基于深度神经网络的搜索引擎点击模型构建
2017-11-27谢晓晖刘奕群马少平
谢晓晖,王 超,刘奕群,张 敏,马少平
(智能技术与系统国家重点实验室,清华信息科学与技术国家实验室(筹),清华大学 计算机系,北京 100084)
基于深度神经网络的搜索引擎点击模型构建
谢晓晖,王 超,刘奕群,张 敏,马少平
(智能技术与系统国家重点实验室,清华信息科学与技术国家实验室(筹),清华大学 计算机系,北京 100084)
随着富媒体展现形式被越来越多地引入搜索交互界面,搜索引擎的结果页面呈异质化和二维模块展现形式,这对传统的点击预测模型提出了巨大的挑战。针对这一情况,我们对实际搜索引擎结果页面的多模态结果进行了分析,构建了一个结合深度神经网络和点击模型的框架,该框架既包含了神经网络的特性,又利用了点击模型的预测能力。我们希望利用这个框架挖掘出多模态信息与文本信息之间的相关性,使之具有描述异质化结果和二维模块展示形式的能力。实验表明,我们的框架相较于传统的点击模型在点击预测性能上有显著提升,但由于搜索引擎的多模态结果内容复杂,仅利用多模态结果的底层特征,即使使用深度神经网络,从中能够挖据出的语义相关性较弱。
异质化结果;深度神经网络;点击模型
1 引言
根据2016年《CNNIC中国互联网络发展状况统计报告》的数据显示,到2015年12月为止,我国搜索引擎用户数量达到5.66亿。可见搜索引擎在互联网用户中的高普及率和其潜在的巨大商业价值,因此,在学术界和业界,搜索引擎都受到了极高的关注。在之前的工作中,搜索引擎结果相关度的计算有如下几种常用的方法。除了TF-IDF[1]等统计方法和利用互联网群体智慧来改善搜索结果相关度估计的方法[2],研究人员也从用户与搜索引擎的交互行为出发,提出了点击模型[3]对用户点击行为进行建模分析。
随着搜索交互技术的不断发展,富媒体展现形式被越来越多地引入搜索交互界面。从图1可以看出搜索引擎的结果展示页面呈现异质化趋势和二维模块展现形式。对原有流行的点击模型进行考察可以发现,大部分点击模型都针对的是同质化的搜索结果页面,无法描述和分析真实的拓扑结构。
在本文中,我们希望建立一个能够描述多模态结果的点击模型。其中,最大的难点之一是文本与多模态结果之间缺乏统一的衡量手段。经过前期的文献调研工作,我们了解到在已有的工作中[4],已经能够利用卷积神经网络框架,在搜索查询词和文本类型结果之间建立相似性函数,从而使得两者之间可以进行相关度分析。由这部分工作得到启发,对于多模态结果,我们考虑将其表征为矩阵形式,通过卷积神经网络进行特征提取和语义挖掘,使得异质结果之间能够进行比较。

图1 搜索引擎结果页面异质化结果
本文的研究任务包括:
① 建立点击模型,使之具有针对异质展现形式结果和二维排布结果的描述能力,重点分析图片和文本类型结果。
② 通过用户的大规模点击行为把图片和文本相关信息映射到同一个relevance相关的空间中进行比较。
③ 提高模型的点击预测性能和相关性排序性能。
本文的组织结构如下: 第2节介绍相关工作,第3节介绍本次实验所用到的卷积神经网络框架,第4节介绍本次实验的数据,展示实验结果并进行分析与讨论,最后一节我们将提出下一步的工作和设想。
2 相关工作
2.1 点击模型
点击模型是用于描述用户从开始搜索到结束搜索之间检验和点击行为的模型。大部分点击模型遵循了如下假设: 一个文档被点击需要同时满足该文档被用户浏览过并且该文档与查询词相关,并且这两个前提是相互独立的。如果我们用Ci=1来表示第i条结果被点击,使用Ei=1来表示第i条结果被浏览检验过,Ri=1来表示第i条结果与查询词相关(在有些工作中,以P(Ri=1)=ru来表示观测相关性的概率),符号“→”来表示满足某前提条件,则以上假设可以用如下公式进行表示。
