加权估计纹理分析结合高斯黎曼流形的人脸识别方法
2017-11-29梁传君卜宇王红梅新疆工程学院计算机工程系乌鲁木齐830011
梁传君, 卜宇, 王红梅(新疆工程学院 计算机工程系,乌鲁木齐 830011)
加权估计纹理分析结合高斯黎曼流形的人脸识别方法
梁传君, 卜宇, 王红梅
(新疆工程学院 计算机工程系,乌鲁木齐 830011)
针对图像集人脸识别中的子空间模型限制问题,提出了加权估计纹理分析结合高斯黎曼流形的人脸识别方法(WETA -GRMD)。使用样本图像和从样本获得的仿射包模型联合表示一幅图像。加权估计纹理分析进行人脸匹配,并解决权值最优化问题。利用高斯黎曼流形计算高斯分量具有识别能力的信息,并通过寻找最大判别分量识别人脸。在两个具有一定挑战性的数据集YouTube Celebrities(YTC)和YouTube Face(YTF)上的实验验证了提出方法的有效性,结果表明,相比其他几种较新的方法,提出的方法具有更高的识别率。
人脸识别; 高斯黎曼流形; 加权估计; 纹理分析; 仿射包模型; 特征提取
0 引言
与传统基于单幅图像的人脸识别相比,基于图像集的人脸识别[1]具有明显的不同,每个图像集包含很多属于某个人或某些人的表情图像或视频,即更多表情、不同视角或不同光照的目标人脸信息[2]。图像集为人脸识别提供了更多机会,但也为人脸识别带来了新的挑战,即利用他们的内部语义关系建模图像集,而小样本情况下的分类模型不能利用这些语义关系[3,4]。
图像集人脸识别可分为3类:基于线性或仿射子空间的方法[5-6]、基于非线性流形的方法[7-8]和基于统计模型的方法[9-11]。
格拉斯曼判别分析(Grassmann Discriminant Analysis, GDA)[5-6]在格拉斯曼流形上将图像集看作点(子空间),且使用基于特征角的格拉斯曼核完成流形上的差异性学习。因为图像集常常拥有大量图像且包含不同视角、光照和表情的变化信息,因此,基于线性或仿射子空间的方法很难获得令人满意的非线性人脸外观。
为了解决子空间模型的限制,文献[7-8]提出了流形-流形距离(Manifold-Manifold Distance, MMD)方法,利用一种更加复杂的非线性流形建模图像集,假设每种图像集符合非线性流形特征,即非线性能分割成许多局部线性模型,且流形间的相似性能转换为组合子空间之间距离的集合,但局部模型匹配精度有待进一步提高。
由于统计模型更加灵活,许多方法运用统计模型对图像集建模。例如,文献[9]使用单高斯函数和流形密度方法(Manifold Density Method, MDM)获得混合高斯模型(Gaussian Mixture Model,GMM),使用经典KL散度测量不同分布之间的距离。由于这两种方法是无监督学习方法,当数据集间存在较弱统计相关性时,该方法的识别性能波动较大。文献[11]提出一种协方差学习(Covariance Discriminative Learning,CDL)方法,通过二阶统计量建模图像集,即协方差矩阵,然后黎曼核函数在黎曼空间使用非奇异协方差矩阵学习差异模型,然而,文献[11]仅使用协方差信息,而协方差信息仅在表示数据相关性方面具有一定优势。
