基于口型运动速度的视频序列对齐方法
2018-01-03王小芳王文青
王小芳 王文青 魏 玮
(河北工业大学计算机科学与软件学院 天津 300401)
基于口型运动速度的视频序列对齐方法
王小芳 王文青 魏 玮
(河北工业大学计算机科学与软件学院 天津 300401)
基于视频人脸替换系统中降低视频抖动和满足语音跟口型匹配的要求,提出一种基于视频图像中口型运动速度特征的视频口型对齐方法。视频中将ASM和光流法相结合,获取稳定的口型运动速度特征;利用平行线约束条件对动态时间规整(DTW)算法的路径搜索范围进行约束以快速求得最优的匹配路径;得到对齐后的视频并给出相似性评价。实验结果表明,该方法可以使得两段视频中说话的口型保持一致。口型对齐不仅满足人物正脸不动的情况,而且能满足人物有任意小角度(<45°)的头部运动的情况。最后对模仿视频给出比较客观的相似性评价,评价结果显示该方法切实可行。
口型运动速度特征 DTW 视频口型对齐 相似性评价
0 引 言
目前视频中的人脸替换存在的一个最大问题就是替换上的人脸出现抖动的现象,许多人脸替换的前提假设源图像和目标图像姿态的相似性[1],其中视频中替换人脸的口型与源视频中人脸口型的相似匹配对替换结果是很重要的[2]。这是因为视频中人脸变化最大、最不稳定的区域就是嘴部,由于人物说话的影响会使得人脸的长度发生变化,从而对替换人脸中比例因子这个参数产生比较大的影响,如果视频序列口型没有对齐,最后会导致融合的结果中人物的脸大小变化比较大,从而出现闪动的现象。
由于每个人的口型张合程度不一样,视频中人物镜头的远近不同以及视频中人物头部本身存在运动变化,单纯利用嘴部特征的相对位置不能反映说话口型真实的变化趋势。本文选取了嘴部说话的运动速度特征,能够消除掉头部整体运动产生的影响,从而体现出口型真实的运动变化趋势。
本文进行时间序列调整时利用的是动态时间规整DTW算法来实现的。DTW算法最早是在20世纪60年代由Itakura提出,在1993年DTW算法最早应用在语音识别中,该算法在处理语音信号相似性方面应用比较广[3-5]。现在该算法已推广到多种应用领域,如单个手语识别[6]、动态手势识别[7-9]以及信息安全领域的签名认证系统[10]等。而该算法用在视频中口型对齐这方面却很少见。本文利用DTW算法根据口型的运动速度特征进行时间规整,对视频重新调整,达到两段视频序列中口型对齐效果理想。
本文的主要贡献就是提出了正向口型运动速度特征和能够适应歪头等复杂情况下的斜向口型运动速度特征,并对传统的DTW进行改进,对路径搜索时加入了平行线约束条件,提高了算法的运行速度。最后本文提出了一种视频对齐的相似性评价标准,能够比较准确地反映视频中口型对齐的优劣程度。
1 视频图像中口型特征提取
在本节中我们主要介绍一下视频中对图像序列提取反映语音信息的口型运动速度特征。人脸特征点跟踪是计算机视觉中一个基本且极具挑战性的研究课题。光流法是目前运动图像分析的重要方法,因为光流可以从单个像素的角度进行特征点跟踪而得到广泛的应用[11]。首先利用Haar_like算法对视频首帧进行人脸检测,得到目标人脸;用主动外观模型(ASM)对要对齐的目标人脸进行特征点提取;对要提取的特征点在以后的视频帧中使用光流法跟踪。最后根据设定的阈值用ASM进行特征点矫正,计算得到反映人物语音信息的口型特征。
1.1 人脸特征点检测
对视频图像进行人脸检测,然后选择要进行口型对齐的目标人脸,再用ASM对人脸进行特征点检测,获取人脸上的特征点。如图1所示为检测到的人脸及面部的特征点。

图1 人脸及面部的特征点检测
对于以后视频帧中的特征点我们利用光流法进行跟踪,每次跟踪都会与预先设定的阈值进行比较,如果超出阈值则利用ASM进行校正。假设当前跟踪的特征点位置为pi,前一帧的特征点位置为pi-1,考虑到嘴唇的点在纵向距离变化比较大,而在横向的变化距离小,经过实验获得经验阈值:横向阈值r1=1和纵向阈值r2=3。当|pi.x-pi-1.x|>r1or|pi.y-pi-1.y|>r2时重新进行ASM人脸特征点检测,更新当前的特征点位置。
