一种基于规则和统计的连动句识别方法
2017-12-01刘雯旻张晓如
刘雯旻,张晓如
(江苏科技大学计算机科学与工程学院,江苏镇江212003)
一种基于规则和统计的连动句识别方法
刘雯旻,张晓如
(江苏科技大学计算机科学与工程学院,江苏镇江212003)
连动句是具备连动结构的句子,现代汉语中十分常见且使用频繁。连动句语法结构和语义关系都很复杂,对此文中针对连动句的识别问题进行了研究,提出一种集规则方法与统计方法于一体的汉语连动句识别方法,文中提出的方法首先设计构建基于连动句形式特征和语义角色的基础规则库和被动名词库,然后使用互信息计算谓语动词与主语候选项的搭配强度,最后达到识别连动句的目的。实验结果准确率达到79.42%,表明本文方法可以较为有效地识别中文文本中的连动句。
连动句;自动识别;互信息;中文信息处理
人工智能始于20世纪50年代,人工智能研究的一个重要组成就是自然语言理解。由于自然语言理解具备约定、多值、缩略、隐含、隐喻等特点,要使计算机能够自主理解人类的自然语言以实现人机的无障碍沟通是十分困难的[1]。事件本体[2]是将人类理解自然语言的能力以计算机可以处理和使用的方式表达知识的方法,事件本体以事件作为知识表示单元,更加符合人类认识世界的规律。Rachel Nordlinger将事件定义为:“谓词、谓词发生的时间段、谓词发生的情况或者条件”[3]。连动句包含多个谓词,蕴含了十分丰富的知识,(因此)获取连动句的方法将在自然语言理解、常识知识获取、智能网页等人工智能应用领域中发挥重要的作用[4]。因此有效的连动句识别方法具有重要的学术价值和应用价值。
许有胜基于连动句的形式特征和词语的语义角色两个方面设计构建了一些规则,实现了自动识别和分析连动句的研究目标[5]。然而基于规则的连动结构识别存在以下问题:①歧义问题,规则方法无法对多个歧义结构进行辨别,尤其是兼语结构和连动结构;②鲁棒性,规则无法有效识别规则没有覆盖到的句子,实践规则方法很难;③规则冲突检测,当规则数量较多时,规则间存在相互冲突,从而影响识别效果。
本文提出一种基于规则和统计的连动句识别方法以提高连动句识别效率,具体步骤如下:①对大规模语料中的所有句子进行预处理,将满足预处理条件的句子放入连动句池内等待进一步筛选。②整理语言学界连动句的相关研究成果,归纳提取连动句形式上的特点总结出提取规则构成基础规则库。基础规则库包括提取规则和排除规则,提取规则就是根据连动句的特征总结归纳的规则,排除规则就是根据容易与连动句混淆的句子的特征总结归纳的规则。③利用基础识别规则和被动名词词典进行连动句的初步识别。④利用互信息[6]进一步判定句子是否是连动句,最后完成连动句的自动识别。
1 本文研究的连动句
连动句在现代汉语中大量存在,是一种常见的汉语句子,连动句的识别一直是中文信息处理研究的热点之一。自1952年李荣先生第一次提出“连动式”[7]的概念,连动句的存废、名称和定义一直都存在争议。杨寄洲先生在《汉语教程》中对连动句的定义是:谓语有两个或两个以上的动词或动词词组组成的句子叫连动句[4],连动句侧重表达连动结构的目的或方式。朱德熙先生在《语法讲义》中对“连谓结构”做出如下描述:连谓结构是谓词或谓语结构连用的格式,谓语结构的前一个直接成分可以是单个的动词也可以是动词结构,后一个直接成分可以是动词或动词结构也可以是形容词[8]。综合各家之言孙晓华将连动句的定义总结归纳为:连动句中间没有关联词、没有语音停顿、没有表示停顿的标点符号,有两个或两个以上动词作同一个主语的谓语且这两个或两个以上动词具备一定的关系以表示两个动作连续进行或相伴进行[9]。
基于以上认识我们发现所谓连动句是指句子中出现连续两个或两个以上动词,且这些动词具有同一主语,但每个动词的宾语均不是主语表示的对象。我们将连动句中的多个动词称为连动词,连动句中出现的动词的数目称为连动词的数目,一般地如果连动句S中出现k个动词则称S是k-元(目)连动句。例如:我开门进房间拿苍蝇拍打苍蝇。该句包含了 4 个动词:“开”、“进”、“拿”、“打”,4 个动词的主语都是“我”,而它们的宾语各不相同,分别为“门”、“房间”、“苍蝇拍”、“苍蝇”。不仅如此,例句中的四个动作连续进行,故该句为4-元(目)连动句。连动句的主要特征之一是动词的主语是一致的,因而通常情况下,一个多元连动句可以分解成若干个二元连动句进行表达,例如上述例句可以表达为3个2-元连动句:“我开门进房间”、“我进房间拿苍蝇拍”、“我拿苍蝇拍打苍蝇”。因此,不失一般性,本文仅考虑针对2-元连动句,提出识别2-元连动句的方法。
