混合协同过滤算法中用户冷启动问题的研究
2017-11-28端德坤傅秀芬
端德坤,傅秀芬
广东工业大学 计算机学院,广州 510006
混合协同过滤算法中用户冷启动问题的研究
端德坤,傅秀芬
广东工业大学 计算机学院,广州 510006
在推荐系统中,用户冷启动问题是传统协同过滤推荐系统中一直存在的问题。针对这个问题,在传统协同过滤算法的基础上,提出一种新的解决用户冷启动问题的混合协同过滤算法,该算法在计算用户相似性时引入用户信任机制和人口统计学信息,综合考虑用户的属性相似性和信任相似性。同时,算法还在用户近邻的选取上做了一些改进。实验表明该算法有效缓解了传统协同过滤推荐系统中的用户冷启动问题。
协同过滤;推荐系统;冷启动;信任机制;用户聚类
1 引言
推荐系统[1]能够向系统中的用户推荐系统中的项目,最常用和最成功的推荐系统之一是协同过滤推荐系统。在协同过滤推荐系统中,两种类型的推荐系统被广泛研究:基于邻域方法[2]和基于模型方法[3]的推荐系统。基于邻域的方法集中于发现相似用户或者相似项目进行推荐,包括基于用户的方法和基于项目的方法,其中,基于用户的方法预测评分是基于相似用户的评分,而基于项目方法预测用户评分是找到当前用户评分项目相似的项目,然后对这些相似项目评分。而基于模型的的协同过滤方法与基于邻域的方法不同,基于模型的方法利用评分矩阵训练模型,这个评分矩阵可以用来解释评分矩阵中的数据,所以基于模型的方法是通过模型预测评分,而不是像基于邻域的方法那样直接操作原始评分数据。
传统推荐系统一直存在冷启动问题,包括新用户冷启动问题[4]和新项目冷启动问题[5],为了能够根据评分数据给用户推荐项目,处理冷启动问题普遍的策略是求助额外信息,将这些信息添加到评分矩阵中。这种方法在很多研究性论文中都有提供,他们大多数是基于混合推荐。下面分析一些混合法;文献[6]分析用户评分尺度及用户活跃度对项目相似性的影响,对混合模型进行了优化。文献[7]提出融合项目特征和移动用户信任关系的推荐算法。文献[8]根据信任度、相似度和关系度的混合权重,提出了一种基于信任传播的协同过滤算法。文献[9]提出一种网络结构和标签相融合的推荐算法,采用网络推荐算法模型和两种用户偏好模型进行组合推荐。文献[10]结合随机游走和K近邻算法,提出基于用户推荐互动的混合推荐系统。文献[11]根据全局信任网络和局部信任网络,提出一种基于信任的推荐系统。文献[12]提出一种利用朋友关系和用户标签的混合推荐系统。文献[13]为了解决用户冷启动问题,设计出一个基于分类的分布式混合推荐框架。
前面方法的策略主要是向评分矩阵中添加额外的信息,例如用户的概况,用户的标签,用户的作品等等。这些方法在一定程度上缓解了冷启动问题。但这些方法没有考虑用户没有评分,或者评分矩阵极度稀疏情况下,会导致这些混合推荐方法推荐质量下降。针对上述问题,论文提出了一种混合协同过滤方法(Hybrid Collaborative Filtering,HCF),在用户刚进入系统没有对项目进行评分,并且评分矩阵极度稀疏的情况下,该方法能够有效地缓解了冷启动问题,并且提高了推荐质量。
