基于PCA挖掘的SLE疾病的数据相关性研究
2018-01-02魏汝哲王剑平欧阳鑫杨晓洪车国霖
魏汝哲,王剑平,付 萍,张 果,欧阳鑫,杨晓洪,车国霖
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明医科大第二附属医院 风湿免疫科,云南 昆明 650500)
基于PCA挖掘的SLE疾病的数据相关性研究
魏汝哲1,王剑平1,付 萍2,张 果1,欧阳鑫1,杨晓洪1,车国霖1
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明医科大第二附属医院 风湿免疫科,云南 昆明 650500)
本文针对 SLE患者并发继发性肾炎发病原因复杂多样、影响因素众多的问题,提出了一种主成分分析降维算法,用于分析这些数据,找出最相关指标及相关规律。运用 python软件运行主成分分析算法的程序,降维得出影响SLE患者并发继发性肾炎主要指标。结果表明,利用主成分分析算法可以找出影响SLE患者并发继发性肾炎主要指标,为诊治提供科学依据。
SLE患者并发继发性肾炎,主成分分析(pca),降维
0 引言
随着信息时代的到来, 数据挖掘被越来越多地应用于临床实践。利用信息技术,医疗记录和随访数据可以更有效地被存储和提取。同时,从医学数据中寻找潜在的关系或规律,从而获得有效的对病人进行诊断、治疗的知识;增加对疾病的预测准确性,在早期发现疾病,提高治愈率。
主成分分析在医疗方面主要应用于中药的成分吸收的药效,任卫高等在主成分分析用于清肺消痤凝胶体外经皮渗透的研究[1]中,主成分分析法可以较全面的反应接受液中药物的信息,以此建立的评价方法可准确的优选出透皮吸收促进剂,并为后续中药复方经皮给药提供了可借鉴的研究思路。张卫国等在基于PCA多特征融合的肝脏B超临床医学图像识别研究与实现研究[2]中,针对任何单一特征都不能完整地表示医学图像的信息,提取医学图像的颜色特征、纹理特征以及区域形状特征,更多地保留图像的各种信息。并对提取的特征利用主成分分析(PCA)方法进行特征级的数据融合。
系统性红斑狼疮(Systemic Lupus Erythematosus,SLE)是一种临床表现涉及多种器官、多个系统受损的慢性系统性自身性免疫性疾病,其具有临床表现复杂多样,轻重缓急不一,免疫调节功能紊乱,血清中含有以抗核抗体为主的多种致病性自身抗体,病程多呈现出病情缓解和急性发作交替等特点[3-4]。SLE是一种育龄期女性好发、多脏器累及的自身免疫性疾病。狼疮性肾炎(LN)是指在SLE的基础上有肾脏疾病临床表现和(或)伴有肾功能异常,或仅在肾活检时发现有肾小球肾炎病变的系统性红斑狼疮患者。LN实际上是一种肾病,即病人的肾脏器官发生的病变,但是当这种肾病和SLE结合在一起的时候就变成了一种非常难以诊断同时又难以治疗的继发性疾病[5-7]。LN是SLE继发性疾病中发病率最高的,同时由于其发病原因复杂多样、影响因素众多而变得非常难以确诊。因此,寻找影响 LN的主要指标,对 LN疾病的诊断具有非常重要的医学意义。
PCA是一种掌握主要矛盾的统计分析方法 ,能够通过简化数据(即用较少的综合指标代替原来具有一定相关性的较多的指标)来反映原来多变量的大部分信息。本文从昆明医学院第二附属医院风湿免疫科近10年关于系统性红斑狼疮的病例中,提取出了758个已确诊患有SLE并发肾炎的病例。由于该病是SLE继发性疾病中发病率最高的,同时由于其发病原因复杂多样、影响因素众多而变得非常难以医治,而且每个病人的整理病历有280个指标,医生很难从中挑选出比较重要的指标对病人进行医治,对病人的治疗造成很大的困难。
