BP神经网络最佳停止法对农机总动力的预测
2017-12-16何志连王福林董慧英王会鹏
何志连,王福林,董慧英,王会鹏
(东北农业大学 工程学院,哈尔滨 150030)
BP神经网络最佳停止法对农机总动力的预测
何志连,王福林,董慧英,王会鹏
(东北农业大学 工程学院,哈尔滨 150030)
在分析和研究了基于神经网络的农机总动力预测的基础上,指出了神经网络传统预测方法预测精度低的原因是神经网络训练阶段和预测阶段的矛盾性。通过一系列实验表明:随着拟合误差的逐渐减小,预测误差出现了先下降后上升的规律,即所谓的“过拟合”问题。为了解决这个问题,应用最佳停止法对农机总动力进行预测,该方法把样本集分成训练样本集、确认样本集及验证样本集3部分。在训练过程中监测训练样本集和确认样本集的误差,当确认样本集的误差连续20次不减小时,退出训练,返回最小确认样本集误差所对应的网络数据,并用验证样本集来检验最佳停止法的预测精度。实验数据表明:最佳停止法避免了网络出现的“过拟合”问题,有效提高了预测精度。最后,用这个训练好的网络模型预测了黑龙江省2015-2020年的农机总动力。
农机总动力;最佳停止法;神经网络;时间序列;过拟合
0 引言
农机总动力(农业机械总动力的简称)指主要用于农、林、牧、渔业的各种动力机械的动力总和, 包括耕作机械、排灌机械、收获机械、农用运输机械、植物保护机械、牧业机械、林业机械、渔业机械和其他农业机械。某地区的农机总动力是衡量该地区农业机械化水平的主要指标,也是该地区政府部门制定农业机械化发展规划及农机生产企业指定产品结构调整方案的重要参考数据[1]。因此,做好农机总动力的预测具有十分重要的意义。目前,关于农机总动力的预测方法主要有线性回归模型、移动平均法、指数平滑法、灰色GM(1,1)模型、龚珀兹曲线、组合预测和人工神经网络等[2],但预测效果都不太理想。BP神经网络结构简单,且BP算法易于实现,有很强的非线性函数映射能力,在时间序列预测方面得到了广泛的应用。但是,传统的BP神经网络预测方法的泛化能力不足,预测的精度难以保证。针对这个问题,本文提出最佳停止法来改善BP神经网络的预测能力。
1 BP神经网络预测模型分析
1.1 BP算法的分析
BP算法是BP神经网络的核心,由信息的正向传递和误差的反向传播两部分组成。3层的BP神经网络结构如图1所示。

图1 3层BP神经网络结构
1)信息的正向传递:设X=[x0,x1,x2,…,xI]T,V=(vij)I×J,W=(wjk)J×K,Y=[y1,y2,…,yK]T,Z=[z1,z2,…,zj,…,zJ]T。其中,I、J、K分别表示输入层、隐含层和输出层神经元的个数;i、j、k分别表示输入层、隐含层和输出层任一神经元。
(1)
(2)
ek=dk-yk
(3)
(4)
2)误差的反向传播:误差首先由输出层传播到隐含层,计算出误差对隐含层到输出层连接权值的梯度矩阵W;再由隐含层传播到输入层,计算出误差对输入层到隐含层连接权值的梯度矩阵V。调整公式分别为
(5)
wjk(n+1)=wjk(n)+Δwjk(n)
(6)
(7)
vij(n+1)=vij(n)+Δvij(n)
(8)
其中,n表示迭代次数,η表示学习率。
1.2 BP神经网络传统预测方法存在的问题
1)BP神经网络采取的是有导师学习方式,在对训练样本进行拟合的时候,理论上如果隐含层神经元个数足够多,输出层神经元的输出信号可以以任意精度逼近导师信号,但是不一定拟合精度越高,预测的精度也越高。拟合精度太高有可能会出现“过拟合”的现象。也就是说,BP神经网络在学习过程中学习了样本过多的细节,反而失去了这些样本中蕴藏的一般规律,这就是所谓的“过学习”现象。“过学习”导致“过拟合”,过拟合导致预测精度低,预测的时间序列越多,误差越大。
2)传统的预测方法隐含层神经元的传递函数采用对数S型函数或者双曲正切S型函数,输出层神经元的传递函数采用线性函数。这样的组合虽然能够提高收敛速度和非线性拟合能力,而且输出层神经元的输出信号的取值范围也不受限;但是,实际上对增长型的时间序列的预测效果并不理想。因为隐含层神经元采用S型函数为传递函数时,由于其函数值是受限的,那么在预测阶段其函数值已经达到饱和,会导致训练阶段与预测阶段的矛盾性。