根据这一假设,一个文档是否被点击的概率可以通过式(4)进行表示。
一些主流的点击模型没有将点击的顺序加以考虑,而是将点击行为简单地对应到搜索结果页面的结果排序上,这些模型被称为基于点击位置的点击模型。该类点击模型认为用户会沿着结果列表从上到下地顺序浏览,并且搜索页面的结果是同质的,即具有类似的展现形式,仅在内容相关度上有所区别。
级联模型[5](cascade model)是经典的基于点击位置的点击模型,该模型假设当某一用户沿着结果列表从上至下进行浏览时,他/她会立刻决定是否点击当前所浏览的结果,如果第i+1个结果被浏览则意味着第i个结果被浏览但未被点击,如式(5)、式(6)所示。可以看出,级联模型能够很好地描述仅存在一次点击的搜索会话,例如导航类搜索等,但对于更多的浏览点击行为,该模型将不具备较好的有效性。
针对级联模型存在的局限,依赖点击模型(DCM)[6]尝试对用户的多次点击会话进行建模,DCM假设一个用户在点击当前结果后有一定的概率继续浏览下一个文档,并且这一概率会受到结果在列表中位置的影响。DCM可以由如下公式进行描述。其中λi表示位置i的继续浏览概率。
随后,用户浏览模型(UBM)[7]进一步改进了检验假设,该模型假设一个结果是否被检验取决于之前被点击的结果位置和两者之间的距离,如式(9)所示。
动态贝叶斯网络模型(DBN)[8]是第一个将搜索结果摘要造成的展现偏置考虑在内的点击模型,该模型区分了实际相关性与察觉相关性,察觉相关性指由结果标题和摘要得出的相关性,实际相关性则代表结果主页的相关性。以Si表示用户对第i个文档是否满意,su表示该事件的概率,ru表示察觉相关性的概率,λ表示继续浏览的概率。DBN可以使用如下公式进行描述。
Wang等人首先提出了一个将结果文本信息考虑在内的点击模型[9],并且证明这部分信息对于点击模型是有效的,他们提出了一系列将文本信息和用户行为信息相结合的方法。
除了基于结果位置的模型之外,部分顺序点击模型(PSCM)[10]尝试将点击序列信息加入模型。PSCM模型基于眼动实验,提出了两个附加的用户行为假设: ①在两次点击之间的,用户会跳过其中的一些结果进行浏览;②在两次点击之间,用户倾向于沿着一个方向进行浏览。该模型将浏览顺序与结果位置进行了区分,并且表现出了比基于位置的点击模型更好的点击预测性能。
2.2 深度学习
2.2.1 深度学习框架对于文本的处理
在近期的研究中,深度学习方法被成功地应用于多个自然语言处理和信息挖掘任务中。通过使用深度学习框架,这些技术能够挖掘数据的高层次抽象信息和相应的特征。Salakhutdinov和Hinton等人使用深度网络改进了LSA模型[11],用于挖掘查询词和结果文档中的多层次语义结构。他们提出了一个语义哈希方法,该方法使用了从深度自动编码器学习到的瓶颈特征,主要用于信息检索。基于这部分工作,Huang和Shen[12-13]提出一个新的框架去构建一系列潜在的语义模型,能够将查询词和结果映射到同一个低维度的空间中,在该空间里面,查询词和文档的相关度以它们之间的距离来进行衡量。他们的深度语义框架模型以最大化给定查询词的文本点击的条件概率为目标,有区别地进行训练。
虽然上述工作在搜索任务的相关度预测上取得了良好的表现,但因为工作中的哈希过程基于英文字母的N元模型,所以想要进一步在非拉丁语系的搜索环境中扩展这些模型显得格外困难。因此,Liu等人提出了一个应用于广告推广搜索的卷积点击预测模型(CCPM)[14]。这个模型能够从包含多种元素的输入样例中提取出局部的关键特征,这一特性使得该模型能够应用于序列广告曝光任务中。然而,这个方法没有能够将结果的文本信息加以考虑。
