基于改进协同过滤算法的农产品个性化推荐研究
2017-12-22周朝进王玉珍
周朝进 ,王玉珍
(1.兰州财经大学 信息工程学院,甘肃 兰州,730020;2.兰州财经大学 甘肃商务发展研究中心,甘肃 兰州,730020)
基于改进协同过滤算法的农产品个性化推荐研究
周朝进1,王玉珍2
(1.兰州财经大学 信息工程学院,甘肃 兰州,730020;2.兰州财经大学 甘肃商务发展研究中心,甘肃 兰州,730020)
随着农村电子商务的发展,农产品电商也慢慢进入人们的生活,在国家“互联网+”战略的推动下,农产品电子商务得到了快速发展,与此同时用户的个性化需求也渐渐地成为一种趋势。为了满足消费者的个性化的需求,提出针对农产品的改进协同过滤算法,其方法结合k-means算法,从而对聚类后的每个簇中的用户进行个性化推荐,此算法不仅可满足用户的个性化需求,而且在推荐产品的准确度和时间上有了较大的改善,进而帮助商家进行精准营销,提高农民收入。
k-means聚类;协同过滤;农产品;改进协同过滤
农产品电子商务在我国起步比较晚,但用户对产品的个性化需求紧跟时代的步伐,为了满足其对农产品个性化的需求,各个平台都在尝试推出不同产品的推荐来满足用户的需要,从而促进产品的销售。所以研究人员在如何提高推荐的精确度和时间的有效性方面做了很大的努力,并且已经形成一定的研究成果,如:郑云飞等人,探讨了当前应用最为广泛的协同过滤推荐技术,针对农产品的特点,设计并实现了一个基于用户的农产品电子商务协同过滤推荐系统[1];陈龙飞、赵雪对个性化推荐系统的优缺点[2]进行了详细描述分析,但由于缺乏数据,无法进行实例验证;许瑞瑞以茶产品为电子商务个性化推荐研究对象,考虑商品评分的同时融合了商品的标签,实现了对茶产品的个性化推荐,并从积极和消极两个维度来计算用户相似性,解决数据的稀疏性问题,最后通过实验数据验证,提高了茶产品的推荐精准性[3];范顺忠,陈浩对基于用户的协同过滤算法进行改进,设计一种融合专家选择和在线推荐的菜品推荐系统,通过在候选菜品选择时引入时间敏感因子和协同过滤中引入时间遗忘因子,改进兴趣感知算法和菜品偏好预测效果,使得在推荐的准确性和效率方面有明显改进[4];丁卯结合时间权重的惩罚系数的协同过滤算法,使得评分时间越接近的用户在相似性计算时获得更大的权重,将隐语义模型和近邻算法相结合的协同过滤算法,在减小时间复杂度的同时,提高了可扩展性[5];P Melville,RJ Mooney等人提出将基于内容的预测和协同过滤进行结合,使得这总混合协同过滤的推荐算法的效果更好[6];李国提出融合聚类和协同过滤的个性化推荐算法,避免了在整个用户项目评分矩阵空间上计算邻居相似性,缩小最近邻居查找空间维度,增强算法的可扩展性[7];许艳茹,王玉珍对slopone协同过滤算法进行了改进,在运用项目相似度的基础上,加入了动态阈值,查找项目的最近邻集,最后通过近邻集预测各项目的评分,即保证了目标项目与邻近项目的相似度,不影响评分精确度,又提高推荐的准确性[8]。