基于大数据信息的软件测试方法改进研究
2017-12-15,
,
(华东计算技术研究所,上海 200233)
基于大数据信息的软件测试方法改进研究
高月,张杨
(华东计算技术研究所,上海200233)
传统软件测试方法中,由于各种实验参数设置没有准确依据数学理论,涉及到的软件测试算法都存在效率偏低的问题,为此,提出基于大数据信息改进的软件测试方法,首先在大数据的背景下,对测试软件目的展开分析,将人的智慧与机器相互结合,通过对社会群体认知与数据价值提炼,使数据从机器智能分析到人类与机器智慧结合的转变;然后对大数据信息软件的三种测试方法进行探讨,第一种是利用粒子群为主线的优化算法,引入蚁群算法作为大数据信息处理机制,可以有效处理大数据信息;第二种就是针对软件特点,提出基于大数据信息处理模型的软件测试方法,通过模型对输入数据进行计算并得出结果;第三种采用仿真原理对软件进行测试;实验结果证明,基于大数据信息软件改进的测试方法不仅可以有效处理数据,还可以提高数据测试效率和软件定位,为今后的软件测试提供有力依据。
大数据信息;软件;测试;方法研究
0 引言
随着科学技术快速的发展,我国的大数据信息出现了大型的增长情况[1-2]。每过两年,我国的数据信息就疯狂的增长一倍,导致大数据信息的长期积压[3-4]。大数据信息的软件测试目的不仅仅是对数据的掌握,还要求对数据信息的专业化处理。大数据的特点是:数据量庞大、种类繁多、价值密度低,对大数据的处理要求就是速度一定要快,这就与传统的数据处理技术有着本质的差别[5-7]。
文献[8]中提出等价类和边界值的数据处理软件的算法,对于软件较大的测试还存在一定的难度;文献[9]中提出满足军兵种的大数据信息软件测试方法,集合了多种电子信息系统,包括情报的侦查、指挥的控制、导航的通信等系统。结合军兵种的大数据信息处理系统主要是为了验证电子信息之间的关联性,为软件测试工作带来了方便。
结合上述的数据软件的测试方法,提出基于大数据信息软件的改进测试方法,首先,利用粒子群为主线的优化算法,按照粒子群中粒子的更新速度和位置来测试软件的数据处理功能,并引入蚁群的算法作为大数据信息处理的机制,提高了软件测试的有效性。针对软件的特点,提出基于大数据信息处理模型软件改进的测试方法,通过模型对输入的数据进行计算并得出结果,并与原来的结果进行对比分析,以验证数学模型是否实现软件测试的有效性。还采用基于大数据信息软件仿真原理测试的方法,在仿真测试的过程中,测试的设备通过主线接收信息,并将信息转变成“作战”的状态[10],等待被传送到软件系统当中,从软件的系统当中得到指令,做好“作战”准备,对数据进行采集的设备是为了给测试结果提供准确数据的设备。最后实验证明,基于大数据信息软件改进的测试方法是有效性的。
1 基于大数据信息改进的软件测试目的

图1 软件测试数据输入与输出的关系
由图可知,判断测试的结果是否正确,无论是在大数据的背景下,还是在分析的趋势下都变的十分的困难。因此,在o′没有限制的条件下,进行软件的测试是不具备规范性的。
大数据信息下的软件处理模式都遵循物理反应得出的数据与化学作用得出的数据,物理反应得出的数据指的是:在不损失测试条件的情况下,降低测试的数据数量,在不改变数据的前提下对数据进行采集、抽样、筛选、提取等方法,还可以直接将大数据变成小数据;而化学作用得出的数据指的是:在不损失测试条件的情况下,对数据进行提炼,使用探索式的考察方法对大数据进行发挥。将人的智慧与机器的应用相互结合,通过对社会群体的认知与数据价值的提炼,可以使数据从机器的智能分析到人类与机器智慧结合转变的目的。
2 基于大数据信息软件测试目的改进的方法研究
