基于减少过估计的改进LDPC码最小和译码算法*
2017-12-18杨卫国
杨卫国
(海军航空大学, 山东 烟台 264001)
基于减少过估计的改进LDPC码最小和译码算法*
杨卫国
(海军航空大学, 山东 烟台 264001)
为了更好地在LDPC码的译码中使用最小和算法,尽量减少最小和算法译码过程中的性能损失,对最小和译码算法进行了深入研究,通过对最小和算法的原理分析得出,其性能损失的根源是算法过程中产生了过估计,而过估计的大小与最小值和次小值之间的差值相关,基于此,提出了一种减少过估计,以提高最小和算法性能的改进译码算法,通过仿真分析,该算法在几乎不增加复杂度的情况下获得了较好的译码性能。
LDPC码; 最小和算法; 过估计; 最小值; 次小值
低密度奇偶校验码(Low-Density Parity-Check Codes)是一类性能接近香农极限的线性纠错码,由于其拥有优于Turbo码的良好性能,使得LDPC码在目前许多通信系统中得以应用,并在去年被国际移动通信标准化组织确定为5G数据信道编码方案。当LDPC码的码长趋于无限长且校验矩阵对应的Tanner图中无环时,置信传播(Belief Propagation,BP)译码算法是其最优迭代译码算法。BP译码算法虽然性能优异,但算法本身需要大量的乘法运算,计算复杂度较高,硬件实现困难,这也是Gallager在提出LDPC码初期不被人们认可的主要原因之一。后来人们提出了对数域BP译码算法,将原算法中大量的乘法运算变成了加法运算,大大降低了运算量的同时引入了双曲正切函数,工程实践中仍然难于实现,直到1999年Fossorier等学者提出了最小和(Min Sum,MS)译码算法,较好地平衡了译码性能和译码复杂度之间的矛盾,使硬件实现变得简单。之后又出现了一系列改进的MS算法,都是基于缩小MS算法与BP算法之间的性能差距。
1 最小和(MS)译码算法
1.1 对数域BP译码算法
最小和译码算法是基于对数域BP译码算法提出的,对数域BP译码算法是将概率域BP译码算法传递的概率信息变换为对数似然比信息,这样可以将大量的乘法运算变为加法运算,降低译码复杂度,减少运算时间,具体的LLR-BP译码算法如下:
首先定义对数似然比,对二元LDPC码,其接收信号对数似然比的表达式为

(1)
据此,将概率域BP译码算法的步骤转换到对数域得:
1)初始化:根据来自信道的码字信息y=(y1,y2,…yn),初始化所有变量节点信息
L(0)(qij)=L(yi),i=1,2,…,n
(2)
2)校验节点更新:根据式(3),对在第l次迭代时的校验节点信息进行更新。
(3)
3)变量节点更新:根据式(4),对在第l次迭代时的校验节点信息进行更新。
(4)
4)译码判决
计算所有变量节点的判决消息
(5)

1.2 最小和译码算法
前文提到,LLR-BP译码算法一定程度上降低了译码复杂度,当引入了双曲正切函数,实际应用中计算量仍然比较大,Fossorier等人根据双曲正切函数的特点,将概率域BP译码算法中的校验节点更新规则式(3)改写为式(6),其中复杂的乘除运算就可以简化为加法运算和比较运算,大幅度降低了译码复杂度。
(6)
1.3 改进的MS译码算法


(7)
在式(6)中加入加性因子β(β>0),即得偏置最小和(OMS)译码算法:

(8)
两种算法均在几乎不增加MS算法复杂度的情况下,一定程度地改善了译码性能。
2 本文的改进最小和译码算法
通过对上述两种改进MS算法的分析,MS译码算法是将LLR-BP译码算法中校验节点的更新值进行了过估计,即
(9)
2.1 影响MS译码算法性能的主要因素
由于MS译码算法是对LLR-BP译码算法中校验节点输出消息可靠度的过估计,不妨直接用计算机求出两种译码算法中校验节点的输出消息,观察影响MS译码算法估计值的因素。
例假设某校验节点c1的输入信息为(0.7,8.5,5.1,2.3)(由于只讨论两种算法数值之间的差距,故全部取正值),分别对应变量节点v1,v2,v3和v4,则两种算法对应的变量节点的输入信息如表1所示。
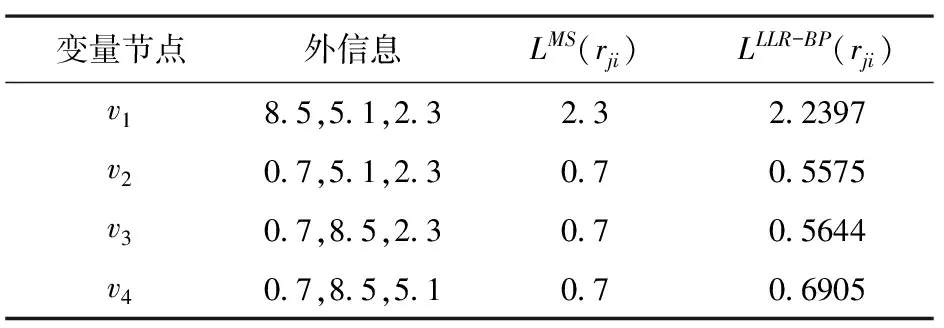
表1 两种算法数值比较
通过观察表1后三行不难发现,MS算法取值不变,但LLR-BP算法取值变化范围较大,变量节点v2和v3对应的值几乎相等,与最小值之间的差距超过了0.1,而变量节点v4对应的值几乎与最小值相等,相差不到0.01。三组数据最大的不同在于最小值与次小值之间的距离,不妨大胆猜测:影响MS译码算法估计值与真实值之间差距的主要因素是最小值与次小值之间的距离,距离越大,估计值越接近真实值。表1变量节点v1对应的值也间接证明了猜测的观点。
证明如下:

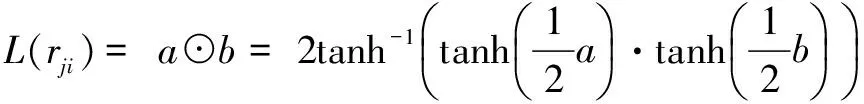
(10)
式中,符号“⊙”表示和积运算,基本关系式如上式所示。
考虑到tanh(a/2)=(ea-1)/(ea+1),


=min(a,b)+f(|a+b|)-f(|a-b|)
(11)
式(11)中,f(x)=ln(1+e-x),代入式(11)后半部分得
f(|a+b|)-f(|a-b|)
=ln(1+e-(a+b))-ln(1+e-(b-a))
(12)
通过图1可以看出,e的对数函数和指数函数均为单调增函数,因此,当a和b均为正数时,式(12)的值为负数,证明了最小和算法是对对数域置信传播算法的过估计。

图1 e的对数函数和指数函数图
继续对式(12)进行分析,当a和b之间的距离逐渐增大到无穷大时,即b-a⟹∞,此时-(b-a)⟹-∞,-(a+b)⟹-∞,则e-(b-a)=0,e-(a+b)=0,式(12)等于0,估计值与实际值相等;当a和b之间的距离逐渐缩小到无穷小时,即b-a⟹0,此时-(a+b)⟹-2a,式(12)转化为ln(1+e-2a)-ln2,因为ln2>ln(1+e-2a)>0,因此估计值与实际值之间的差值不会超过ln2=0.6931,当最小值a较大时,基本可以忽略不计,而当a较小时,这个差值的影响就会比较明显。
由此可得,影响MS译码算法估计值与真实值之间差距的主要因素是最小值与次小值之间的距离以及最小值a的大小。此外,当最小值与次小值之间的距离较小,且各值之间的方差较小时,对估计值也有一定的影响。
2.2 改进算法
根据前文提到的理论,MS译码算法其他步骤不变,校验节点更新规则如下:
1)首先将校验节点cj的外置信消息的绝对值|L(qij)|,按照从小到大的顺序进行排序,并确定门限值d;
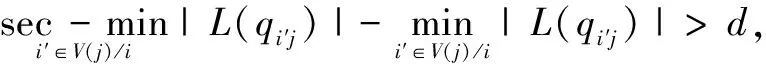
(13)