2 识别连动句的方法
2.1 提取规则和排除规则
将规则和统计方法结合的分析方法是自然语言处理领域常用的信息处理方法[11],本文将连动句的规则特征和统计特征结合起来,有利于提高识别连动句的准确度。加入识别规则可以降低方法对大规模语料库的以来,通过统计概率的计算可以大幅度降低规则方法处理的复杂度,弥补规则不完备的缺点提高识别准确率。
首先,由于分词会过度切分和错误标注的问题很难解决,这里我们用启发式规则,解决较为突出的问题。基础规则库包括提取规则和排除规则,提取规则就是根据连动句的特征总结归纳的规则,有短语处理规则和句法结构和语义分析规则,排除规则就是根据容易与连动句混淆的句子的特征总结归纳的规则,易与连动句混淆的句子有兼语句、复句、紧缩句[12-14]等。具体规则如下。
2.1.1 短语处理规则
本文需要通过一系列规则保证句子保持理想的句法结构,因此部分被切分的词语要进行整合。
规则1连续出现的多个名词概念合并成一个名词概念。
连续出现的多个名词往往是一个整体,应当合并为一个名词。如“李明/n代替/v外联部/n部长/n发言/v”中将“外联部”作为一个概念。
规则2连续出现的多个单字形容词合并为一个形容词。
连续出现的多个单字形容词往往是一个整体,应当合并成一个形容词。例如,可将“鲜艳/a靓丽/a的/u裙子/n”合并为“鲜艳靓丽的/a裙子/n”。
规则3连续出现的动词和助词的合并为一个形容词。
连续出现的动词和助词的合并为一个形容词。如:“奔跑/v的/u”合并为“奔跑的/a”。
规则4连续多个用并列关系连词或选择关系连词连接的名词或形容词及连词合并为一个名词或形容词。
连续多个用并列关系连词或选择关系连词连接的名词或形容词及连词合并为一个名词或形容词。如“色彩/n 和/cc 情调/n”合并为“色彩和情调/n”;“开心的/a和/cc开朗的/a”合并为“开心的和开朗的/a”
规则5名词短语识别规则集合
规则5-1连续出现的形容词和名词合并为一个名词。如:“好看的/a裙子/n”合并为“好看的裙子/n”。
规则5-2连续出现数词、量词、名词合并为一个名词。如:“五/m条/q鱼/n”合并为“五条鱼/n”。
规则5-3句首连续出现的动词和名词合并为一个名词。如:“促销/v活动/n”合并为“促销活动/n”。
规则5-4句首连续出现的动词、助词和名词合并为一个名词。如:“奔跑/v的/u狮子/n”合并为“奔跑的狮子/n”。
2.1.2 句法结构规则
规则6包含两个及以上动词的句子可能是连动句。
连动句可表示为:<主语n1><谓语v1(动词1)>[<宾语 n2>]<谓语 v2(动词 2)>[<宾语 n3>],具备两个动词是一个基本条件。如:“我/rr去/vf上海/ns”只有一个动词不满足规则该句一定不是连动句,而“我/rr骑车/vi去/vf上海/ns”满足规则包含两个动词则该句可能是连动句。
2.1.3 排除规则
现代汉语中有许多句式易与连动句混淆,例如:兼语句、复句、紧缩句等。本文提出基于易混淆句式的排除规则来确保连动句识别的准确率。
规则7不包含关联词的句子可能是连动句
连动句中不可包含表示逻辑关系的关联词语,包含关联词的句子一般情况下是紧缩句。如:“他/rr一/d坐/v下来/vf就/d看/v书/n”包含两个动词但同时包含关联词“一…就…”因此该句不是连动句。
规则8第一个谓语动词的宾语是被动名词的句子可能是连动句
我们将不能主动发出动作的名词定义为被动名词,一般被动名词不能做主谓结构中的主语。如:我用石头砸核桃。该句中石头不能主动发出“砸”的动作,因此“砸”的主语是我而不是石头,该句是连动句。吕叔湘把名词分为4种:1)人物;2)物件;3)物质;4)无形[15],其中只有“人物”可以主动发出动作,本文以“物件”、“物质”和“无形”为基础类扩充被动名词库。这里我们结合潘正高识别中文命名实体的方法[16]手工整理了包含一万个被动名词的词库。
规则9两个动词之间没有否定副词的句子可能是连动句。
连动句不把“不”、“或”和“没有”等否定副词放在第二个谓语动词前面,如果否定形式的句子中把否定副词放在第二个动词前面即可判定为非连动句。如:我不骑车去上学。否则副词“不”在第一个动词前面,且不再两个动词之间因此该句可能是连动句。
2.2 v1、v2与前面主语候选项的搭配强度
连动句自动识别中的识别的重要条件之一是第一个动词和第二个动词的主语是一致的。因此,两个动词与前面的主语候选项的搭配强度的计算是本文方法的重点之一。主谓搭配是词语搭配之一,有两个成分组成,前一个是主语后一个是谓语。