1.2 口型运动速度特征
经过ASM特征点检测,我们得到了人脸的77个特征点。因为提取的是反映讲话的口型特征,考虑到嘴唇讲话时张合变化最大的是嘴唇中间的点,所以本文选取的是上下嘴唇外轮廓的中心点,即第62和第74个特征点pi1和pi2,如图1(b)中嘴唇上面的两个特征点。在以后的视频人脸跟踪中分别跟踪第62和第74这两个点,嘴唇上面的点记作第一个特征点,嘴唇下面的记作第二个特征点。对于正脸和歪头的情况,我们分别提出了正向口型运动速度特征和兼容两种情况的斜向口型运动速度特征。
1.2.1 正向口型运动速度特征
对于视频中人物正脸的情况,人物讲话过程的嘴唇变化最主要的就是嘴唇的张合,所以本文计算嘴唇的上下相对距离来作为嘴唇张合的判断依据。然后利用前后帧嘴唇张合的相对距离计算时间序列的一阶差分获得嘴唇的速度信息,这样可以规避掉由于人物本身运动或头部运动产生的速度干扰。那么视频序列A的第i帧的口型运动速度为ai,如公式:
ai=(yi-1,2-yi-1,1)-(yi,2-yi,1)
(1)
式中,yi,1表示第i帧的第一个特征点的纵坐标。如此就得到了反映口型速度的特征向量a=(a1,a2,…,am)。
1.2.2 斜向口型运动速度特征
由于式(1)只用了两点的纵坐标的变化,该方法可以很好地适应人物正脸说话的情况,但是不适合对于人物说话有随意的小角度(一般不超过45°)的头部运动的情况。当头有歪头的情况时,导致嘴的实际的运动方向并不是沿着垂直方向而是始终沿着人脸的垂直方向,自然地,口型运动的实际方向就有了一个偏转角度θ,就是沿着垂直方向偏转θ角度的方向,因此本文提出了斜向口型运动速度,定义视频序列A的第i帧的斜向口型运动速度为ai,如公式:

(2)
式中:xi,1表示第i帧的第一个特征点的横坐标,yi-1,2表示第i-1帧的第二个特征点的纵坐标,其他同理。
2 视频对齐
DTW算法最早是由Itakura提出来的,主要目的是用来衡量两个长度不同的时间序列的相似度。其在语音处理领域应用范围很广。本文在传统的DTW算法的基础上对其进行了改进,提出了一种平行线约束条件对局部搜索路径进行约束,利用该方法来解决图像信息处理中的口型对齐问题,能够使得模仿视频中人物口型与参考视频模板对齐,对以后视频处理奠定了基础。
2.1 改进DTW算法
首先,设有两段视频序列,其中一个为参考模板A,另外一个为测试模板B,前提条件是视频序列B是参照参考模板模仿得到的,即两段讲话中的语素是相同的,不同的就是说话的语速、嘴型的张合力度等因素。两段视频序列的长度分别为m和n。经过这两种人脸特征点检测的介绍,就可以分别获得两段视频序列的口型速度特征向量a和b,即:
a=(a1,a2,…,am);b=(b1,b2,…,bn)
为了对齐两段视频序列,就需要构造一个m×n的累加距离矩阵D。首先定义一下视频序列中任意两个特征点之间的距离d(ai,bj)=(ai-bj)2;对于累加距离矩阵中任意元素d(i,j),它的值只可能来自于三个方向,如图2所示。只来自于(i,j-1)、(i-1,j-1)和(i-1,j)。因此定义累加距离矩阵的计算公式为:
(3)
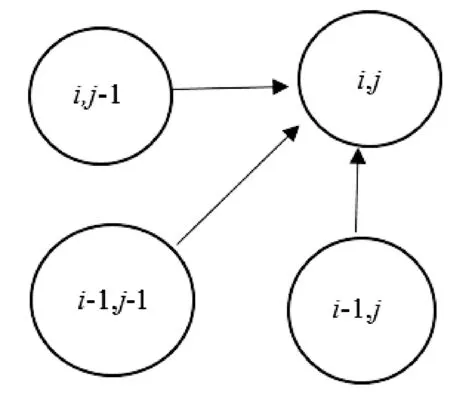
图2 相邻节点示意图
由于两段视频序列中m和n一般比较大,如果全部计算累加距离矩阵中的每个值,此矩阵必然很庞大,运算量也会很大。基于此,不少方法都对DTW的搜索路径进行了改进,从而减少计算量,提高系统的效率,如文献[12]中提出了基于菱形的全局路径约束。以上方法固定了搜索路径的斜率,不能够很好地适应两段口型时间上差别比较大的情形。文献[13]提出了三个矩形区域的路径约束条件,该方法更适合视频序列比较长的情况。本文对DTW算法进行了改进,提出了平行线的路径搜索约束条件,搜索范围由两段视频的时间差异决定,适合任意长度的视频序列。