2 传统协同过滤算法
传统协同过滤算法首先需要获取用户对项目的评价信息,这些信息用一张二维表表示,如表1所示,表中包含m个用户和n个项目,表中每行代表每一个用户,表示为U={U1,U2,…,Um},每一列代表每个项目,表示为 j∈[1,2,…,n]。表中每一行与每一列的交点代表用户对项目的评分,这里用Rij表示,其中i∈{ }1,2,…,m ,j∈[1,2,…,n]。表中的缺省项表示用户Ui还没有对项目Ij评分。
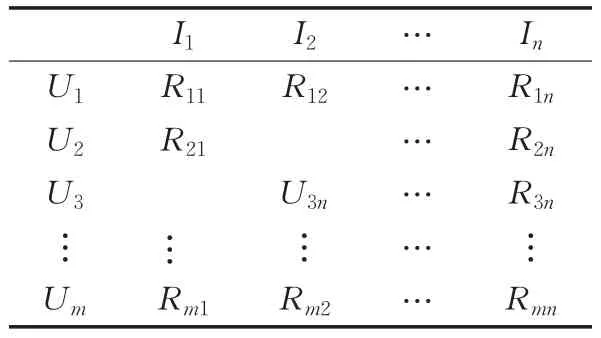
表1 用户-项目评分矩阵R(m×n)
传统协同过滤算法第二步是找到用户的相似邻居,有许多相似性计算方法,最常用的度量方法为皮尔逊相关系数(Pearson)、余弦相似度(Cosine)和修正的余弦相似度(Adjust Cosine)。这三种方法的计算公式如式(1)~(3)所示。
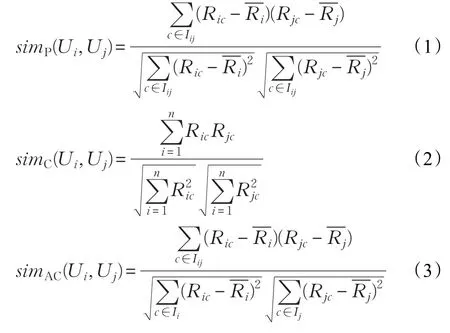
其中 simP(Ui,Uj)、simC(Ui,Uj)和 simAC(Ui,Uj)分别表示皮尔逊相关系数、余弦相似度和修正的余弦相似度,Ii和Ij分别表示用户Ui和Uj已评分过项目的集合,Iij表示用户Ui和用户Uj共同评分过项目的集合,Ric和Rjc分别表示用户Ui和用户Uj对项目c的评分,和分别表示用户Ui和用户Uj分别评分过的项目平均分。
通过分析这三个公式,这三个方法都需要根据用户共同评分的项目数计算用户间的相似度,而当用户刚进入系统时,用户对项目没有评分或者只有少量的评分,这样用户间只拥有极少数的共同评分,甚至没有共同评分,可以看出这两种方法计算出的结果不准确,不能真实地反应用户间的相似关系。
传统协同过滤算法最后一步是计算用户对未评价项目的评分,分数由相似邻居评分的加权平均数获得,计算公式如下:
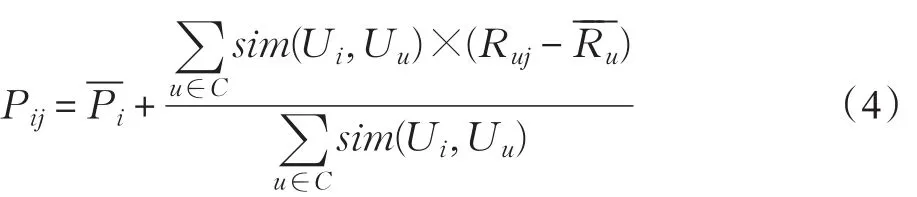
其中,sim(Ui,Uu)为用户Ui和Uu的相似度,Ruj为用户Uu对项目Ij的评分,和分别表示用户Ui和Uu对已经评分项目的平均分,C为目标用户Ui的近邻集合。
通过分析公式(4)可以看出,此方法需要知道目标用户对已评分项目的平均评分才能预测目标用户对未评分项目的评分。而对于新用户而言,新用户对项目可能没有评分或者只有极少数评分,不能真实地反应用户对项目的平均评分。所以传统的协同过滤方法不能有效地缓解用户冷启动问题。
3HCF算法设计
传统协同过滤算法不适合用户没有评分,或者评分矩阵极度稀疏的情况。针对这些缺点,HCF算法做了一些改进。
3.1 改进的相似度度量方法
当评分矩阵极度稀疏时,利用评分矩阵计算新用户与其他用户的相似度不能得到理想中的效果,或者得出的结果具有偶然性。文献[14]提出一种信任度与兴趣度相融合的方法来调整相似性计算。
