.Hokkaido,Japan:IEEE,2016:288-293. [8] HU Q,WANG G,PHILIP S Y.Public information sharing behaviors analysis over different social media[C]//2015 IEEE Conference on Collaboration and Internet Computing (CIC).USA:IEEE,2015:62-69. [9] SHI G,GAO B,ZHANG L.The optimized k-means algorithms for improving randomly-initialed midpoints[C]// 2013 International Conference on Measurement,Information and Control (ICMIC).USA:IEEE,2013:1212-1216. [10] XU Y,CHEN C.An improved K-means clustering algorithm[J].Computer Applications and Software,2005,25(3):275-277. [11] ZHOU H.Adaptive K-means clustering algorithm SA-K-means[J].Science and Technology Innovation Herald,2009,N034:4-8. [12] CUI X,WANG F.An Improved method for k-means clustering[C]//2015 International Conference on Computational Intelligence and Communication Networks (CICN).USA:IEEE,2015:756-759. xk-split:ASplitClusteringAlgorithmBasesonk-medoids CHENYi-fei1,2,YUHui-qun1 (1.DepartmentofComputerScienceandEngineering,EastChinaUniversityofScienceandTechnology,Shanghai200237,China; 2.ShanghaiKeyLaboratoryofComputerSoftwareEvaluationandTesting,Shanghai201112,China) In recent years,the scale of internet data has explosive growth,which makes big data analysis become a hot topic.However,it is difficult to directly utilize the collected data,so a certain degree of pretreatment had to be made in order to improve the quality of big data.In this work,the data set will be gradually divided into smaller subsets by using the split iterative process,which can effectively avoid the limitation of traditional clustering algorithm and reduce the time complexity.In addition,by threshold-based noise data filtering,the dirty data can be eliminated during the iterative process so as to enhance the tolerance of the clustering algorithm to the dirty data. data mining; clustering; k-means; k-medoids;split 1006-3080(2017)06-0849-06 10.14135/j.cnki.1006-3080.2017.06.015 2016-11-23 陈逸斐(1991-),男,硕士生,主要研究方向为云计算。 虞慧群,E-mail:yhq@ecust.edu.cn TP391 A3 实验与分析
3.1 实验设计
3.2 实验结果与分析
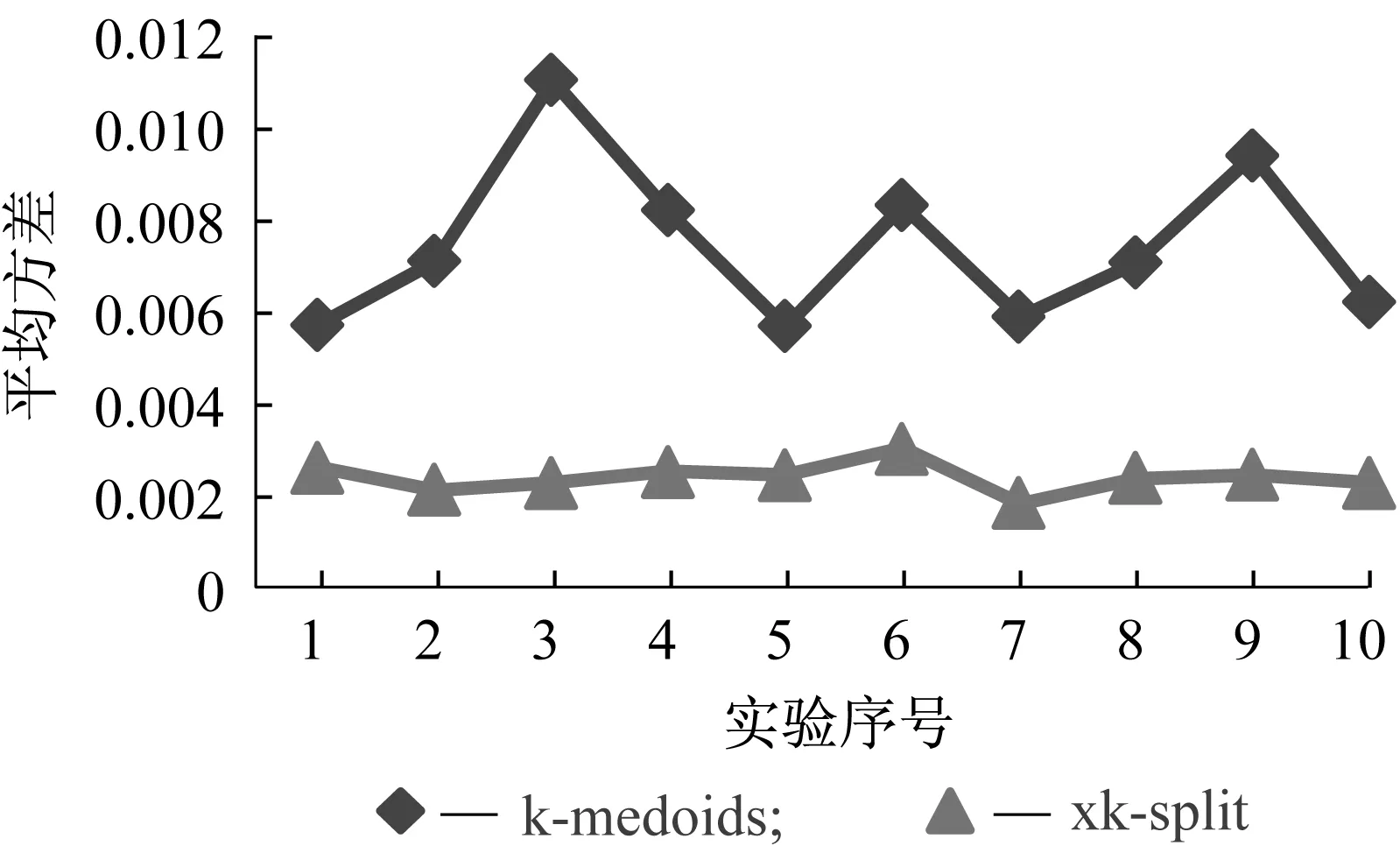
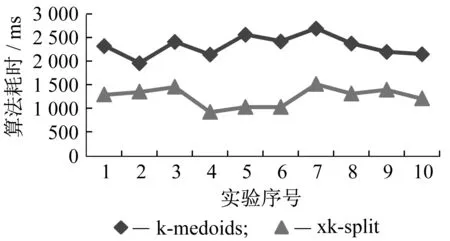

4 结束语