改进后的最小和算法流程图如图2所示。
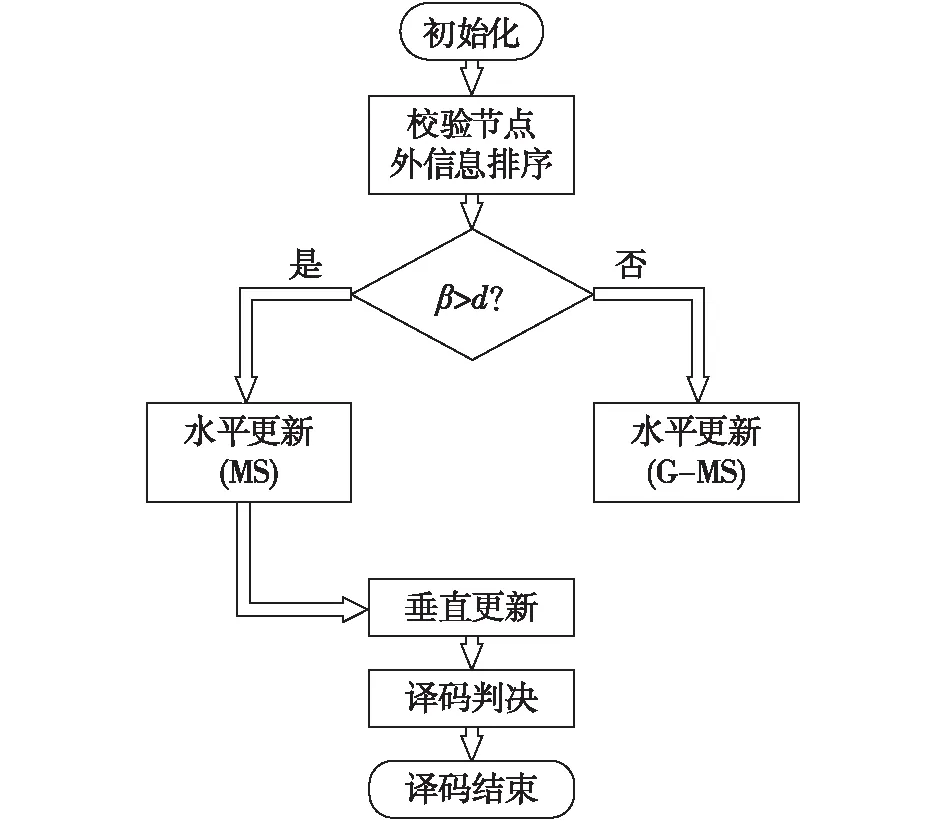
图2 改进MS译码算法流程图
从图2中可以看出,改进后的MS算法只是在原有的MS算法基础上增加了排序和判断两个步骤,新的水平更新规则在每次迭代过程中增加了一次减法运算和乘法运算,算法复杂度基本没有改变。
3 仿真分析
任意选取几组数字,按照式(13)的更新规则进行的估计值与实际值之间的差距如表2所示,根据前文的分析,当β最大时,取α+β/10=1,因此门限值d的取值为d=(1-ln2)*10≈3。
通过观察表中数字不难发现,本文提出的G-MS算法的估计值比MS算法更接近LLR-BP算法的真实值,且在β趋于3时,MS算法的估计值与LLR-BP算法的真实值之间的差距已经基本可以忽略,说明门限值d的取值也是合理的。
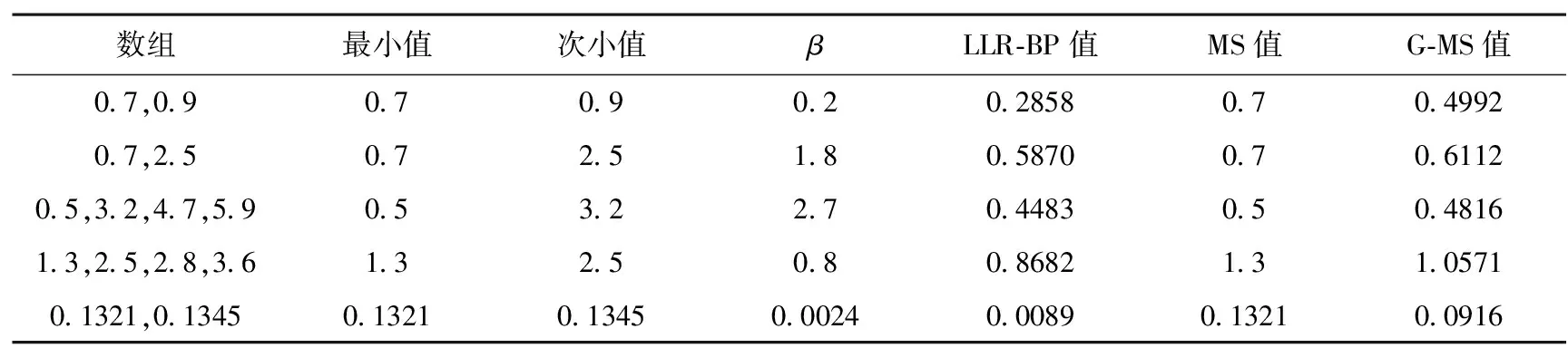
表2 两种算法估计值与真实值
分别取码长为114,570和1710的三种码进行性能仿真,码率均为1/2,采用BPSK调制,传输信道选用高斯信道,采用本文提出的译码算法(G-MS算法)进行译码仿真,迭代次数为10次,仿真结果如图3所示。