如果用户Ui到用户Uj在社交网络图中无可达路径,那么非直接好友用户Ui和用户Uj的间接信任度ST(Ui,Uj)=0,如果用户Ui到用户Uj有一条以上的可达路径,那么非直接好友用户Ui和用户Uj的间接信任度,综上所述,非直接好友的间接信任度计算公式如下:

其中,n表示可达路径的最大长度,根据社交网络中有名的小世界理论,一个用户节点最多通过五个中间用户节点可以搜索到任意其他用户节点,因而n的取值范围定为2≤n≤6。r表示信任传播的衰减速度,取值范围为0<r<1,在信任传播过程中,路径长度每增加1,那么信任度就衰减r。Pi表示用户Ui到用户Uj可达路径集合。
由于直接好友的直接信任度为1,则间接好友的间接信任度因在[0,1)范围内,而上述公式计算出来的间接信任度的取值范围为[0,+∞),所以对上述公式做归一化处理,计算公式如下:
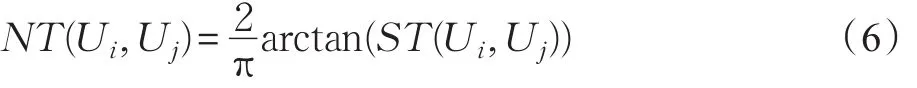
其中,NT(x,y)为归一化后用户x和用户y的间接信任度。
在利用式(1)计算用户兴趣相似度时,只考虑了用户间的共同评分数,但没有考虑用户共同评分的项目数,当simP(Ui,Uj)=simP(Ui,Uz)时,具有共同评分项数更多的用户之间相似度应该更大,对式(1)改进如下:

其中,|SUi,Uj|表示用户Ui和用户Uj的共同评分项目。
通过将用户兴趣相似度simr(Ui,Uj)与用户信任相似度simt(Ui,Uj)进行线性融合,得到用户融合相似度simhs(x,y),计算公式如下:
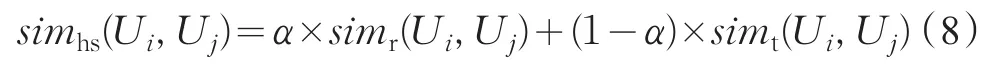
其中,如果用户x和用户 y的直接信任度不等于0,那么simt(Ui,Uj)=1,否则simt(Ui,Uj)=NT(Ui,Uj)。用户兴趣相似性simr(Ui,Uj)由式(7)中可得。融合相似度simhs(Ui,Uj)由式(8)得出。
但上述方法存在一定的不足,虽然在式(7)中对皮尔逊相关系数算法进行了一些改进,考虑了共同评分项数,但是当新用户刚进入系统时,新用户对项目的评分项数为0,那么新用户和所有其他用户的共同评分项都为0,这样,改进的方法和传统的方法没有本质的区别,都不能缓解用户冷启动问题。并且在式(8)的融合相似度算法中,融合兴趣相似度,并不能提高计算新用户的相似用户的正确性,当权重系数α越大,性能越差。
文献[15]提出用户属性聚类和改进的奇异值分解方法获取用户的近邻:


其中α+β+γ=1,E(Ui)表示用户Ui的特征值,A(Ui)表示用户Ui的年龄特征值,J(Ui)表示用户Ui的职业属性特征值,S(Ui)表示用户Ui的性别属性特征值,α,β,γ分别表示三个特征值的权重。
根据式(9)计算每个用户的特征值,然后利用改进的K-means聚类算法与该特征值对用户进行聚类,通过调整聚类中心得到最后的聚类簇,找到目标用户所在聚类簇,填充未评分项,并且将目标用户所在聚类簇的评分矩阵进行奇异值分解,最后利用皮尔逊相关系数算法计算用户最近邻。
上述方法也存在一定的弊端,在利用K-means聚类算法对用户进行聚类时,初始点的选取是随机的,初始点选取的好坏影响最后得到的聚类结果。并且该方法在解决冷启动问题上并没有考虑用户的信任关系。