本文通过运用 pca降维方法,对病人的指标数据进行降维,通过降维来寻找影响LN的主要指标,找出的指标来对医生提供帮助制定治疗方案。
1 主成分分析算法(pca)概述
主成分分析(Principal Component Analysis, PCA)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个新坐标轴正交而且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此我们可以忽略余下的坐标轴,即对数据进行了降维处理。
设F1表示原变量的第一个线性组合所形成的主成分指标,即由数学知识可知,每一个主成分所提取的信息量可用其方差来度量,其方差 V ar(F1) 越大,表示 F1包含的信息越多。常常希望第一主成分 F1所含的信息量最大,因此在所有的线性组合中选取 F1应该是的所有线性组合中方差最大的,故称 F1为第一主成分。如果第一主成分不足以代表原来p个指标的信息,再考虑选取第二个主成分指标 F2,为有效地反应原信息, F1已有的信息就不需要再出现在 F2中,即 F2是与 F1不相关的 X1, X2,… ,Xp的所有线性组合中方差最大的,故称 F2为第二主成分,依此类推构造出的为原变量指标第一、第二、…、第m个主成分。
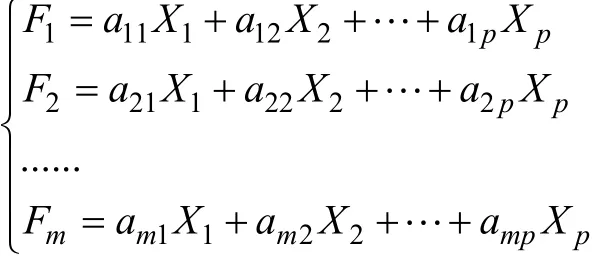
根据以上分析得知:
(1) Fi与 Fj互不相关,即 C ov( Fi, Fj) = 0
2 基于PCA的sle的数据挖掘
2.1 实验环境
本文实验中所用的计算机是 Intel (R) Pentium(R) CPU G2020 @ 2.90 GHz,8 GB内存,500 GB硬盘,Windows操作系统。在python环境下实现实验。
2.2 数据来源及预处理
本文从昆明医学院第二附属医院风湿免疫科近10年关于系统性红斑狼疮的病例中,提取出758个已确诊患有SLE并发肾炎的病例。每个病人的整理病历有280个指标,但是该数据包含有很多的缺失值。处理数据中的缺失值,我们有一些可选的做法:1.使用可用特征的均值来填补缺失值;2.使用特殊值来填补缺失值,如-1;3.忽略有缺失值的样本。在280个指标里几乎所有的样本都有缺失值,因此去除不完整的样本不太现实。在后面的算法中要进行去均值化,所以也没有采取特征的均值来填补缺失值。这里选择实数0来替换所有的缺失值。
本文在实验仿真中使用了 python第三方库numpy,由于每组数据数值差异较大,有可能影响预测效果,因此需要对数据进行归一化处理,使每组数据的参数都在 0~1 之间。

2.3 pca降维
用代码实现pca降维的流程图如下:
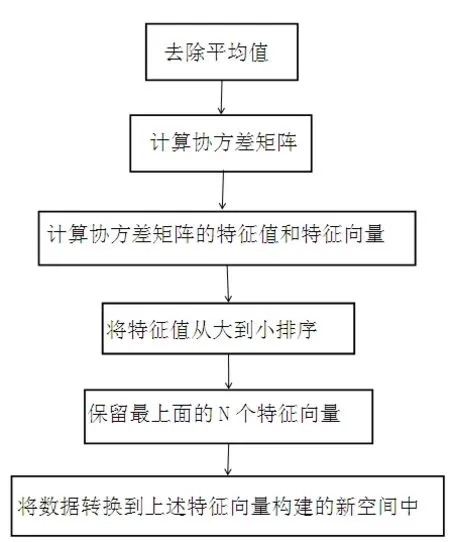
图1 pca降维流程图Fig.1 Pca dimension reduction flow chart
Python代码如下:
def loadDataSet(fileName, delim=' '):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float,line) for line in stringArr]
