基于粗糙集的决策树在医疗诊断中的应用
2017-12-20黄锦静李梦天
黄锦静,陈 岱,李梦天
(中国矿业大学 计算机科学与计算学院,江苏 徐州 221116)
基于粗糙集的决策树在医疗诊断中的应用
黄锦静,陈 岱,李梦天
(中国矿业大学 计算机科学与计算学院,江苏 徐州 221116)
网上医疗诊断越来越受欢迎,电子病例的数据也越来越多。如何从众多的医疗数据中降低医疗数据的冗余度,快速提取有用的医疗价值,提高医疗诊断的速度和精度,成了一个大家研究的热点问题。针对这一系列问题,研究了医疗系统关于肺癌诊断的一些数据,建立了基于属性依赖改进的可分辨矩阵属性约简的C4.5算法,并用随机森林进行算法改进。属性约简算法降低了医疗数据的冗余度,决策树算法提取了肺癌诊断的一些规则,随机森林提高了医疗诊断的准确性。文中对肺癌诊断场景进行了仿真实验与应用,并将单纯的C4.5算法,属性约简与单棵C4.5决策树,属性约简和C4.5决策树随机森林进行性能比较。实验结果表明,该方法加快了计算速度,提高了医疗诊断的精度。
粗糙集;属性约简;可分辨矩阵;C4.5算法;决策树
1 概 述
随着计算机行业的快速发展,医院也开始走向电子化时代,网上挂号、网上诊断、电子病例等,积累了海量的医疗数据。如何利用这些数据挖掘出医疗价值,即基于医疗的数据挖掘,成为一个非常热门的研究领域。医疗数据的挖掘在医疗领域应用的主要内容包括医疗图像数据挖掘、医疗管理检索系统和电子病例的分析等。例如,在医疗图像方面,文献[1]提出了一种基于成像的神经退行性疾病的分类方法,以提取突出的脑模式。在电子病例这种文本数据方面,文献[2]提出了一种可变精度粗糙集模型的属性约简算法。
特别是电子病例这类的文本数据,数据量庞大,储存了大量信息,是数据挖掘的一个热点对象。病例隐含了众多信息,记录了很多病情症状,即很多属性特征,针对不同的病情不同属性的重要度也不同,但是电子病例里面往往包含很多属性,而且有很多是冗余的。大家去医院检查都要做各种繁复的检查,其实很多检查项是冗余的,记录了很多冗余的属性,同时还增加了病人的费用。针对这些问题,如何在海量的电子病例中删除冗余症状,高效和准确地建立决策树,挖掘有重要应用价值的特征数据,是一个十分重要的课题。
粗糙集理论是一种研究模糊性和不确定性问题的数学分析和数据挖掘工具。粗糙集的主要内容是属性约简、规则提取,在很多领域应用广泛。例如,文献[3]在邮件过滤领域提出了基于变精度粗糙集的决策树分类算法,提高了邮件的正确分类率。文献[4]提出了一种在多准则排序方面的算法,即基于粗糙集的多准则排序方法,非常高效。文献[5]将粗糙集应用到食品安全检测领域,并且得到了很好的食品检查效果,提高了食品检查的速度,文献[6]将粗糙集和BP神经网络相结合,提高了粮食产量预测的精确度。文献[7]为了提高图像插值方法的插值效率,改善放大图像边缘的模糊现象,提出了一种基于粗糙集约简的支持向量机图像插值方法。文献[8]为解决危险品风险分析的一些问题,应用粗糙集理论,加快了计算速度。文献[9]为了能够有效、快速地评价电网运行的优质性水平,提出一种粗糙集与证据理论相结合的方法等。
