基于科创大数据的系统架构模拟研究∗
2017-12-18黄宏立黄元阔
顾 彬 武 炜 黄宏立 黄元阔
(珠海市生产力促进中心 珠海 519000)
基于科创大数据的系统架构模拟研究∗
顾 彬 武 炜 黄宏立 黄元阔
(珠海市生产力促进中心 珠海 519000)
伴随业内实行创新创业的热潮,构建科创大数据平台成为政府服务机构迫在眉睫的需求。以科技创新作为大数据平台建立的背景,当前业界涌现了各类大数据服务工具用于验证服务性能的优劣。论文以科技创新作为研究背景,设计了一套大数据系统架构模拟平台,按照高性能计算芯片的设计理念,利用队列理论和随机模型相结合,将传统的小时级的数据服务时间降低到分钟级,论文主要介绍了该平台的设计原理以及模拟大数据系统架构的实际过程。
大数据;模拟平台;随机模型;排队论
1 引言
近来,随着国家创新创业热潮的加剧,构建科技创新的大数据平台成为各级政府部门响应国家科技号召、提升科创服务,为创业者提供高效、准确的创业信息。基于科创的越来越多移动应用的出现,基于该应用的大数据中心系统建模成为学者们的研究重点,这是由于基于移动端设备的应用需求远超传统工作站的性能,尽管当前有大量用于详细评估桌面和服务器体系结构组件的工具[1~3],但这些详细的建模工具不太适合研究科创数据中心系统。传统的架构模拟器通常比它们建模的硬件慢六个数量级,并且模拟周转时间随着建模的系统和核心的数量线性地增长。此外,模拟的存储器占用量通常大于模拟工作负载,用这样的工具模拟甚至适度的集群是棘手的。
本文提出了一种用于数据中心系统的仿真基础架构—SmartBig。该架构使用排队理论和随机建模的组合,而不是使用详细的微架构模型来模拟服务器,可以在几分钟而不是几小时内模拟服务器集群服务,利用统计模拟技术将模拟周转时间限制到所需精度所需的最小运行时间。SmartBig基于随机排队模拟(SQS)方法[4~5]。SQS不是像传统的仿真工具[1~3]那样以指令、存储器或磁盘访问的粒度来模拟工作负载,而是建立在排队理论的理论框架上,其中基本工作单元是一个任务(又名工作)。任务的特点是一组统计特性-描述其长度,资源需求,到达分布或其他相关属性的随机变量,通过观察真实系统来收集这些属性。SQS将数据中心抽象为描述软件/硬件组件的相关行为的队列和功率/性能模型的相互关联网络。离散事件模拟使用各种统计采样技术来提供对可选择的输出变量与可量化的置信度测量的估计,同时使得并行仿真能够提供强缩放以减少周转时间。
2 SmartBig介绍
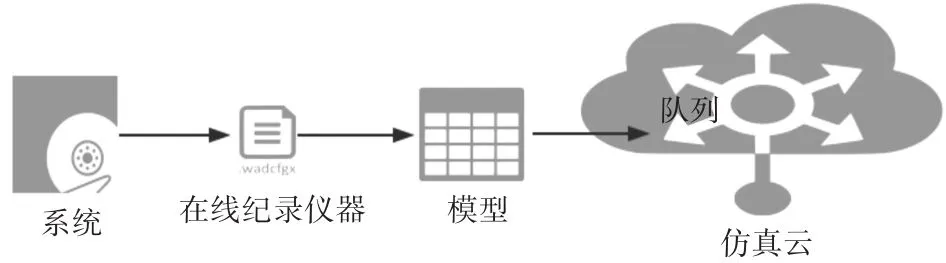
图1 SmartBig使用概述图
在对排队模型的分析中,诸如到达时刻和服务分布的统计被用于计算封闭形式的绩效测量。文献[18]容易分析的排队模型(例如,M/M/1)通常不能代表互联网服务。选择更通用的模型,例如G/G/1或G/G/k队列(广义的到达时间和服务时间分布以及1或k个服务器)没有已知的闭式解决方案。然而,实验证明该队列的精度通常是不足的,相反,使用本文提出的SmartBig,采用模拟分析来练习这些难以处理的模型。虽然这会带来不可忽略的时间,并且集成到框架中可以重复使用的模型。本文,首先描述SmartBig模拟基础的软件架构和细节,以及其使用的一般方法。
