预测性大数据分析在高校招生中的应用研究
2017-11-29邓广彪广西民族师范学院数学与计算机科学学院崇左532200
邓广彪(广西民族师范学院 数学与计算机科学学院,崇左 532200)
预测性大数据分析在高校招生中的应用研究
邓广彪
(广西民族师范学院 数学与计算机科学学院,崇左 532200)
在大数据时代,高校招生工作要占领制高点,需要采用数据分析方法把握学校招生状态。通过预测性大数据分析方法对招生数据进行分析,根据分析结果对发现的问题及时整改并预测未来的发展状况,才能真正做到基于数据进行决策。对常用的预测性数据分析方法进行介绍,结合高校招生工作的应用进行分析,使用SAS EG建立新生报到预测模型,对2016年录取新生报到情况进行预测,通过预测结果与实际报到情况对比验证了模型的有效性。
数据分析; 招生; 逻辑回归; SASEG
0 引言
在大数据时代,网络及移动技术的发展使得人们产生、收集数据非常便利,可目前状况却是人们在生活中常被大量的数据围绕并淹没,如何从数据中提取知识进行决策却一直困扰着相关工作人员,采用简单且实用的分析技术从数据中获取知识是一个普遍待拯救的问题。在大数据时代,很多人想用高深的算法从大量杂乱无章的数据中获取有用的知识来进行决策,其实这是一个误区,因为数据越多越杂则导致噪声越多,从数据中提取知识进行决策的难度就越大[1]。在文献[2]中提出对于小企业、小单位要做到大数据小应用,不能以高深的算法和TB级以上的数据才算大数据,只要能综合利用身边的数据提取知识进行决策,就是属于大数据的应用。因此,收集日常工作相关数据进行分析决策,是每个单位、每个行业在大数据时代必须要掌握的基本技能,这样才能在大数据时代不迷失方向,使数据真正发挥决策作用。
对于高校招生来说,每年都有大量各省份各专业考生录取数据及新生报到情况,可这些数据目前在很多高校仅作为基础数据导入各种管理系统中存储,仅在需要时进行查询统计,没能为招生工作提供决策依据发挥作用。其实对于这些数据,可以建模分析各专业的招生情况是否存在差异,是什么原因导致这种差异;也可以根据历史报到数据建立新生报到模型,预测所录取考生未来的报到情况;更可以使用时间序列对历年招生人数建立模型,预测未来招生人数变化趋势。通过这些预测性数据分析,在招生中就能做到有把握、有目的、有方向的工作,从而保证学校得到稳定的高质量生源。
1 数据的计量尺度
在数据分析中,很多分析软件对数据的计量尺度是敏感的,因此需要弄清每个变量的计量尺度,才能明白该数据用何种类型进行表示,进而知道采用何种方法对这些数据进行分析。数据的计量尺度有定类、定序、定距和定比4种[3],其中定类和定序属于分类型数据,定距和定比是属于连续数值型数据。定类尺度是描述数据的分类情况,这些类别之间无高低大小之分,如招生数据中的性别、民族等。定序尺度也是描述数据的分类情况,但是所分的类别固有大小或顺序区分,如招生数据中的层次,有研究生、本科、专科等高低类别。定距和定比两种尺度在数据分析中一般不做特别区分,指的是连续的数值型数据,有大小、顺序区分,分布的范围较广,如招生数据中的投档成绩、录取人数等。另外,在数据分析过程中,定类和定序数据很少用汉字表示,一般都会转换成数值表示,如性别中男用1、女用2,招生层次研究生用1、本科用2、专科用3表示等等,因此在做数据处理时要做好数据计量尺度的区分。
2 常用的预测性数据分析方法
2.1 方差分析
当自变量是分类数据、因变量是连续数值型数据时使用方差分析来判断自变量的不同水平是否对因变量有显著影响[4],如录取考生中不同专业的考生在录取分数上是否有显著影响,以此作为依据来判断本校的哪些专业是当年录取的热门专业。在方差分析时,主要通过计算总离差平方和SST、组间离差平方和SSM、组内离差平方和SSE,然后计算F统计量并根据显著性水平来判断各组之间是否有显著差异,最后通过决定系数来判断模型的解释力度。
假设分类数据有m个水平(组),每个水平有ni个数据,每个数据用xij表示,则得式(1)~(3)。
(1)
(2)
(3)

根据SST、SSM、SSE可计算F统计量和决定系数R2,得式(4)、(5)。
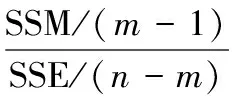
(4)

