基于随机森林和规则匹配的垃圾评论识别
2018-01-02魏伟,康准
魏 伟,康 准
(中南民族大学 计算机科学学院,湖北 武汉 430074)
基于随机森林和规则匹配的垃圾评论识别
魏 伟,康 准
(中南民族大学 计算机科学学院,湖北 武汉 430074)
针对电子商务平台存在的大量垃圾评论,提出一种基于随机森林和规则匹配的垃圾识别方法。该方法对样本进行有放回的重复抽取样以建立随机模型,以减弱评论数据集不平衡性的影响。一部分垃圾评论数据特征明显,采用规则匹配进一步提高评论识别的召回率。从现有的电商平台上提取评论数据集进行实验,结果表明基于随机森林分类模型比其他基于基线分类模型分类效果更好,且引入规则匹配机制后,分类效果也有一定程度的提高。
垃圾评论识别;随机森林;集成学习算法;不平衡问题
0 引言
随着电子商务的高速发展,越来越多的消费者习惯网上购物,同时在网上大量写下相关产品或服务的评论信息,为之后的消费者作为参考。但是,在上述评论中,存在一些垃圾评论,这些垃圾评论包括与产品无关评论,广告评论等。何海红等人[1]针对购物网站中的垃圾评论识别做了相关研究,这种评论被用于误导消费者购买行为。Gilbert等人[2]的研究发现 10%~15%的评论本质上被早期评论所影响,并且很可能被垃圾评论所影响。这些垃圾评论不仅损害消费者的权益,给网络市场的正常竞争造成了严重的负面影响。因此,甄别网络上的垃圾评论对净化网络购物环境和正确引导消费者的购物行为具有重要意义。
通过分析文献[3-4],本文将垃圾评论划分为以下几类:(1)与商品内容不相关的其他评论,比如对其他商品的评论等;(2)重复评论,相同字词重复出现,单纯为凑字数而评论;(3)与评论无关的信息,例如无意义的随机字符,各类广告和超链接等等。
近年来,研究者针对商品垃圾评论做了大量的工作。丁晟春等[5]人从评论、评论者和被评论的商品三个方面选择特征,使用SVM模型中4种常用的核函数进行垃圾商品评论的识别,取得了较好的识别效果。吴为等[6]人利用评价句的数量能有效地区分与产品无关的评论或垃圾评论,结合评论的主题词、情感倾向、文本结构等,有针对性地提取相应的特征,使用SVM分类模型对评论进行分类。何海江等[7]人提出将相关度向量空间模型CVSM作为评论的文档表示模型,讨论了信息增益 IG、互信息MI、χ2统计CHI、文档频率DF等不同特征抽取方法对模型的影响,与传统的向量空间模型相比,显著提高了垃圾评论的识别能力。
