基于区分深度置信网络的病害图像识别模型
2017-11-28宋丽娟
宋丽娟
1.西北大学 信息科学与技术学院,西安 710127 2.宁夏大学 信息工程学院,银川 750021
基于区分深度置信网络的病害图像识别模型
宋丽娟
1.西北大学 信息科学与技术学院,西安 710127 2.宁夏大学 信息工程学院,银川 750021
对枸杞病害进行及时、准确地检测识别对于病害的监测、预测、预警、防治和农业信息化、智能化建设具有重要意义。研究提出了一种基于区分深度置信网络的枸杞病害图像分类识别模型。首先,把枸杞叶部病害图像通过自动裁剪方式获得包含典型病斑的子图像,再采用复杂背景下的图像分割方法分割病斑区域,提取病斑图像的颜色特征、纹理特征和形状特征共计147个,结合区分深度置信网络和指数损失函数建立了病害识别模型。实验结果表明,该方法对于病害图像识别效果较好,与支持向量机相比,基于区分深度置信网络的病害图像识别模型高效地利用了底层图像特征的高层表示,解决了没有足够标注数据时的图像识别问题。
病害图像;区分深度置信网络;指数损失函数
1 引言
自然图像的识别和分类是充分挖掘自然图像中的底层特征,将不同类别的图像区分开来。针对不同的需求环境,出现了不同的图像识别和分类方法。Li等人提出了一种基于贝叶斯的增量学习方法,这种方法只需要很少的训练图片,在101类图像分类实验中取得了很好的结果[1]。Yu和Wong集成多个分类器分别利用不同的底层和高层抽象特征对图片进行分类,设计了一系列规则将多个分类器的结果进行汇总[2]。Lu等人给出了一个新的图像分类表示方式,首先用期望最大方法提取特征,然后用训练自适应增强(Adaboost)分类器选择最有区分性的特征[3]。范建平等人主要利用概念相关性来指导图像分类器的训练[4]。
在宁夏地区,枸杞病害不同时期、同一部位的病症多变、情况错综复杂,客观上存在很大的识别、预警困难,针对大田环境、复杂环境(叶片的遮挡和重叠、果实的倾斜和变形、多变的光照因素、杂草和泥土等)下的枸杞图像,背景信息量巨大,病害复杂程度高,枸杞病害叶片与健康(无病害)枸杞叶片之间的灰度差异不大等,如何有效地将病害目标和复杂背景分割开来是极具挑战的问题;而且,枸杞病害的生理信息机理决定了病害种类的规律性和稳定性,例如,在形态结构、尺寸大小、颜色纹理上的差异性很大,不存在两片完全一样的枸杞叶片;不存在两块完全相同的病害区域,不同的枸杞病害和同一种枸杞病害在不同的发病时期上所呈现出来的病理特征,从颜色、形状、纹理上也不尽相同,要想达到最好的病斑分割效果,就需要提取不同的枸杞病害在不同的病理时期的关键特征。传统的病害病斑图像分割多是基于聚类算法的方法[5-7],对于复杂背景下的病害分割分割效果不好。传统的图像识别方法不足以将病斑图像和复杂背景进行分离,利用病斑图像的多特征融合,构建复杂背景下的枸杞病害识别模型,具有重要的理论意义。
本文针对枸杞叶片病害的5类病斑图像,研究一种基于区分深度置信网络的枸杞病害图像识别和分类算法,高效地利用底层图像特征的高层表示。
2 病斑图像的特征提取和优化
在田间环境下采集具有典型症状病斑的枸杞叶片病害图像共计1 000张,其中65张白粉病图像、305张灰斑病图像、290张瘿螨病图像和340张炭疽病图像,获取的病害图像的分辨率为3 088×2 056像素。首先,对原始病害图像进行预处理,采用自动裁剪方法从每一张枸杞病害图像中裁剪出含有一个或多个病斑的子图像,然后采用复杂背景下的图像分割方法,分割效果如图1所示,得到枸杞叶片病害的5类病斑图像(包括无病斑图像)共计1 201张,对所有样本图像划分为训练图像集和测试图像集。