return mat(datArr)
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals)
eigValInd = eigValInd[:-(topNfeat+1):-1]
redEigVects = eigVects[:,eigValInd1]
lowDDataMat = meanRemoved * redEigVects
reconMat = (lowDDataMat * redEigVects.T)+ meanVals
return lowDDataMat, reconMat,eigVals,eigValInd
loadDataSet()函数是用来将数据转换为 pca()函数可以操作的数据集。
pca()函数有两个参数:第一个参数是调用loadDataSet()后得到的数据集,第二个参数topNfeat则是一个可选参数,即应用的N个特征值。如果不指定 topNfeat的值,那么函数将会返回前 9999999个特征值,或者原始数据中的全部的特征。这里我们根据和医院的交流选取前5个特征。
首先计算并减去原始数据集的平均值,mean()函数求平均值。然后通过cov()函数来计算协方差矩阵,Linalg.eig()函数计算其特征值和特征向量,接着利用啊如果 argsort()函数对特征值进行从小到大的排序。根据特征值排序结果的逆序就可以得到topNfeat个最大的特征向量。这些特征向量将构成后面对数据进行转换的矩阵,该矩阵则利用N个特征将原始数据转换到新空间中。最后,原始数据被重构后返回用于调试,同时降维之后的数据集也被返回了。
3 挖掘的结果及分析
本文是通过降维来寻找影响 LN的主要指标,通过 pca降维之后数据转换到了新的空间,所以用来构建新的空间的topNfeat个最大的特征向量是影响LN的主要指标,topNfeat个最大的特征向量也就是topNfeat个最大的特征值。
pca()函数最后输出的 eigValInd就是 topNfeat个最大的特征值的下标,通过数据可视化,图1就是最相关的 5个理化指标,这 5个指标分别是dsDNA 抗体、clq 抗体[8-9]、ANCA[10]、SM 抗体[11-12]、ALB。
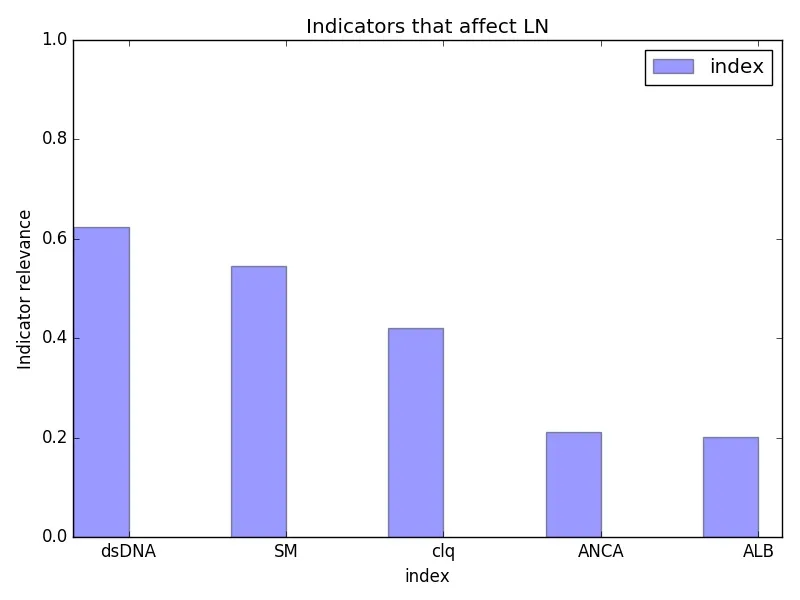
图2 数据挖掘结果Fig.2 Data mining results
通过实验得到dsDNA抗体、SM抗体、clq抗体、ANCA抗体、ALB这5个影响LN的主要指标,根据实验结果可以帮助医生得到最佳的治疗方案。
4 结语
本文通过运用 pca降维方法,对病人的指标数据进行降维,通过降维来寻找影响LN的主要指标,找出的指标来对医生提供帮助制定治疗方案。现将本文的主要内容总结如下:
(1)本文对来自医院的病例资料进行数据预处理,包括数据清洗、数据插补、数据变换,为下一步的研究做准备工作;
(2)基于预处理后的数据,通过python运算pca算法,对原始数据降维,获得影响LN的主要 指标。
(3)将运行算法获得的结果与医学文献所得结果相对比,验证了算法的正确,也为治疗 LN提供更加科学的依据。
[1] 任卫高, 彭琳秀, 雷飞飞, 等. 主成分分析用于清肺消痤凝胶体外经皮渗透的研究[J]. 中国中药杂志. 2015, 40(2):231-235.