文献[5-7]虽然考虑到特征值从多维度提取,但是未考虑商品评论数据集不平衡问题。本文在文献[8-10]的工作基础上,在评论特征[11]中选取元数据特征,情感特征,评论者特征三个维度提取特征建立随机森林模型进行初步识别。与此同时鉴于一部分垃圾评论评论较显著,在初步识别的基础上,对商品评论文本进行基于规则的过滤。实验结果表明,基于随机森林和规则匹配能有效提高垃圾评论识别的准确率。
1 算法框架
1.1 识别流程
产品垃圾评论识别如图1所示。
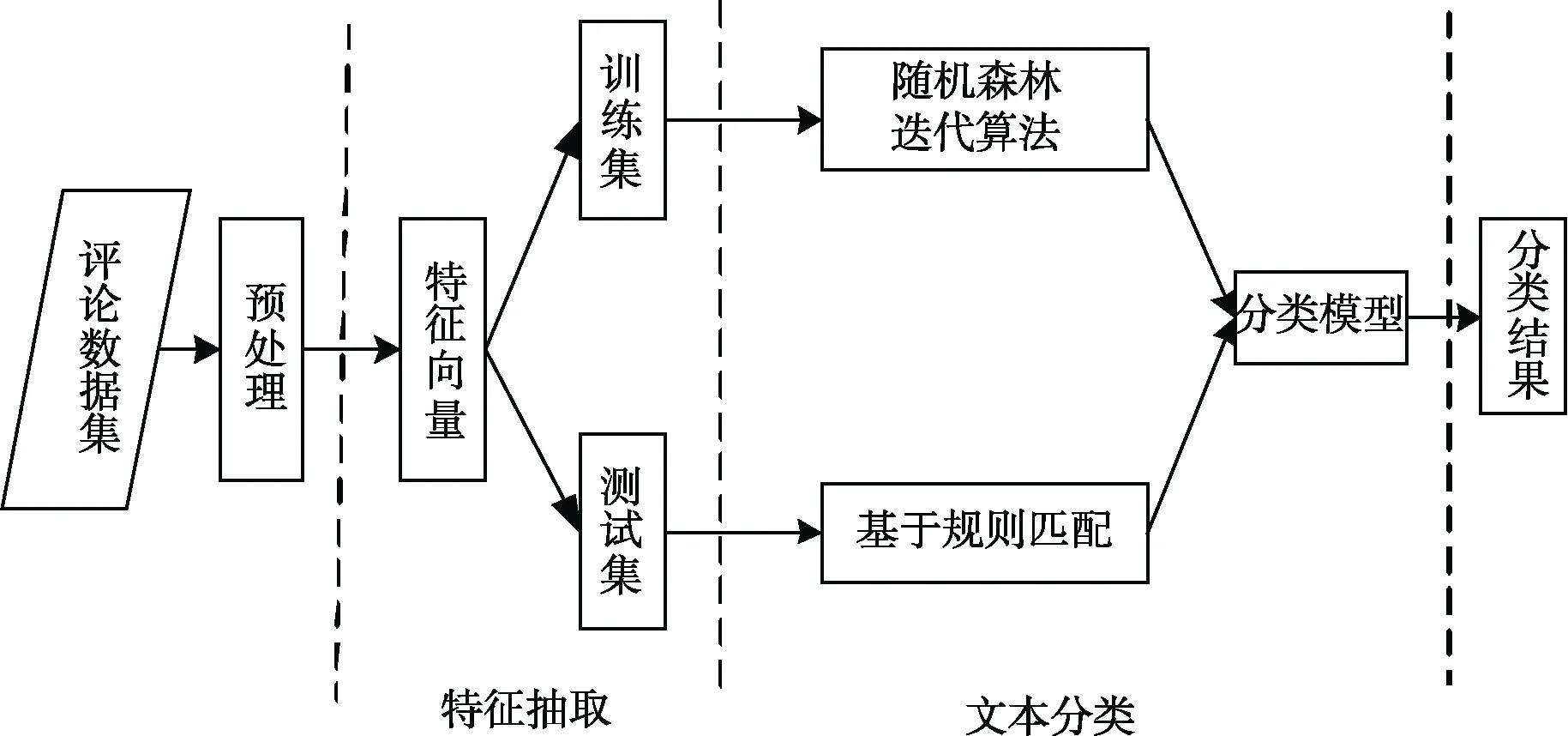
图1 垃圾商品评论识别流程Fig.1 The process of recognizing spam comment
1.2 数据预处理
鉴于商品评论样本数据形式不一致,例如一些样本评论数据中含有链接,数字等。对样本数据分词前作如下处理:(1)将样本数据中多余空格去掉;(2)剔除全是字母,数字,标点的样本数据;(3)去除重复评论。预处理结束后,针对本文的样本数据集,定义每个评论表示为特征向量其中n为本文模型中使用特征个数, yi= { 0,1},0表示正常评论,1表示垃圾评论。
1.3 特征提取
无论是半监督学习算法还是全监督学习算法,都需要用对应的特征向量表示评论。定义并抽取恰当的评论特征是正确识别垃圾评论的关键。根据商品评论的特点引入以下特征表示商品评论并提取其特征值。从三个维度提取,文本特征中选取:内容相似度,链接数,广告词数,名词度。情感特征中选取:情感词数。元数据特征中选取:获得赞数,评论长度。评论者特征中选取是否匿名,信用等级或者经验等级。
(1)内容相似度。内容相似度是指评论者为了达到评论所需的最低字数选择复制粘贴,例如评论“满意满意满意满意满意”。内容相似度越低,该评论就越有可能是垃圾评论。内容相似度计算如式(1)所示:

其中riL 表示评论ir的总汉字数,riC 表示评论ir中不同的汉字数。
(2)链接数。根据电商平台的评论数据分析,绝大多数含有超链接的评论都是属于广告评论或者推销评论。一般正常评论中是比较少的含有超链接,所以一般含有的超链接数量越多,越有可能是垃圾评论。
(3)广告词数。针对商品评论中,有人利用大部分消费者在网上购物都会看该商品的评论信息的习惯借助评论打广告。例如“全场包邮”,“淘宝链接”,“假一罚十”等等,搜集常见的广告词制作广告字典,样本评论数据分词之后与字典比较,含有广告词越多的越可能是垃圾评论。
(4)名词度。一般的评论都是表达消费者的意见,满意或者不满意。而垃圾评论更多的是描述信息,例如广告信息,营销信息。因此名词度越高,该评论越可能是垃圾评论。计算方式如式(2)所示:

其中riC 表示评论ir的总词数,rin表示评论ir中名词数。