图1 复杂背景下的病斑分割
然后,充分挖掘枸杞叶片的5类病斑图像的特征信息,提取病斑图像的颜色特征、纹理特征和形状特征共计147个,其中颜色特征总计36个,包括R、G、B、H、S、V、L*、a*和b*共9个颜色分量的灰度图像的灰度均值m(9个)、方差σ2(9个)、标准差 s(9个)、偏度 S(9个)、峰度 K(9个)和熵ER(9个);纹理特征总计99个,包括R、G、B、H、S、V、L*、a*和b*共9个颜色分量的灰度图像的Hu不变矩(63个)、能量均值(9个)、惯性矩均值(9个)、相关均值(9个)和熵均值(9个);形状特征总计12个,包括偏心率、形状复杂性、圆形度、紧密度、矩形度和二值化病斑图像的Hu不变矩(7个)。下面给出一幅病斑图像的灰度均值如表1所示,方差如表2所示,标准差如表3所示,偏度如表4所示,峰度如表5所示,熵如表6所示。

表1 RGB、HSV和L*a*b*模型下枸杞病斑区域和无病区域的均值

表2 RGB、HSV和L*a*b*模型下枸杞病斑区域和无病区域的方差值

表3 RGB、HSV和L*a*b*模型下枸杞病斑区域和无病区域的标准差值

表4 RGB、HSV和L*a*b*模型下枸杞病斑区域和无病区域的偏度值

表5 RGB、HSV和L*a*b*模型下枸杞病斑区域和无病区域的峰度值

表6 RGB、HSV和L*a*b*模型下枸杞病斑区域和无病区域的熵值
为了避免不同特征的取值范围的差异对病斑类型识别的准确性的影响,需要对病斑图像的147个特征的取值范围进行归一化操作[8],使得各特征值均小于1,公式如(1)所示:

其中,Xi为第i个特征值,Xinormal为第i个特征的归一化值,Ximin为训练图像集中第i个特征的最小值,Ximax为训练图像集中第i个特征的最大值。
对枸杞叶片病害的5类病斑图像(无病斑、白粉病图像、灰斑病图像、瘿螨病图像和炭疽病图像)的147个特征进行归一化操作后,采用主成分分析PCA方法,把147个特征映射成50个综合特征,用这50个特征来反映病斑图像的信息,最终实现特征优化。
3 区分深度置信网络深层架构
3.1 区分深度置信网络
区分深度置信网络(Discriminative Deep Belief Networks,DDBN)是一个全连接定向的多层神经网络,如图2所示。

图2 区分深度置信网络架构
其中,包括一个输入层,N个隐藏层和顶部的一个类别标签层,输入层h有D个单元,等同于数据x中特征的个数,类别标签层有C个单元,等同于标签数据y中的类别数。W={ω1,ω2,…,ωN+1}是深层架构中需要学习的参数。X是一个样本数据集,表示为X=[x1,x2,…,xL+U]。其中,L是已标注图像的数量,U是未标注图像的数量,D是每个数据的特征个数,X的每一列是一个数据x。一个拥有所有特征的数据可以看作是空间RD中的一个向量,其中第 j个坐标对应第j个特征。
在区分深度置信网络深层架构中,定义能量状态(hk-1,hk)为:

hk-1发生的概率是:

其中Z()
θ是归一化常数。
hk和hk-1的条件概率是:

第t个单元为1的概率是包含hk-1和的逻辑函数:
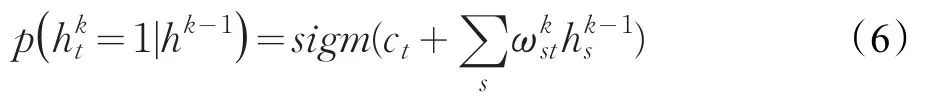
第s个单元为1的概率是包含hk和的逻辑函数:

其中,逻辑函数为:

对隐藏层产生的概率的对数相对于模型参数ωk进行求导,通过CD方法得到[9]:

最后,对参数ωk进行调整:

其中,ϑ是冲量,η是学习率。
计算得到参数ωk后,隐藏层可以在一个数据x从h0输入后,通过公式(11)得到hkt()x。

参数空间ωN是用服从正态分布的随机数初始化的。

3.2 损失函数
为了使用L个标注数据来优化参数空间W,从而使得区分深度置信网络深层架构具有更好的区分能力,即转化为优化问题:

其中

T为损失函数,合适的损失函数可以提高分类器的区分能力。常见的损失函数有对数损失函数、合页损失函数[10]和指数损失函数。
对数损失函数可以正确地分类数据,但是类别之间的分界线距离每个类别的优化目标位置很远,这样会出现过度优化,过度优化会增加错误分类点的个数。合页损失函数一般在数据分类边界线(x)=(x)比较近时会停止优化,是SVM的损失函数,如果有足够的支持向量,那么则该类优化可行。
本文的基于区分深度置信网络的病害图像识别分类器采用的是指数损失函数,运用指数损失函数的典型分类器是AdaBoost算法,指数损失函数在实际的数据集中表现良好[11]。指数损失函数的具体形式如下:

其中,r=hN(xij)yij,不同损失函数的比较如图3所示,本文所提出的分类器使用指数损失函数。

图3 损失函数的比较
4 基于区分深度置信网络的病害识别算法
针对没有足够标注数据时的枸杞病害识别问题,从病斑图像提取了颜色特征、纹理特征和形状特征等底层特征,通过底层特征的逐层特征变换,得到更加抽象的高层特征,从而发现更易于分类或预测的特征表示。
结合区分深度置信网络和指数损失函数,建立枸杞病害识别模型。建立的基本过程分为:第一步,构建深层架构,L+U个训练数据被用来寻找N层网络的参数空间{ω1,ω2,…,ωN-1} ;第二步,基于梯度下降方法的监督学习,利用反向传播机制将深层架构的参数空间进一步优化,使用共轭梯度算法对深层架构进行训练。所以,本文研究的是一种半监督学习方法,有效地将无监督学习的抽象能力和监督学习的区分能力相结合。
病害识别模型训练完成后,当输入一个新的病斑图像x,可以根据该模型的输出h的值来判断x所属的病斑类别。
4.1 病害识别算法流程
基于区分深度置信网络的病害图像识别算法流程如下所示。
病害图像识别算法流程
输入 样本图像集X,类别集Y,隐藏层h,层数N
每一层的单元个数D1,D2,…,DN,
迭代次数Q
参数空间W={ω1,ω2,…,ωN}
偏置b,c,冲量ϑ,学习率η
已标注图像的个数L,未标注图像的个数U
输出 包含训练后参数空间W的深层架构
1.构建深层架构
for k=1;k〈=N-1 do
for q=1;q〈=Q-1 do
for u=1;u〈=L+U do
计算非线性正向和反向状态:

更新参数和偏置:

end
end
end
2.基于梯度下降方法的监督学习

4.2 实验测试与分析
通过前期图像处理获得枸杞叶片病害的5类病斑图像共计1 201张,其中100张无病斑图像、75张白粉病图像、330张灰斑病图像、340张瘿螨病图像和356张炭疽病图像,病斑图像的样例如图4所示。

图4 病斑图像的样例
首先,对每一张病斑图像提取它的颜色特征、纹理特征和形状特征共计147个,然后通过特征优化得到每一张病斑图像的50个主要特征。选择标注图像数据时,标注的个数在2~75之间变化,确保每类病斑至少有一个标注数据。
实验中,每张病斑图像的分辨率是20×20,区分深度置信网络深层架构为50-50-50-200-5,表示输入层的结点个数为50,即输入每张病斑图像的50个特征,输出层的结点个数为5,即病斑类别为无病、白粉病、灰斑病、瘿螨病和炭疽病5类,三个隐藏层的结点个数分别为50、50和200。第一阶段,训练每一层的迭代次数为30,学习率为0.1,初始冲量为0.5,迭代5次后,冲量变为0.9;第二阶段,使用共轭梯度下降算法,迭代次数为20,每次迭代中使用3次线性搜索。
使用4.1节算法输入新的病斑图像x,可以根据该模型DDBN输出x所属的病斑类别,该分类器DDBN的分类性能与代表性的KNN、SVM[10]和NN[12]分类器相比较,使用不同数量的已标注图像来比较各个分类器的分类错误率。已标注图像的个数分别设为5、25、50和75,每类病斑至少有一个是已标注的。比较实验的结果如表7所示。