在匹配过程中,许多节点是到达不了的,因此通过设置匹配窗口的大小,只计算两条平行线之内的部分累加距离,平行线之外的距离是不需要计算的,如图3中阴影部分,从而缩小了计算量,提高了运算速度。
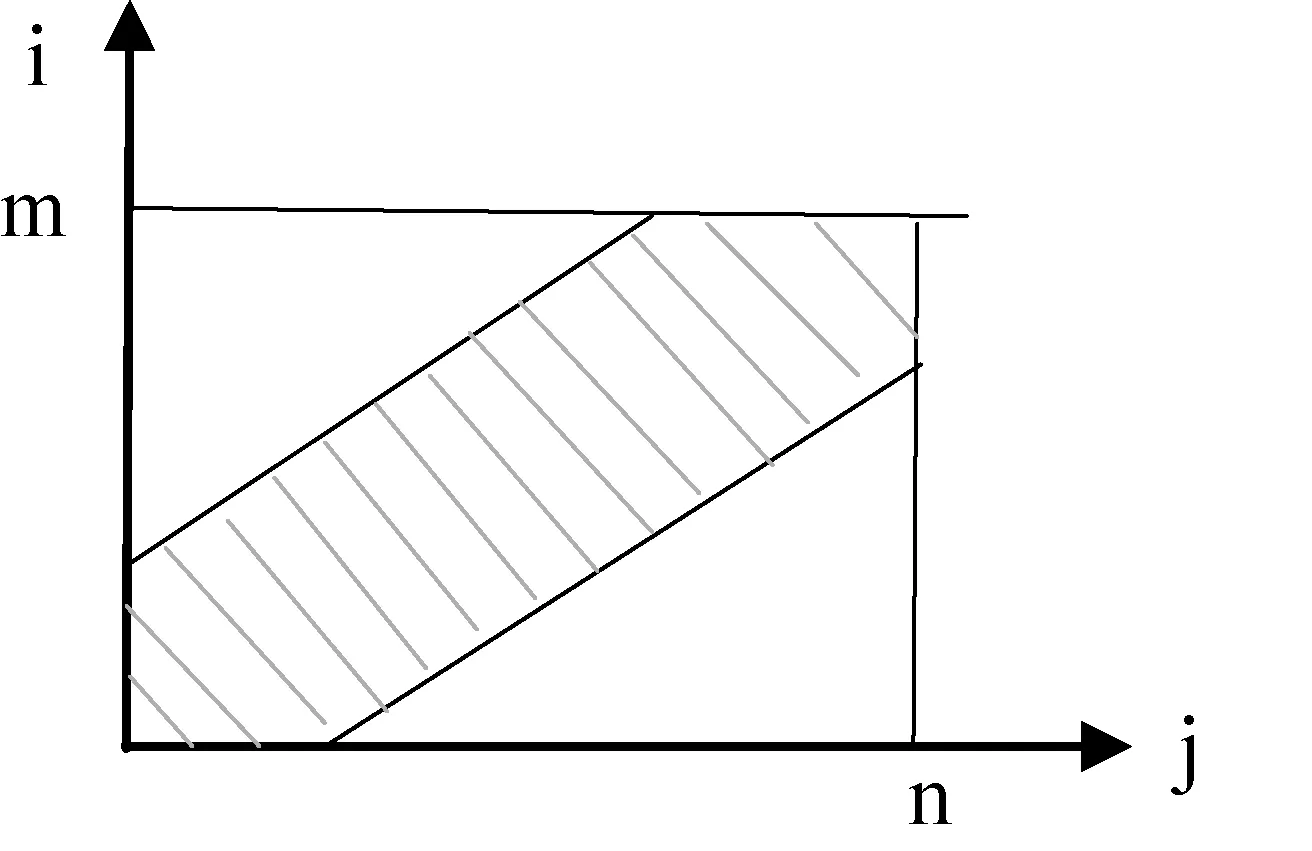
图3 路径约束示意图
这两条平行线的斜率由参考模板的长度m和待测模板的长度n共同决定,这两条平行线的方程分别为:
x(m-n+r)-yr+r(n-r)+2r=0x(m-n+r)-yr+r(n-r)=0
(4)

(1) 当i=0,j=0时,d(i,j)=2|a0-b0|。
(2) 当1≤i≤r,j=0时,d(i,j)=d(i-1,0)+ |ai-b0|。
(3) 当i=0,1≤j≤r时,d(i,j)=d(0,j-1)+ |a0-bj|。
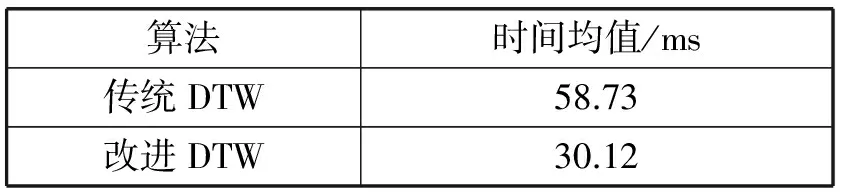
(4) 当istart≤i≤imax,1≤j d(i,j)= min{d(i-1,j)+ |ai-bj|;d(i-1,j-1)+ 2 |ai-bj|;d(i,j-1)+|ai-bj|} 累加距离矩阵计算完成之后,矩阵中最后位置(m-1,n-1)的值存放两个时间序列对齐之后的最小距离,即d(m-1,n-1)。 2.2 逆向搜索法寻找最优路径 根据前面计算得到的累加距离矩阵,从最大位置(m-1,n-1)开始逆向搜索,直到(0,0)点结束。首先给出任意两个数p和q,两数的较小者我们简单地定义为: (5) 设m=min{min(d(i-1,j),d(i-1,j-1)),d(i,j-1)},定义矩阵Pm×n来存放最优路径,初始化矩阵全部为零,当某位置(i,j)处有路径经过时,则将此处元素赋值为1,即p(i,j)=1。具体过程如下: (1) ifm=d(i-1,j) 则i--,p(i-1,j)=1。 (2) ifm=d(i-1,j-1)则i--,j--,p(i-1,j-1)=1。 (3) ifm=d(i,j-1) 则j--,p(i,j-1)=1。 (4) ifi==0,则j--,p(0,j-1)=1。 (5) ifj==0,则i--,p(i-1,0)=1。 最后遍历整个矩阵P,将值为1的坐标(xi,yi)输出,即得到最后的最优路径p0,…,pi,…,pm=(x0,y0),…,(xi,yj),…,(xm,yn),其中pi=(xi,yj),即A序列的第xi帧与B序列的第yj帧相对齐。由于待测模板向参考模板对齐,最后调整的待测模板长度与参考模板相同。对于最后得到的最优路径中待测模板某一帧同时对应参考模板好几帧的情况,即存在某段路径:(xi,yj-k),…,(xi,yj),…,(xi,yj+l),根据式(6)将该帧与参考模板重复的每一帧进行比较,计算速度的差值,选取差值最小的那一帧作为最后的对应帧。 (6) 针对视频序列对齐的结果,本文给出了关于对齐结果的相似性评价准则。它能够给出待测模板根据参考模板对齐之后达到的相似性程度,通过定义的匹配时间误差来判断。因为视频对齐的目的是使得替换的人脸口型保持相似,从而使得五官位于脸上的比例相似,视频替换上的声音仍取自电影声音,所以要求的是口型的相似而不是发音语素的相似。基于此,本文就认为口型张合的程度越相近就认为模仿越像,也就是相似性越高。 由于两段说话视频中表演者开始讲话的开始时间是随意的,评价的对象是表演者从开始说话到讲话完成为止这段时间内表演者两段讲话的相似性,所以首先获得整段序列中表演者讲话的那部分序列帧,对两段视频序列的口型速度特征向量a和b对时间求导,计算其一阶差分: (7) 本文提出了口型相似性评价参数为相似度系数SC(Similarity Coefficient),定义为: (8) 式中:pi·x表示得到的最优路径的第pi个点的横坐标;该公式表示计算对齐之后的视频与参考视频两个口型上下差值的欧式距离。