为了表示图像集中不同的图像,使用GMM描述这种变化,但GMM分布的差异还不足以完成分类任务。因此,提出了一种基于加权估计纹理分析结合高斯黎曼流形判别分析(WETA-GRMD)的方法。该方法通过不同高斯分布的距离差异,获取相应的正定概率核,该概率核能编码黎曼流形。
1 人脸集表示
使用样本图像和从样本获得的仿射包模型联合表示一幅图像,因为同时包括样本和结构信息,所以该联合表示更具鲁棒性。令Xc=[x1,x2,…xnc]表示第c个图像集,其中,xi是第i幅图像的特征向量,类的仿射包估计为式(1)。
(1)
也可使用其他参数形式表示为式(2)。
(2)
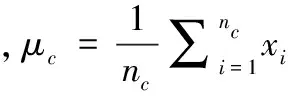
2 加权估计纹理分析(WETA)
2.1 人脸匹配
设人脸库中有许多两眼清晰且具有相同坐标的人脸图像,使用Sir表示第i个人的第r张人脸图像,将图像划分为B块大小相等互不重叠的图像小块。
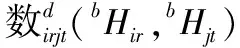
通过计算直方图距离判断2张图像是否为同一个人,如式(3)。
(3)
式(3)中,wb表示权值。
常见的相关反馈机制是基于对一组图像Q⊂χ的用户反馈处理[12],Q中的元素为处于前一步迭代中产生的排序为前w的元素,那些计算得到最高概率P(relevant|x)的元素作为与用户查询相关的元素。该过程导致了严重的有偏估计,并且获得的分值可靠性在整个特征空间上显著不同。
假设有一个新的随机变量reliable,可以在集合{true,false}上取值,这取决于x以及表达相关的后验概率P(relevant|x)。
如果reliable为真,则在给定点x的对应的相关估计认为是可信的。但是,如果reliable为假,则有关相关性的唯一信息则由P(相关)给定,而与x无关。如果可以得到可靠性信息,并且假设为独立的,则获得x相关性的正确概率为式(4)。
P′(relevant|x)=P(reliable|x)·P(relevant|x)+
(1-P(reliable|x))·P(relevant|x)
(4)
采用P(reliable|x)就可以同时解决人脸匹配引起的小样本规格和标记样本局域性问题了。这样一个概率函数的定义是限定在一定的范围内的,但是无疑在评估点x附近的样本密度时与其相关的。
2.2 权值估计
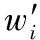