3)时间序列的预测往往给出的数据有限,如何选择输入样本的维数直接关系着网络结构的确定,同时也决定了输入样本的个数。输入样本的维数不宜过多也不宜过少。输入维数过多则输入样本个数会过少,网络就难以学习到蕴藏在样本中的一般规律。时间序列预测是一种让历史告诉未来的预测方法,输入样本维数过少意味着历史太少,难以预测未来。
2 最佳停止法
2.1 最佳停止法的原理
最佳停止法是一种有效提高网络泛化能力的方法,解决了传统方法训练阶段和预测阶段的矛盾及网络的“过拟合”问题。
在最佳停止法中,样本数据被划分成3部分:一是训练样本集,在网络训练过程中用来计算梯度和修正网络的权值和阈值;二是确认样本集,在训练过程中监控确认样本集的误差;三是验证样本集,是用来检验网络的预测效果的。这部分样本在网络训练中并没有用到,也就是说事先假设确认样本集的输出是不知道的。在训练的过程中,每训练一次不仅要计算出训练样本集的误差,同时也要计算出确认样本集的误差。训练样本集的误差在BP算法的操作下进行反向传播,层层修正网络的权值和阈值。在训练初期,训练样本集和确认样本集的误差都会连续减小;在训练达到一定程度时,训练样本集的误差还在继续减小,但确认样本集的误差可能会增大。以确认样本集的误差第1次开始增大为计数点,保留前一次确认样本集的误差和网络的各项数据。网络继续训练,当确认样本集的误差连续不减小的次数达到设定次数时,网络退出训练,返回最小确认样本集误差所对应的网络数据,即为网络训练的最终结果。
2.2 最佳停止法的实现
最佳停止法可以用于MatLab神经网络工具箱中的各种训练函数,仅需要将确认样本集的数据传送给训练函数。但在收敛速度太快的算法(如trainlm)中使用最佳停止法要特别谨慎,需要设置训练参数(如将系数mu设置得相对大一些,如设为1;将mu_dec和mu_inc设为接近1的数值,如分别为0.8和1.5),以减小收敛速度;而对于采用收敛速度较慢的算法的训练函数(如trainscg和trainrp),通常应用最佳停止法的效果很好。另外,确认样本集的选择也是很重要的,确认样本集应该要有代表性。实现最佳停止法的参数设置如下:
Net.divideFcn=’divideind’; %样本划分函数
Net.divideparam.trainind=train_ind; %训练样本
Net.divideparam.valind=val_ind; %确认样本
Net.divideparam.testind=test_ind; %验证样本
Net.trainparam.max_fail=20; %最大失败次数
其中,divideind只是样本划分函数的其中一种,除此之外还有dividedblock、dividedint、dividerand和dividetrain函数。
3 农机总动力的预测实验
根据2015年黑龙江省统计年鉴,黑龙江省1980-2014年农机总动力数据如表1所示。

表1 黑龙江省1980-2014年农机总动力
3.1 BP神经网络预测模型建立
1)网络结构的确定。设时间序列数为M=2014-1980=35,样本输入的维数I=6,样本个数为R=M-I=29,隐含层神经元个数J=6,样本输出维数为1,建立6-6-1的3层BP神经网络,如图1所示。
2) BP算法的选择。为了观测在网络训练过程中误差的变化规律,以及考虑到运用最佳停止法进行训练时观测训练样本和确认样本的误差变化规律,选择收敛速度适中的弹性BP算法。
3) 归一化。根据输入维数为6,输出维数为1,生成样本原始数据表,再把样本原始数据按照式(9)归一化到[0,1]区间,则
(9)
其中,xmin为数据序列中的最小数,xmax为数据序列中的最大数。
3.2 农机总动力的传统方法预测
以输出为1986-2010年黑龙江省农机总动力数据对应的样本作为训练样本,以输出为2011-2014年黑龙江省农机总动力数据对应的样本作为验证样本。为了验证拟合误差与预测误差的关系,设计不同均方误差精度的网络训练仿真实验得到实验数据,如表2所示。

