云计算环境下网络异构数据节点失效概率密度分布计算
2018-01-02宋晓霞
张 杰,宋晓霞
(山西大同大学数学与机算机科学学院,山西 大同 037009)
云计算环境下网络异构数据节点失效概率密度分布计算
张 杰,宋晓霞
(山西大同大学数学与机算机科学学院,山西 大同 037009)
针对传统的网络异构数据节点失效概率密度分布计算方法,一直存在计算不准确、效率低的问题,提出云计算环境下的网络异构数据节点失效概率密度分布计算方法。通过网络数据节点效能指标、网络数据节点功率指标、平均失效节点度量指标、网络数据节点活动时间指标为基准进行失效分析,采用基环变换方法,建立约束模型,引入支持向量机的方法。通过引进一个非线性映射,对网络异构数据节点的失效概率密度分布进行计算。实验结果发现,采用改进方法时,其计算精度及计算效果均要优于传统计算方法,具有一定优势。
网络;异构数据;节点;支持向量机;失效;概率密度
0 引言
云计算方法的出现,影响范围颇大,产业界和学术界都对此议论纷纷,直到目前为止,其统一定义都未确定[1-2]。云计算使用方法中,最具有代表性的一类具体解析如下:开发者向云计算服务提供商业租用虚拟服务器,幵发者可根据需求随时处理服务器状态,使用服务器操作应用程序,同时,服务器还可以根据运行程序中不同操作指令自动匹配对应虚拟服务器数量,以此为云服务提供商结算费用提高依据[3-4]。云计算是互联网环境下的一种新型计算方法,云计算平台可实现软硬件资源和信息共享,可以根据计算机或者其他设备的不同需求,给与相对应信息提供[5-6]。云计算环境覆盖面逐渐增大,然而在使用过程中,经常会出现偏差等问题,因此对网络异构数据节点的失效概率密度分布进行计算,在该领域成为了亟待解决的问题,受到广大学者的关注[7-8]。
文献[9]提出一种异构存储节点下的可用性分析框架,以及优化的纠删码部署方法。实验表明,所提出的纠删码部署方法的可用性与系统实际可用性的差异小,性能明显优于现有的相关工作。但是该方法存在计算精度低的问题。文献[10]提出一种机架间基于任务特性和节点计算能力的数据分配策略.该分配策略提高了对数据局部性的关注,使每个节点都尽可能只访问本地数据。通过实验可知,该策略可以有效地缩短作业执行时间,提高时效性;同时提高数据局部性,减少网络数据传输,避免拥塞;最后,该分配策略还具有较好的稳定性。但存在计算精度低、耗时长的问题。
针对上述问题的产生,提出云计算环境下的网络异构数据节点失效概率密度分布计算方法。实验结果发现,采用改进的计算方法,可有效的获取失效概率密度分布情况,且计算耗时短、效率高,相比传统方法优势较大。
1 失效分析及数学模型的构建
1.1 失效分析
元件是网络异构数据节点的最小组成单元,对失效进行分析时,以单个元件作为计量单位。元件寿命长短、不同材质、装配方式、工作环境等因素都会直接影响元件的可靠性,是一个连续的随机变量,则其分布函数可表示为:

寿命概率密度函数为:
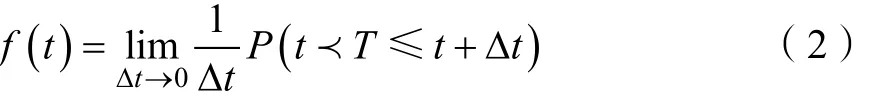
分布函数与密度函数的关系为:

网络异构数据节点的效度函数也是一种概率指标,其定义为元件在t前正常的概率,表达式为:

从定义可知:

由分布函数分布规律可知,效度函数取值区域为[0,1]。原件第一次使用并运行时,可取得较高的效度。随着使用次数增加,元件会逐渐发生磨损甚至伴随衰老,使用效度就会随之降低,直到为零。元件效率分析过程中很难获得元件寿命相关的分布函数,所以元件可靠性指标分析最常采用元件功率函数()tλ[11]。表示元件在时刻t前正常的条件下,t时刻后的条件概率密度函数为:
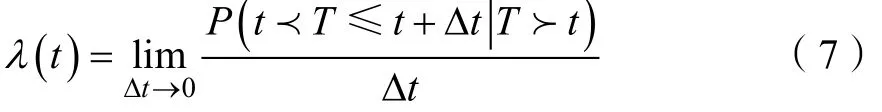
正常运行的时间概率公式为:

式中:λA为功率,λALj为主节点j的功率,为节点i上的有用功率。分别为网络异构数据节点的功率。则失效表示为其网络数据节点效能指标、网络数据节点功率指标、平均失效节点度量指标、网络数据节点活动时间指标[12-13]。
(1)网络数据节点效能指标
网络数据节点效能指标是指每个用户在单位时间内的节点效能,表达式为:

式中:iλ为网络数据节点i的平均效能;iN为网络数据节i的运行时间。
(2)网络数据节点功率指标
网络数据节点功率指标用来表示一个时间段内网络异构数据所得到的节点运行功率。用下式进行表示:

(3)平均失效节点度量指标
平均失效节点度量指标是指网络异构数据每个时间段内监测到的与失效节点相关联信息的次数,计算公式为:

(4)网络数据节点活动时间指标
网络数据节点活动时间是网络数据流在受到外界影响情况下可持续的活动时间,表达式为:

式中:iλ、iU、iN分别表示节点i的平均活动量、平均暂停时间和时间间隔。
1.2 失效约束模型分析
云计算环境下网络异构数据分析采用辐射状结构,且各节点不存在环网,则其拓扑约束表达式为:

式中: C1-1为节点间不联系, C1-2为网络数据流中不存在环网。

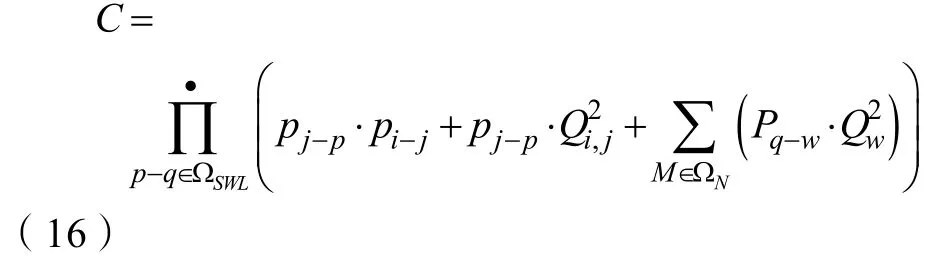
式中:SWLΩ、NΩ分别为联络节点、数据节点的集合,ijP-、ijQ-分别表示节点i j- 的有功功率和无功功率,wP和wQ分别表示代恢复区域节点q的有功效率和无功效率。在满足运行约束条件下,通过改变运行时的联络节点组合状态对拓扑结构实行转换[15-16],在不一样馈线间转换节点,从而干扰数据流分布,对运行进行优化,获取目标优化函数表达式为:
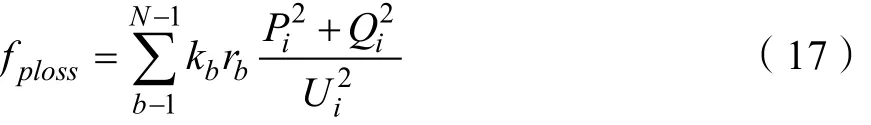
式中:polee表示的有功损耗,N表示节点数,i, j分别表示节点的首末节点号,kb为节点b的离散状态变量, rb为节点b的阻碍点, Ui为节点b的阻碍幅值,得到失效约束模型表达式为:

式中:cIλ为区域的等效故障概率,iλ、iγ为区域中元件i的平均功率和平均活动时间,ctN 为区域元件数量。
2 失效概率密度分布计算分析
在建立失效概率约束模型的基础上,采用支持向量机方法,对失效概率密度分布进行计算。
云计算环境下网络异构数据节点与正常的有所不同,其需要人为的设定一个时间间隔 dx,才能计算出失效概率密度分布值,其分布的定义表达式为:

式中,x为的节点数值, d A( x)为失效的个数,H( x)为失效概率密度。
则网络异构数据节点总的失效可以表示为:

式中: m ax( x)表示网络异构数据中最大节点。
假设失效概率主要有两个独立的随机变量Z和W,其中Z服从正态分布,W服从非对称拉普拉斯分布,具体公式如下所示:

则失效概率密度分布Yf可由Zf和zf的卷积而得到:
对于失效概率密度线性不可分的情况,能采用支持向量机的方法,通过引进一个非线性映射,将失效概率密度不可分问题,转化为线性可分问题,表达式为:
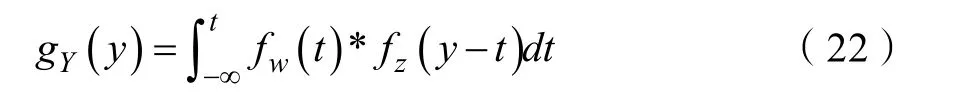

其中:H是失效概率密度特征集合,对训练样本在特征集合中的映射构造线性分类决策函数,此时的分类超平面为:

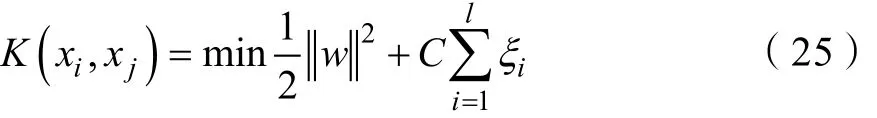
通过求解可以得到:

为了构造真实函数集的基于支持向量机的失效概率密度分布,使用一种新的损失函数ε增加失效概率密度分布计算的精度,定义如下所示:

则寻找iw和ib,使得在约束的条件下,得到失效概率密度特征为:
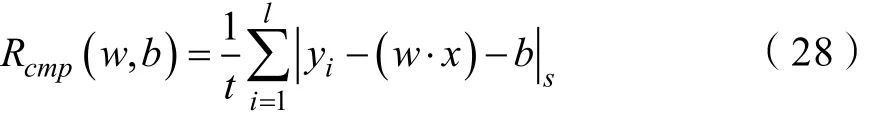
假设ξ是一个随机变量,ξ的概率分布函数,表达式为:

对其进行泛化处理,表达式为:

从概率学的角度来看,能将每个元件看作是一个独立样本,则元件的频率为元件总数,当dx无线微分,失效概率密度函数就趋近与它的频率分布,表达式为:
综上所述,在建立失效概率约束模型的基础上,采用支持向量机方法,可对失效概率密度分布进行计算,需要进行实验对比分析。
3 实验结果分析
为进一步证明数据节点失效概率密度分布计算方面,改进计算方法的有效性及可行性。采用优化函数值变化情况对节点进行分析,如图1所示,系统中含有30个节点34个支路。实验以传统计算方法与改进方法为对比进行实验分析,结果如图 1所述。
从图1可以看出,采用传统方法时,从迭代运行0~20次时,出现急剧下降的状态,但优化函数值下降到0.83时,就开始趋于平稳;采用改进方法时,从迭代运行0~20次时,出现急剧下降的状态,但优化函数值下降到0.585,才开始稳定,相比传统方法其优化效果更好。
为了进一步验证改进方法的有效性及可性能,采用传统方法与改进方法为对比进行密度分布为对比进行对比分析,结果如图2所示。
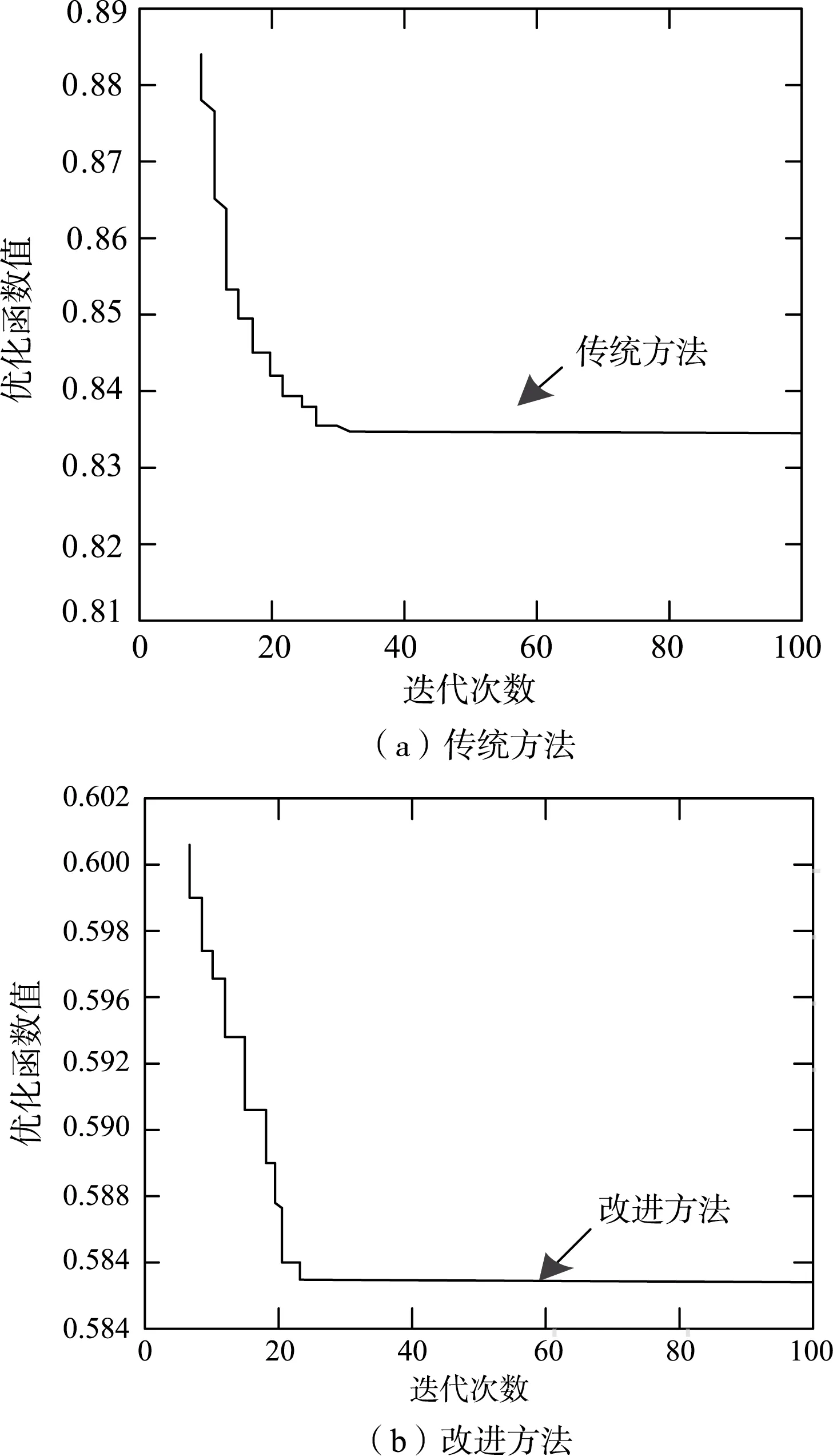
图1 不同方法下的优化函数值变化情况Fig. 1 Variation of optimal function value under different methods
从图2可以看出,采用改进方法时,其失效概率密度分布情况与实际的分布情况较为接近,且在21-29之间未出现较大波动。但采用传统方法时,其失效概率密度分布情况与实际的分布情况相距较远,且在 21-29之间出现多处波动,由此可知,改进方法相比传统方法具有一定的优势,这主要是因为改进方法对云计算环境下网络异构数据节点的失效概率密度计算时,进行了目标函数优化,获取失效概率密度特征的原因。
4 结论
云计算平台基于虚拟化技术向用户提供多种类型虚拟资源,大范围整合物理资源,提高用户计算能力,网络异构数据节点在其中担任着重要作用。针对其失效概率密度分布计算方法存在计算不准确、效率低的问题,提出云计算环境下的网络异构数据节点失效概率密度分布计算方法。建立失效概率约束模型,在此模型基础上,采用支持向量机方法,对失效概率密度分布进行计算,从优化函数值变化情况、失效概率密度分布对比两方面进行实验对比分析。实验结果证明,采用改进方法时,其计算结果精确度高,可以有效规避传统方法存在问题,效果显著。