经过统计整段视频每帧对应的匹配系数,当SC小于经验阈值4时就认为匹配正确,最后计算匹配正确的帧数占总帧数的比例得到视频口型对齐之后的相似性概率SP(Similarity Probability),即SP=正确匹配帧数/总帧数。 靠嘴部的运动反映表演者说话内容,不同于直接提取语音信息,这就要求说话者能够将话中的每个字的发音口型表达清楚,只有这样,才能得到对话语比较准确的特征,才能够使得匹配更加精确。实验中分别选取了不同的9段话,其中包括中文和英文。随机找了10个人来讲这9段话,每句讲2遍,讲话过程人物头部随意摆动,只要摆动角度在左右偏转45度之内就行,在实验室环境下拍摄共180段样本数据;所有实验都是在Win7 64位+Intel core i3+CPU 2.30 GHz的PC机上进行的。 实验一:下面是对人物正脸讲话情况下,发音为“open”时对齐的结果如图4所示,(a)是参考模板分别为第30、32、34、36、38、40帧时的图片,(b)是待测模板对应的相应帧的图片,(c)和(d)是分别用正向和斜向口型运动速度特征对待测模板口型对齐之后相应帧的图片。 图4 正脸口型对齐结果 实验二:以下是对人物头部有歪头情况下,发音为“我是不是哪里不好啊”时对齐结果展示,如图5所示,(a)是参考模板分别为第35、40、45、50、55、60、65、70、75帧时的图片,(b)是待测模板对应的相应帧的图片,(c)和(d)分别是用正向和斜向口型运动速度特征对待测模板口型对齐之后相应帧的图片。 图5 歪头情况口型对齐结果 从图4可以看出对于正脸情况,本文提出的两种口型运动速度特征都能使得两段视频口型对齐。但由图5(c)、(d)与(a)比较可知,正向运动速度特征已不能满足歪头的情况。由图4和图5综合比较可以看出,本文提出的斜向口型运动速度特征不仅适应正脸情况,而且在人物歪头或头部有任意小角度(<45°)运动的情况下,都能够使得两段视频序列的口型对齐。 实验三:为了避开人物嘴唇形状、厚度等外界因素的影响,本文设计的实验为每个人根据不同的9段话分别说两遍,然后测试每个人说的这两段话的相似性概率,最后计算每组匹配相似性概率的均值,共10组数据如图6所示。 图6 口型相似性评价结果 从图6中可以看出,经本文提出的口型对齐结果相似性评价方法进行评价可以得到:有的对齐比较准确,能够达到正确率95%左右;但有的结果不理想,仅有73%。经实验分析,即使是同一个人说相同的话,这两遍的发音口型也不完全相同,有时在开始结尾处的差别比较大,导致对齐的相似性概率比较低。但总平均相似性概率能够达到85.08%,说明本文提出的方法能够比较好地满足口型对齐的目的。 实验四:实验比较了传统DTW算法和经过本文改进之后的DTW算法应用到本系统中的时间效率,实验中分别统计了两种方法在180段实验样本中运行的时间,表1所示为对齐1 min的视频序列所需的平均时间。 表1 算法平均时间比较 由表中的实验数据分析得出,本文改进DTW算法相比传统DTW算法可以使得整个系统的效率提高将近2倍。 在口型特征点检测时本文将ASM和光流法跟踪相结合,通过设定阈值来纠正跟踪结果以获得准确的嘴唇特征点。在对齐过程中利用了DTW算法,经过提出的平行线的路径搜索约束条件的限制,算法运算速度明显提高。最后利用嘴唇上下运动的速度特征实现了正脸人物讲话时的口型对齐,并在此基础上又提出了斜向的运动速度特征,解决了人物讲话头部有任意小角度摆动的情况下口型对齐问题,为以后视频人脸替换奠定了基础。人物讲话存在嘴部歪斜不对称的情况,如何解决这类问题将口型对齐更加完善,将是下一步研究的问题。 [1] Bitouk D,Kumar N,Dhillon S,et al.Face swapping automatically replacing faces in photographs[C]//Proc ACM SIGGRAPH 2008.New York:ACM press,2008:1-8. [2] Dale K,Sunkavalli K,Johnson M K,et al.Video Face Replacement[J].Acm Transactions on Graphics,2011,30(6):61-64. [3] 李燕萍,陶定元,林乐.基于DTW模型补偿的伪装语音说话人识别研究[J].计算机技术与发展,2017,27(1):93-96. [4] 吴康妍,李锵,关欣.一种结合端点检测可检错的DTW乐谱跟随算法[J].计算机应用与软件,2015,32(3):158-161. [5] Sun X,Miyanaga Y.Dynamic time warping for speech recognition with training part to reduce the computation[C]//International Symposium on Signals,Circuits and Systems.IEEE,2013:1-4. [6] 张露.基于DTW的单个手语识别算法[J].现代计算机,2016(8):77-80. [7] Moon C H,Kim Y C.Hybrid gesture classifying method using K-NN and DTW for smart remote control[C]//International Conference on Information Science,Electronics and Electrical Engineering.IEEE,2014:1298-1300. [8] Hong D,Luo Y.A gesture trace detection method using DTW[J].Applied Mechanics and Materials,2013,380-384:3874-3877. [9] Ruan X,Tian C.Dynamic gesture recognition based on improved DTW algorithm[C]//IEEE International Conference on Mechatronics and Automation.IEEE,2015:2134-2138. [10] 鄢晨丹,杨阳,程久军,等.基于统计模型的DTW签名认证系统[J].信息网络安全,2015(7):64-70. [11] Ahn B,Han Y,Kweon I S.Real-time facial landmarks tracking using active shape model and LK optical flow[C]//International Conference on Ubiquitous Robots and Ambient Intelligence.IEEE,2012:541-543. [12] Jambhale S S,Khaparde A.Gesture recognition using DTW & piecewise DTW[C]//International Conference on Electronics and Communication Systems,2014:1-5. [13] Lou Y,Ao H,Dong Y.Improvement of Dynamic Time Warping (DTW) Algorithm[C]//International Symposium on Distributed