[2] 张卫国, 王桂花. 基于PCA多特征融合的肝脏B超临床医学图像识别研究与实现[J]. 计算机应用与软件. 2014, (4):239-243.
[3] Hochberg MC.Updating the American College of Rheum atology revised criteria for the classification of systemic lupus erythem atosus[J]. Arthritis Rheum, 1997, 40(9): 1725.
[4] Kozyrev SV, Abelson AK, Wojcik J, et al. Functional variants in the B-cell gene BANK1 are associated with systemic lupus erythematosus[J]. Nat Genet, 2008, 40(2): 211-216.
[5] Biesecker G, Katz S, Koffler D. Renal localization of the membrane attack complex in systemic lupus erythematosus nephritis[J]. Journal of Experimental Medicine, 1982, 154(6):1779-1794.
[6] HOUMAN MH, SMITI- KHANFIR M, BEN GHORBELL I,et al.Sysmetic lupus erythematosus in Tunisia: Demographic and clinical analysis of 100 patients[J]. Lupus, 2004, 13(3):204-211.
[7] RESENDE AL, TITAN SM, BARROS RT, et al. Worse renal outcome of lupus nephritis in male patients: a case- control study[J]. Lupus, 2011, 20(6): 561- 567.
[8] Botto M, Walport MJ. C1q, autoimmunity and apotosis[J].Immunobiol, 2002, 205: 395-406.
[9] Braun A, Sis J, Max R, et al. Anti-chromatin and anti-C1q antibodies in systemic lupus erythematosus compared to other systemic autoimmune diseases[J]. Scand J Rheumatol,2007, 36: 291-298.
[10] 刘军生, 肖湘成, 陈立平, 等. 狼疮肾炎抗中性粒细胞胞浆抗体与临床表现的相关性研究[J]. 医学临床研究, 2006,23(10): 1606-1610.
[11] MANSON JJ, MA A, ROGERS P, MASON LJ, et al.Relationship between anti-dsDNA, anti- nucleosome and anti- alpha-actinin antibodies and markers of renal disease in patients with lupus nephritis: a prospective longitudinal study[J]. Arthritis Res Ther, 2009, 11(5): 154.
[12] SUH-LAILAM BB, CHIARO TR, DAVIS K W, et al. Evaluation of a high avidity anti- dsDNA IgG enzyme- linked immunosorbent assay for the diagnosis of systemic lupus erythematosus[J]. Int J Clin Exp Pathol, 2011, 4(8): 748-754.
Correlation of PCA-based Data Mining SLE Disease
WEI Ru-zhe, WANG Jian-ping, FU Ping, ZHANG Guo
(Kunming University of Science and Technology, Kunming 650500, China; Intelligent Measurement and Control Institute, Kunming 650500)
In this paper, we propose a principal component analysis reduction algorithm to solve the problem of complex and diverse influencing factors of SLE patients with secondary nephritis. The program of running the principal component analysis algorithm using python software was used to reduce the influence of SLE Patients with secondary primary symptoms of secondary nephritis. The results show that the principal component analysis algorithm can find out the main indexes that affect the secondary nephritis in SLE patients, and provide scientific basis for diagnosis and treatment.
SLE patients with secondary nephritis; Principal component analysis; Dimensionality reduction
TP181
A
10.3969/j.issn.1003-6970.2017.12.018
本文著录格式:魏汝哲,王剑平,付萍,等. 基于PCA挖掘的SLE疾病的数据相关性研究[J]. 软件,2017,38(12):95-97
国家自然科学基金(61364008);云南省应用基础研究重点项目(2014FA029);云南省教育厅重点基金项目(2013Z127);昆明理工大学人才培养项目(14118596);昆明理工大学复杂工业控制学科方向团队建设计划
魏汝哲(1992-),男,山东聊城人,硕士,主要研究方向为医疗数据挖掘,检测技术。单位:昆明理工大学;张果,男,研究生导师,昆明理工大学;欧阳鑫,男,研究生导师,昆明理工大学;杨晓洪,女,研究生导师,昆明理工大学;车国霖,男,研究生导师,昆明理工大学。
王剑平,男,研究生导师,昆明理工大学;付萍,女,研究生导师,昆明医科大学。