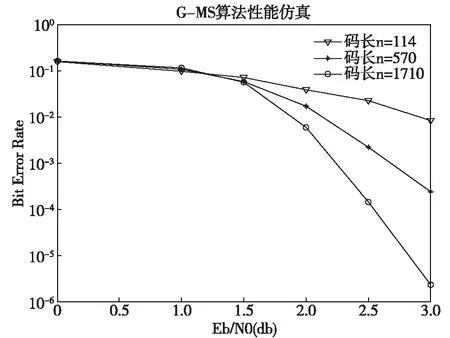
图3 G-MS算法译码性能仿真
从图3中可以看出,无论是短码还是长码,三种码在使用本文所提出的译码算法的情况下,均有较好的译码性能,当码长达到1710,在仅迭代10次的情况下,信噪比为3时的误码率已经达到了10-6数量级,译码性能比较优异。
同等仿真条件下,对MS算法和本文提出译码算法进行性能仿真,选取码长为512的中短码,仍然采用BPSK调制,传输信道为高斯信道,图4所示为迭代10次的译码性能仿真。
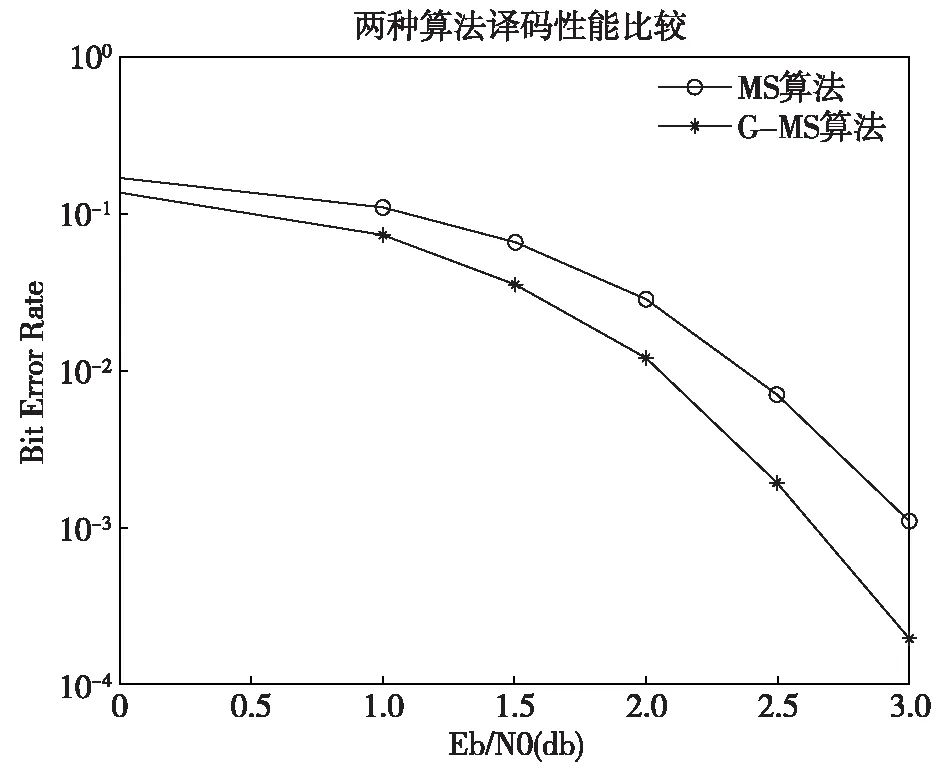
图4 MS算法与G-MS算法性能仿真
由于对MS算法中产生的过估计进行了削弱,G-MS算法相比于传统的MS算法更接近于LLR-BP译码算法的真实值,从仿真图4中可以清楚地看出,本文所提出的译码算法在译码性能上比MS算法有较大的提高,在误码率为10-3数量级时,有接近0.4dB的性能增益。
将本文提出的改进型译码算法同LLR-BP译码算法进行性能比较,码字仍然选取1/2码率,码长为512的码。采用BPSK调制,传输信道为高斯信道,迭代次数为10次,仿真结果如图5。