2.1 基于粒子群-蚁群算法的大数据信息软件测试方法
大数据信息软件改进的测试目的就是为了使机器与人类的智慧相互结合,基于这个目的,对软件测试的方法进行了研究,利用大数据信息中的粒子群-蚁群的算法对软件生成的数据进行测试。
(1)首先建立一个基本的框架,粒子群算法就是基于这个基本框架的新型全局优化势算法,是一种新型的软件测试技术。粒子群算法对软件测试的原理为:设大数据的规模为l,所占的空间为j,在迭代时间为t的第n个粒子当前的坐标可以用公式表示为:
Xn(t)=(Xn1,Xn2,…,Xnj),在迭代时间为t的第n个粒子当前的速度可以用公式表示为:Vn(t)=(Vn1,Vn2,…,Vnj),第n个粒子用当前的速度在空间为j的搜索过程中得出的最佳个体解决数值为:,而最佳全局解决数值为:。随着时间的流逝粒子的坐标位置和运动的速度也会发生改变,其运动轨迹用公式(1),(2)来表示:
Vn(t+1)=Vn(t)+∂1β1[Qn(t)-Xn(t)]+
(1)
Xn(t+1)=Xn(t)+Vn(t+1)
(2)
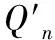
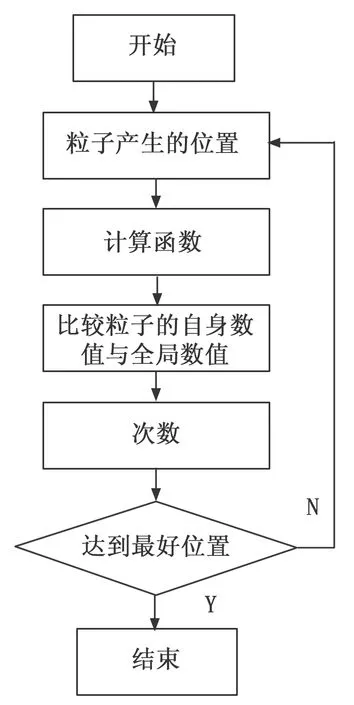
图2 数据信息中的粒子群算法的基本框架
(2)利用大数据信息分析法中的蚁群算法对软件进行测试,其结果的可靠性较高。蚁群算法主要依据的就是大量蚂蚁蚁群集体行为的活动,每个蚂蚁都有自己行动的轨迹,按照轨迹去计算蚂蚁将去方向的概率。蚂蚁将去方向的概率取决于行动地点的距离与其它不可预测的因素,但是蚂蚁属于群居行为,因此,当某个方向出现的蚂蚁数量越多的时候,将会有更多的蚂蚁跟随。蚁群的算法可以表示为:设蚂蚁的数量有n只,所占的空间为j,Efg表示的是f和g之间的距离,Nf(t)表示的是在t时刻,位于f地点处的蚂蚁数量,Ifg(t)表示的是t时刻在f和g之间连线上的信息;每一个方向上的初始信息量Ifg(t)是一致的,即Ifg(0)=C(C为常量);每一只蚂蚁都要根据信息的提示独立的到第二个位置上,由此,蚂蚁转移的概率:
(3)
公式(3)中,allowed表示的是蚂蚁n根据信息的提示独立的到第二个位置上所有点。
在上述的粒子群算法中,即使每个粒子的更新速度都随着当前个体位置的变化而变化,但是在整个的更新过程中,∂1粒子自身运动方向最好的坐标位置的运动因子与∂2粒子全局运动方向最好的坐标位置的运动因子相互接近的时候,粒子就将陷入全局运动方向最好的坐标位置,停止向下一个方向移动,最主要的原因就是每一个粒子在运动的时候都会保留在运动空间中最优的位置,不会接收其它的信息。而蚁群最优的算法是在特定的空间内对信息进行分析,并按照一定概率的方向寻找,从而获得数据的最优的数值。因此,基于大数据信息软件测试的方法中,利用粒子群为主线的优化算法,按照粒子群中粒子的更新速度和位置来测试软件的数据处理功能,并引入蚁群的算法作为大数据信息处理的机制,提高了软件测试的有效性。
2.2 基于大数据信息处理模型的软件测试方法
大数据信息处理软件的定义是:多方位,更全面的处理应用软件的相应数据,它的特点具有专业性和多样性。大数据信息处理软件的特点决定了测试人员没有办法能够简单的计算出数据输出的结果,也无法推测出输入的数据与输出的数据之间的关系,更无法被验证。种种因素都会限制软件测试的方法和测试数据的准确性,为此,基于大数据信息的软件测试方法可以从数学模型入手。
设数学模型的坐标变量(ΔX,ΔY),其中(X,Y)分别表示的是数据在数学模型中的横变坐标向量;r表示的是数据之间的半径;k1、k2为不同数据之间的系数;P1、P2为不同数据所表示的信息量;B1、B2为坐标(X,Y)随机取到的数据,由此可得到数据的模型为:
ΔX=X(r2k1+r4k2)+(r2+2x2)P1+2xyP2+xB1+yB2
ΔY=Y(r2k1+r4k2)+(r2+2x2)P2+2xyP1+xB2+yB1
(4)
想要了解软件测试的结果是否准确以及处理过程是否精密,就需要基于数学模型作为参考实现软件测试数据处理的完美效果。由公式(4)可得出数学的模型,通过模型对输入的数据进行计算并得出结果,并与原来的结果进行对比分析,以验证数学模型是否实现了软件测试的有效性。
2.3 基于大数据信息软件仿真原理测试的方法
基于大数据信息软件仿真的原理进行测试的方法是最具有权威性的,其核心是建立的模型可以与被测试的软件系统实行动态之间相互交流的仿真测试原理。该方法主要利用双网络的环境下对模型进行集成,并建立大数据信息软件仿真原理测试的环境,如图3所示。

图3 大数据信息软件仿真原理测试的环境
由图可知,大数据信息软件仿真测试的环境主要由3种设备和2条主线来组成,3种设备包括:计算机测试设备、仿真设备、输出设备;2条主线包括:测试线路与仿真线路。其中计算机测试设备是由计算机测控、系统备份、数据采集组成的,实现运行管理的控制功能;仿真设备是由电子信息、模拟操纵、指挥模板组成的,可以是按转换和发送的工作;输出设备是由仿真内路连接、数据集成输出组成的,遵循输出的准则,实现数据输出的准确性。
在仿真测试的过程中,测试的设备通过主线生成动态的信息模式,进入仿真系统,准备检测。仿真的设备接收信息,并将信息转变成“作战”的状态,等待被传送到软件系统当中,从软件的系统当中得到指令,做好“作战”准备,对数据进行采集的设备是为了给测试结果提供准确数据的设备,必不可少,因此,仿真测试环境的完美建立是测试软件的重要方法之一。
3 实验结果与分析
3.1 实验步骤
实验的数据主要来自于中央电力集团某个研究场所,用来测试的软件中只有一种配置项才能完成大数据信息的处理,这种配置项被称为坐标的转换。坐标转换主要运行于WAP24芯片中,并且依赖A3X-A4X型号的编辑翻译器的开发,其运行的代码大约为1356行。采用平面坐标向直角坐标的正面方向转换的例子,来验证实验方法的有效性。
假设平面坐标为(a,b),求直角坐标(X,Y),在这个求解过程所要依赖的数据信息模型如公式(5)所示:
(5)

I=a-i1,k=e′sinb,t=tanb
基于大数据信息模型的软件测试设计如下:
利用传统的坐标转换对信息软件进行实验,那么所选取的数据就会具有随机性,假设输入的一组数据为(a,b),那么相应的就会接收到一组数据(X,Y),其返回的数据并不完全符合协议规定的样式,因此,需要根据公式(5)中的数据模型作为输出的结果对被测试的软件进行对比,并根据Mary的软件测试样本进行模拟测试。由于数据的选择具有随机性,简单的测试方法很难发现软件中的漏洞,因此使用了基于大数据信息软件的测试方法,并利用数据信息模型的公式,其测试原理依据公式(6):
(6)
其中:α表示的是常量;x1,x2,x3,…xn表示的是坐标的横向变量,同理y1,y2,y3,…yn表示的是坐标的纵向变量;x1m,x2m,x3m,…xnm表示的是x1,x2,x3,…xn经过n次的不断增长中的最小值,x1M,x2M,x3M,…xnM表示的是x1,x2,x3,…xn经过n次的不断增长中的最大值。
3.2 实验结果
为了验证上述实验过程的有效性,对其参数进行设定:IM=180°,Im=-180°,bM=90°,bm=-90°,n=50
由此可得出直角坐标(X,Y)随着平面坐标长度a的变化而发生改变,如图4所示。
