基于深度学习的CPU实时动物目标检测
2017-12-18高志华
高志华
(四川大学计算机学院,成都 610065)
基于深度学习的CPU实时动物目标检测
高志华
(四川大学计算机学院,成都 610065)
随着深度学习的发展,目标检测技术得到很大的发展,在很多领域都得到了广泛应用;如行人检测、车辆检测等;动物检测同样是非常重要的一个应用领域;作出两点贡献,第一,创建一个包含6834张高清图像11个不同类别动物目标检测数据库;第二,在one-stage目标检测框架的基础上构建基础网络MiniNet,针对动物目标得出卓越的检测性能;并使该目标检测框架CPU实时,在Intel i5四核主频2.7GHz处理器上达到100ms每帧。
深度学习;实时目标检测;动物检测
0 引言
近年来,许多组织和政府在基础设施中投入大量的资金来保护各种动物物种;建设新的道路等设施人为地干预了动物的迁徙等行为,所以利用计算机视觉进行动物检测具有重要的研究意义,可以用来检测动物的运动,提供指定区域的野生动物的迁徙数据。
目前基于深度学习目标检测框架主要分为twostage和one-stage方法。two-stage方法如Selective Search work[6],第一阶段产生一组稀疏的候选目标区域集合,该集合包含了所有的目标对象,同时过滤掉大部分负样本区域;第二阶段对候选区域进行前景、背景的分类。R-CNN[7]则将第二阶段的分类器升级为卷积神经网络,在准确性上获得了极大的收益,开创了现代的目标检测时代;多年来,R-CNN在速度[8-9]以及产生候选窗口算法[2,10-11]上有都有很大的提升,区域建议网络(RPN)将第二阶段分类器集成到一个卷积神经网络中,形成了更快的R-CNN框架[2]。two-stage算法拥有很高的准确性,但是速度上很难达到实时;OverFeat[12]是最早的基于深度学习的one-stage框架,最近的算法如SSD[1]和YOLO[4]重新关注了该方法;这类算法在速度上有很大优势,但在准确性上却逊于two-stage算法;SSD的准确性降低了10-20%,而YOLO则关注更加极端的速度/准确性的折衷;Focal Loss[13]指出onestage算法准确性不足的主要原因是正负样本分布不均衡造成的,简单样本数量太多,困难样本没有得到充分的训练,通过在交叉熵损失函数前乘以因子(1-pt)γ使得one-stage算法的检测准确性达到了two-stage的效果同时速度上的优势保持不变;本文采取one-stage方法结合Focal Loss的思想在本文构建的的数据库中取得卓越的性能。
1 数据库
本文创建了一个拥有6834张带标签的高分辨率图像的数据集,分属于11个类别;分别是猫、鹿、狗、豹子、蜥蜴、猴子、熊猫、兔子、羊、蛇、松鼠;这些图像是从网上收集,进行人工贴标签。在每个类别中随机选取20%作为测试集;图片的标注信息包含目标的位置左上角(xl,yl)坐标和右下角坐标(xryr)以及数字表示的类别信息;在该数据集上我们使用mean Average Precision(mAP)的目标检测评价指标,部分图片如图1所示。
2 MiniNet网络设计细节
大多数基于CNN的目标检测框架都被巨大的计算量限制着,尤其是在CPU设备;尤其是卷积操作在输入图像的尺寸,卷积核的尺寸以及输出的通道数都很大时更是极其耗时;为了解决这个问题,本文提出的MiniNet通过精心设计的网络结构,快速地降低输入图片的维度,使用合适的卷积核尺寸和少量的通道数使该网络结构达到CPU实时的效果,该框架具体分为两个部分;第一部分为基础网络主要用于提取图片全局特征,后半部分是分类、回归网络用于得到目标的置信度以及目标的坐标;具体设计细节如下:
(1)输入图片降维:为了快速降低输入图片的维度,MiniNet设计上对卷积层和采样层采用了一系列很大步长;如图二所示,Conv1,Pool1,Conv2 和 Pool2 的步长分别设置为4,2,2和2;总共的步长为32,意味着输入图片的维度可以快速的降低32倍。
(2)选择合适的卷积核尺寸:前面几层的卷积核尺寸应该尽可能的小以保证速度的提升,同时应该足够大保证输入图片为度降低时信息的损失;如图二所示,为了同时保证效率和精度,对Conv1,Conv2和所有的Pool层分别使用 7×7,5×5 以及 3×3 的尺寸。
(3)降低输出通道的数量:本文使用C.ReLU激活函数降低输出的通道的数量;C.ReLU[14]的动机在于观察到CNN底层的滤波器常以成对的形式出现,例如以相反的状态;通过这样的观察,C.ReLU可以加倍输出通道的数量通过简单的连接负状态的输出,使用C.Re-LU显著地增加了速度,精度的下降可以忽略不计。

图1

图2
3 训练
损失函数包含两个部分:置信度损失函数以及位置损失函数,将它们按权重相加起来就是总的损失函数;公式如下:

其中N是与真实窗口匹配的候选窗口的数量,如果N等于 0,那么损失也为0;位置损失函数为Smooth L1损失函数;它计算候选窗口(l)和真实窗口(g)之间距离;用xkij={1,0}表示第i个首选窗口是否匹配第j个真是窗口,且类别为k;
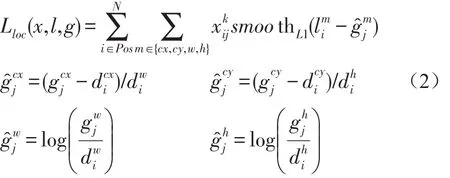
置信度损失函数采用focal loss损失函数,它由两部分组成,(1-pt)γ为调节因子,Lconf(x,c)为交叉熵损失函数;

α是权重系数,本文设置为1;调节因子γ取2。
4 学习详细过程
使用随机梯度下降法并且batchsize大小为32、动力为0.9、权重衰减为0.0005的超参数来训练网络;其中少量的权重衰减对于模型学习是重要的;这里的权重衰减不仅仅是一个正则化矩阵,它减少了训练误差;对于权重w的更新规则为:

wi+1:=wi+vi+1
使用均值为0、标准差为0.01的高斯分布初始化了每一层的权重;对于所有层都使用了相等的学习率,学习率在训练过程中可以调整,当训练误差不在下降时就将学习率除以10;学习率初始化为0.01;我训练该网络时候大致将该5462张训练数据集循环了235次;其中batchsize为32,最大迭代次数为80000次,在两块GPU分别为NVIDAI GTX 980Ti 4GB和NVIDAI GTX 960 4GB上花费时间为两天;
5 实验
我们针对该数据集分别对比了MiniNet、VGG-16Net、ZF-Net、ResNet-101 等基础网络的效果;实验结果总结与表1当中。
由上图可以看出本文提出的MiniNet对比其他现有网络在本文创建的数据库中取得了最好的效果;速度方面MiniNet的精巧设计可以在CPU上达到100ms每帧,精度上比略微高于ResNet101,这主要是因为MiniNet的输入图片的尺寸很大,而针对于该数据集存在着不少的小目标,MiniNet的网络设计上适合小目标比较多的情况。
6 结语
当前的目标检测模型在计算上令人望而却步,CPU设备实现实时的速度以及保持高性能是很困难的。本文提出了一种新颖的动物检测器,具备出色的性能,在准确性以及速度上兼具优势;提出的轻量级的网络结构由基础网络以及回归+分类两部分组成,结合Focal Loss的思想在本文提出的数据库上取得了优越的性能;改检测器速度非常快,在Intel i5四核主频2.7GHz处理器上达到100ms每帧。

表1
[1]W.Liu,D.Anguelov,D.Erhan,S.Christian,S.Reed,C.-Y.Fu,and A.C.Berg.SSD:Single Shot Multibox Detector.In ECCV,2016.
[2]Ren,S.,He,K.,Girshick,R.,Sun,J.:Faster R-CNN:Towards Real-time Object Detection with Region Proposal Networks.In:NIPS.2015.
[3]He,K.,Zhang,X.,Ren,S.,Sun,J.:Deep Residual Learning for Image Recognition.In:CVPR.2016.
[4]Redmon,J.,Divvala,S.,Girshick,R.,Farhadi,A.:You only look once:Unified,Real-time Object Detection.In:CVPR.(2016)
[5]Girshick,R.:Fast R-CNN.In:ICCV.2015.
[6]J.R.Uijlings,K.E.van de Sande,T.Gevers,and A.W.Smeulders.Selective Search for Object Recognition.IJCV,2013.
[7]R.Girshick,J.Donahue,T.Darrell,and J.Malik.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation.In CVPR,2014.
[8]K.He,X.Zhang,S.Ren,and J.Sun.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.In ECCV.2014.
[9]R.Girshick.Fast R-CNN.In ICCV,2015.
[10]D.Erhan,C.Szegedy,A.Toshev,and D.Anguelov.Scalable Object Detection Using Deep Neural Networks.In CVPR,2014.
[11]P.O.Pinheiro,R.Collobert,and P.Dollar.Learning to Segment Object Candidates.In NIPS,2015.
[12]P.Sermanet,D.Eigen,X.Zhang,M.Mathieu,R.Fergus,and Y.LeCun.Overfeat:Integrated Recognition,Localization and Detection using Convolutional Networks.In ICLR,2014.
[13]Lin T Y,Goyal P,Girshick R,et al.Focal Loss for Dense Object Detection[J].arXiv preprint arXiv:1708.02002,2017.
[14]W.Shang,K.Sohn,D.Almeida,and H.Lee.Understanding and Improving Convolutional Neural Networks Via Concate-Nated Rectified Linear Units.In ICML,2016.
CPU Real Time Animal Detection Based on Deep Learning
GAO Zhi-hua
(College of Computer Science,Sichuan University,Chengdu 610065)
With the development of deep learning,the object detection technology has been greatly developed in many areas and has been widely used,such as pedestrian detection,vehicle detection;Animal detection is also a very important application area.Makes the following two contributions:first,creates a database containing 6834 HD images with 11 different categories of animal.Second,builds the basic network MiniNet on the basis of the one-stage object detection framework and gets excellent performance for animal objects.And makes the object detection framework CPU real time,reaches 100ms per frame in Intel i5 quad-core frequency 2.7GHz processor.
Deep Learning;Real Time Object Detection;Animal Detection
1007-1423(2017)31-0022-04
10.3969/j.issn.1007-1423.2017.31.006
高志华(1991-),男,安徽合肥人,硕士,研究方向为基于深度学习的目标检测
2017-09-22
2017-10-26
