基于HMM与词典的汉维词对齐研究
2017-12-18李萍杨勇任鸽赛买提艾力
李萍,杨勇,任鸽,赛买提·艾力
(新疆师范大学计算机科学技术学院,乌鲁木齐 830054)
基于HMM与词典的汉维词对齐研究
李萍,杨勇,任鸽,赛买提·艾力
(新疆师范大学计算机科学技术学院,乌鲁木齐 830054)
词对齐被广泛的用于基于短语的统计机器翻译中,词对齐效果的好坏直接影响了机器翻译的质量。提出将隐马尔科夫模型用于汉维词对齐时,由于汉维双语标记的数据量比较大而且标记数据也还没有公开,导致汉维词对齐的质量较差,也没有办法进行评价,提出采用基于词典的方法进行对齐评价,实现汉维双语词典的构建系统,实验表明,该方法的效果较好,并同时构建汉维双语语料库。
隐马尔科夫模型;词对齐;词典;语料库
0 引言
在统计机器翻译中,词对齐是一个重要的组成部分。在词对齐的研究中,经典的非监督词对齐方法主要是基于IBM模型1-IBM模型5[1]词对齐方法和基于HMM模型的词对齐方法[2]。这六种模型可以将他们分类,IBM1、IBM2和HMM分为一类,这类模型比较容易处理和实现,IBM模型3、IBM模型4和IBM5分为一类,这类模型不容易处理,但是准确性更高。GIZA++软件工具将这两种模型都进行了实现,因此很多的研究者都使用GIZA++来进行词对齐,本文也将使用此工具进行汉维词对齐的实验。
在IBM5模型和HMM模型基础上,对词对齐的研究,很多的学者也提出了一些其他方法,文献[3]没有采用统计的方法,而是考虑将语言学知识融入词对齐过程中,语言学知识包括语义、词性等,初步的对齐是在基于词典的方法上,这种方法需要计算双语词语的语义相似度;文献[4]提出了基于锚点词对的词对齐方法,这种方法独立于前六种模型,实现较简单,但其依赖于词典,在初步对齐时,如果词典的数量不够,则对齐就比较粗糙;文献[5]提出了加权二部图的汉日词对齐方法,此方法也是在基于词典的基础上,首先根据双语词典判断双语是否对齐,在不对齐的情况下,再根据相似性、词性等特征来计算两个词语的相似性,从而判断是否对齐;文献[6]为了提高汉维之间的词对齐质量,提出了对维吾尔语进行形态分析,将词干和词缀进行分离。
这些方法中有些未考虑到未登录词的情况,有的比较依赖于双语词典,对词典的构建要求较高,将维吾尔语词干和词缀进行分离后,对齐的效果不是特别明显,而且增加了对齐的负责性,对于对齐后词典的再次构建也不是很有利,另外有些方法没有解决词语之间的一对多或多对多的情况。
鉴于汉语维吾尔语关于词对齐之间的标记语料较少的情况,本文提出了将HMM模型应用于汉维词对齐中,对于对齐后的评价采用基于词典的方式进行评价,对于词对齐后的结果,再次修改双语词典,使得双语词典更丰富。
1 基于HMM的词对齐
1.1 HMM 模型介绍
隐马尔科夫模型由一个五元组构成:

其中S为状态的集合,K为输出符号的集合,π,A,B分别为初始状态的概率分布,状态转移概率,符号发射概率[7]。
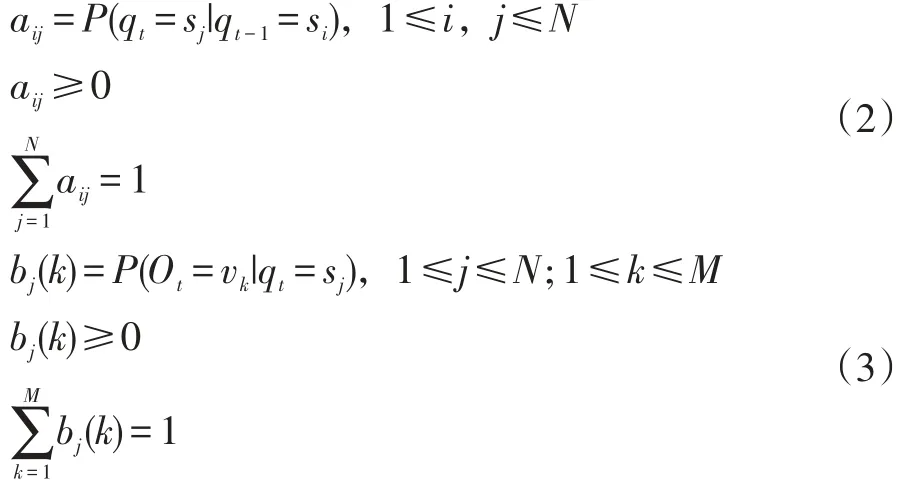
在词对齐问题中,源语言为隐马尔科夫模型中观察符号,目标语言为状态,对齐位置a为内部状态序列。其中隐马尔科夫模型的初始状态概率,状态转换概率和符号发射概率都可以通过HMM的参数估计得到。
1.2 HMM的参数估计
在进行词对齐时,首先需要对隐马尔科夫模型进行参数估计,这里采用期望最大化方法EM进行参数估计,具体实现EM方法时,采用前向后向算法。
在t时刻位于状态si,在t+1时刻位于状态sj的概率:


模型 μ的参数可以采用下面三个公式循环估计,直到所有的参数收敛为止:
在时间t位于状态si的概率为:
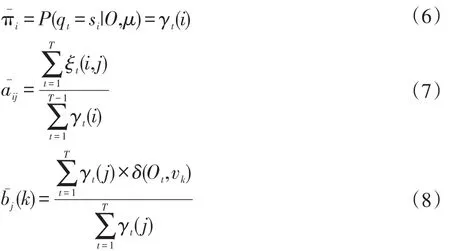
1.3 维特比算法
通过隐马尔科夫模型的参数估计运算,得到模型,然后根据源语言即观察序列和模型,使用维特比算法得到最佳的解释序列,即最佳的内部状态,内部状态序列即为对齐位置a。
2 双语词典的自动化构建
由于汉维语料较少,人工标注工作量大,公开的汉维双语词典更少,为了汉维的自动化翻译,汉维双语词典的构建尤其重要,本文利用基于HMM的词对齐方法,将对齐的结果与已有的词典进行相似度计算,反过来作用于双语词典,让双语词典更丰富。为了构建初步的双语词典,利用互联网上的双语词典检索系统,构建本地双语词典库。
本地双语词典检索系统截图:

图1 汉维双语词典检索系统
目前已经构建了农业领域的3万个汉维双语词典,如图2所示,构建了以大连理工大学信息检索实验室的情感词为基础,构建了3万个汉维双语情感词词典,如图3所示。

图2 农业领域的双语词典
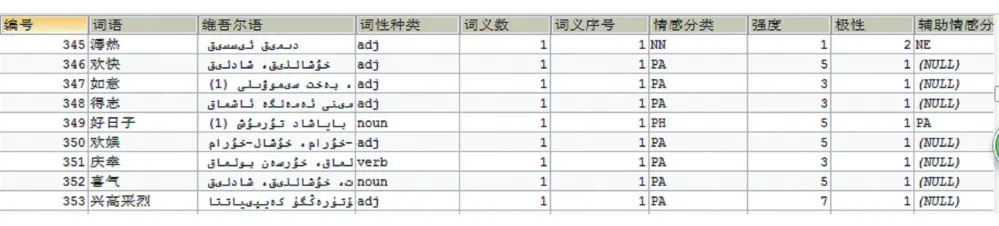
图3 情感词双语词典
本地汉维双语词典自动化构建算法描述:
步骤1:从汉维双语检索系统的首页获取查询词或词对齐结果。
步骤2:与词典里的数据进行匹配,若匹配成功,将对应的维语显示在系统上,词典查询结束。若匹配失败,进入步骤3。
步骤3:根据查询词从网站izda上抓取网页数据。
步骤4:网页数据预处理,并且使用正则表达式匹配对应的汉维双语。
步骤5:将获取到的汉维双语存入到汉维双语词典库中,并将结果显示在汉维双语检索系统中。
3 实验
3.1 词对齐评价模型
目前词对齐的评价主要是三方面的,一个是召回率prec,一个是准确率rec,还有一个是对齐错误率AER[8-9]。本文根据对齐的结果和已构建的词典,将对齐的结果与词典里的词动态比较,判断其正确性,将词语入库,重新构建词典,同时得到维吾尔语的词缀,以便于后续研究。
3.2 汉维词对齐实验
本文采用giza++来进行汉维词对齐,进行词对齐之前,先获取汉维双语平行语料,部分平行语料如表1所示:
在词对齐之前,需要对汉语进行分词,分词后的结果如表2所示:

表2
词对齐结果如下图所示:

图4 词对齐结果
4 结语
本文采用基于HMM的汉维词对齐方法,对平行语料进行汉维词对齐,将对齐的结果存入词典中,并且在没有标注语料的情况下,通过相似性比较,来对词对齐结果的正确性进行判断,最后得到汉维双语词典,构建和实现了汉维双语词典,为以后的研究提供语料基础。本文在一些方面还存在不足,例如对齐的质量方面,对齐的质量也会影响词典的质量,词典和对齐的结果互相依赖,在以后的研究中还有待提高。
[1]F Brown,Peter&Della Pietra,Stephen&Della J Pietra,Vincent&Mercer,Robert.(1993).The Mathematics of Statistical Machine Translation:Parameter Estimation.Computational Linguistics.19.263-311.
[2]Vogel S,Ney H,Tillmann C.HMM-Based Word Alignment in Statistical Translation[C].Conference on Computational Linguistics.DBLP,1996:836-841.
[3]晋薇,黄河燕,夏云庆.基于语义相似度并运用语言学知识进行双语语句词对齐[J].计算机科学,2002(11):44-47.
[4]张孝飞,陈肇雄,黄河燕,王建德.基于锚点词对的双语词对齐算法[J].小型微型计算机系统,2006(02):330-334.
[5]吴宏林,刘绍明,于戈.基于加权二部图的汉日词对齐[J].中文信息学报,2007(05):101-106.
[6]麦热哈巴·艾力,王志洋,吐尔根·依布拉音.一种提高维吾尔语-汉语词语对齐的方法研究[J].小型微型计算机系统,2012,33.(11):2551-2555.
[7]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013:110-111.
[8]Och F J,Ney H.Improved Statistical Alignment Models[C].Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2000:440-447.
[9]黄书剑,奚宁,赵迎功,戴新宇,陈家骏.一种错误敏感的词对齐评价方法[J].中文信息学报,2009,23(03):88-94.
Research on Chinese-Uyghur Word Alignment Based on HMM and Lexicon
LI Ping,YANG Yong,SAI Mai Ti·Ai Li,REN Ge
(College of Computer Science and Technology,Xinjiang Normal University,Urumqi 830054)
Word alignment is widely used in statistical machine translation phrase based on phrase.The effect of word alignment directly affects the quality of machine translation.Puts forward using a hidden Markov model for Chinese-Uyghur word alignment,because of the large amount of bilingual marker data and the lack of labeled data,resulting in poor quality of Chinese Uyghur word alignment,there is no way to evaluate.Puts forward the evaluation method based on the alignment dictionary and constructs a bilingual dictionary system.The experiment shows that the effect is good and the Chinese Uighur bilingual corpus is constructed.
Hidden Markov Model;Word Alignment;Lexicon;Corpus
新疆师范大学优秀青年教师科研启动基金项目(No.XJNU201420)
1007-1423(2017)31-0007-04
10.3969/j.issn.1007-1423.2017.31.002
李萍(1989-),女,湖南株洲人,硕士,讲师,研究方向为自然语言处理、机器学习
杨勇(1979-),男,陕西汉中人,副教授,博士,研究方向为自然语言处理
赛买提·艾力(1983-),男,新疆乌鲁木齐人,讲师,硕士,研究方向为自然语言处理
任鸽(19-),女,新疆乌鲁木齐人,讲师,硕士,研究方向为自然语言处理
2017-10-20
2017-11-03