本体语言学主要是从两个谓语动词的主语异同及与谓语动词之间的关系差异这两种方法来进行区别。前一种方法对于我们来说非常有借鉴意义,我们可以通过分别计算、主要是与前面主语候选项的搭配强度来判定和的主语是否相同。本文采互信息[17-18]作为评价v1、v2与前面主语候选项的搭配强度,互信息公式如下:
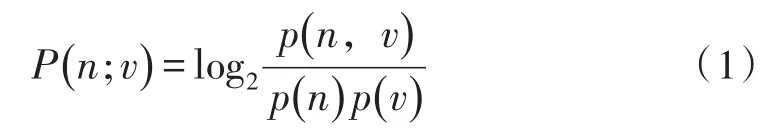
其中v是v1或v2,n是v1或v2前面的主语候选项,p(n,v)是v1、v2与前面主语候选项出现概率,p(n)和p(v)是其各自出现的概率。当P(n;v)=0时,n和v独立即n和v不能构成搭配,当P(n;v)>0时,n和v可以构成搭配,且P(n;v)值越大,n和v的搭配强度越大,本文认为当P(n;v)>∝时n和v可以构成搭配。
3 连动句的自动识别步骤
根据以上分析,本文连动句的识别方法的完整步骤详细描述如表1所示。
根据以上具体识别步骤,给出1个例子的分析过程。例句:“妈妈套住母鹿,男孩挤了一杯鹿奶大口地喝了下去。”,分析结果如下:
Step1:将例句切分为2个独立小句:“妈妈套住母鹿”“男孩挤了一杯鹿奶大口地喝了下去”。
Step2:对句子进行分词和词性标注,结果如下:“妈妈/n套住/vi母/ng鹿/n”、“男孩/n挤/v了/ule一/m杯/q鹿/n奶/n大/a口/n地/ude2喝/vg了/ule下去/vf”。

表1 连动句识别步骤
Step3:2个句子满足短语处理规则,而第一个句子包含一个动词不满足句法规则,第二个句子包含2个动词即满足句法规则。
Step4:第二个句子中没有关联词和否定副词且“鹿奶”是被动名词因此该句满足排除规则。
Step5:“男孩/n挤/v了/ule一/m杯/q鹿/n奶/n大/a口/n地/ude2喝/vg了/ule下去/vf”中,P(男孩;挤) >∝ 、P(男孩;喝) >∝且P(鹿奶;喝) <0所以该句的两个谓语动词“挤”和“喝”主语一致。得出结论,句子“妈妈套住母鹿”不是连动句,“男孩挤了一杯鹿奶大口地喝了下去”是连动句。
4 实验及结果分析
4.1 实验指标
指标采用准确率、召回率和平均值,具体定义如下:

4.2 测试集
实验中首先使用ICTCLAS分词系统对测试文本进行分词和词性标注,预处理后得到2万个描述性语句,经人工标注连动句有4 051条。经连动句自动识别步骤,本文通过提取规则库和识别规则库的筛选抽取出5 244条句子,经人工验证其中有3 200条句子是连动句,通过判断这些句子中两个谓语动词的主语一致判定5 244条句子中有3 581条连动句,经人工验证其中有2 703条句子是连动句。实验各指数如表2所示。

表2 本实验评价指标
通过分析实验中误判、漏判的句子,我们发现本文所提的方法存在以下几个缺陷:
1)分词错误:分词程序在错综复杂的文本中还是会造成很多类型的错误,间接造成抽取结果错误。虽然我们用规则进行部分规避,但是还是不能完全覆盖。例如“李明/r打算/v要/n竞选/v班长/n”。这里就将“要”标记成了一个名词。
2)名词短语的识别错误:本文方法中虽然构造了名词短语的识别规则,但是规则仍不够充分导致结果不尽如人意。例如“铁路/n部门/n降低/v高铁/n运行/v速度/n”。例句中能识别“铁路部门”这个名词短语,但是不能识别“运行速度”这个名词短语,进而会给实验结果带来错误。后续工作需要引入更好的名词短语识别方法。
3)规则稀少。本文的方法提出多个规则但仍不全面,出现漏判情况。
5 结束语
本文介绍了一种基于规则和统计的连动句识别方法,先对大规模语料中的所有句子进行分句、分词和词性标注的预处理,将满足预处理条件的句子放入连动句池内等待进一步筛选。然后归纳提取连动句形式上的特点总结出提取规则构成基础规则库。基础规则库包括提取规则和排除规则,利用基础识别规则和被动名词词典进行连动句的初步识别。最后利用互信息进一步判定句子是否是连动句,完成连动句的自动识别。本文下一步的工作是进一步提高连动句的识别准确率,将从以下几个方面开展工作:
1)努力完善连动句识别的规则系统。
2)扩大可识别的连动句的范围,提出可以识别包含两个以上谓语动词的连动句的方法。
3)提高判定v1和v2的主语是否是同一个主语的准确率,主语是否一致的判定方法是本文后续研究的最主要的任务之一。
[1]吴畏,赵川.基于语义的自然语言理解研究[J].数字通信,2014(4):32-34.