根据式(8)和(9)中存在的不足。论文通过融合用户属性相似性和用户信任相似性来缓解用户冷启动问题给相似性计算带来的影响。对式(1)改进如下:
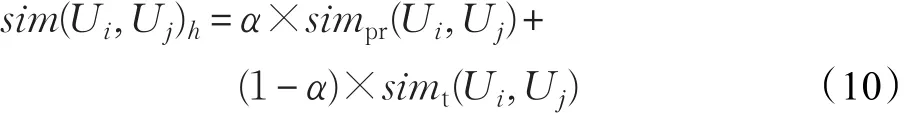
其中simpr(Ui,Uj)表示用户的属性相似性,simt(Ui,Uj)表示用户的信任相似性,α为权重系数,α∈[0,1],通过改变α值调节属性相似性和信任相似性的比重。
通过分析式(10),此算法计算相似度不受用户之间共同评分的影响。该算法通过解析用户之间的人口统计学信息和信任关系来计算目标用户与其他用户的相似度。无论刚进入系统的用户对项目是否有评分,或者仅有少量的评分,该算法同样适用。并且当评分矩阵极度稀疏时,对该算法计算相似度的正确性影响非常小。
3.2 改进的评分预测方法
对于刚进入系统的新用户,由于对任何项目都没有评分,或者只有少量的评分,在预测评分的算法式(4)中,的值或者等于0,或者等于有限对项目评分的平均值,这样不能反映用户对项目的真实平均分,导致预测评分不准确。
根据公式(10)计算出目标用户的相似用户,论文利用相似用户对项目评分的平均值作为新用户的平均值:
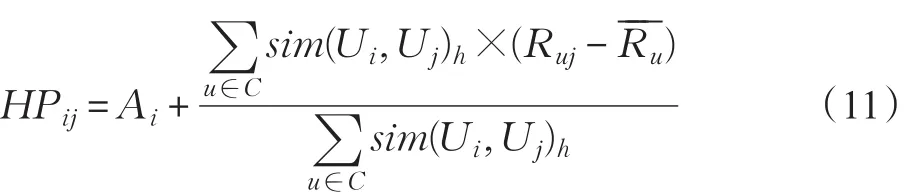
其中Ai为目标用户的相似用户的平均值,sim(Ui,Uj)h表示用户的混合相似度,HPij表示新用户对未评价项目的预测评分。
4HCF算法描述
4.1 用户属性值聚类
论文采用改进的K-means聚类算法进行用户聚类,传统的K-means聚类算法中心点的选取是随机的,而初始中心点的选取对聚类结果的正确性有很大的影响,论文考虑到拥有较多好友的用户具有一定的代表性,所以将这些用户作为初始聚类中心。该算法具体步骤如下:
步骤1从用户集合中选取直接好友最多的n个用户作为初始聚类中心,记为CCenter={cc1,cc2,cc3,c3,ccn}。
步骤2n个聚类都初始化为空,记为集合C={c1,c2,c3,c3,cn}。
步骤3对每个用户,计算用户特征值和聚类中心之间的距离,得到相似性最大的聚类中心ccm,将用户加入到相应的聚类中。
步骤4计算每个聚类中所有用户特征值的平均值,将平均值作为新的聚类中心。
步骤5重复步骤4和步骤5,直到聚类中心不再发生变化。
根据上述聚类算法获得N个聚类,在同一个聚类中的用户具有较高的属性相似度,不在同一个聚类中的用户具有较低的属性相似度。simpr(Ui,Uj)的计算方法为:若用户Ui和用户Uj在同一个聚类中,则令simpr(Ui,Uj)=1,否则另 simpr(Ui,Uj)=0。
4.2 信任相似度计算
步骤1输入目标用户Ui,信任传播的步长n和信任传播的衰减指数r。
步骤2根据社交网络中的直接好友关系建立社交网络图。
步骤3根据公式(5)计算用户Ui所有间接好友的间接信任度,并且根据公式(6)进行归一化处理。
4.3 融合相似度计算
输入 目标用户Ui,用户-项目评分矩阵R(m×n),用户属性相似矩阵 P(x×y),用户信任相似矩阵T(x×y),权重系数α,最近邻居个数k。
