基于蒙特卡洛树搜索的仿真足球防守策略研究*
2017-12-18柴伟凡梁志伟夏晨曦
柴伟凡,梁志伟,夏晨曦
(南京邮电大学 自动化学院,江苏 南京 210023)
基于蒙特卡洛树搜索的仿真足球防守策略研究*
柴伟凡,梁志伟,夏晨曦
(南京邮电大学 自动化学院,江苏 南京 210023)
针对Robocup仿真足球比赛中本位点区域化跑位的局限性,在三角剖分的阵型设计基础上将蒙特卡洛树搜索算法引入2D仿真中,将球员智能体在球场上的状态定义为博弈树节点,将双方球员的动作选择视为节点间的状态转移,对于球队的防守任务建立蒙特卡洛树模型。利用极坐标方式对球场进行区域分割,结合Q学习与蒙特卡洛树搜索中的信心上限树算法(Upper Confidence Bound Apply to Tree of Monte Carlo)进行球队训练,将训练结果的动作评估值用于优化比赛代码,使得球队的防守能力得到了较大程度的提升。
robocup2D仿真;蒙特卡洛树搜索算法;Q学习;动作选择
0 引言
Robocup2D仿真比赛平台是一套能够让由不同语言编写的自主球员程序进行足球比赛的仿真平台。服务器端程序Soccer Server提供了一个虚拟场地并且模拟包括球和球员在内的所有物体移动。在仿真2D足球机器人这一对抗环境中,日本Helios球队使用树搜索算法优化了球队动作链[1]。这种方式在小区域策略中起到了很好的作用,对于仿真足球是很好的启发。
基于Delaunay三角剖分的阵型设计是南邮Apollo2D球队之前的工作重点[2],如图1所示,将球场分割成三角网模型,以此实现球员的站位。这套阵型由于本位点区域化的跑位在本质上很不灵活且有一定的局限性,本文在三角剖分的阵型基础上引入蒙特卡洛树搜索算法[3]改善球队的防守策略,分组大量实验获取动作在不同区域的评估值编入比赛代码,在此基础上增加球队动作选择的科学性与灵活性。

图1 Robocup2D球场图及三角剖分的阵型设计
1 仿真足球的蒙特卡洛树模型
蒙特卡洛树搜索算法是机器学习中的一种博弈树搜索算法,它是博弈树搜索算法以及蒙特卡洛模拟方法的结合,该算法属于一个纯粹的数学模型,在多领域具有很好的通用性。将通过2D仿真介绍这一算法。蒙特卡洛树搜索算法一般分为4个阶段:选择阶段、扩展阶段、模拟阶段和回溯更新阶段。算法会重复地执行这4个阶段,直到满足场上的某一个特定情况为止。在2D仿真中,这种情况包括我方犯规、我方拦截成功、敌方进球等,整个模拟过程如图2所示。

图2 蒙特卡洛树的建立
图2中,长方形模块代表根节点,树的建立由根节点向下扩展。该节点的状态一般是指敌方持球进攻且进入我方半场。另外,当发生敌方获得定位球等使游戏中断的状态时,此状态也将成为下一次防守任务该博弈树的根节点。
椭圆形模块表示子节点,子节点是游戏中发生状态转移的一般节点,当我方智能体选择动作时产生节点之间的转移,该节点保存着我方球员智能体时间以及空间上的状态量,即在某一段时间采取什么样的防守策略。
三角形模块代表叶子节点,代表搜索树到达了游戏的边界或者不确定环境,该节点状态为敌方进球、我方断球等上述情况中的一种,或遍历到了评估值低于标准值的节点。