SmartBig最适合用于调查负载平衡、电源管理、资源分配、硬件配置或集群,分布式或多层数据中心应用程序的成本优化的研究。在SmartBig中,包括计算集群的许多系统被表示为通用排队网络,由SmartBig用户通过配置文件和简明的Java代码来描述,在队列模型中的任务对应于正在研究的工作负载的最自然的工作单元,例如单个请求,事务,查询等。SmartBig排队网络捕获了处理步骤,通过这些步骤,任务必须以适合于所研究问题的细节水平进行,排队网络中的每个服务器耦合到调制服务速率并生成感兴趣的输出变量(例如,任务执行时间或能量消耗)的功率/性能模型。然后在SmartBig仿真环境中运行该模型,对输出度量进行采样,并在收敛时终止模拟,即每个输出变量已被测量到所需的统计置信水平。如图1所示为SmartBig的使用概述流程,主要包括两个独立的步骤:1)表征工作负载和感兴趣的系统;2)模拟。
1)软件架构
SmartBig的软件架构分为两个主要模块:第一模块用于描述模拟数据中心,包括类似于典型离散事件仿真器的模型和事件的集合,SmartBig使用面向对象的层次结构来表示数据中心的各个部分,例如服务器,机架等。SmartBig用户可以使用这些现有对象来描述特定的数据中心架构,如果需要更多的功能,也可以扩展此层次结构以建模新功能。例如,服务器模型可以被子类化或扩展为包括用于各种ACPI功率模式的状态变量,其调制任务运行时间,控制ACPI状态转换和输出功率/能量估计。配置文件描述了SmartBig如何实例化和连接这些对象并提供诸如核数,峰值功率等参数;第二个模块为协调仿真。此模块包括SmartBig统计软件包,管理预热和统计独立性测试,跟踪指定的输出指标,并在输出指标估计达到统计收敛时终止模拟,它还提供了一个通信和控制基础设施,用于在核心和/或机器集群上分布BigHouse模拟。
2)工作负载和系统表征
应用SmartBig实现特定实验,用户必须重用或创建实现显着工作负载特性和输出度量的模型的系统模型组件。这些模型通常源自实际硬件的特性,表征包括在线和离线组件[6~9]。
SmartBig不是像传统的模拟器那样使用应用程序二进制文件或跟踪,而是将系统中每种任务的到达和服务时间的经验测量分布表示为工作负载。工作负载模型还可以包括其他关键任务参数的分布(例如,如果建模网络链路,则任务的网络业务)。以前的SmartBig用户通过实时系统构建这些经验性工作负载模型。通常,该过程涉及插入二进制,使得记录任务到达的定时及其持续时间。随后,可以处理这些轨迹以导出期望的分布。有必要在实时流量下在线捕获这些工作负载模型,因为进程间很大程度上依赖于互联网服务的用户。SmartBig使用这些分布生成合成事件跟踪来驱动其离散事件模拟。因为它不使用跟踪或二进制,SmartBig工作负载模型可以紧凑地表示—典型的分布占用小于1MB,而事件跟踪通常需要多GB文件。此外,与二进制相反,行业通常不愿传播、公开传播的到达和服务分配显然更容易,因为它们不需要释放专有软件。
如果模拟系统与收集迹线的系统显着不同,则获得统计上严格的性能估计。SmartBig的抽样方法是建立在假设事件序列通过从经验分布中随机抽取而合成生成的。为了对特定系统建模,Smart-Big用户提供简洁的Java代码,跟踪与每个任务处理步骤相关联的状态变量,并生成与每个任务相关联的输出指标。用户提供的代码接受输入任务并计算相应的输出指标,例如,在对多核服务器中的功率管理进行建模的实验中,输入任务的特征可以在于大小,状态变量可以跟踪每个核的ACPI功率状态,而输出度量可以包括消耗的时间和能量。通常,系统模型中描述的输入任务和输出度量之间的关系是从真实系统的离线表征导出的。在模拟过程中,本文提出了系统表征的具体例子,以及如何将这些模型合并到SmartBig中。