图5 LLR-BP算法与G-MS算法性能比较
从图5中可以看出,在误码率小于1时,两种算法的性能几乎一致,随着信噪比的增大,LLR-BP算法的性能稍好于G-MS算法,当信噪比达到3dB时,本文提出的G-MS算法已经有了超过LLR-BP译码算法的译码性能。
为了更好地观察本文提出的译码算法的性能,分别采用LLR-BP译码算法、MS译码算法、NMS译码算法、OMS译码算法和本文提出的改进MS译码算法(G-MS译码算法)对码长为1024,码率为1/2的码进行译码仿真,同样采用BPSK调制,传输信道选用高斯信道,迭代次数为10次,其中NMS译码算法修正因子取α=0.8,OMS译码算法修正因子取β=0.2,仿真结果如图6所示。

图6 不同译码算法性能对比
从图6中可以看出,低信噪比时,本文提出的G-MS算法的译码性能与LLR-BP译码算法和NMS译码算法性能接近,在信噪比达到3dB时,G-MS算法的误码率已经优于其他两种算法,且由于NMS算法对于不同码字、不同信噪比条件下的不同α值,译码性能会有不同的表现,因此其稳定性不及本文提出的译码算法;与OMS算法相比,本文提出的译码算法的误码率明显优于OMS算法的误码率。
4 结束语
本文通过对MS算法的原理分析,针对MS算法中对LLR-BP译码算法校验节点更新规则的过估计,提出了改进型MS译码算法,改进后的译码算法在算法复杂度上并没有太大增加,且通过仿真分析不难看出,本文所提出的译码算法,在误码率上与LLR-BP译码算法并没有太大差距,甚至在大信噪比条件下有优于LLR-BP译码算法的性能,与传统MS译码算法和几种改进算法相比在性能上都有一定的优势,且不需要根据码字性能和信噪比调整修正因子,稳定性较好,很好地做到了译码复杂度与译码性能的平衡。
[1] Gallager R.Low-density parity-check codes[J].Information Theory,IRE Transactions on Information Theory,1962,8(1):21-28.
[2] MacKay D J C.Good error-correcting codes based on very sparse matrices[J].IEEE Transactions on Information Theory,1999,45(2):399-431.
[3] Ma Ke-xiang,Zhang Peng.Low-Delay Loop Detection Algorithm for LDPC Codes[J].Journal of CAEIT,2015,4(2):341-349.
[4] 李化营,王健,刘焱.LDPC码改进高速译码算法[J].遥测遥控,2015,36(2):47-53.
[5] Fossorier M P C.Quasi-cyclic low-density parity-check codes from circulant permutation matrices[J].IEEE Transactions on Information Theory,2004,50(8):1788-1793.
[6] Tanner R M,Sridhara D,Sridharan A,et al.LDPC block and convolutional codes Based on circulant matrices[J].IEEE Transactions on Information Theory,2004,50(12):2966-2984.
[7] Gallager R G.Low-Density Parity-Check Codes[D].Cambridge,M A:MIT Press,1963.
[8] Chen X, Kang J, Lin S,et al.Memory System Optimization for FPGA-Based Implementation of Quasi-Cyclic LDPC Codes Decoders[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2011,58(1):98-111.
[9] 张立军,刘明华,卢萌.低密度奇偶校验码加权大数逻辑译码研究[J].西安交通大学学报,2013,47(4):35-38,50.
[10] Kumar,Pravin R.An efficient methodology for parallel concatenation of LDPC codes with reduced complexity and decoding delay[C]∥2013 National Conference on Rakhesh Singh Communications(NCC),2013.
[11] 黄胜,穆攀,贾雪婷,等.基于BIBD与基区组元素组合的QC-LDPC码[J].华中科技大学学报(自然科学版),2016,44(9):16-19.
Modified LDPC Codes Min-sum Algorithm Based on Reducing the Over-estimation
YANG Wei-guo
(Navy Aeronautics University,Yantai 264001,China)
In order to reduce the loss so that we can make full use of the min-sum algorithm in LDPC codes decoding, this paper deeply researches in the min-sum algorithm. The analysis of the min-sum algorithm’s principle comes to that it is the over-estimation which is related to the difference of the minimum value and the second minimum value that leads to the loss. Thus, this paper proposes a modified min-sum algorithm by reducing the over-estimation.Simulations show that this algorithm is better than the traditional MS algorithm without increasing complexity.
LDPC codes; min-sum algorithm; over-estimation; minimum value; second minimum value
1673-3819(2017)06-0053-05
TN911.22;E917
A
10.3969/j.issn.1673-3819.2017.06.012
2017-08-20
2017-09-18
国家自然科学基金资助项目(61671463)
杨卫国(1987-),男,山东烟台人,硕士研究生,研究方向为信道编码。