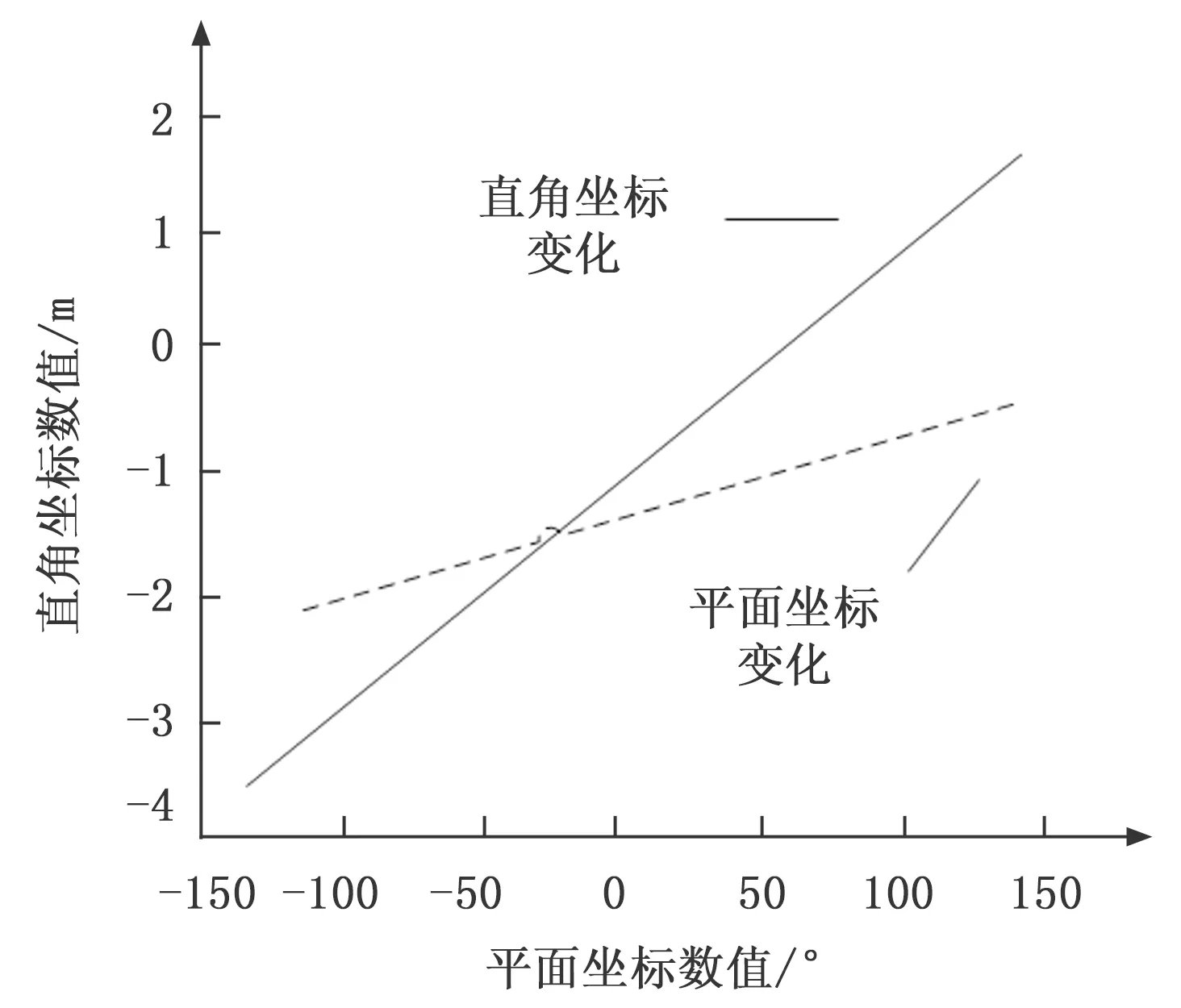
图4 直角坐标(X,Y)随平面坐标a的变化
直角坐标(X,Y)随平面坐标的输入变量a与变量b的同步增长趋势与图1所画的图像是一致的。根据图1中平面坐标的输出变量与输入变量之间的关系,就可以验证大数据信息软件的测试方法的有效性。

比较图4与图5发现,之前图1中的平面坐标的变化与直角坐标的变化轨迹不一样,但是经过上述实验结果的推论,图5中的平面坐标的变化与直角坐标的变化轨迹大致吻合。经过技术人员的开发与研究,当输出值大于2.004106的时候,其软件测试成功。
4 结束语
大数据信息软件的测试完成后,对信息系统进行综合监视。软件测试技术从单一方面向多元素方面进行转变,测试的据不仅限制了输入数据的属性,还综合数据大小以及数据特性。在科学发达的今天,构建一个自动化软件测试环境非常简单,能够是满足客户端需求。

图5 预期的直角坐标Y与被测试软件输出的直角坐标y1之间的差别
基于大数据信息软件的测试方法不仅可以有效的处理数据,还可以清晰的转变输入与输出量之间的复杂关系,有利于测试方法可以准确的选择软件需要测试的数据,并且提高数据测试效率。在今后软件测试方法研发中,将结合实践进行更深层次的实验来验证软件处理数据功能,并对算法进一步改善,不断提高软件测试质量。
[1] 孟 岩,周 航,刘 沓.大数据时代环境管理会计发展探究[J].财会通讯,2015(7):5-7.
[2] 陈志刚,鲁晓波.大数据背景下信息与交互设计的变革和发展[J].包装工程,2015(8):6-9.
[3] 刘彩云,沈春会.浅析大数据时代的电子政务信息资源采集[J].档案管理,2015(3):25-27.
[4] 齐 萱,杨 静.大数据时代会计信息相关性研究述评[J].财会通讯,2015(28):62-65.
[5] 赵 霞,林天华,马素霞,等.基于选择性加载策略的电能质量数据处理[J].计算机应用,2016,36(5):1434-1438.
[6] 杨 斐,艾晓燕,张永恒,等.大数据精准挖掘处理架构及预测模型研究[J].电子设计工程,2016,24(12):29-32.
[7] 赵曙光.禀赋结构、比较优势与传统媒体转型——基于传统媒体与新媒体从业人员的调查数据分析[J].新闻记者,2016(9):51-57.
[8] 蒋 亮,蒙祖强,胡玉兰,等.一种基于向量夹角的快速计算等价类算法[J].小型微型计算机系统,2015,36(10):2360-2364.
[9] 李志强,高大兵,苏 盛,等.基于大数据的智能电表入侵检测方法[J].电力科学与技术学报,2016,31(1):121-126.
[10] 刘耀聪,袁海斌,李 荣.基于CAN总线仿真测试的开发平台[J].计算机应用,2016,36(S1):184-187.
SoftwareTestingMethodBasedonLargeDataInformation
Gao Yue, Zhang Yang
(East-China Institute of Computer Technology, Shanghai 200233, China)
the traditional software testing method for a variety of experimental parameter Settings are not accurate according to the mathematical theory, and involves all exist the problem of low efficiency of software testing algorithm. To do this, I put forward a kind of software testing method based on large data information, first of all, under the background of big data, analyzes the purpose of the software of the test, the application of the wisdom of men and machines together, through the understanding of the social group and the value of the data extract, can make the data from the machine's intelligent analysis to the combination of human and machine intelligence. Then three test methods for large data information software were discussed, the first is using particle swarm optimization algorithm as the main line, the introduction of ant colony algorithm as the big data information processing mechanism, can be effective way to deal with large data information; The second is according to the characteristics of the software, and puts forward the software testing method based on large data information processing model, through the model of input data is calculated and the results; The third method USES the principle of simulation to test software. Finally, the experimental results show that based on the large data information software testing method not only can effectively process the data, also can improve the test efficiency of the data and software localization problem, for the future of software testing provides a strong theoretical basis.
big data information; software; test; methods to study
2017-06-13;
2017-07-13。
高 月(1976-),女,江苏常州人,硕士,高级工程师,主要从事计算机软件方向的研究。
1671-4598(2017)11-0107-04
10.16526/j.cnki.11-4762/tp.2017.11.028
TP473
A