3)模拟
SmartBig模拟过程根据工作负载模型合成任务跟踪,并通过分布式离散事件模拟练习用户描述的排队网络和系统模型。SmartBig离散事件模拟的核心功能与用于模拟排队网络的其他工具没有明显不同,该功能根据文献[9]对于排队模型的详细论证得出。SmartBig使用系统模型(例如,上述的多核功率性能模型)和随着模拟进行监测和量化输出度量估计的置信度的采样机制来增加常规排队网络。

图2 模拟过程介绍
1)预热—模拟在初始瞬态状态开始,其中观测值被初始模拟状态偏置(例如,所有队列为空)。为了避免这种冷启动效应,模拟必须经历热身阶段,并且进行周期观察,其中所有观察值被丢弃。当前,业界并没有用于自动检测稳态的严格方法可用,因此预热周期必须由用户明确指定。
2)校准—从离散事件仿真中绘制样本时必须解决的关键挑战之一是确保采样观测值之间的独立性。使用来自基于排队的模拟的连续观察已经显示将偏差引入估计,因为观察往往是自相关的(即附近的观察不是独立的)[10]。这种方法的主要后果是,稳态模拟长度膨胀系数为1。因为每取1次就丢弃1-1个观测值,必须模拟总共N=1·n个事件以实现目标样本大小。在校准阶段,SmartBig执行运行测试,以确定观测值和适当的直方图分档参数之间的滞后间隔,以实现分位数估计。
3)测量—一旦模拟进入稳态,收集观察值用以填充每个输出度量的直方图表示。大多数仿真运行时都花费在这个阶段;其他三个阶段施加了不显着的运行时开销。
4)收敛—一旦观察到的样本大小足以实现期望的置信区间,则认为输出度量收敛。如果样本是使用分布式模拟生成的,则在此时合并。最后,可以报告分位数和平均值的估计。
准确性和可信度。输出度量的估计具有一起形成置信区间的相关联的准确度α和置信水平1-α。з以与输出度量相同的单位(例如,具有±50ms的响应时间)来定义置信区间的半宽度。本文通过平均估计值对这个值进行归一化,以便在多个输出度量之间进行有意义的比较:

在式(1)中,给定E将期望的精度描述为百分比(例如,具有±5%的响应时间)。估计的置信水平描述了如果模拟被重复大量次数将落入置信区间内的估计的预期百分比。95%的置信水平是常见的,在本文的其余部分使用此值。为了确定平均估计值的置信区间(例如,平均响应时间)。根据中心极限定理,当样本量增加时,平均值估计的抽样分布倾向于正态分布。因此,可以通过以下公式确定给定置信度所需的样本大小:

其中 Z1-α表示标准正态:它是在(1-α/2)个分位数处的标准正态分布的值,并且对于95%的置信度是1.96。σ是样本标准偏差,是所需置信区间的半宽度。分位数的置信区间也可以使用中心极限定理[12]来导出。
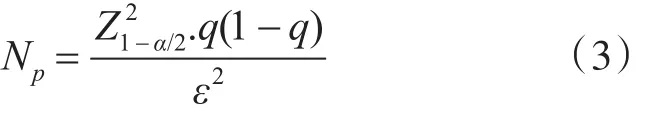
该符号与对于具有添加q作为期望分位数的平均估计相同,为了找到准确的分位数,需要记录和排序样本中的所有观测值。即使单个输出度量所需的样本大小也可能非常大。因此,记录和分类整个样本序列以确定分位数施加了很大的负担。本文使用[11]中提出的方法来保持观察变量的直方图表示,大大减少了内存开销。该方法需要预先确定直方图装箱参数。通常,知道给定输出度量的平均值和至少一个分位数是有用的。在这种情况下,用于所需置信度的所需样本大小将为