表7 不同分类器在不同数量的已标注图像的分类错误率%
在不同数量的已标注图像的分类器比较实验中,DDBN的分类结果总是优于其他的分类方法,在没有足够的已标注图像时表现出了稳定的、优越的分类性能。本文研究的识别模型不但表明了深层架构在自然图像识别任务中的有效性,也为深层架构解决困难的学习问题理论提供了实验验证[13-15]。
5 结论
本文结合区分深度置信网络和指数损失函数建立了病害识别模型,实现了枸杞病害图像的快速的、有效的识别和分类,首先对枸杞病害图像进行预处理,建立“白粉病”、“灰斑病”、“炭疽病”和“瘿螨病”四种病害类别的图像样本集,然后对图像样本集中各类别图像的颜色特征、纹理特征和形状进行提取和优化,建立区分深度置信网络深层架构,利用深层架构建立病斑特征与病斑图像类别之间的映射关系,本文研究的方法高效地利用了底层图像特征的高层表示,解决了没有足够的标注数据时的图像识别问题。
[1]Li F,Fergus R,Perona P.Learning generative visual model from few training examples:An incremental Bayesian approach tested on 101 object categories[C]//CVPR Workshop on Generative-Model Based Vision.New York,NY,USA:Elsevier Science Inc,2004:1-9.
[2]Yu Z,Wong H S.Image classification based on the baggingadaboost ensemble[C]//International Conference on Multimedia and Expo.Naples,Italy:IEEE,2008:1481-1484.
[3]Lu F X,Yang X K,Zhang R,et al.Image classification based on pyramid histoshoji tanaka,yuichi iwadate,seiji inokuchi and attractiveness evaluation based on the physical gram of topics[C]//International Conference on Multimedia and Expo.Piscataway,NJ,USA:IEEE,2009:398-401.
[4]Fan Jianping,Shen Yi,Yang Chunlei,et al.Structured max-margin learning for inter-related classifier training and multilabel image annotation[J].IEEE Transactions on Image Processing,2011,20(3):837-854.
[5]毛罕平,张艳诚,胡波.基于模糊C均值聚类的作物病害叶片图像分割方法研究[J].农业工程学报,2008,24(9):136-140.
[6]Omrani E,Khoshnevisan B,Shamshirband S,et al.Potential of radial basis function based support vector regression for apple disease detection[J].Measurement,2014,55:512-519.
[7]Dubey S R,Jalal A S.Fusing color and texture cues to identify the fruit diseases using images[J].International Journal of Computer Vision and Image Processing,2014,4(2):52-67.
[8]秦丰,刘东霞,孙炳达,等.基于图像处理技术的四种苜蓿叶部病害的识别[J].中国农业大学学报,2016,21(10):65-75.
[9]Chen E K,Yang X K,Zha H Y,et al.Learning object classes from image thumbnails through deep neural networks[C]//International Conference on Acoustics,Speech and Signal Processing.Las Vegas,Nevada,USA:IEEE,2008:829-832.
[10]Collobert R,Sinz F,Weston J,et al.Large scale transductive SVMs[J].Journal of Machine Learning Research,2006,7:1687-1712.
[11]Friedman J H,Hastie T,Tibshirani R.Additive logistic statisticalview ofboosting[J].Annals ofStatistics,2000,28:337-407.
[12]Mitchell T M.Machine learning[M].Columbus OH,USA:McGraw-Hill Science/Engineering/Math,1997.
[13]Bengio Y,Lamblin P,Popovici D,et al.Greedy layer-wise training of deep networks[C]//International Conference on NeuralInformation Processing Systems.Canada:NIPS Foundation,2006:153-160.
[14]Weston J,Ratle F,Collobert R.Deep learning via semisupervised embedding[C]//International Conference on Machine Learning.Helsinki,Finland:ACM,2008:1168-1175.
[15]Girshick R,Donahue J,Darrell T,et al.Region-based convolutional networks for accurate object detection and segmentation[J].IEEE Transactions on Pattern Analysisamp;Machine Intelligence,2016,38(1):142-158.
SONG Lijuan
1.School of Information Science and Technology,Northwest University,Xi’an 710127,China 2.School of Information Engineering,Ningxia University,Yinchuan 750021,China
Recognition model of disease image based on discriminative deep belief networks.Computer Engineering and Applications,2017,53(21):32-36.
To detect and identify the disease of Chinese Wolfberry in time and accurately is very important on the disease monitor,prediction,early warning,treatment and the construction of agricultural information and intelligence.The deep architecture of disease image classification and identification is proposed based on discriminative deep belief networks.First of all,this paper automatically crops the leaf disease image of Chinese Wolfberry into the sub-image containing typical spots,and then researches segmentation under complex background and the image feature extraction,the features is a total of 147 on color feature,texture feature and shape feature.Disease recognition model is established with discriminative deep belief networks and exponential loss function.Experimental results show that,the method has good effect on image recognition.Compared with the support vector machine,the disease image recognition model based on discriminative deep belief network not only can effectively use the high-level representation of low-level image features but also can solve the problem of data annotation image recognition.
disease image;discriminative deep belief networks;exponential loss function
A
TP391.4
10.3778/j.issn.1002-8331.1707-0506
国家自然科学基金(No.61363018);宁夏高等学校科学技术研究项目(No.NGY2014055,No.NGY2016016)。
宋丽娟(1978—),女,博士生,副教授,研究领域为图像处理与机器视觉,E-mail:slj@nxu.edu.cn。
2017-08-01
2017-09-30
1002-8331(2017)21-0032-05