Dirjt=dirjtwT
(5)
假设2种图像对的协方差矩阵相等,则利用Fisher准则寻找最优权值为式(6)。
(6)
然而,式(6)并不符合从左到右的面部对称,若令bw=b+B/2w,权值则具有对称性,故将式(6)改写为式(7)。
(7)
因此,权值问题得到了解决。
3 高斯黎曼流形分类
C={(C1,y1),(C2,y2),…(Cn,yn)}
(8)
式(8)中,yi∈{1,2,…m}表示类的标签,m为类总数,矩阵Ci与l之间的相似性可定义为式(9)。

(9)
式(9)中,δ(·)是离散狄拉克函数,且Nl为式(10)。
(10)
式中,nl为训练的矩阵总数。
在流形上建立表示黎曼点的一组参考点Ci,i∈{1,2,…n},使用式(11)计算Ci,i∈{1,2,…n}与所有类之间的相似性,用相似模式表示每一个黎曼点Ci为式(11)。
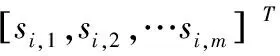
(11)
训练数据的相似向量表示为式(12)。
P={(p1,y1),(p2,y2),…(pn,yn)}
(12)
利用FLDA提取特征,得到映射W*为式(13)。
(13)
式(13)中,SB和SW分别表示类间散射矩阵和类内散射矩阵为式(14)、(15)。
(14)
(15)

将pq映射到特征空间为式(16)。
xq=W*Tpq
(16)
最后,利用最近邻分类为xq分配类标签,完成分类。
测试阶段,给定通过GMM建模的测试图像,首先计算高斯分量具有识别能力的信息。然后通过寻找所有可能判别高斯分量之间的最大分量识别人脸。算法1总结了本文判别分析(Discriminant Analysis,DA)算法的训练和测试过程。

算法1判别分析算法的训练和测试过程输入:GMM和训练图像集n幅图像的标签:G1,l1{},…,Gn,ln{}。Nk表示第k幅图像的高斯函数数量,g1,…,gn表示所有训练GMM的高斯函数,其中N=∑nk=1Nk;图像集Gte的GMM用于测试,使用gte1,…,gteM表示高斯分量。输出:测试图像集的标签lte。1:根据式(12)计算ktri=kgi,g1(),…,kgi,gN()[]T和ktej=kgtej,g1(),…,kgtej,gN()[]T,i∈1,N[],j∈1,M[];2:最大化式(16)计算变换矩阵;3:计算属于第k个图像集的Nk个高斯函数的映射zk1,…,zkNk,k∈1,n[];4:计算属于测试集的M个高斯函数的映射zte1,…,zteM;5:计算ztei和zkj之间的余弦相似性cosztei,zkj();6:计算^k=argmaxkcosztei,zkj(),对所有i∈1,M[],j∈1,Nk[];7:返回lte=l^k;
4 实验与分析