表2 拟合误差与预测误差关系
表中的数据都是训练10次取平均值得到的。由表2可见:拟合平均相对误差随着均方误差的减小而减小,预测平均相对误差随着拟合平均相对误差的减小而先减小后增大。这验证了传统预测方法训练阶段和预测阶段的矛盾性,即所谓的“过拟合”问题。
3.3 农机总动力的最佳停止法预测
以输出为1986、1987、1989、1990、1992、1993、1995、1996、1998、1999、2001、2002、2004、2005、2007、2008、2010年黑龙江省农机总动力数据所对应的样本为训练样本;以输出为1988、1991、1994、1997、2000、2003、2006、2009年黑龙江省农机总动力数据所对应的样本为确认样本;以2011-2014年数据所对应的样本为验证样本。仿真实验数据如表3所示。
由表3可见:采用最佳停止法的预测误差为2.87%,训练样本平均相对误差(即拟合平均相对误差)为3.37%,确认样本平均相对误差为3.59%。采用最佳停止法预测误差的2.87%比传统方法预测误差处于最低时的4.54%还低1.67%,即误差减小了36.78%。另外,最佳停止法的训练样本平均相对误差和确认样本平均相对误差相当,说明了样本划分的合理性,有效避免了出现“过拟合”。
为了直观地看到最佳停止法的误差变化规律,画出图2。图2中,横坐标为迭代次数,纵坐标为均方误差。由图2可知:网络训练开始时,训练样本和确认样本的均方误差都在持续减小,迭代次数为69后,确认样本均方误差持续增大;迭代次数为89次时,到达设定的max_fail=20,网络退出训练,返回最小确认样本误差对应的网络。
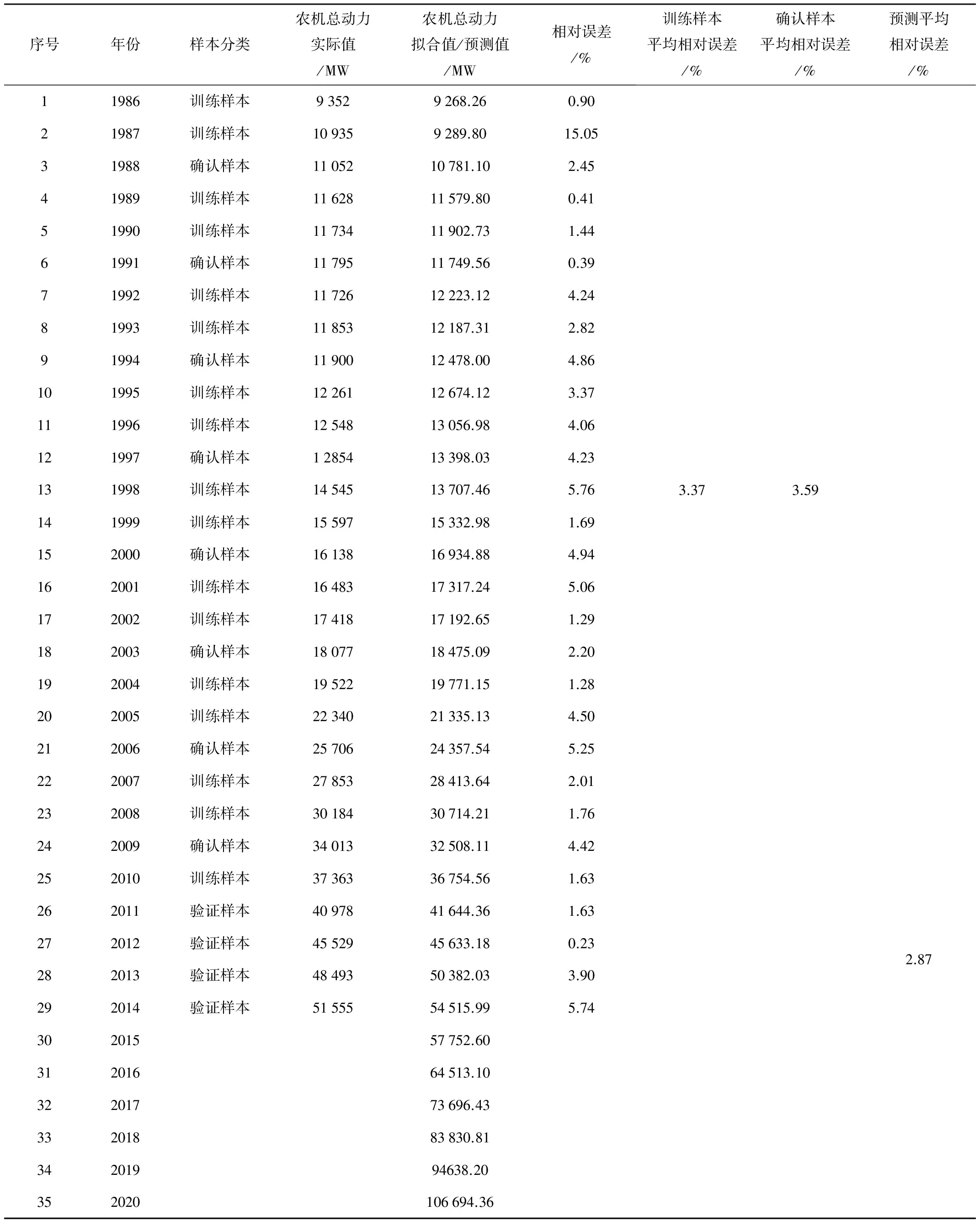
表3 最佳停止法预测

图2 最佳停止法误差曲线
4 结论
1)实验表明:随着拟合误差的逐渐减小,预测误差出现了先下降后上升的规律,即所谓的“过拟合”现象。
2)实验表明:采用BP神经网络最佳停止法进行黑龙江省农机总动力预测解决了采用BP神经网络传统预测方法出现的“过拟合”问题,有效提高了预测的精度。最佳停止法的平均预测误差为2.87%,比传统方法预测处于最好情况时的4.54%还低1.67%,即预测误差下降了36.78%。同时,用最佳停止法训练好的网络,预测了2015-2020年的黑龙江省农机总动力。
[1] 杨军强.中国农机总动力预测分析[J].湖南农机,2008(11):19-20.
[2] 朱瑞祥,黄玉祥,杨晓辉.用灰色神经网络组合模型预测农机总动力发展[J].农业工程学报,2006(2):107-110.
[3] 王吉权,王福林,邱立春. 基于BP神经网络的农机总动力预测[J].农业机械学报,2011(12):121-126.
[4] 周金勇.混沌时间序列预测模型研究[D].武汉:武汉理工大学,2009.
[5] 宋珲,董欣,王兵.基于BP神经网络的农机总动力预测模型研究[J].东北农业大学学报,2009(4):116-120.
[6] 张淑娟,赵飞.基于Shapley值的农机总动力组合预测方法[J].农业机械学报,2008(5):60-64.
[7] 郑建红.组合预测方法研究及其在农机总动力预测中的应用[D].哈尔滨:东北农业大学,2012.
[8] 严磊,毛凤梅,雷邦军,等.农机总动力预测的灰色神经网络新方法[J].中国农机化,2013(3):45-48.
[9] 刘玉静,李成华,杨升明. 辽宁省农机总动力组合预测与分析[J].农机化研究,2007(5):31-33.
[10] 王笑岩,王石. 基于BP神经网络的辽宁省农机总动力预测[J].中国农机化,2015(2):314-317.
The Application of the BP Neural Network with the Best Method of Stop in Forecast of Total Power of Agriculture Machinery
He Zhilian , Wang Fulin , Dong Huiying , Wang Huipeng