输出 目标用户的相似用户集合。
步骤1根据4.1节计算用户属性相似度simpr(Ui,Uj)。
步骤2根据公式(6)计算用户信任相似度simt(Ui,Uj)。
步骤3调整权重系数α,将α、simpr(Ui,Uj)、simt(Ui,Uj)带入公式(10)计算融合相似度sim(Ui,Uj)h。
步骤4重复步骤1至步骤3,计算目标用户u的相似用户集合S(u)。
4.4 评分预测
根据4.3节获得用户的融合相似度sim(Ui,Uj)h和目标用户的相似用户集合S(u),通过公式(11)计算用户u对项目i的预测评分HPui,并根据HPui对项目进行top-N排序,将评分最高的N个项目推荐给目标用户。
5 实验结果及分析
5.1 数据集
实验中使用的数据为新浪微博数据集。该数据集中有63 641个新浪微博用户信息,84 168条关于12个主题的微博信息,1 391 718条用户好友关系,27 759条微博转发关系,用户-项目的评分矩阵密度为:
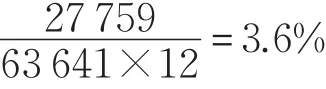
5.2 数据预处理
论文利用微博转发关系构建用户-项目评分矩阵,如果用户转发了其他用户的微博,则对此微博所属的主题评分为1,否则评分为0。
随机抽取80%的数据集作为训练集,剩余的作为测试集。由于新用户冷启动问题是用户没有对项目有过评分,数据集中不存在新用户评分信息,因此在进行实验的测试集中随机抽取100至500个用户作为新用户,训练集中对应的用户对项目的评分信息设置为0。然后对处理后的训练集和测试集进行实验。
5.3 实验方案
实验对HCF推荐算法中提出的信任相似度算法和HCF算法的有效性进行验证。其中,信任相似度算法和可达路径链接算法中的经典算法Resource Allocation[16](RA)算法进行对比试验。HCF算法其他一些经典的处理冷启动问题算法比较。
对于信任相似度算法的评价依据是top-N推荐中经常使用的F1-measure,其定义为:
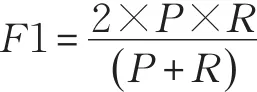
P表示查准确率(Precision),R 表示查全率(Recall),F1表示二者的调和平均数,其计算公式分别如下所示:
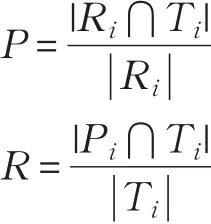
其中Ri表示对用户Ui形成的推荐列表,Ti表示用户Ui的测试集。
对于HCF推荐算法,论文采用平均绝对误差(Mean Absolute Error,MAE)作为度量标准,MAE的定义如下:
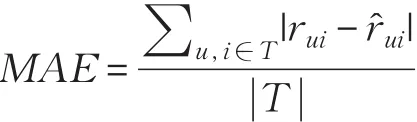
其中,T为测试集合,rui表示用户u对项目i的真实评分,表示用户对项目的预测评分。MAE值越小,说明推荐算法质量越高。
5.4 信任相似度算法与其他传播模型比较
实验首先确定最优信任传播路径长度n,n的值从2开始,每次增加1,直到n增加为6,实验结果如图1所示。