文中将粗糙集的属性约简算法应用到肺癌诊断上。属性约简算法有很多,如通过去除某属性后,判断不可区分关系是否改变来决定是否应删除该属性,但是这种算法得到的约简集不完备。自从SKOWRON提出可分辨矩阵这一理论后[10],就出现了可分辨矩阵和粗糙集理论相结合的属性约简算法[11]。这种算法可以得到比较完备的约简集,但是引入矩阵自然增加了运算量,所以算法的复杂度高、耗时长。为了得到完备的最小约简集,文中提出了一种基于属性依赖改进的可分辨矩阵的属性约简算法,减少了计算量,提高了运算速度。
经过属性约简后的病例集属性间的冗余度有所降低,将该病例集作为训练集来构建决策树,进行规则提取。这样相比直接构建决策树进行规则提取,不仅减少了计算量,也减少了树的深度,使规则更加准确。决策树是从一组无次序且无规则的元组中推理出一组以决策树为表现形式的分类规则。它是一种自顶向下的递归方式,在树的内部节点进行属性值之间的比较,根据属性值的不同从当前节点向下进行分支,而叶节点是最终要划分的类,即决策属性。从根节点到叶节点的一条路径对应着一条合取规则,而整个决策树对应着一组析取表达式规则。决策树算法有很多,如基于粗糙集的变精度算法[12]和ID3算法[13],但是它们不能很好地处理连续值;C4.5算法是ID3算法的改进,能很好地处理连续值。因此文中采用C4.5算法通过信息熵增益率来构建决策树,同时为了提高准确率引入了决策树的随机森林。
2 问题定义
就肺癌的医疗诊断数据进行分析,定义病例样本集S={U,C,D,V,f}。其中U为病例样本的实例集合∅,即论域;C为条件属性;D为决策属性;Vi为属性i的值域;f为信息映射函数,f:C(C∪D)→V。
根据给定的训练集建立决策树,找到肺癌诊断的推理规则,进行智能诊断并预测病人的情况。因此如何建立快速且准确的诊断规则,即如何快速准确地建立决策树是关键。
2.1 粗糙集约简算法模型
定义1:已知论域U,对于每一个属性子集P⊆(C∪D),P≠∅,定义不可分辨关系IND(P);则有:∀x∈U,[x]IND(P)=[x]p=∩∀R∈P[x]R。即论域U上的一个划分为U/IND(P),IND(P)为论域U的等价关系,即有U/IND(P)={[x]IND(p)|∀x∈U}。

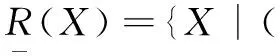
(1)

(2)
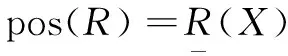
定义3:对于R∈C,对于决策条件D,如果
posIND(C)(IND(D))=posIND(C-{R})(IND(D))
(3)
则R是条件属性C上D的可约分关系,否则是不可约分关系。
定义4:在论域U上,所有的条件属性C上D的不可约分关系构成的集合,称为C的核心集,记为Core(C)。核心集为条件属性的所有约简集的交集,所以约简集一定包含核心集,且对于每个病例样本集核心集是唯一的。
定义5:对于病例集S={U,C,D,V,f},对于所有的属性P,Q属于C,有Q对P的依赖度为
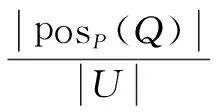
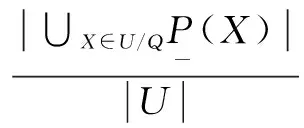