Computing and Applications for Business Engineering and Science.IEEE,2015:384-387. VIDEOSEQUENCEALIGNMENTMETHODBASEDONVELOCITYOFMOUTHMOVEMENT Wang Xiaofang Wang Wenqing Wei Wei (SchoolofComputerScienceandSoftware,HebeiUniversityofTechnology,Tianjin300401,China) Based on the requirement of reducing video jitter and video matching between mouth and voice in video face replacement system, a video mouth alignment method based on the characteristics of mouth speed in video image is proposed. In the video, the ASM and the optical flow method were combined to obtain the stable velocity characteristics of the mouth, and then the path search range of the Dynamic Time Warping (DTW) algorithm was constrained by the parallel line constraint condition to obtain the optimal matching path quickly. Finally, the aligned video was obtained and the similarity evaluation was given. Experimental results show that the proposed method can make the mouth speak two videos in consistent alignment. This method not only satisfies the situation of human face immobility, but also satisfies the human head motion at any degree less than 45 degrees. Finally objective similarity evaluation is given to the imitation video, and the evaluation results show that the method is feasible. Velocity characteristics of mouth movement DTW Video mouth shape alignment Similarity evaluatio 2017-03-11。天津市科技计划项目(14RCGFGX00846);河北省自然科学基金面上项目(F2015202239);天津市科技计划项目(15ZCZDNC00130)。王小芳,讲师,主研领域:机器视觉。王文青,硕士生。魏玮,教授。 TP3 A 10.3969/j.issn.1000-386x.2017.12.040
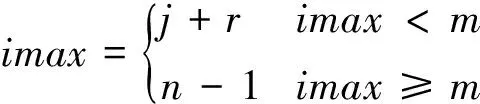
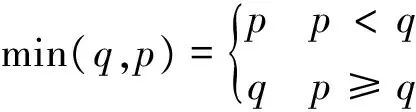

3 视频序列的相似性评价

4 实验结果



5 结 语