(5)情感词数。评论一般需要表达出消费者的意见,通常饱含情绪。情感词用的越少越可能是垃圾评论。第一步,分析语料库创建情感词词典,例如“开心”,“幸运”,“倒霉”等。然后计算评论中包含的情感词语的数量。
(6)获得赞数。电商平台一般会给一个评论设置一个回馈,后面的消费者如果觉得这条评论对自己有用就可以给这个评论点赞,类似的说法还有,有用数,给评论的评论数等等。这一类的数值越低越说明这条评论是一条垃圾评论的可能性越高。
(7)评论长度。真实顾客在写评论时一般比较简短,甚至懒于评论。而垃圾评论往往为了描述更多的信息去打广告,匹配更多的关键字导致内容比较长。基于此,本文把正规化长度的平方 SNL(Square of the Normalized Length)作为描述长度的特征,在标注数据集时观察得到当SNL越接近1时该评论为垃圾评论的可能性越大,其中计算SNL如式(3)所示:

其中kmax 是表示评论数据集中最长的评论;表示评论的长度,本文采用评论中汉字的个数来表示。
(8)是否匿名。一般情况下如果评论者是匿名的情况下,说明这一类评论是垃圾评论的可能性越高。
(9)评论者信用等级或者经验等级。一般情况下如果评论者的信用等级或者经验等级越低,越说明这条评论是一条垃圾评论的可能性越高。
2 随机森林算法与规则匹配
目前主流垃圾评论识别相关方法主要考虑如何利用评论文本信息,评论者等信息对商品进行识别,忽略了评论数据集的不平衡性[12]。不平衡数据集会带来如下问题:(1)容易导致小类样本的缺失;(2)比较难区分噪声样本和小类样本。(3)决策面偏移问题等等。为了克服以上可能会产生的问题,Breiman等人在2001年提出随机森林(RF, Random Forest)算法[13],随机森林是一个包含多个决策树的组合分类器,单棵决策树可以按照一定精度分类,为了进一步提高精度标准的做法就是种植一个森林,并且让所有决策树参加投票,通过投票结果得出最终的预测结果。当采用标准的随机森林来解决垃圾评论识别问题时候,发现有较好的分类性能,但是对于一些不平衡的数据集识别速度很慢,需要做进一步改进。通过分析文献[14-15]将随机森林算法来处理垃圾评论分类问题,并减弱数据集不平衡性带来的负面影响。实验结果表明,该方法可以取得比较好的识别效果,具体算法如表1示所示。

表1 随机森林算法Tab.1 Random forest algorithm
2.1 基于规则匹配设计