刘英提出了一种结合用户评论的内容推荐算法,通过挖掘网站中产品的用户评论内容,应用不同的特征集合,降低文本向量的维度,最后采用准确率、召回率和F-Measure指标对该推荐系统进行了评价,大幅度改善了推荐的质量[9]。由此可见,推荐系统的发展越来越受到重视,即为用户提供合适的商品推荐,又帮助提高电子商务系统的服务质量[10],所以,个性化推荐不仅有利于用户本身,更得益于商家,加上农产品自己的属性以及用户对绿色食品的个性化需求,使得对农产品个性化推荐研究成为一种必然性。
综上所述,目前该领域研究成果主要集中在应用领域为一些极具有特色的农产品或者只是对农产品电子商务做一些简单的述评,在实证分析的研究成果较少,因此文中提出一种基于改进的协同过滤算法进行农产品推荐,利用聚类算法使得相似用户在同一个簇中,并对其中的用户进行推荐。这种算法提高了推荐的准确性和速度,帮助商家进行精准营销,精确满足用户需求的多变性,并在很大程度上改善农户的生活,促进农产品电子商务的发展。
1 改进协同过滤算法设计
由于文中改进的算法是在协同过滤算法的基础之上进行的,所以重点介绍一下协同过滤推荐中基于用户的和基于内容的这两种算法之间的区别,如表1所示。

表1 UserCF和ItemCF优缺点对比Table 1 Comparison of advantages and disadvantages between UserCF and ItemCF
针对上表中的信息可知,不管是基于用户的还是基于内容的协同过滤推荐算法,其数据的稀疏性[11-12]是一个弊端。根据有关数据显示,数据的稀疏性可达90%以上,这对推荐的准确度有较大的影响。所以为了解决稀疏性的难题,提高推荐的准确度,文章先对稀疏性数据进行聚类,保证相似用户在同一个簇中,提高用户之间的相似度,从而有效地避免稀疏性难题,提高推荐的准确度。
1.1 改进协同过滤算法的基本思想
文中算法的基本思想是:通过k-means方法[13]根据用户的某个属性把用户进行聚类,聚类的结果就是把具有相似属性的用户分到同一个簇中,以便查找时的方便快捷,然后对簇中的用户进行推荐。首先根据用户名找到此用户属于的簇类,然后通过这个簇,找到同一个簇中其他相似的用户,其次计算这些用户所购买物品的相似度,最后把相似度较高的前几个产品推荐给该用户。
1.2 改进协同过滤算法的构建
改进协同过滤算法的基本流程如图1所示:
1.3 验证该算法的优越性