图1 传播路径长度对推荐准确性的影响
从图1可以看出,当路径长度等于3时,信任相似度算法的准确性最高,因此,在后续的信任相似度算法实验当中,设置传播路径长度为3。
确定了最优路径长度后,接下来的实验比较信任相似度算法和RA算法的性能,实验结果如图2。

图2 信任相似度算法与RA算法比较
从图2可以看出信任相似度算法优于RA算法,这是因为RA算法的传播路径长度为2,并没有考虑更长路径对性能的影响。
5.5 HCF算法与其他处理冷启动算法比较
为了验证HCF算法的有效性,实验先确定公式(10)中权重参数α,参数α用来调节用户属性相似度和用户信任相似度的权重,所以α的取值大小将会影响推荐效果。实验中α的取值从0开始,每次增加0.1,直到增加为1,实验结果如图3所示。
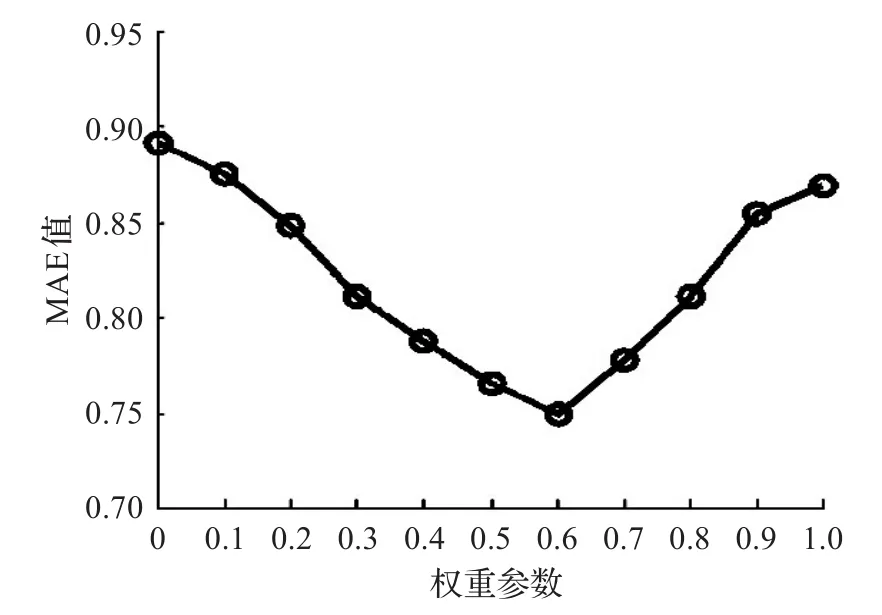
图3 调整权重参数α
从图3可以看出权重参数α取值为0.6时有最佳推荐效果。当α等于0.6时,用户信任相似度所占比例相较于用户属性相似度更大,这说明用户更加信任于关系更亲近的用户。
根据上述实验获取的权重系数α,下面实验将HCF算法与平均法、众数法和熵法[17]这些经典的处理冷启动问题的算法进行比较,新用户数K从100到500逐步递增,结果如图4所示。
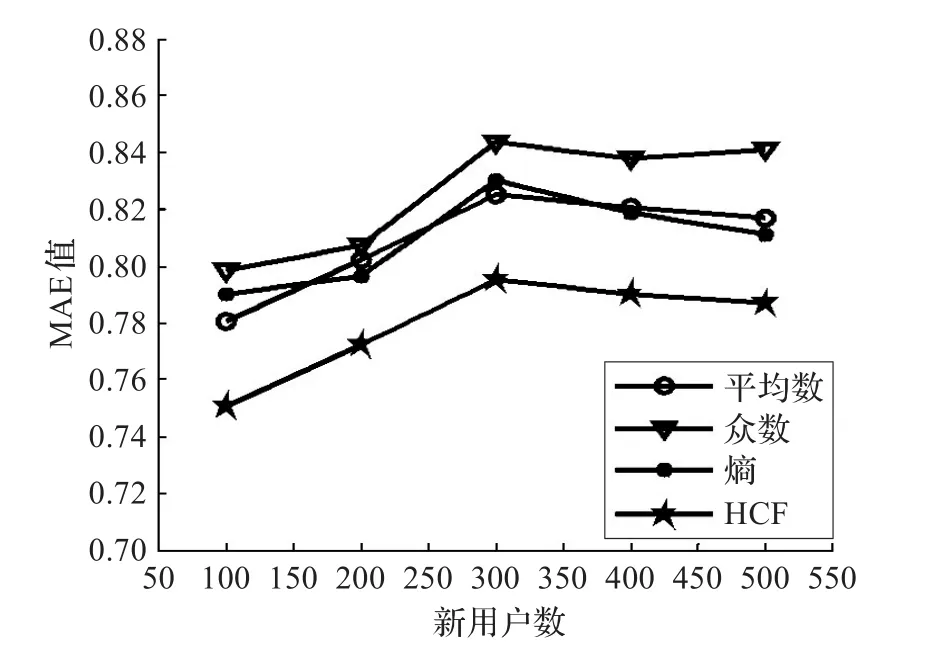
图4 几种算法的MAE值比较
从图4中可以看出,HCF算法比平均数算法、众数算法、熵算法的MAE值都要小,其次为平均数和熵算法,众数算法效果最差。且新用户数从100增加到300时,HCF算法的MAE值逐渐增大,当新用户数大于300时,MAE值趋于稳定。
6 结束语
在传统协同过滤推荐系统中,推荐系统操作新用户会有很大的困难。当新注册的用户没有对任何项目有评分时,用户就不能得到系统提供的个性化推荐。当用户只对很少的项目有评分时,由于评分的数量不够充足,传统协同过滤推荐系统也不能给出可靠的推荐。针对传统推荐系统中存在的用户冷启动问题,论文提出了一种混合协同过滤算法,该算法针对传统基于用户的协同过滤推荐系统没有考虑用户的社会化关系以及用户的人口统计学属性对计算用户相似性的影响,论文综合考虑用户的属性相似性和信任相似性的混合协同过滤算法。该算法不仅有效解决了传统协同过滤算法用户冷启动问题此外,而且缓解了数据稀疏性问题。实验表明该算法在一定程度上提高了推荐准确度。
在实际应用中,用户的兴趣可能受时间因素和空间因素的影响,在不同的时间或者不同的地点,用户的兴趣可能不同。下一步工作将在HCF算法中综合考虑时间和空间因素对计算用户相似度的影响,动态地获取用户间的相似度,以提高推荐质量。
[1]Ekstrand M D,Riedl J T,Konstan J A.Collaborative filtering recommender systems[J].Foundations and Trends in Human-Computer Interaction,2011,4(2):81-173.