实验在配置为英特尔双核i3 CPU、2.98 GHz主频、4.0 GB内存的PC机上实现,编程环境为MATLAB 2011b。
4.1 数据库描述
实验使用两个具有一定挑战性的大型数据库:YouTube Celebrities(YTC)[14]和YouTube Face DB(YTF)[15]。为YTC和YTF的样本图像,如图1所示。
对这两个数据库,使用级联人脸检测器检测视频帧中人脸,然后归一化YTC人脸为20×20,YTF人脸为24×40。为了缓解光照的影响,对以上两种数据库获取的灰度人脸图像进行直方图归一化。

(a) YTC

(b) YTF图1 人脸库样本图像示例
4.2 不同数量高斯分量下算法性能比较
YTC上不同数量高斯分量时,本文方法的流形距离(manifold distance,MD)与识别率的曲线关系图,如图2所示。
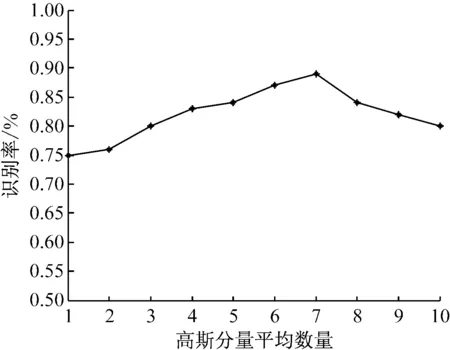
图2 不同高斯分量数量情况下,本文方法在YTC上的识别率
从图2中可以看出,对每个数据集,高斯分量的数量不同。高斯分量的平均数量没有必要是整数。实验结果显示,在合理数量高斯分量范围内,算法性能比较稳定。当高斯分量的平均数量约为7时,本文方法所获取的性能最佳。
4.3 实验结果和分析
比较的方法如下:
(1) 基于线性或仿射子空间的方法:GDA;
(2) 基于非线性流形的方法:MMD;
(3) 基于统计模型的方法:MDM、CDL[11]、CHISD[12]和SANP[13]。
除GDA和MDM外,原作者均提供了算法的源代码。为公平起见,根据原参考文献调整每种算法的主要参数。对所有这些算法,首先使用PCA降维,保留95%的数据能量。
YTC数据集:YTC包含47个个体的1 910个视频,使用10折交叉验证实验且从十折的每一折中随机选择三组训练数据和六组测试数据。本文数据库中总共有1 910组。由于数据集包括由3个不同像机拍摄的视频,因此,对每种视频分别采用十折交叉验证。
YTF数据集:YTF包含1 595个个体的3 425个视频,数据集设置与文献[15]相同。随机选择5 000个视频对,且这些视频中的一半来自于同一个体,另一半为不同个体。然后,将这些数据集分为10组且每组包含250个“相同”对和250个“不同”对。
在不同的实验设置下,通过减少集大小将本文方法与现有的先进方法进行比较,为查询和图库集大小设置上界m,当视频包含的帧超过m时,仅使用前m个进行训练和测试,如果视频包含的帧少于m,则使用全部帧。YTC和YTF上的错误率,如表1、表2所示。

表1 YTC上的分类错误率

表2 YTF上的分类错误率
从表1、表2中可以看出,当使用更多样本时,通常性能会更好,本文方法和SANP在完整视频序列上实现了完美分类,但是当减少集样本时,本文方法实现了最佳性能。CDL和CHISD的性能低于文献[11]和文献[12]给出的结果,因为调整图像集大小为20×20,而非40×40。