为了验证改进算法的优越性,通过与基于项目的协同过滤推荐在推荐的准确度和推荐的运行时间两方面进行比较,得出其中的差异性,实验结果如下所示。
(1)源数据收集
文中研究数据为某商务网站中农产品的用户订单信息,部分数据如下表2所示。

图1 改进协同过滤算法的基本流程图Fig.1 Basic flowchart of improved collaborative filtering algorithm

用户ID真实姓名所在地区物品年龄1067周颖 平凉市草甘霖 281067周颖 平凉市当归 281067周颖 平凉市洋葱 281073杨鹏飞平凉市蕨麻 321073杨鹏飞平凉市土豆 328239柳继先平凉市精品蔬菜556236张洁 平凉市苹果 466236张洁 平凉市精品蔬菜466236张洁 平凉市大米 463729孙文凯平凉市苹果 303729孙文凯平凉市精品蔬菜303202王小平定西市苹果 443202王小平定西市辣椒 44……………
(2)数据预处理
通过分析将农产品类别大致可以分为养生类、主食类 、鸡蛋肉类、蔬菜类、水果类和干果类,部分数据如表3、表4、表5所示。
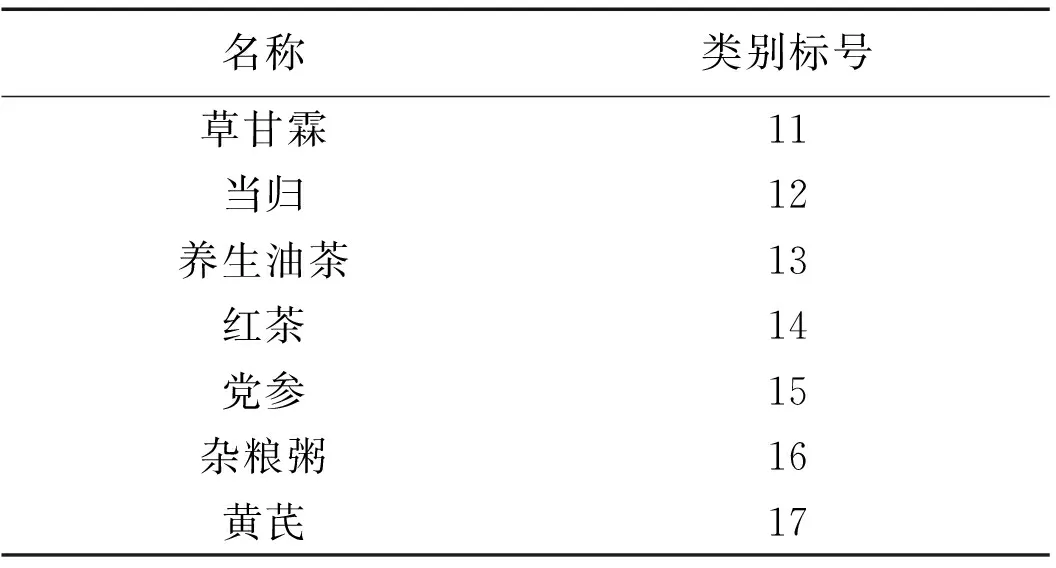
表3 养生类别Table 3 Health category

表4 主食类别Table 4 Staple food category

表5 鸡蛋肉类别Table 5 Egg and meat category
根据对农产品类别分类,将数据标准化之后形成用户物品表,如表6所示。

表6 用户物品表Table 6 User items table
(3)算法优越性检验
分别使用改进后的算法和传统的基于内容的协同过滤算法,作用于标准化之后的数据,得出其中的差异性,如下所示。
①推荐的准确度(如图2和图3所示)

图2 改进的推荐精确度 图3 传统的推荐精确度Fig.2 Improved recommended accuracy Fig.3 Traditional recommended accuracy
根据上图对比,两次准确度最高的都是22号玉米,但是准确度明显是聚类之后改进的算法推荐的结果更好一点,相似度从85.76%上升到89.44%。虽然两次实验都是推荐前10个农产品,但是推荐的农产品却不尽相同,但是相比相同的农产品,25号粉条的相似度从56.20%上升到61.24%,有了较大的提高;最后根据对比实验可知,推荐的第10个农产品的准确度上升到44.72%,推荐准确度最低的农产品的相似度也稍微的进行了改善。由此可见,改进协同过滤推荐算法推荐的效果相比于传统的、没有改进的基于项目的系协同过滤算法,推荐更好,准确度更高。