n/N代表着通过该节点达到任务成功的次数与该节点被遍历的总次数的比值。
选择阶段:从树的根节点开始,搜索遍历整个树,递归地选择当前节点下评价最高的那个子节点。当遍历达到叶子节点时结束该阶段。
扩展阶段:添加一个子节点进入博弈树结构中。简单地说就是,当遇到评估值较低的节点时,从添加的一系列可采取的防守动作策略中选取新的动作策略进入模拟。
模拟阶段:利用扩展阶段所描述的方式进行游戏,最后基于模拟的结果建立新节点的评估值。即采取某一个新的防守动作或策略,并以此方式直到防守任务结束,根据反馈的比赛结果评估采取的动作策略。
更新回溯阶段:当该路径的遍历结束后,沿着树的逆路径更新这条路径上所有节点的评估值。即根据防守任务达到的成效对之前所采取动作的每一个节点进行评价,改变节点中收益比值,此阶段只更新参与了本次任务动作的值。
2 动作选择策略
蒙特卡洛树模型搭建完成后,模型中各节点的动作选择所形成的节点间的转移过程决定了算法在仿真足球比赛中的适用性。本节根据球所在区域带来的威胁对球场进行区域划分,利用Q学习算法对各区域内的动作选择进行评估,结合蒙特卡洛树搜索的UCT[4]算法更新该动作下整个路径中的评价值,分小组对各个区域进行实验获取每个区域内最合理的参数值,建立了一个科学且具有灵活性的动作选择策略。
2.1 区域划分
首先,如图3所示,通过比赛经验将尺寸为52×68的我方半场不等分地剖分为4块区域,根据敌方带球队员所在区域训练球队对于禁区内部、边线进攻、中路进攻以及外围传球的防守能力。
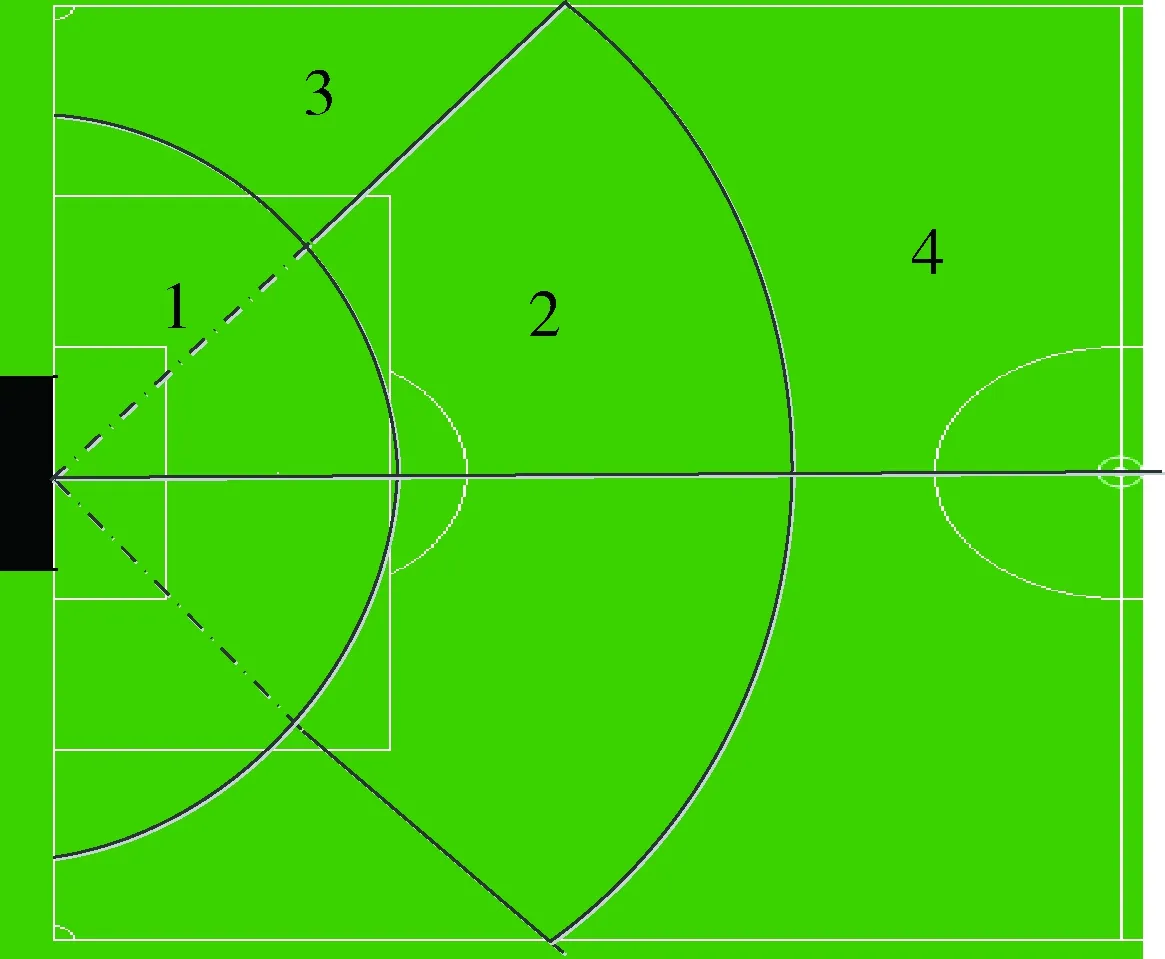
图3 球场剖分
以球门的正中心点O为极点,由O指向球场中圈的圆心P的射线为极轴建立极坐标系。再由O点出发,与射线OP呈60°作一条射线,并用圆弧将1/4球场分为4份(实线为区域边界线,1号区域由于离球门较近属于禁区范围故不参与分割,所以分割线用虚线表示),便可以根据球所在区域与球门的距离和所呈角度定位敌方球员区域,设置参数数据化敌方威胁系数。
2.2 基于Q学习的区域动作评估
Q学习作为强化学习的一个主流算法,由Watkins在1989年提出[5]。Q学习的核心思想是定义Q(st,at)表,其代表了状态st下执行动作at并在进行多次循环执行所得到的累计回报值,当多次重复实验达到收敛后,便可将最优策略表示为:
(1)
Q函数的更新等式如下:
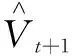
(2)

(3)
算法的优势在于智能体在不需要前瞻性搜索也不需要通过接下来的状态进行判定就可以获得最优动作。这一优势对于通过多次模拟训练来获取当前区域内的最优动作来说非常适用[6]。
由于仿真足球环境的复杂性,本文根据区域划分设立了一套当前动作获得的实时收益的评估机制,该机制可以由下式进行简单的表述:
(4)
其中,S(s,dis)代表训练中出现敌方射门情况时的射门结果和射门距离,当敌方进球,S(s,dis)取0;η代表敌方球员在我方队友采取动作s时所在区域的危险系数(2.1节中所划分的区域每一块均设置了其危险系数);Q*代表了动作产生的一些直接回报值,例如铲断成功、犯规获得黄牌等。在此基础上,便可以在每个区域动作的训练过程中获得一个及时的评价值来对动作进行优化。