图2 不同方法下失效概率密度分布对比Fig. 2 Comparison of probability density distribution of failure probability under different methods
[1] 向春枝, 范颖. 云计算环境中分布式数据存储关键技术研究[J]. 现代电子技术, 2016(3): 63-67.
[2] 张晋芳, 王清心, 丁家满, 等. 一种云计算环境下大数据动态迁移策略[J]. 计算机工程, 2016, 42(5): 13-17.
[3] 陈志华. 分布式云计算环境下的海量数据有效查询方法[J].科技通报, 2015, 31(8): 222-224.
[4] 白亚鲁. 云计算环境下大规模数据处理的研究[J]. 软件,2013, 34(5): 128-129.
[5] 蹇旭. 云计算环境下的海量数据特定特征挖掘技术[J]. 现代电子技术, 2017, 40(13): 178-180.
[6] 马自堂, 陈鹏, 李兆兴. 云计算环境下基于主动预测的节点部署模型研究[J]. 计算机科学, 2015, 42(9): 139-143.
[7] 耿丽丽. 失效网络中节点可通信性能评估方法研究[J]. 现代电子技术, 2016, 39(22): 27-31.
[8] 毛建旭, 毛建频, 姚晓玲, 等. 基于等价类的大型数据库频繁项集挖掘算法[J]. 新型工业化, 2011, 1(4): 35-44.
[9] 徐利谋, 李长云, 满君丰. 基于剩余能量和距离信息的异构网络分簇协议[J]. 计算机应用研究, 2016, 33(9):2763-2766.
[10] 刘波, 刘青凤. 云计算环境下异构数据节点冗余存储模式的优化[J]. 计算机应用与软件, 2015, 32(1): 30-33.
[11] 林常航, 郭文忠, 陈煌宁. 针对Hadoop异构集群节点性能的数据分配策略[J]. 小型微型计算机系统, 2015, 36(1):83-88.
[12] 蒋文贤, 赖超. 一种压缩感知的异构传感网络分簇路由算法[J]. 小型微型计算机系统, 2015, 36(2): 252-256.
[13] 杨明霞, 王万良, 马晨明. 面向节能和容错的异构WSNs数据收集算法[J]. 传感技术学报, 2016, 29(6): 934-940.
[14] 林常航, 郭文忠, 陈煌宁. 针对Hadoop异构集群节点性能的数据分配策略[J]. 小型微型计算机系统, 2015, 36(1):83-88.
[15] 杨泽民. 数据挖掘中关联规则算法的研究[J]. 软件, 2013,34(11): 71-72.
[16] 曹戈, 程玉虎. 基于初始聚类中心选取和数据点划分的K均值聚类算法[J]. 新型工业化, 2011, 1(5): 90-94.
The Failure Probability Density Distribution of Network Heterogeneous Data Nodes in Cloud Computing Environment is Calculated
ZHANG Jie, SONG Xiao-xia
(School of Mathematics and Computer Science, Shanxi Datong University, Datong Shanxi, 037009, China)
According to the traditional heterogeneous data network node failure probability density distribution calculation method, calculation is not accurate, there has been the problem of low efficiency, the proposed network of heterogeneous data in cloud computing environment the node failure probability density distribution calculation method. Through the network data node, network data node performance index, the average power failure node metrics, data network node time index as a benchmark for failure analysis, using the base ring transformation method,establish the constraint model, the introduction of support vector machine method. By introducing a nonlinear mapping, the probability density distribution of the network heterogeneous data nodes is calculated. The experimental results show that the improved method is better than the traditional method in calculation accuracy and calculation effect, and has some advantages.
Network; Heterogeneous data; Node; Support vector machine; Failure; Probability density
TM711
A
10.3969/j.issn.1003-6970.2017.12.011
本文著录格式:张杰,宋晓霞. 云计算环境下网络异构数据节点失效概率密度分布计算[J]. 软件,2017,38(12):61-65
大同市科技局软科学项目(2016120);山西省高等学校教学改革创新项目(2015090);大同市工业重点研发计划项目(2017011);山西省高等学校教学改革创新项目(J2017093)大同市科技局项目(2017127)山西大同大学科研基金项目(2017K12)
张杰(1979-),男,山西大同人,硕士研究生,讲师,主要研究方向:网络安全、物联网;宋晓霞(1975.5-),山西广灵人,教授,博士,研究方向:物联网,压缩感知。