根据本文上面章节总结的垃圾评论的类型以及显著性特征,我们设置了下面几种规则匹配。规则匹配包含相应的词典,正则表达式等资源,由判别逻辑表达式构成识别规则。一篇评论如果符合规则中一条或者几条,则根据规则匹配识别为垃圾评论。未识别的被留存,给下一步的分类模型进行分类识别。为了阐述规则匹配的建立过程,我们把一篇评论视为一个词语序列,不构成词语的部分则视为一个连续的字符串,词语和非词语字符串在规则匹配中等价(下面都称为词语)。对于评论文本 R为一个词语序列,W为评论文本中包含的词语的集合,规则匹配构建如下:
(1)基于关键词规则
以广告,营销,传播虚假信息等为目的的垃圾评论。在评论文本中通常包含网站链接,“http”“https”“www”等。联系方式,“加 QQ”“联系 QQ”“微信搜索”“公众号”等。营销信息,“代金券”“促销”“抢购”“热线”等。我们根据这些关键词来构建垃圾关键词词典。设置词典集合 K,以及垃圾关键词的正则表达式集合 R。正则表达式算子为Match(Word,Regx∈{true,false}),若 Word 符合正则表达式Regx,则值为true,否则为false。
规则一:若(∃ word ∈ W)(∃ regx ∈ R)(word∈ K V Match(word,regx)),则 T 为一篇垃圾评论。
(2)评论中无序字母,数字及字符序列规则
有效评论一般包含正常评论的英文单词数量,而垃圾评论中包含多个连续的与内容无关的字母,数字和字符等。利用非词语字符串占评论比例可以有效判断垃圾评论。
规则二:对于评论 T,非词语字符长度为 l,若l/|T|>χ,则评论T被认为是垃圾评论。例如:“很好吃啊!!!!!!!。。。。”等。
(3)内容相似度规则。
单纯去凑够评论字数的评论,基本毫无意义。1.3节中对于特征值内容相似度已做阐述,设置S(t)为评论T的相似度。
规则三:若|S(t)|<α,则评论T为垃圾评论。
3 实验与评价
3.1 数据集构建
现有机器学习算法中,标注训练语料的准确性将直接影响最后的分类正确性。然而目前国内对于中文语料没有一个公开的语料库。为了追求数据真实性,本文从淘宝网络商城(https://www.taobao.com)上抓取数据。本文的数据集就是基于这个抓取的数据构建得到,该数据集一共包含9901篇评论,其中正常评论8020篇,垃圾评论881篇,大类和小类的比例约为 10:1,数据集的不平衡性比较大,其构成如表2所示。
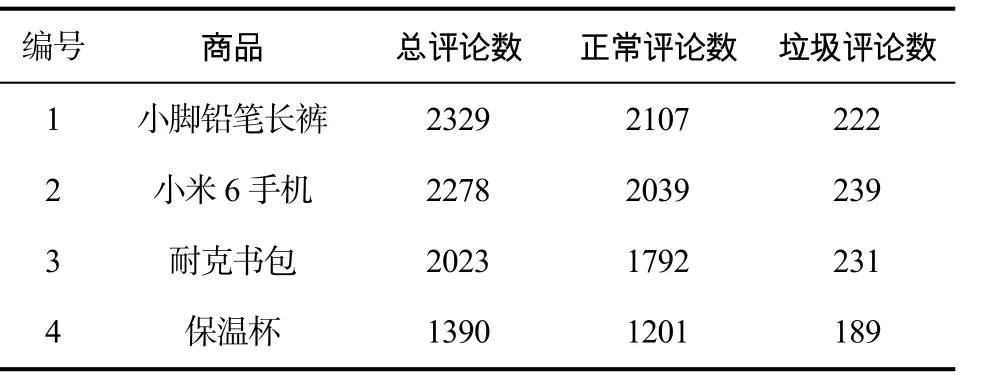
表2 实验数据集Tab.2 Experimental data set
3.2 实验设置
为了比较全面的评价本文所提识别方法的有效性,本文在统计召回率和正确率两个指标的基础上采取F值作为垃圾评论识别效果的最终测评指标。公式如下:
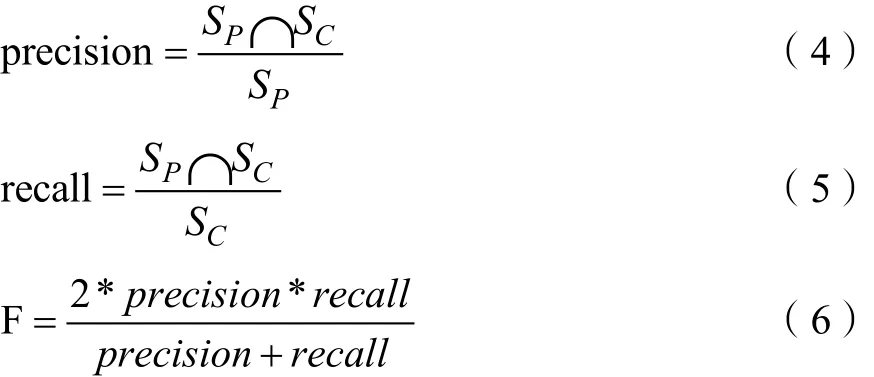
其中,CS表示实际标注的虚假评论集合;PS表示算法预测的虚假评论集合。
3.3 基于随机森林和规则匹配算法实验结果与
分析
本文采用 3.1节获取的数据集作为实验数据并且以weka作为实验平台,采用十折交叉验证的方法进行实验。为了验证本文所提方法的可行性和有效性一共设计了二组实验,第一组实验主要比较不同基线方法与随机森林的性能差别结果如表3所示。
第二组实验主要比较在本文采用基于随机森林算法的基础上,进一步进行规则过滤。基于对大量垃圾评论的观察,得出垃圾评论具有的一些显著特征,故本文在采用基于随机森林算法的基础上,采用2.1节提出的规则匹配进行过滤。实验结果如表4所示。
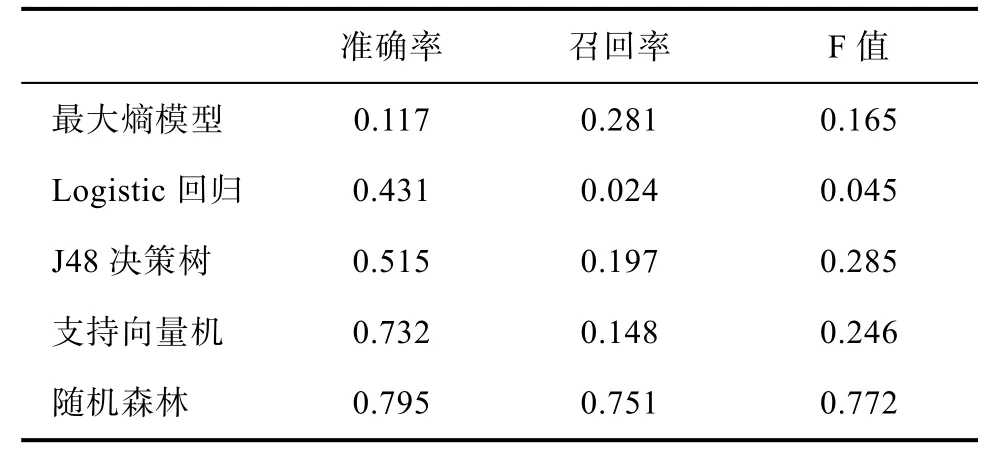
表3 基于随机森林的bagging算法与基线方法实验结果Tab.3 The results of bagging algorithm experimental
通过表2的数据可以看出,在本文收集的数据集的情况下,随机森林的识别准确率明显高于其他基于基线的方法。通过表3中的Result_1可知,经过规则过滤,对于选择的四类产品垃圾评论的识别准确率进一步提高,与此同时召回率和F值均高于Result_0,实验结果表明本文提出规则的有效性。
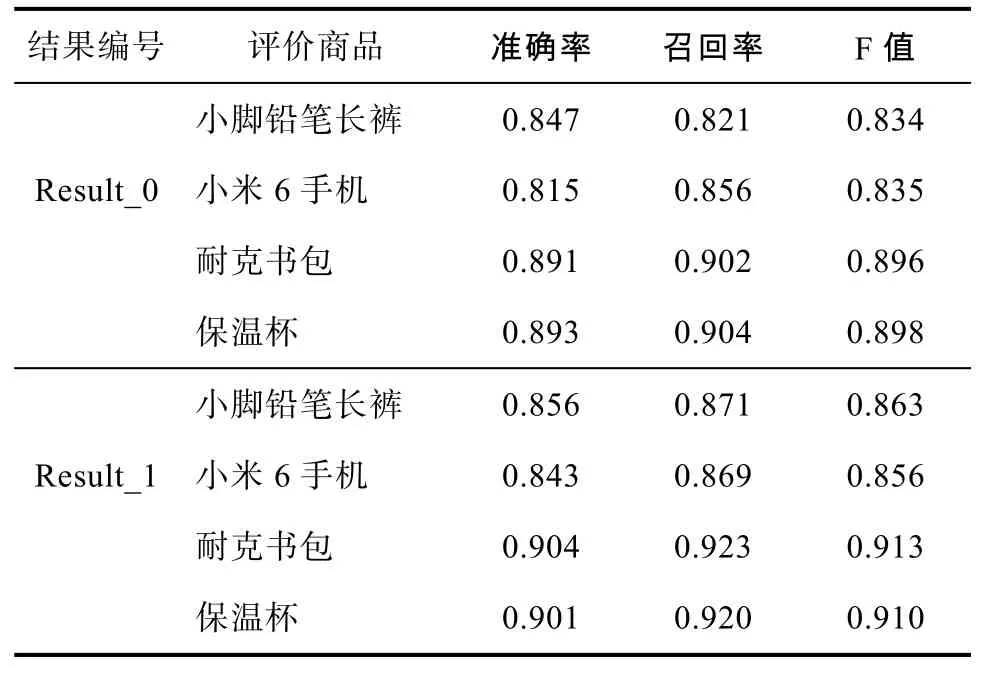
表4 基于随机森林和规则匹配的实验结果Tab.4 The results of rules matching experimental
4 结论及未来工作
本文针对垃圾评论数据集不平衡性问题,提出基于随机森林的垃圾识别方法,以减弱数据不平衡性的影响,实验结果表明本文所提的识别方法取得良好的效果,未来将尝试大规模评论数据的垃圾评论识别研究,同时针对中文垃圾评论,在特征建模过程中增加文本的心理语言学特征改进模型加快算法执行效率。
[1] SUN Y C, Li Q S. The research situation and prospect analysis of meta search engines[C]// 2012 2nd International Conference on Uncertainty Reasoning and Knowledge Engineering(URKE). IEEE. Bali. Indonesia, 2012: 224-229.