(4)
若有属性k=1,则P和Q等价。所以为了节省计算量,P和Q不应该出现在同一个最小约简集。
文中采用基于属性依赖度的可分辨矩阵约简算法,对于经典的属性频率的约简算法而言,减小了很多不必要的计算,并且考虑了属性间的依赖性,使属性约简集更加完备[14]。
对于病例集S,构建其二进制可分辨矩阵:
m((i,j),k)=
(5)
当m((i,j),k)=1时,表示属性ck在(xi,xj),xi,xj∈U下可区分,否则不可区分。
文中基于核心集Core(C),首先求最小约简集R=Core(C),然后求核心集对应的等价属性,并在可分辨矩阵中去掉其等价属性对应的值,然后选择|M(ck)|最大值的属性ck加入最小约简集。
2.2 决策树算法模型—C4.5算法
由问题定义可知,在病例集S={U,C,D,V,f}中,假设它的一个划分为{X1,X2,…,Xn},其中pi=P(xi),则有:
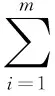
(6)

信息熵最早由香农提出,表示物理学上信息的不确定度,而在数学上则表示为信息冗余度和概率之间的关系。信息熵增益表示病例集S按照某条件属性C划分时造成熵减少的期望,如下:
Gain(S,C)=Entropy(S)-
(7)
其中,Vc表示某一条件属性c的值域;Sv表示病例集S中属性C划分时,属性C取值为v的子集合的信息熵。
ID3算法以信息熵增益作为条件属性选择的依据,更倾向于选择属性取值多的属性作为决策树的节点,而某些情况下这些节点并不是特别有价值。而C4.5算法用信息熵增益率代替了信息熵增益作为选择的标准,克服了ID3算法的不足。信息熵增益率计算方法如下:
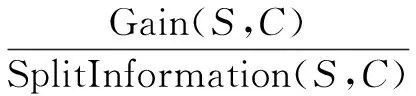
(8)
其中,SplitInformation(S,C)表示按照条件属性C划分病例集的广度和均匀性,称为分裂因子,其公式为:

(9)
决策树算法是基于属性频率的,所以ID3算法和基于粗糙集决策树无法处理好连续的实数型参数,因此要对连续实数型属性进行离散化。假设条件属性C1是连续实数型的,且样本总数为n,则设它的取值序列为VC1={v1,v2,…,vn}。C4.5算法将对它做如下处理:
步骤1:将VC1={v1,v2,…,vn}进行排序。
步骤2:对已经排序好的取值序列,以相邻两个元素的和作为断点,如下:
v=(vi+vi+1)/2(1≤i≤n)
(10)
步骤3:总共取了n-1个断点,对决策系统而言,单个断点将病例集分成条件属性C1≤v和C1>v两部分,对每个断点计算GainRatio(S,v)的值,选GainRatio(S,v)最大的那个作为区分属性C1的分割阈值,从而将属性C1离散化。
为了避免由于训练集S过多,加大树的深度,树过饱和,而导致树的准确率下降,采用悲观剪枝的方法对其进行剪枝。
3 算法设计
3.1 算法描述
基于可分辨矩阵的粗糙集属性约简的C4.5智能诊断算法包括两部分:基于属性依赖改进的可分辨矩阵属性约简算法,给定病例集S,对S进行属性约简,得到最小属性约简集;然后将S进行简化,即只留下最小约简集的属性和决策属性,得到简化后的病例集S,然后用C4.5算法构建决策树,提取关于S的规则。