GDA、MDM和MMD在整长视频上优于CDL和CHISD,但是当集大小减小时他们的性能急剧下降。CDL和CHISD不能像前三种方法那样在大集上执行,但他们的性能不会急剧下降。SANP在整长视频上获得了完美分类,但不能像本文方法那样在较小集上执行。
几种方法在两个数据库上5倍实验时的平均错误率和相关的标准差,本文方法优于其他所有方法。如表3所示。
从表3可以看出,所有方法的性能在这个数据集上都相对较低,因为它包含姿态、光照和表情方面的大外观变化,且由于低质量视频中的跟踪误差,无法精确裁剪人脸。
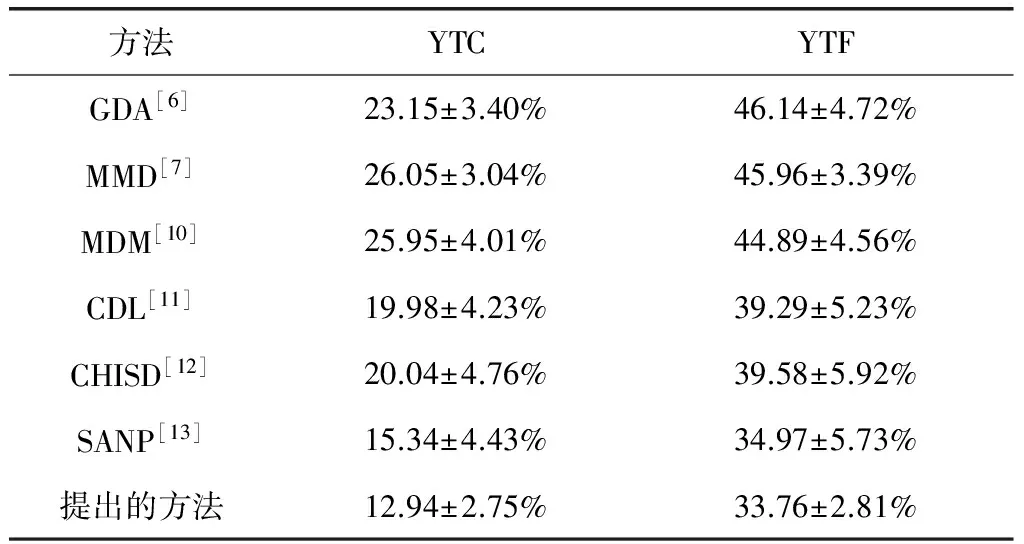
表3 平均分类错误率和标准差
4.3 分析
上述两个实验的CMC曲线(累积匹配特征),如图3所示。

(a) YTC
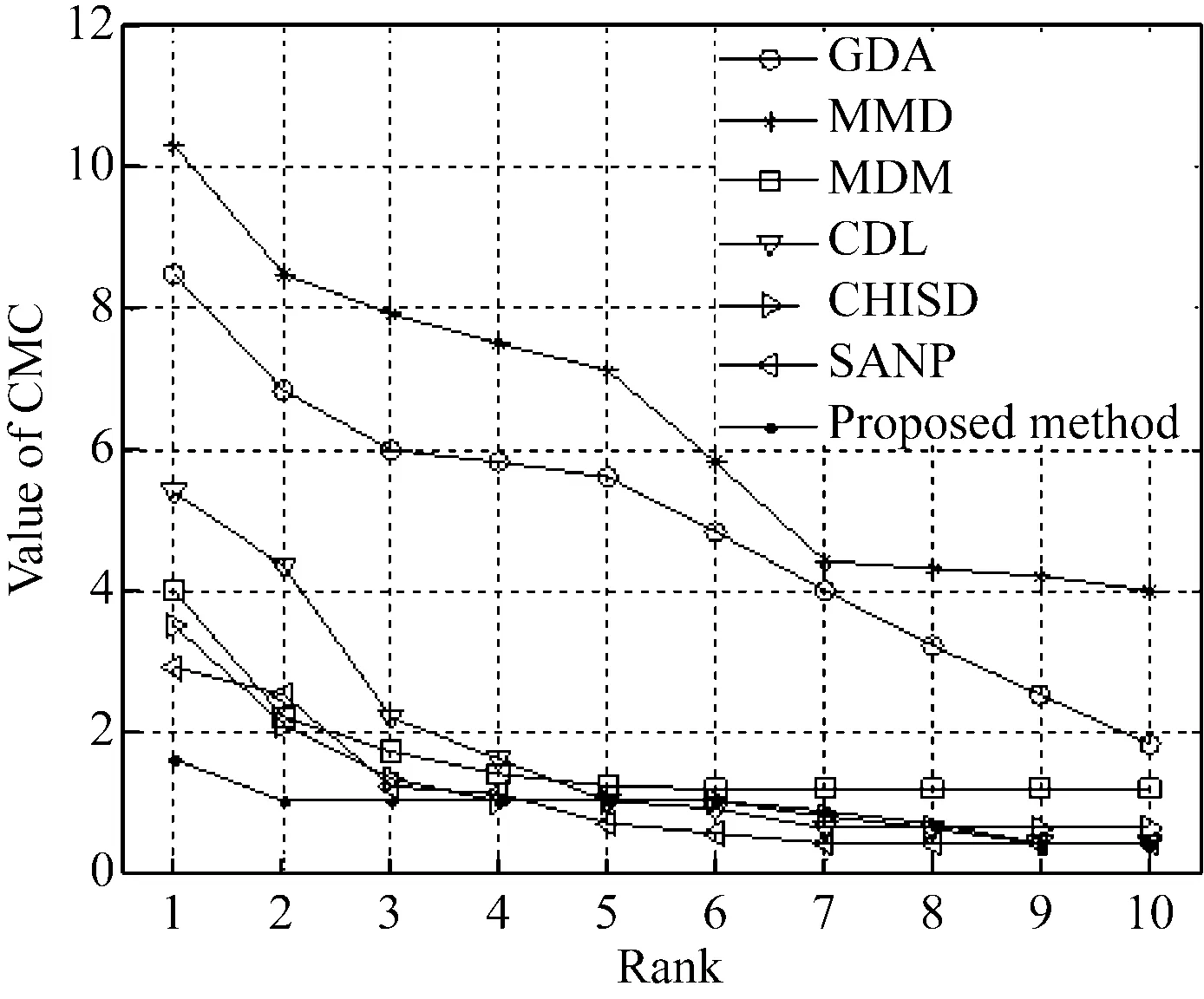
(c) YTF图3 错误率的CMC曲线(10倍结果)
本文方法在YTF数据上从rank 1到10、在YTC数据上从rank 1到4获得了最佳性能。本文方法在不同特征类型上能持续获得最佳性能,相对其他性能随特征类型波动的方法来说这是一个优点。
两个数据集上比较了所有方法的等差率(Equal Error Rate,EER),如表4所示。
在YTC和YTF数据集的情况下,分别给出了5倍实验时的平均EER和标准差,本文方法获得了最佳整体性能。

表4 YTC和YTF上的等差率
5 总结
本文提出一种用于图像集人脸识别的高斯黎曼流形判别分析方法,与传统在欧氏空间学习判别分析的方法不同,该方法在黎曼流形空间学习高斯分布。使用样本图像和从样本获得的仿射包模型联合表示一幅图像,使用加权估计纹理分析方法进行人脸匹配,利用高斯黎曼流形完成人脸分类。YTC和YTF上的识别结果表明,提出的方法识别率高于其他几种优秀方法。
未来将研究更多高斯分布的概率核函数和更加通用的用于高斯分布黎曼流形学习的方法。
[1] 顾伟, 刘文杰, 朱忠浩,等. 一种基于肤色模型和模板匹配的人脸检测算法[J]. 微型电脑应用, 2014, 30(7): 13-16.
[2] Yang A Y, Zhou Z, Balasubramanian A G, et al. Fast -Minimization Algorithms for Robust Face Recognition[J]. Image Processing IEEE Transactions on, 2013, 22(8): 3234-3246.
[3] 李雅倩, 李颖杰, 李海滨, 等. 融合全局与局部多样性特征的人脸表情识别[J]. 光学学报, 2014, 34(5): 515-520.