②推荐的运行时间(如表7所示)
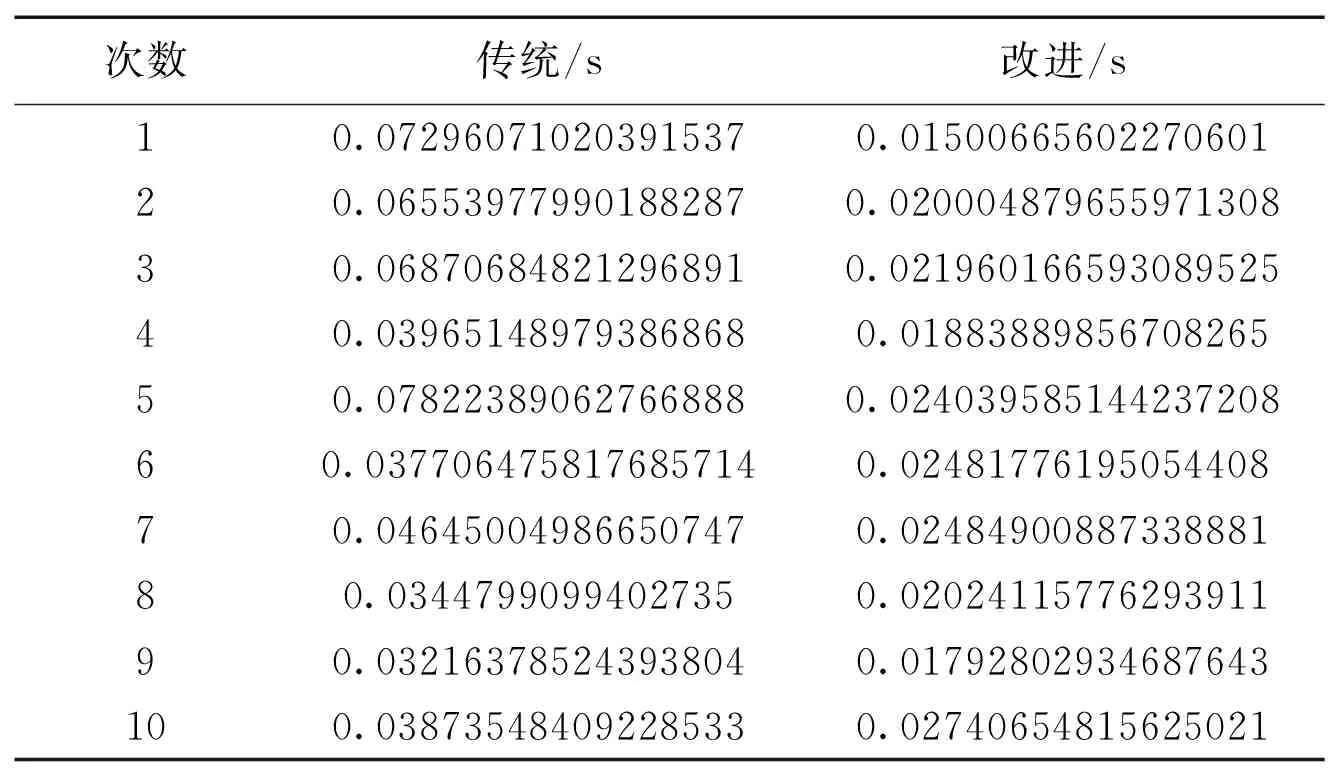
表7 运行时间对比Table 7 Running time comparisons between items and improvements
根据多次的实验结果可知,每次传统实验的运行时间都比改进之后的运行时间要长,且根据前10次的实验结果可知,传统推荐的最小运行时间要比聚类之后推荐的运行时间要长,即0.03216378524393804>0.02484900887338881。之所以改进后推荐的运行时间会缩短,原因就在于,改进后的推荐每次计算物品之间相似度的时候,都是在同一个簇类进行农产品相似度的计算,既提高推荐的准确度,又缩短了运行时间。而传统的基于项目的协同过滤推荐是基于所有数据进行计算物品之间的相似度,即要扫描整个数据库,所以耗费的时间自然会多点。
综上所述,根据两次对比实验的分析,可知改进的协同过滤的推荐算法相比于传统的基于项目的协同过滤推荐算法在推荐的准确度和运行时间上有了所改善,对满足用户的个性化需求和农产品电子商务的发展方面起到了较大的作用。
2 改进协同过滤算法在农产品个性化推荐中的应用
2.1 源数据收集及数据预处理
源数据为某商务网站中农产品的信息,并对其进行数据预处理,使其标准化。
2.2 算法实现过程
由于研究对象是农产品,种类较少,用户较多,所以文章采用的是对基于项目的协同过滤进行改进,进而对某个用户进行农产品的推荐。首先对搜集到的用户基本数据进行基本观察和总结,再根据本改进的协同过滤算法,对用户的年龄属性进行K-means聚类,将具有相似年龄段的用户聚在同一个簇中,推荐时,计算用户所在簇中的其他相似用户的农产品之间的相似度,把相似度最高的前10个农产品推荐给用户。
2.2.1 k-means聚类
文中使用k-means算法对数据中年龄属性进行聚类,并将用户年龄的分布大致分为3个簇,分别是:26-35岁的用户,熟练应用农产品电商;36-45岁的用户,初次使用网络购买农产品;46-55岁用户,尝试使用网络,即文中设定k-means 中的参数K=3。
使用工具对预处理后的数据进行聚类,得出的实验结果如下图4所示。

图4 聚类实验结果Fig.4 Clustering experiment results
经过多次实验,图4的实验效果与实际较符合。即用不同的标号标记不同的簇,并给予同一个簇中相似用户同一个标号,最后把标号添加到标准数据中。令26-35岁的用户簇为1,36-45岁的用户簇为2,46-55岁的用户簇为3。即标准数据部分显示如表8所示。

表8 聚类之后的数据Table 8 Data after clustering
续表