2.3 基于UCT算法的动作评估
在仿真足球比赛中,防守的目的便是阻止对方球员进攻得分。因此,根据最终结果返回区域动作一个评价值这一延迟奖励机制是必不可少的。本小节将蒙特卡洛树搜索中的UCT算法引入仿真环境,对整个动作树评估机制进行优化设计。
UCT算法雏形来自于多臂匪徒问题[7],在没有先验知识的情况下,算法提出了一个能够快速收敛且高效的策略。这个算法关键在于很多时候它不仅选择最好的动作,还同时兼顾探索一些通常的动作,这样做是通过对每个被访问的低势候选动作的胜率增加一个数来实现的。但是这个数每次在父节点被访问或是其他走法被选择时会同时升高一点。这一思想可以用信心上界索引公式表示:
(5)
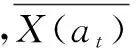
仿真足球环境中的UCT算法流程在2.1节中已进行介绍,这里不再做过多阐述。它的优势为在保证探索更好的路径的基础上具有很好的方向性与自主学习能力。
2.4 动作训练
训练过程中,将Q学习与UCT算法相结合,在保证探索性和尽量保证选取最优动作的前提下通过调节参数获得一个较为科学的评价机制,公式表述如下:
Vt=aQ(st,at)+I(at)
(6)
其中,UCT算法起主导作用,用于探索未采用的节点并通过将最终结果回溯更新动作评价值的方式影响动作的评估值;Q学习得到的当前区域动作收益值起到调整修正总评估值Vt的作用且保证了随着加权系数C的调整,该实验的收敛速度。实验中的算法流程如下:
初始化Q表:
(1)获取球场信息,创建根节点N(st);
(2)将下一步可以采取的动作作为子节点N′(st);
(3)由Vt选取动作;
(4)由式(2)得到Q(st,vt);
(5)N′(s1)访问下一层子节点直至终局,回溯更新遍历的所有子节点,更新Vt;
(6)转步骤(2),直至Vt收敛。
在Linux14.04操作系统,rcssserver15.2.2比赛平台下,使用trainer训练器进行场景模拟,分为中路进攻、边路进攻的6V5防守场景,以及模拟快速反击的中路3V2防守场景。对剖分的4块区域进行分组动作模拟,训练周期为50周期,每个区域训练次数为500,根据收集得到的结果,绘制折线图,本小节以快速反击情况下2区域内的动作选择为例,得到的数据如图4所示。
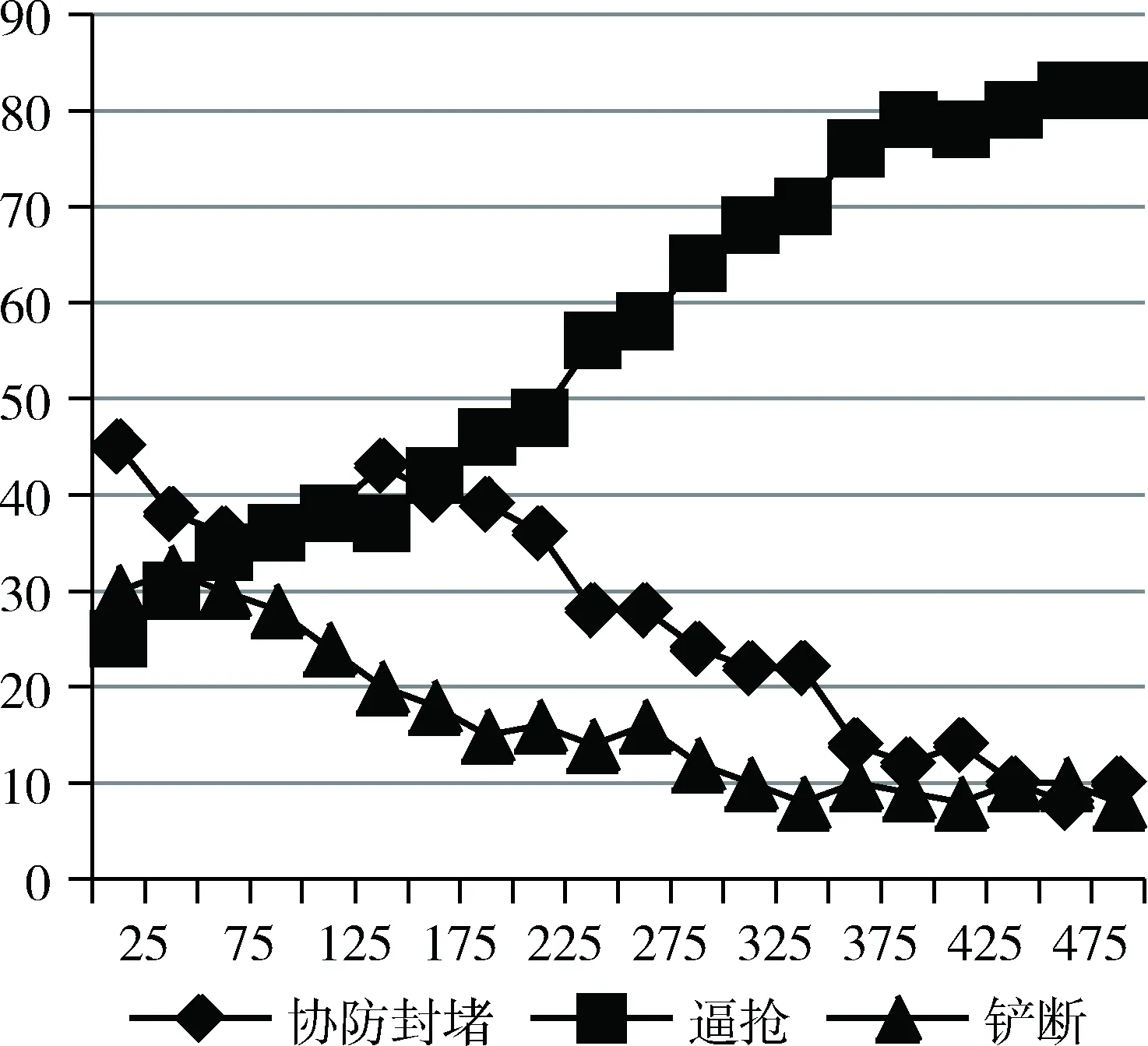
图4 训练数据统计图
图4中,横坐标代表训练次数,纵坐标代表动作被选取的百分比。可见,当训练次数达到400次左右时,评估函数已经基本收敛。
2.5 比赛应用
在Robocup2D仿真比赛中,将模拟训练所得到的数据录入Apollo2016比赛源码中,得到了一套较为合理的动作选择策略。而在比赛中,为了避免代码的复杂性造成智能体接收信息出现障碍等情况,本文对Apollo2016比赛代码在Q学习策略上进行了一定删除,其中采取蒙特卡洛树搜索的动作选择策略伪码如下:
functionUCTSelect;