[2] CALLAN J P. LU Z H, CROFT W B. Searching distributed col-lections with inference networks[C]// Proceedings of the 18thAnnual International ACM S1G1R Conference on Research and Development in Information Retrieval. ACM.Massachusetts. USA, 1995: 2128.
[3] JINDAL N. LIU 13. Opinion spam and analysis[C]//International Conference on Web Search and Data Mining. ACM, 2008:19-230.
[4] LIU B. Sentiment Analysis and Opinon Mining[M], Chicago:Morgan&-Clayppol, 2012: 113-115.
[5] 李霄, 丁晟春. 垃圾商品评论信息的识别研究[J]. 现代图书情报技术, 2013, (01): 63-68.
[6] 游贵荣, 吴为, 钱沄涛. 电子商务中垃圾评论检测的特征提取方法[J]. 现代图书情报技术, 2014, (10): 93-100.
[7] 何海江, 凌云. 由Logistic回归识别Web社区的垃圾评论[J].计算机工程与应用, 2009, 45(23): 140-143.
[8] 章剑锋. 评论挖掘中的语义信息抽取[D]. 复旦大学, 2008.
[9] 何珑. 基于随机森林的产品垃圾评论识别[J]. 中文信息学报, 2015, 29(03): 150-154.
[10] 黄铃, 李学明. 基于AdaBoost的微博垃圾评论识别方法[J].计算机应用, 2013, 33(12): 3563-3566.
[11] 林煜明, 王晓玲, 朱涛, 周傲英. 用户评论的质量检测与控制研究综述[J/OL]. 软件学报, 2014, 25(03): 506-527.
[12] Piyaphol Phoungphol. Robust Multiclass Classification for Learning from Imbalanced Biomedical Data[J]. Tsinghua Science and Technology, 2012, 17(06): 619-628.
[13] BREIMANL Random F[J]. Machine learning, 2001, 45(1):5-32.
[14] Zhou ZH, Wu JX, Tang W. Ensembling neural networks:Many could be better than all. Artificial Intelligence, 2002,137(1, 2): 239. 263.
[15] 郭山清, 高丛, 姚建等. 基于改进的随机森林算法的入侵检测模型(英文)[J]. 软件学报, 2005, (08): 1490-1498.
Recognition of Spam Comment Based on Random Forest and Rule matching
WEI Wei, KANG Zhun
(College of Computer Science, South-Central University for Nationalities, Hubei Wuhan 430074)
Aiming at the spam comment on the existence of e-commerce platform, a identification method based on random forest and rule matching is proposed. The method extracts the same number of replicas for the two classes in the sample, or assigns the same weight to two different classes to establish a stochastic model to weaken the impact of the data set imbalance. Part of the spam comment data characteristics are obvious, the use of rule matching to further improve the recall rate of comments identified. The results show that there is a high recognition rate for the identification of spam, and the validity of the proposed method is verified by extracting the data from the actual electricity platform.
Spam collection recognition; Random forest; Integrated learning algorithm; Unbalanced problem
TP301.6
A
10.3969/j.issn.1003-6970.2017.12.017
本文著录格式:魏伟,康准. 基于随机森林和规则匹配的垃圾评论识别[J]. 软件,2017,38(12):90-94
中南民族大学中央高校基本科研业务费专项资金项目(CZZ15002)
魏伟(1991-),男,中南民族大学计算机科学学院硕士研究生,主要研究方向为自然语言处理和分布式计算。康准(1992-),男,中南民族大学计算机科学学院硕士研究生,主要研究方向为自然语言处理和知识图谱。