用户编号用户年龄物品编号簇类编号355623355413446623446413…………
2.2.2 个性化推荐
(1)推荐步骤
①找到对所推荐用户所属于的簇类标号;
②根据这个标号找到属于同一个簇的所有相似用户;
③求出相似用户所购买农产品的相似性;
④向用户推荐与他过去购买的农产品相似度较大的前10个农产品;
(2)实验结果
①向用户标号为“2”的用户推荐农产品;
②得出所推荐的农产品以及其相似度;如图5所示
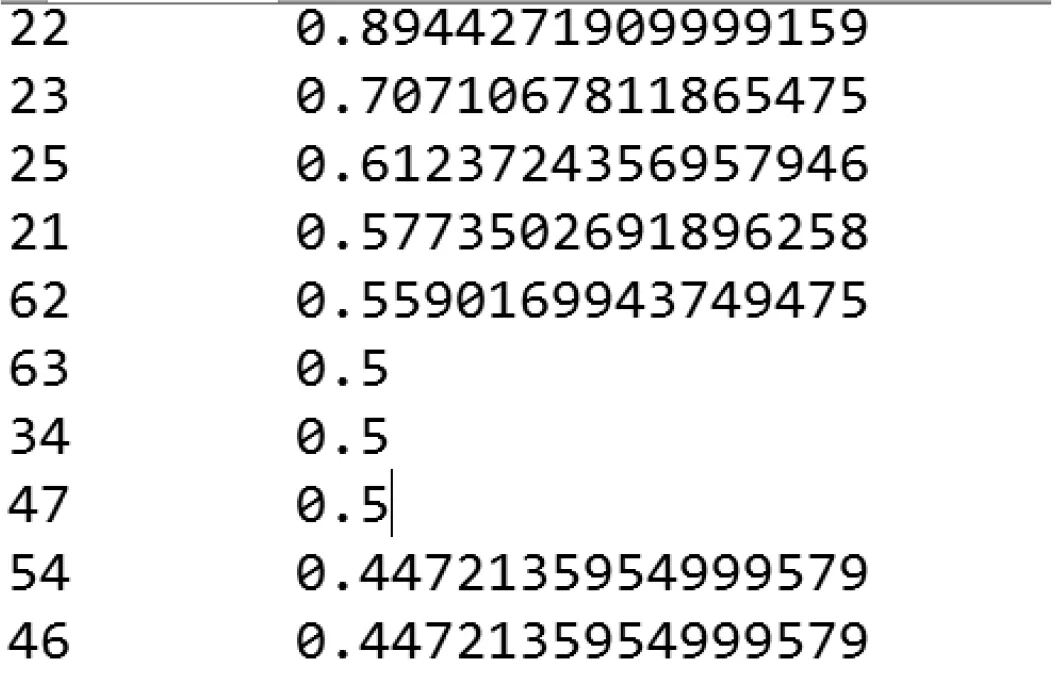
图5 推荐农产品及其相似度Fig.5 Recommended agricultural products and their similarity
③结果分析。
由图5可知,向用户2推荐的农产品有玉米、胡麻油、粉条、樱桃、苹果、杏子、红枣、洋葱、玫瑰、黄瓜等。根据原始数据我们可知用户2曾经购买过农产品有蕨痳、土豆、百合、西瓜籽、黄芪、杂粮粥、精品蔬菜。我们都知道土豆不仅可以当作食也可以作为蔬菜,并有很高的营养价值,现实生活中的好多东西如薯条、粉条都是以土豆为原材料,而与它相似度最大的是玉米,玉米也具有很大的营养价值,并且有时也可以直接当作主食食用;还具有较高相似度的是粉条,它和土豆也相似,因为大多数粉条都是土豆做的;推荐的前三个农产品有个共同的特性就是在现实生活中食用频率比较大。既然用户2买了百合、西瓜籽等干果,那么推荐的农产品里面也推荐了玫瑰干;所推荐的洋葱、黄瓜与购买的精品蔬菜有很大的相似性,都是蔬菜类的;用户2买的杂粮粥与玉米、红枣相关性较大;樱桃、苹果、杏子与用户的蔬菜都是补充人体的维生素的,具有较大的相似性。
根据实验结果与现实分析相结合,我们发现实验结果基本符合现实需求,并较满足用户的个性化需求的要求,而且推荐的准确性也比较好,所以文中研究的个性化农产品的推荐还是很有必要的,即为农产品电子商务增加了入驻流量,也满足了用户的个性化需求,并且提高了推荐的准确性,从而为供应商提供营销策略,改善农民的生活质量,提高他们的收入。
3 总结
文中提出的改进协同过滤推荐算法,即利用聚类算法,把具有相似属性的用户放在同一簇中,然后,针对某一个簇中的用户群进行农产品相似度的计算,最后得到所推荐的农产品。此文构建的算法在某种程度上提高了推荐的准确度,有效避免搜索整个数据库的局限性,使得算法在处理大规模数据集时,提高了推荐的运行时间。不仅可以为卖家提供一个了解用户需求的路径,而且可以提高农民的收入,改善他们的生活,最后并从一定程度上促进了农产品电子商务的发展。
[1]郑云飞,夏帅,谭武坤.基于用户的农产品协同过滤推荐系统的设计与实现[J].农业网络信息,2014,(09):49-53.