while处于比赛状态do
ApolloPolicy(s)
//球队根据训练数据定义的初始策略
returun a(bestaction(s))
functionApolloPolicy(s)
利用a=bestaction(s)进行比赛
//初始定义的评估值最高的动作
while返回评估值<定义评估值do
vn← 扩展阶段(v)
Δ←模拟阶段(s)
回溯更新阶段(v,Δ)
//s代表当前状态,v代表当前节点
else
return状态s收益
function扩展阶段(v)
选择行动a∈其他评估较高的可选择动作
为v添加子节点v’,令s(v’)=f(s(v),a),a(v’)=a
returnv’
function模拟阶段(s)
whiles非终止状态do:
继续按照apollopolicy策略行动
s←f(s,a)
return状态s的收益
function回溯更新阶段(v,Δ)
whilev≠Nulldo:
n(v)=n(v)+1;
//更新该条路径上的访问次数
V*(v)=V*+Δ;
//更新所访问路径的收益值
functionbestaction(v)
3 比赛结果分析
本节将基于蒙特卡洛树搜索算法的防守策略应用于南邮Apollo2016球队,通过实例分析和比赛数据两方面对球队进行分析,实验结果如下。
3.1 实例分析
本小节以2015年、2016年两届Robocup中国赛中南邮Apollo球队的比赛为例,通过分析对相同情况的不同处理方式论证算法的合理性。
图5(a)是2015年国赛Apollo2015对阵Yushan2015(2015年国赛亚军)场景,图5(b)是2016年国赛Apollo2016对阵Yushan(2016年国赛冠军)场景。均为敌方智能体断球后进行快速反击,带球压迫至禁区的情形。
图5(a)为依赖于Delaunay三角剖分阵型设计的防守
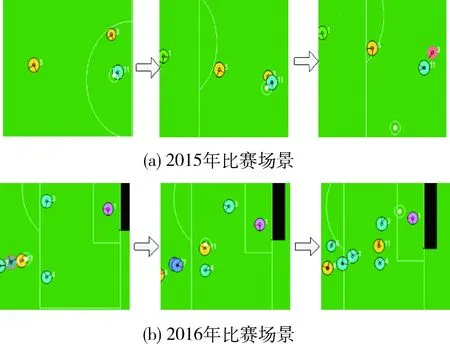
图5 比赛实例分析
体系,该体系面对敌方智能体进攻时有较好的针对性,不容易出现漏人等情况。但受限于本位点盯防的区域化限制,在面对反击时的表现则显得较为死板。图中,敌方断球快速反击,由9号智能体带球进入禁区,由于阵型设计根据球的位置规定了球员的防守站位区域,我方智能体便选择了区域协防策略。然而对方球员在大禁区位置直接选择射门,导致球队失球。图5(b)为建立在三角剖分阵型基础上,运用基于蒙特卡洛树搜索的防守策略优化后的球队。由于在之前的训练调试过程中,出现过多次这样的丢球情况,根据反馈评估值,当智能体再次面临这种情况时,就不再使用评估较低的协防策略,而选择了4号智能体后撤协防,3号智能体直接抢断的动作,这一具有高风险高回报的动作最终成功完成防守。
3.2 比赛数据分析
本小节以2016年国赛南邮Apollo2016队面对前八球队的详细防守数据为例,并添加赛后进行的Apollo2015、2016对相同对手50次防守实验和10次比赛实验比较,数据如表1。

表1 球队防守成功率表 (%)