[2]Bell R M,Koren Y.Improved neighborhood-based collaborative filtering[C]//KDD Cup and Workshop at the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2007:7-14.
[3]Liu N N,Yang Q.Eigenrank:A ranking-oriented approach to collaborative filtering[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2008:83-90.
[4]杨圩生,罗爱民,张萌萌,等.基于信任环的用户冷启动推荐[J].计算机科学,2013,40(z2):363-365.
[5]于洪,李俊华.一种解决新项目冷启动问题的推荐算法[J].软件学报,2015,26(6):1395-1408.
[6]李鹏飞,吴为民.基于混合模型推荐算法的优化[J].计算机科学,2014,41(2):68-71.
[7]胡勋,孟祥武,张玉洁,等.一种融合项目特征和移动用户信任关系的推荐算法[J].软件学报,2014,25(8):1817-1830.
[8]王维,吴清烈.基于信任传播的协同过滤算法[J].计算机工程与应用,2015,51(21):250-254.
[9]张新猛,蒋盛益,李霞,等.基于网络和标签的混合推荐算法[J].计算机工程与应用,2015,51(1):119-124.
[10]Zhang H R,Min F,He X,et al.A hybrid recommender system based on user-recommender interaction[J].Mathematical Problems in Engineering,2015:1-11.
[11]Zheng X L,Chen C C,Hung J L,et al.A hybrid trustbased recommender system for online comm-unities of practice[J].IEEE Transactions on Learning Technologies,2015,8(4):345-356.
[12]Tinghuai M A,Jinjuan Z,Meili T,et al.Social network and tag sources based augmenting collaborative recommend-der system[J].IEICE Transactions on Information and Systems,2015,98(4):902-910.
[13]Wang J H,Chen Y H.A distributed hybrid recommendation framework to address the new-user cold-start problem[C]//IEEE International Conference on Ubiquitous Intelligence and Computingamp;IEEE International Conference on Autonomic and Trusted Computingamp;IEEE 15th International Conference on Scalable Computing and Communicationsand ItsAssociatedWorkshops(UIC-ATC-ScalCom),2015:1686-1691.
[14]侯成龙.融合社会化关系的推荐算法研究与实现[D].北京:北京邮电大学,2014.
[15]巴麒龙.基于用户属性聚类和奇异值分解算法的推荐技术研究[D].北京:北京邮电大学,2013.
[16]Liao H,Zeng A,Zhang Y C.Predicting missing links via correlation between nodes[J].Physica A Statistical Mechanicsamp;Its Applications,2015,436(1):216-223.
[17]孙冬婷.协同过滤推荐系统中的冷启动问题研究[D].长沙:国防科学技术大学,2010.
DUAN Dekun,FU Xiufen
School of Computers,Guangdong University of Technology,Guangzhou 510006,China
Research on user cold start problem in hybrid collaborative filtering algorithm.Computer Engineering and Applications,2017,53(21):151-156.
In the recommendation system,user cold start problem is the problems existing in the traditional collaborative filtering recommendation system.Aiming at this problem,on the basis of collaborative filtering algorithm,a new hybrid collaborative filtering algorithm is proposed to alleviate cold start,when calculating the user similarity is introduced into the algorithm users trust mechanism and demographic information,comprehensive considering attribute similarity and trust of users.At the same time,this algorithm improves the neighbor selection of users.Experiments show that the proposed algorithm can effectively alleviate the cold start problem of traditional collaborative filtering recommendation system.
collaborative filtering;recommendation system;cold start;trust mechanism;user cluster
A
TP391
10.3778/j.issn.1002-8331.1612-0166
广州市科技计划项目(No.2014XYD-007)。
端德坤(1989—),男,硕士研究生,主要研究领域为推荐系统、数据挖掘,E-mail:15602320926@163.com;傅秀芬(1957—),女,教授,主要研究领域为网络多媒体、协同软件、网络安全。
2016-12-12
2017-01-16
1002-8331(2017)21-0151-06
CNKI网络优先出版:2017-04-14,http://kns.cnki.net/kcms/detail/11.2127.TP.20170414.1857.048.html