[2]陈龙飞,赵雪.关于农资产品个性化推荐的研究[J].电子世界,2013,(24):258-259.
[3]许瑞瑞.融合标签和评分的茶产品个性化推荐研究[D].合肥:安徽农业大学,2015.
[4]范顺忠,陈浩.基于兴趣感知和时间因子的个性化菜品推荐[J /OL].计算机应用研究,2018,35(2):[2017-03-15](预排期卷).http://www.arocmag.com/article/02-2018-02-060.html.
[5]丁卯.基于协同过滤的推荐系统研究[D].天津:河北工业大学,2014.
[6]MELVILLE P,MOONEY RJ,NAGARAJAN R.Content-boosted collaborative filtering for improved recommendations[J].Eighteenth National Conference on Artificial Intelligence,2002:187-192.
[7]李国.基于聚类和协同过滤的个性化推荐算法研究[D].昆明:昆明理工大学,2012.
[8]许艳茹,王玉珍.基于动态阈值的协同过滤算法研究[J].邵阳学院学报(自然科学版),2017,14(5):27-33.
[9]刘英.基于用户评论的个性化产品推荐系统[D].北京:北京邮电大学,2015.
[10]王小亮.基于协同过滤的个性化推荐算法的优化和应用[D].杭州:浙江工商大学,2010.
[11]邓晓懿,金淳,韩庆平,等.基于情境聚类和用户评级的协同过滤推荐模型[J].系统工程理论与实践,2013,(11):2945-2953.
[12]路春霞.个性化推荐中协同过滤算法研究[D].北京:北京交通大学,2016.
[13]王道平.我国农产品物流模式的实证研究—基于各省市的聚类分析法[J].财经问题研究,2011,(2):108-113.
ResearchonPersonalizedRecommendationofAgriculturalProductBasedonImprovedCollaborativeFilteringAlgorithm
ZHOU Chaojin1,WANG Yuzhen2
(1.School of Information Engineering,Lanzhou University of Finance and Economics,Lanzhou 730020,China;2.Gansu Business Development Research Center,Lanzhou University of Finance and Economics,Lanzhou 730020,China)
k-means clustering;collaborative filtration;agricultural products;improved collaborative filtration
1672-7010(2017)06-0023-09
TP391.9
A
2017-09-19
兰州财经大学甘肃商务发展研究中心项目(JYYY201506)
周朝进(1991-),女,甘肃白银人,硕士研究生,从事数据挖掘、电子商务研究;E-mail:2293196078@qq.com
王玉珍(1970-),女,教授,硕士,从事数据挖掘、电子商务研究;E-mail:wyz70214@163.com
Received:With the development of rural electronic commerce,agricultural products manufacturers also slowly into people’s lives,under the impetus of the national “Internet +” strategy,the electronic commerce of agricultural products has been developed rapidly,at the same time,the personalized demand of the users has gradually become a trend.In order to meet the personalized needs of consumers,this paper proposed an improved collaborative filtering algorithm for agricultural products,using K-means clustering to cluster users,personalized recommendation for users in each cluster,the proposed algorithm not only improves the platform construction,satisfies the user’s demand,but also improves the accuracy and the time of the recommended product,and then helps the merchant to carry on the accurate marketing,enhances the farmer income.