算法1:基于属性依赖改进的可分辨矩阵的属性约简算法。
输入:U,原始病例样本集,待属性约简;
输出:U,属性约简后的样本实例集。
步骤1:求基于论域U,条件属性C的正域。通过式[3]找出所有不可约分关系,并求不可约分关系的交集即为核心集Core(C)。设最小约简集R=Core(C);
步骤2:求Core(C)的等价关系,并从条件属性和样本集U中去掉相关的值;
步骤3:构建二进制可分辨矩阵,选择|M(ck)|最大值的条件ck加入最小约简集;
步骤4:如果R满足知识完备性,则得到最小约简集,去掉不是约简集中数据的样本实例集U,不然返回步骤3。
算法2:基于C4.5的决策树构造算法。
输入:U,属性约简后待训练的病例样本实例集;
输出:Tree,构建好的基于C4.5算法的决策树C4.5_DTree(U)。
步骤1:计算病例集的每个条件属性的取值范围VC;
步骤2:如果当前的样本集U对于决策属性的取值全部相同,则将叶子节点赋值为该决策属性的取值,或者样本集的条件属性集为空,则叶子取值为决策属性取值比较多的值,并返回,不然转入步骤3;
步骤3:计算每个条件属性Ci的信息熵增益,首先判断是否是连续性取值,如果是,按照2.2节中的算法求其基于决策属性Dj的信息增益率,如果条件属性为离散值,直接求该属性对于决策属性Dj的信息熵增益率;
步骤4:取信息熵增益率最大的条件属性Cmax作为决策树的节点,并从条件属性集中删除属性Cmax;
步骤5:根据条件属性Cmax的取值对样本集U进行划分,并返回步骤2;
步骤6:根据样本集对决策树进行悲观剪枝。
3.2 算法改进
决策树建立在已知病例集上,一课决策树的预测和分析可能会不太准确,为了提高准确率,文中构建了决策树森林,即将属性约简之后的病例集随机划分成多个病例集,然后每个病例集生成多棵决策树,多棵决策树构成森林。由于构建每棵决策树的病例集是独立的,所以决策树之间没有关联,当有一条新的病例数据产生时,让森林里的每一棵决策树分别进行判断,以概率最大的结果作为决策结果,可以提高准确率。
4 性能评价与系统仿真
为验证文中算法对医疗诊断推理的正确性和有效性,取某医疗系统关于肺癌诊断的一些电子病例集,对基于属性依赖的可分辨矩阵属性约简算法与可分辨矩阵属性约简算法进行性能比较,将单纯的C4.5算法、属性约简与单棵C4.5决策树、属性约简和C4.5决策树随机森林进行性能比较。
4.1 仿真数据与仿真指标
采用某医疗系统关于肺癌手术后是否康复或者寿命只为1年的医疗数据进行分析,该数据总共有870条记录,有16个条件属性,1个决策属性,如表1所示。
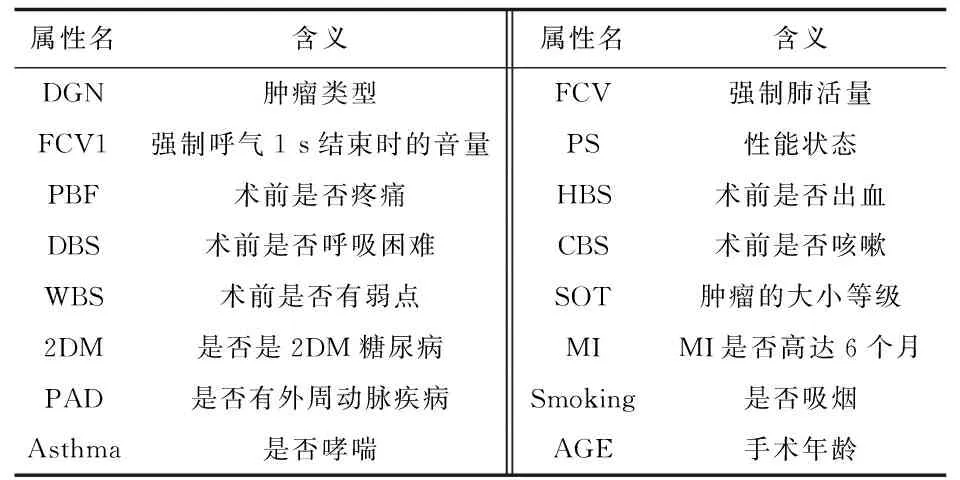
表1 属性表
以编写的C++程序作为测试工具,主要从分类的正确性和时间消耗这两个方面对肺癌数据的分析进行评价。
4.2 仿真结果
在仿真中,为验证文中提出算法的时间性能,将其与可分辨矩阵属性约简算法进行性能比较,如表2所示。

表2 属性约简算法的实验结果比较