定义敌方获得射门机会以及获得前场任意球为防守失败。观察表1中的数据可以清楚地发现,基于蒙特卡洛树搜索的防守策略拥有更好的防守效果。本文提出的策略在比赛中拥有更好的灵活性和适用性。
4 结束语
为了增加球队防守的全面性与灵活性,本文在三角剖分的阵型设计上引入基于蒙特卡洛树搜索算法的防守策略使得球队动作的执行不再更多地依赖于区域划分,而是更多地基于场上的形势,使得Apollo2D球队获得了国赛第三这一近年来最好的成绩。但是当面对没有交手记录的强队时,需要一定时间在比赛中进行节点评估与模拟,这会增加一定的危险性,仍需要其他的保护策略来优化球队防守能力。
[1] AKIYAMA H, NAKASHIMA T, ARAMAKI S. Online cooperative behavior planning using a tree search method in the robocup soccer simulation[C]. Proceedings of 4th IEEE International Conference on Intelligent Networking and Collaborative Systems (INCoS-2012),2012:170-177.
[2] Xu Xiaoxing, Liang Zhiwei. Team formation design using Delaunay triangulation in Robocup 2D simulation competition[C].Proceedings of 27th Control and Decision Conference (CCDC), Qingdao, China, 2015: 4335-4340.
[3] BRADBERRY J. Introduction to Monte Carlo tree search[EB/OL].(2015-09-07)[2016-08-15]. https://jeffbradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/.
[4] GELLY S, WANG Y. Exploration exploitation in go: UCT for Monte-Carlo go[C]. In: Advances in Neural Information Processing Systems 19 (NIPS),2006.
[5] WATKINS C. Q-Learning[J]. Machine Learning, 1992, 8(3): 279-292.
[6] 申时全. Linux多线程编程技术在掷骰子游戏模拟程序中的应用[J]. 微型机与应用,2016,35(9):85-88.
[7] AUER P. Using confidence bounds for exploitation-exploration trade-offs[J]. the Journal of Machine Learning Research, 2003(3): 397-422.