3 实验研究
在本节中,使用SmartBig对相关的功能/性能进行实验验证,这些实验已在真实的硬件服务中进行了验证,具体介绍如下:
3.1 GoogleWeb搜索中的资源管理
本文的第一个案例研究取自文献[12],其中SmartBig来了解处理器和内存低功耗模式对Google Web搜索的性能影响。研究的目的是了解如何在Web搜索服务器中实现能量比例操作,同时保持合理的延迟。使用SmartBig能够预测侵入性实验的效果,如更改服务器性能状态。
首先必须为工作负载收集经验到达和服务分布。通过对生产二进制进行跟踪实时流量的到达顺序来获得到达时间分布。为了测量服务时间分布,将查询一次一个地注入到隔离的Web搜索节点中,从而确保在搜索节点内没有排队。因此,可以简单地将查询服务时间测量为查询的完成时间和到达时间之间的差。这些分布都是在大量查询样本上测量的。接下来测量隔离搜索节点的功率—性能行为以构建系统模型。通过离线实验,改变处理器频率和内存延迟,并测量了处理器和内存性能设置空间中每个点的单个查询的平均服务时间。从这些数据,构建了一个SmartBig系统模型,调整服务时间和每个查询的报告功率估计。最后,通过这些表征步骤完成,SmartBig可以用来估计能源管理策略在各种负载下的影响,负载可以通过缩放到达间分布来改变。

图3 验证Google网页搜索的效果
图3 提供了SmartBig模拟结果验证的局部视图。线代表所预测的95百分位数延迟,由SmartBig和点表示来自实际硬件的测量数据。因为实验改变了处理器和内存设置,所以性能设置空间是二维的,该图显示了具有固定存储器性能和可变CPU性能的子集。横轴表示在典型工作范围内变化的利用率(以每秒最大查询或QPS的百分比表示),所有验证点的平均误差为9.2%。
3.2 时间安排
本文的第二个案例研究中,SmartBig用于研究DreamWeaver[12],这是一种调度机制,旨在合并空闲时段,以便在多核服务器中使用空闲低功耗模式。调度机制被设计为尽可能地在所有核上对齐空闲和活动时间,以最大化所有核都是空闲的间隔,并且整个系统可以被置于深度睡眠模式。调度机制的本质是抢占执行,并且如果未完成的任务比核少,则进入深度睡眠。然而,如果任何任务被延迟超过预先指定的阈值,则系统唤醒并且执行恢复,即使一些保持空闲。本质上,该技术按每个请求的延迟交易,以创建深度睡眠的机会,结果如图4所示。
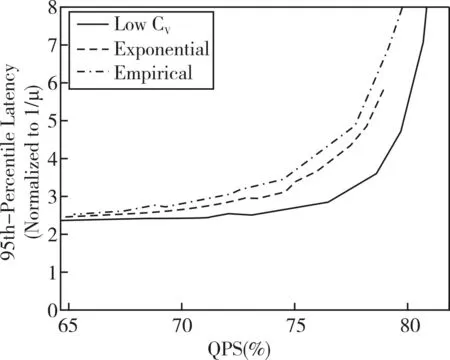
图4 到达间分布对延迟的影响图
使用SmartBig预测此调度机制的有效性,并针对Solr开源Web搜索系统的调度机制的软件实现验证SmartBig预测。Solr是一个功能齐全的网络索引和搜索系统,用于许多企业在其网站中添加本地搜索功能。验证实验使用AOL查询集[14]和维基百科的索引[15]来执行Solr。
4 结语
本文提出了新的大数据系统架构模拟研究系统SmartBig,该系统用于验证数据中心系统的仿真基础架构。通过提高仿真抽象级别,SmartBig可以比传统的微架构模拟器显着更快地建模服务器或集群。通过两个实例完成SmartBig对模型的验证(相比传统的硬件服务),发现系统的准确性是相当好的。
[1]M.M.K.Martin,D.J.Sorin,B.M.Beckmann,M.R.Marty,M.Xu,A.R.Alameldeen,K.E.Moore,M.D.