(5)
其中m表示水平数,n表示总记录数。
根据给定的显著性水平查找临界值,如果F大于临界值则说明各水平之间有显著差别,根据相关软件输出的系数可构造预测模型。依据的值可判断模型的解释力度,R2越大说明模型越好。
2.2 线性回归
线性回归用于自变量和因变量都是连续数值型数据,这些数据散点图落在一条直线附近,通过这些历史数据建立回归方程对未来数据进行预测的方法[5],如在招生中可根据历年考生录取数量与新生报到数量建立线性回归模型,用该模型来预测新生报到率。线性回归可用如式(6)表示:
y=β0+β1x1+β2x2+…+ε
(6)
其中β0为方程的截距,x1、x2、……为自变量,β1、β2、……为相关自变量对应的系数,ε为扰动项。若模型只有一个自变量,则一元线性回归模型为式(7)。
y=β0+β1x1+ε
(7)
针对一元线性回归,根据所给的样本,使用最小二乘估计法可计算出β0和β1,则可得到线性回归方差式(8)、(9)。

(8)
(9)
为确保方程的有效性和可用性,需要根据样本数据以及拟合的方差计算方程的拟合优度R2并使用F检验对方程进行检验、使用t检验对方程的系数进行检验,如式(10)~(12)。
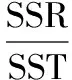
(10)

(11)

(12)

根据计算结果,R2越接近1说明方程拟合得越好。根据给定的显著性水平,F大于临界值则说明方程有效,t大于临界值则说明方差的系数有效。
2.3 逻辑回归
逻辑回归是线性回归的变形,当因变量为只有两个取值的是否型、自变量为分类或连续型数据时可以使用逻辑回归构造回归方程来对因变量取值的概率进行预测[6],如在招生数据中,可以使用高考分数、专业、层次等因素来预测新生的报到情况。逻辑回归与线性回归类似,区别为线性回归方程左边直接为数值型的因变量,而逻辑回归方程左边为因变量拟合值取值概率的逻辑函数,逻辑回归方程为式(13)。

(13)
其中pi表示第i个事件发生的概率,βi为自变量xi的回归系数。
2.4 列联表分析
当自变量和因变量都是分类变量时,可以使用列联表分析两个变量之间的相关性,如在招生中判断性别或民族等是否对专业录取有影响则可使用列联表进行分析判断。在列联表分析中,将自变量放入行、因变量放入列,行列交叉的位置则计算自变量当前分类值与因变量当前分类值出现的次数(或百分比),最后通过计算单元格期望频数和卡方(x2)值来判断两个分类变量之间是否存在相关性,如式(14)、(15)。
期望频数=行总计×列总计÷样本总数
(14)
(15)
其中R为行数,C为列数,Obsij表示该单元格的实际频数,Expij表示该单元格的期望频数。
如果期望频数等于观测频数则说明两个分类变量之间不存在相关性,如果大于临界值则说明两个分类变量之间存在相关性。
2.5 时间序列
根据2017年11月27日和2018年4月26—27日两次鄱阳湖湖区的水体垂直巡航观测数据,观测区域主要在主湖区及松门山以北的主航道(图1a),考虑湖区水流条件变化、河流汇入以及人类活动变化等影响因素,分别设置了1701#~1711#等11个、1801#~1820#等20个站点,其中,星子站日均水位分别为 9.50、11.78 m左右。站点空间分布如图 1所示。
时间序列分析一般是针对连续数值型数据,分析这些数据随着时间变化的规律,并根据这些变化规律对未来的发展进行预测[7],如在招生工作中,可以利用历年的招生录取的人数,采用时间序列建立模型预测未来的招生人数。对于一个时间序列,通常包括如下四方面内容:
长期变动趋势(T):指序列有持续上升、下降或停留在某一水平的趋势,反映了事物主要发展的情况,是时间序列中重要的研究内容。
季节变动(S):指序列是否有按周、月或季度的变化周期。
循环变动(C):一般是指长期(一年以上)受非季节因素影响的变动。
不规则变动(I):指时间序列中受偶然因素影响无法进行预测的部分。
因此,时间序列有如下3种模型:
加法模型:Y=T+S+C+I
乘法模型:Y=T×S×C×I
混合模型:Y=T×S+I
进行时间序列基本预测的方法:(1)逐步回归法:数据有明显趋势但无季节效应时使用;(2)指数平滑法:数据没有固定趋势并且波动较大时使用;(3)Winters乘法:数据有季节效应且随着时间的变化季节效应增大时使用;(4)Winters加法:数据有季节效应且随着时间的变化季节效应不变时使用。
ARMA和ARIMA法:如果时间序列平稳,可以使用ARMA法建模;如果时间序列不平稳,可以通过差分后将数据转换为平稳时间序列后建模,则使用的是ARIMA法。
3 使用逻辑回归建立新生报到预测模型
虽然每个学校甚至每个专业每年的报到率都相对稳定,但是根据报到率只能得到一个可能会到校报到的人数,但对于具体是哪些人可能不会报到则无法相对准确掌握,导致对新生各项工作开展不能完全按计划进行。因此对录取到的考生判断其未来报到的情况是每个学校在录取考生后需要相对准确掌握的数据,特别是对于报到率不是非常高的学校,预测每个录取考生是否报到的情况对于宿舍安排、专业分班等有着很好的指导作用。
由于因变量“是否报到”只有0(不报到)、1(报到)两个取值,因此采用逻辑回归来建立新生报到模型,并以该模型对未来录取的考生进行预测其报到情况。
3.1 数据变量说明
新生录取数据的变量有很多,根据经验选取变量来建立模型,如表1所示。
由于每年分数线都不同,在分析成绩是否影响报到时不直接采用投档成绩,而采用投档成绩减去当年分数线的形式,使得模型能够适应每年录取的数据。由于全校的专业数量太多,根据历年情况,师范类专业的报到率普遍较高,而理工科类专业的报到率偏低,因此将专业按师范类、非师范理工科类、非师范文史类进行区分。
3.2 建模及结果分析
在进行逻辑回归前,先在SAS EG中使用列联表分析每个分类自变量与因变量是否报到之间的相关性,经过分析发现性别、政治面貌、考生类别这3个变量与是否报到的相关性不大,因此在建模时把它们剔除。
使用SAS EG进行逻辑回归建模时,对于自变量是否进入模型采用“逐步选择”的方法进行选择,进入模型、保留在模型中的显著性水平均设置为0.05,经过软件建模发现是否少数民族、层次无法进入模型,如图1所示。