Research on simulated soccer defensive strategy based on Monte Carlo tree search algorithm
Chai Weifan, Liang Zhiwei, Xia Chenxi
(College of Automation, Nanjing University of Post and Telecommunications, Nanjing 210023, China)
Aiming at the limitation of regionalization of standard point in RoboCup simulating, in this dissertation, Monte Carlo exploring method is introduced to 2D stimulation at the basic of Delaunay triangulation, and it uses player agent to define nodal point of game tree, and players’ choices of movement are regarded as transition among nodes. For defensive works, it builds the Monte Carlo tree model. It utilizes polar coordinates system to make region segmentation, also makes combination of Q learning and Upper Confidence Bound Apply to Tree of Monte Carlo exploring method to train the team players. While using the evaluated value of the training results as optimizedcompetition codes, and team’s defensive ability has been improved enormously in this way.
robocup2D simulation; Monte Carlo tree search; Q-learning; action selection
TP391
A
10.19358/j.issn.1674- 7720.2017.23.015
柴伟凡,梁志伟,夏晨曦.基于蒙特卡洛树搜索的仿真足球防守策略研究[J].微型机与应用,2017,36(23):50-53,57.
江苏省自然科学基金(BK2012832)
2017-05-01)
柴伟凡(1991-),通信作者,男,硕士,主要研究方向:智能机器人理论与技术。E-mail:chaiwb911@sina.com。
梁志伟(1980-),男,博士,副教授,主要研究方向:智能机器人理论与技术。
夏晨曦(1995-),男,学士,主要研究方向:信息安全。