(Northeast Agricultural University , Engineering College , Harbin 150030, China)
Based on the analysis and research of the application of Neural Network in forecast of total power of agriculture machinery , the reason for the low prediction accuracy is pointed out . That is the contradiction between training period and forecast period . Through a series of related simulation experiments conducted in Matlab , the law that as the error of fitting decreased gradually , the error of forecast decreased firstly and then increased has been proved . This is the “over fitting” problem . In order to solve the problem , the best method of stop which separate the sample set into training sample set , validation sample set and test sample set is put forward to forecast the total power of agriculture machinery . During the training period , the error of training sample set and the error of validation sample set are monitored . When the error of validation sample set begin to increase and cannot decrease in 20 iterations , the training is stopped and the minimum error of validation sample set and its related neural network are saved . Then the test sample set is used to test the forecast error . Experiments prove that the problem of “over fitting” is solved by the best method of stop and forecast accuracy is improved.Finally, the total power of agriculture machinery of Heilongjiang province from 2015 to 2020 is predicted by this trained neural network.
power of agriculture machineny; best method of stop; neural network; time series; over fitting
2016-03-17
国家自然科学基金项目(31071331);黑龙江省教育厅科学技术研究项目(12511049)
何志连(1989-),男,湖南永州人,硕士研究生,(E-mail)295952258@qq.com。
王福林(1959-),男,黑龙江安达人,教授,博士生导师,(E-mail)fulinwang1462@126.com。
S23-01
A
1003-188X(2017)02-0001-05