表1 变量及取值说明

图1 模型选择的变量
最后保留在模型中的自变量有录取专业顺序、成绩与分数线差、科类、年龄、投档志愿这5个变量作为主效应,整个建模过程的ROC曲线变化,如图2所示。

图2 建模的ROC曲线变化
根据图1所示的P值,进入模型的5个变量对影响是否报到都具有极显著的统计学意义。根据图1的评分和图2的ROC曲线变化情况,发现录取专业顺序、成绩与分数线差这两个变量对考生是否报到有较大的影响,这与实际情况是一致的,因为有部分未录取到意向专业或高考成绩分数较高的考生,会选择复读来年考一个更好的到学校。根据图2所示最后建立模型ROC曲线下的面积为0.881,说明该模型对原始数据拟合时有88.1%左右的考生能够正确预测该考生是否报到的情况。
使用上述建立的模型,对2016年录取非艺术体育类2 825名考生的报到情况进行预测。经过模型预测结果与实际情况比较,能正确预测报到的有2 347人,正确预测不报到的有179人,预测准确率为89.4%,模型的预测效果还不错,说明逻辑回归所建立的模型对预测新生报到情况有一定的指导作用。
4 总结
大数据小应用是当前大数据时代小企业、小单位对所拥有数据进行决策的出路,掌握预测性数据分析方法是正确在该道路上行走的基本技能。本文对方差分析、线性回归、逻辑回归、列联表分析、时间序列这五种常用的预测性数据分析方法的使用过程、使用场合及在招生中的应用进行说明,指出针对自变量、因变量不同数据类型该采用何种分析方法进行分析。为验证预测性数据分析方法的有效性,使用SAS EG6.1根据历年招生数据、报到数据建立新生报到模型,并使用该模型对2016年录取的考生进行报到情况预测,通过实际情况统计验证该模型的有效性,说明预测性数据分析方法在招生工作中能起到决策作用。
[1] 胡小明. 大数据应用的误区、风险与优势[J]. 电子政务,2014,(11):80-86.
[2] 李军.大数据:从海量到精准[M].北京:清华大学出版社,2014.
[3] 曹正凤.从零进阶!数据分析的统计基础[M].北京:电子工业出版社,2015.
[4] 田应福,张钊,朱晓坡. 方差分析的两个重要问题及其解决方法[J].统计与决策,2013,(16):7-9.
[5] 王胜.基于线性回归的适应性排名算法研究[J].计算机应用研究,2015,32(9):2684-2686.
[6] 刘力银.基于逻辑回归的推荐技术研究及应用[D]. 成都:电子科技大学,2013.
[7] 汤震,刘珂. 基于小样本时间序列的数据挖掘技术研究[J].微型电脑应用,2014,30(12):18-19.
ResearchontheApplicationofPredictiveDataAnalysisinCollegeEnrollment
Deng Guangbiao
(School of Mathematics and Computer Sciences, Guangxi Normal University for Nationalities, Chongzuo 532200)
While occupying the heights of the college enrollment in the era of big data, data analysis needs to be used to grasp the status of college enrollment. The method of the predictive data analysis can do some timely rectification for the problems found. The analysis results can forecast the future development, can help to make decisions based on data. Common predictive data analysis methods are introduced, and used to analyze the college enrollment. It establishes a predictive model for the freshmen’s enrollment by using the SAS EG, and predicts the 2016 freshmen’s enrollment. The validity of the model is verified by the comparison between the predictive data and the actual enrollment data.
Data analysis; Enrollment; Logistic regression; SAS EG
2015年度广西高校科学技术研究项目(KY2015LX539)
邓广彪(1982-),男,瑶族,广西荔浦,讲师,硕士,研究方向:数据挖掘、大数据分析.
1007-757X(2017)11-0020-04
TP311.13
A
2017.04.22)