这个数据集的核属性有5个。从表2可知,两种算法在肺癌的诊断数据上得到的最佳简约集相同,但是基于属性依赖的可分辨矩阵属性约简算法比可分辨矩阵属性约简算法的时间消耗小,前者大约是后者的0.6倍左右。
表3列举了约简后的部分数据集。
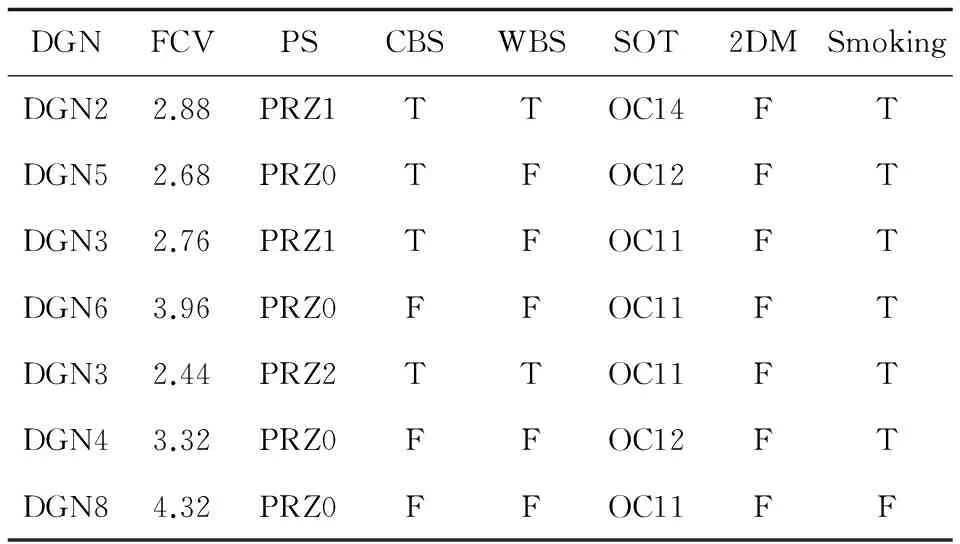
表3 属性约简之后的部分数据集
为验证属性约简之后用C4.5算法以及C4.5加随机森林的准确性,进行了规则提取的仿真。从870条记录中随机抽取120条作为检验正确性的测试集,然后用剩下的750条做训练集。对于单纯的C4.5算法,未经过属性约简,直接将原始的病例集作为训练集,构建决策树,构建好的决策树的节点有236个,规则有91条,准确率为80.8%,比较低,耗时为2.326 s。
属性约简后的训练集,用C4.5算法构建单棵决策树,得到146个节点,78条规则,正确率为91.7%,有比较大的提升,耗时减少为1.843 s。
属性约简和单棵C4.5决策树直接将这750条测试数据当作训练集即可,而对于属性约简和C4.5决策树随机森林,该算法要先进行属性约简,然后将约简后的750条数据随机抽样出300条记录,抽样成5份训练集,然后测试集进行测试时走每棵决策树的结果,将以占比大的推理结果作为结果,时间消耗比单棵决策树有所提高,为2.048 s,但正确率提升为94.2%。
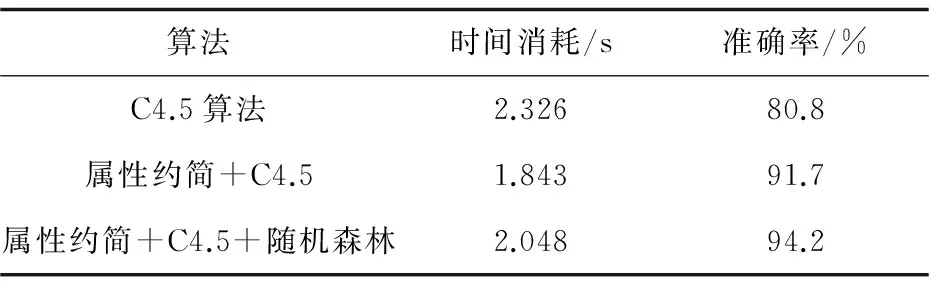
表4 决策树算法的实验结果比较
实验结果表明,属性约简之后再用C4.5算法,减少了时间消耗,提高了肺癌诊断的正确性,而且耗时短。说明去掉那些不必要的因素可以很好地提高推理的正确性,而且也防止了决策树因训练集太多,导致过饱和,而使正确性下降。从表4可以看出,加入随机森林之后,医疗诊断的准确度有所提升,这很好地避免了由于训练集过多而使决策树节点过多,从而导致不准确的情况。该算法使肺癌诊断的准确性上升了一个台阶。
5 结束语
对肺癌诊断数据进行研究与分析,着重于医疗数据属性冗余度大的问题,提出了一种基于属性依赖的可分辨矩阵的属性约简算法,找出最佳约简集,减少了很多不必要的属性。仿真结果表明,与基于可分辨矩阵的属性约简算法比较,在保证信息量的前提下,减少了算法时间开销。对快速提出准确规则问题,文中将属性约简后的训练集用C4.5算法进行规则提出,相比直接进行C4.5算法,准确率提高很多,时间消耗也降低了。为了提高分类的准确性,提出了基础C4.5算法的随机森林,实验结果表明,该算法提高了肺癌诊断结果的准确性。该方法不只可以用在肺癌数据的分类推理中,也可以用在其他病医疗数据中;但是文中本质上是根据医疗记录对肺癌数据进行的分类训练,对其他未知的情况无法给出明确的解答,这个问题还要在后期研究工作继续探索。
[1] RUEDA A,GONZLEZ F A,ROMERO E.Extracting salient brain patterns for imaging-based classification of neurodegenerative diseases[J].IEEE Transactions on Medical Imaging,2014,33(6):1262-1274.