[4] Lu J, Tan Y P. Locality repulsion projections for image-to-set face recognition[C]// IEEE International Conference on Multimedia amp; Expo IEEE Computer Society, 2011: 1-6.
[5] Huang L, Lu J, Tan Y P. Co-Learned Multi-View Spectral Clustering for Face Recognition Based on Image Sets[J]. Signal Processing Letters IEEE, 2014, 21(7): 875-879.
[6] Alashkar T, Amor B B, Daoudi M, et al. A Grassmannian Framework for Face Recognition of 3D Dynamic Sequences with Challenging Conditions[M]// Computer Vision-ECCV 2014 Workshops Springer International Publishing, 2014: 326-340.
[7] Huang L, Lu J, Tan Y P, et al. Collaborative reconstruction-based manifold-manifold distance for face recognition with image sets[C]// Multimedia and Expo (ICME), 2013 IEEE International Conference on IEEE, 2013: 1-6.
[8] 于谦, 高阳, 霍静,等. 视频人脸识别中判别性联合多流形分析[J]. 软件学报, 2015, 32(11): 2897-2911.
[9] Arandjelovic O, Shakhnarovich G, Fisher J, et al. Face Recognition with Image Sets Using Manifold Density Divergence[J]. IEEE, 2005, 27(1): 581-588.
[10] 马龙. 基于多流形判别分析的单样本人脸识别研究[D]. 南京:南京理工大学, 2014.
[11] Arandjelovic O, Shakhnarovich G, Fisher J, et al. Face recognition with image sets using manifold density divergence[C]// Computer Vision and Pattern Recognition(CVPR), 2005: 581-588.
[12] Z. Cui, S. Shan, H. Zhang, S. Lao, and X. Chen. Image sets alignment for video-based face recognition[C]// IEEE Computer Society on Computer Vision and Pattern Recognition (CVPR), 2012: 1678-1684.
[13] Hu Y, Mian A S, Owens R. Face Recognition Using Sparse Approximated Nearest Points between Image Sets[J]. IEEE Transactions on Pattern Analysis amp; Machine Intelligence, 2012, 34(10): 1992-2004.
[14] 曾青松. 黎曼流形上的保局投影在图像集匹配中的应用[J]. 中国图象图形学报, 2014, 19(1): 414-420.
[15] L. Wolf, T. Hassner, and I. Maoz. Face recognition in unconstrained videos with matched background similarity[C]// In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2011: 1369-1374.
AFaceRecognitionMethodBasedonFusionofWETAandGaussianRiemannianManifold
Liang Chuanjun, Bu Yu, Wang Hongmei
(Department of Computer Engineering, Xinjiang Institute of Engineering, Urumqi, Xinjiang Uygur Autonomous Region, 830011, China)
In allusion to the subspace model limitation problem in the image set based face identification, the face identification method based on weighted estimation for texture analysis-Gaussian Riemann manifold (WETA-GRMD) is proposed in this article. Firstly, the sample image and the affine hull model obtained from the sample are combined to represent an image; then, weighted estimation for texture analysis (WETA) is adopted to execute the face matching operation and solve the weight optimization problem; finally, Gaussian Riemann manifold (GRMD) is adopted to calculate the information with identification capability in Gaussian component in order to find the maximum discriminant component for face identification. Meanwhile, the effectiveness of the proposed method is verified by the experiment in two challenging data sets YouTube Celebrities (YTC) and YouTube Face (YTF), and the result shows that compared with several other new methods, the proposed method has higher identification rate.
Face identification; Gaussian Riemann manifold; Weighted estimation for texture analysis; Affine hull model; Feature extraction
新疆维吾尔自治区高校科研计划青年教师科研启动基金项目(XJEDU2016S085);新疆工程学院科研基金项目(2015xgy101712)。
梁传君(1980-),女,硕士,讲师,研究方向:图形图像处理、模式识别等。
卜宇(1981-),女,讲师,硕士,研究方向:图像处理、模式识别等。
王红梅(1982-),女,副教授,硕士,研究方向:计算机网络及模式识别等。
1007-757X(2017)11-0015-05
TP391.4
A
2016.11.30)