[2]仲兆满,刘宗田,李存华.事件本体模型及事件类排序[J].北京大学学报:自然科学版,2013(2):234-240.
[3]张凯隆,庄艳,陈继明,等.一种基于谓词覆盖技术的启发式事件匹配算法[J].计算机应用与软件,2010(6):1-4,13.
[4]陈波,姬东鸿,吕晨.基于特征结构的汉语连动句语义标注研究[J].中文信息学报,2013(5):60-66,74.
[5]许有胜.连动结构的自动识别和分析[J].巢湖学院学报,2013(4):108-115,142.
[6]刘海峰,陈琦,张以皓.一种基于互信息的改进文本特征选择[J].计算机工程与应用,2012(25):1-4,97.
[7]彭国珍,杨晓东,赵逸亚.国内外连动结构研究综述[J].当代语言学,2013(3):324-335,378.
[8]姚兰.“事件”视野下现代汉语连动句[J].青春岁月,2013(12):104-105.
[9]孙晓华.现代汉语连动句及其习得研究[D].南京:南京师范大学,2008.
[10]吴宏洲.分词技术的研究与应用——一种快速分词的实现[J].电脑知识与技术,2015(6):1-5.
[11]昝红英,张腾飞,张坤丽.规则与统计相结合的介词用法自动识别研究[J].计算机工程与设计,2013(6):2152-2157.
[12]张恒.动结式、V得句和兼语句的比较[J].汉语学习,2013(4):56-64.
[13]吴锋文.基于关系标记的汉语复句分类研究[J].汉语学报,2011(3):63-73,96.
[14]皇甫素飞.紧缩构式的界定及其句法结构分析[J].浙江工商大学学报,2014(5):18-25.
[15]王华.现代汉语名词语义分类体系研究[J].时代文学(上半月),2012(4):197-198.
[16]潘正高.基于规则和统计相结合的中文命名实体识别研究[J].情报科学,2012(5):708-712,786.
[17]徐峻岭,周毓明,陈林等.基于互信息的无监督特征选择[J].计算机研究与发展,2012(2):372-382.
[18]赵海峰,陆明,卜令斌等.基于特征点Rényi互信息的医学图像配准[J].计算机学报,2015(6):1212-1221.
A method based on rules and statistic for serial⁃verb sentence recognition
LIU Wen⁃ming,ZHANG Xiao⁃ru
(Jiangsu University of Science and Technology,School of Computer Science and Engineering,Zhenjiang212003,China)
Serial⁃verbsentence is a common sentence patterns in Chinese,whichis a special sentence with a serial verb construction.Serial⁃verbsentence is so complex,in view of the above problem thispaper studies the recognition of Serial⁃verbsentences in large corpora,proposes a method which combines rule methods and statistical methods to recognize serial⁃verbsentence.The proposed method constructs rules based on formal features and semantic roles of serial⁃verbsentence,and passive nouns library,calculates collocation between predicate verbs and candidate subject with mutual information.Experimental results show that the proposed method can more effectively recognize serial⁃verbsentence.
serial⁃verbsentence;automaticrecognition;mutualinformation;Chineseinformationprocessing
TN02
A
1674-6236(2017)22-0018-05
2016-10-08稿件编号:201610016
江苏科技大学海洋装备研究院自培育项目(HZ2016004)
刘雯旻(1983—),女,江苏阜宁人,硕士研究生。研究方向:智能信息处理。