[2] INUIGUCHI M.Attribute reduction in variable precision rough set model[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2011,14(4):461-479.
[3] 王 靖,王兴伟,赵 悦.基于变精度粗糙集决策树垃圾邮件过滤[J].系统仿真学报,2016,28(3):705-710.
[4] SZELAG M,GRECO S,SOWISKI R.Variable consistency dominance-based rough set approach to preference learning in multicriteria ranking[J].Information Sciences,2014,277(2):525-552.
[5] 鄂 旭,任骏原,毕嘉娜,等.基于粗糙变精度的食品安全决策树研究[J].计算机技术与发展,2014,24(1):242-245.
[6] 徐兴梅,曹丽英.基于粗糙集和BP神经网络的粮食产量预测研究[J].东北农业大学学报,2014,45(10):95-100.
[7] 贾晓芬,赵佰亭,周孟然,等.基于粗糙集约简的图像插值方法[J].计算机应用研究,2015,32(2):623-626.
[8] 高举红,赵天一.基于粗糙集理论的危险品运输风险分析[J].安全与环境学报,2015,15(1):40-43.
[9] 蒋亚坤,李文云,赵 莹,等.粗糙集与证据理论结合的电网运行优质性综合评价[J].电力系统保护与控制,2015,43(13):1-7.
[10] SKOWRON A,RAUSZER C.The discernibility matrices and functions in information system[J].Theory and Decision Library,2012,11:331-362.
[11] 常梨云,王国胤,吴 渝.一种基于Rough Set理论的属性约简及规则提取方法[J].软件学报,1999,10(11):1206-1211.
[12] 常志玲,周庆敏.基于变精度粗糙集的决策树优化算法研究[J].计算机工程与设计,2006,27(17):3175-3177.
[13] ZHAO Guoying,HUANG Xiaohua,MATTI T,et al.Facial expression recognition from near-infrared videos[J].Image and Vision Computing,2011,29(9):607-619.
[14] 王 珏,王 任,苗夺谦,等.基于Rough Set理论的“数据浓缩”[J].计算机学报,1998,21(5):393-400.
ApplicationofDecisionTreeBasedonRoughSetinMedicalDiagnosis
HUANG Jin-jing,CHEN Dai,LI Meng-tian
(School of Computer Science and Technology,China University of Mining and Technology,Xuzhou 221116,China)
Online medical diagnosis is becoming more and more popular,so more and more data are in electronic records.How to reduce the redundancy of medical data,extract useful medical value rapidly from a large number of medical data,and improve the speed and accuracy of medical diagnosis has become a hot issue.In view of it,some data of diagnosis of lung cancer in medical system are researched,and the C4.5 algorithm of attribute reduction based on attribute-dependent improved discernibility matrix is established and improved by stochastic forest.Attribute reduction algorithm reduces the redundancy of medical data,the decision tree algorithm extracts some rules of lung cancer diagnosis,and the stochastic forest raises the accuracy of diagnosis.In this paper,simulation and application are carried out under the scenario of lung cancer diagnosis.The simple C4.5 algorithm is made a comparison with the attribute reduction and the single C4.5 decision tree,and attribute reduction and random forests of C4.5 decision tree.The experiment shows that the proposed method accelerates the computing and improves the accuracy of medical diagnosis.
rough set;attribute reduction;discernibility matrix;C4.5 algorithm;decision tree
TP39
A
1673-629X(2017)12-0148-05
10.3969/j.issn.1673-629X.2017.12.032
2017-01-21
2017-05-25 < class="emphasis_bold">网络出版时间
时间:2017-09-27
国家级大学生创新项目(201510290002)
黄锦静(1994-),女,研究方向为计算机科学与技术;陈 岱,副教授,研究方向为计算机应用。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170927.1000.074.html