Hill,and D.A.Wood.Multifacet's general executiondriven multiprocessor simulator(GEMS)toolset[J].ACM SIGARCH Computer Architecture News,2005,33(4):92-99.
[2]D.Wang,B.Ganesh,N.Tuaycharoen,K.Baynes,A.Jaleel,and B.Jacob.DRAMsim:a memory system simulator[J].ACM SIGARCH Computer Architecture News,2005,33(4):100-107.
[3]T.F.Wenisch,R.E.Wunderlich,M.Ferdman,A.Ailamaki,B.Falsafi,and J.C.Hoe.SimFlex:Statistical Sampling of Computer System Simulation[C]//IEEE Micro,2006,26(4):18-31.
[4]D.Meisner,J.Wu,and T.F.Wenisch.Towards a Scalable Data Center-level Evaluation Methodology[C]//In Proc.of the International Symp.on Performance Analysis of Systems and Software,2011:121-122.
[5]D.Meisner and T.F.Wenisch.Stochastic Queuing Simulation for Data Center Workloads[C]//In Exascale Evaluation and Research Techniques Workshop,2010.
[6]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.MEN Xiaofeng,CHI Xiang.Big Data Management:Concepts,Techniques and Challenge[J].Jonrnal of Computer Research and Development,2013,50(1):146-169.
[7]徐庚保,曾莲芝.基于仿真的复杂系统研究[J].计算机仿真,2013,30(2):1-4.XU Y B,ZENG Lianzhi.Simulation-Based Complex System Study[J].Jonrnal of Computer Simulation,2013,30(2):1-4.
[8]胡晓峰.大数据时代对建模仿真的挑战与思考军事运筹与系统工程[J].军事运筹与系统工程,2013,27(4):5-12.HU Xiaofeng.Big data era to the challenge of modeling and simulation with thinking about military strategy and system engineering[J].Military Operations Research and Systems Engineering,2013,27(4):5-12.
[9]M.Harchol-balter.Theory of Performance Modeling,CMU Class Notes,2005.
[10]E.J.Chen and W.D.Kelton.Determining simulation run length with the runs test[J].Simulation Modelling Practice and Theory,2003,11(3-4):237-250.
[11]E.J.Chen and W.D.Kelton.Quantile and histogram estimation[C]//In Proc.of the Winter Simulation Conf.,2001.
[12]D.Meisner,C.M.Sadler,L.A.Barroso,W.-D.Weber,and T.F.Wenisch.Power Management of Online Data-Intensive Services[C]//In Proc.of the 38th International Symp.on Computer Architecture,2011.
[13]D.Meisner and T.F.Wenisch.DreamWeaver:Architectural Support for Deep Sleep[C]//In Proc.of the 17thInternational Conf.on Architectural Support for Programming Languages and Operating Systems,2012,47(4):313-324.
[14]AOL Query Log,2006[OL].http://www.gregsadetsky.com/aol-data/.
[15]Welcome to Solr,2011[OL].http://lucene.apache.org/solr/.
Research on System Simulation Infrastructure Based on KeChuang Big Data
GU BinWU WeiHUANG HongliHUANG Yuankuo
(Zhuhai Productivity Promotion Center,Zhuhai 519000)
With the industry of carrying out the craze of innovation and entrepreneurship,to build a large data platform has become a government service agencies imminent needs.In the background of the establishment of large data platform,scientific and technological innovation,various large data service tools have emerged in the industry to verify the performance of service.In this paper,a large data system architecture simulation platform is designed based on the background of scientific and technological innovation.According to the design concept of high performance computing chip,the queuing theory and stochastic model are combined to reduce the traditional hourly data service time to minutes.The design principles of the platform and simulation of large-scale data system architecture of the actual process simulation are introduces in this paper.
big data,simulation platform,stochastic model,queuing theory
TP393
10.3969/j.issn.1672-9722.2017.11.021
Class Number TP393