Zhang等人提出了一个基于递归神经网络(RNN)的点击预测框架[15]。这个框架也是为广告推广搜索而设计,并且利用RNN 中的递归结构对用户的序列行为中的依赖性进行了建模。
Severyn等人也提出了一个深度学习框架,用于对短文本进行排序[16]。这个工作使用了已有的词向量结果对查询词和结果建立特征矩阵。在那之后,他们计算了查询词和结果之间的相关性,该模型的一个优势是它的框架能够直接引入一些附加特征,从而提升了学习的表现。然而这个框架没有将用户的行为习惯和基本假设加以考虑。
2.2.2 深度学习框架对于图片的处理
作为深度学习框架之一,卷积神经网络被广泛应用于图像识别任务中。基于图片自身的特性,卷积神经网络相比于普通的前馈神经网络[17]具有局部感知和参数共享的优势,这两个优势使得卷积神经网络能够极大地降低参数数量。
Krizhevsky等人在ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)-2012中使用改进的卷积神经网络模型[18]达到了15.3%的错误率。改进的模型由七个层次组成,前五个是卷积层(有一些采用了最大池化操作),后两个是全连接层。输出层由1 000个单元组成,分别对应1 000个图像类别。该框架中对神经元使用非饱和、非线性的激活函数,相比于常用的sigmoid 和 tanh激活函数,该激活函数的训练速度更快。
Lin等人构建了一个能够根据自然语言问题和图片,给出自然语言回答的卷积神经网络框架[19]。该框架的整体模型主要由三部分卷积神经网络组成,分别为图像的卷积神经网络、句子的卷积神经网络和整合前两者输出的卷积神经网络组成。
Wan等人[20]在多种设置下研究了卷积神经网络在基于内容的图片检索方面的性能,探究卷积神经网络是否能够填补低维图片特征和高维语义特征之间的“语义间隙”。发现在大规模图片数据中进行预训练后得到的深度卷积神经网络能够直接用于图片的特征提取,并且能够从图片的原始像素中得到高质量的语义信息。
在本次工作中,我们选择了卷积神经网络作为我们点击模型的框架,使用它来结合查询词文本信息、结果文本信息、垂直结果图片信息和用户行为。我们的框架主要有如下三个特点。
① 与现有的仅能预测单一信息的神经网络框架不同,我们的框架能够像传统的点击模型一样,同时预测点击概率,结果的相关度和用户的检验信息等。
② 通过把传统的点击模型训练结果作为附加信息加入到了框架中,我们能够将文本信息、图片信息和用户的行为信息进行结合。
③ 不同于现存的基于卷积神经网络的逐点学习策略,我们的框架能够从搜索返回结果页面中同时学习十个文本结果和四张图片结果,这种成对学习的方法有利于整体结果排序的研究。
3 基于深度神经网络的点击模型
在这一节中,我们将具体阐述我们的基于深度神经网络的点击模型。在该框架中,为了能够将深度神经网络与用户行为信息相结合,所有的特征(包括点击模型得出的检验概率和相关性分数等)会在连接层和隐层进行聚合和映射,模型框架如图2所示。

图2 基于深度神经网络的点击模型框架
3.1 输入层
3.1.1 句子矩阵构造
在前人的工作中,有许多生成基于文本的特征的方法。比如基于给定文本的N元字母构建的词语哈希方法[12]和使用给定文本文档的词向量方法[14],但正如我们在相关工作中提到的,N元字母方法不适用于非拉丁语系的语言环境。考虑到基本所有主流的商业搜索引擎都提供CJK(Chinese,Japanese,Korean)语言的服务,选择词向量的方法去生成句子矩阵显得更加合适。
在我们的工作中,我们使用了一个开源工具[21]在某商业搜索引擎超过 1 000万个网页中进行训练,获得了词向量数据集,每一个词向量的维度为100维。
3.1.2 图片矩阵构造
相比于文本内容,因为图片用其本身的颜色模型表示,在矩阵构造这方面相对比较简便。对于一张输入的实际图片,可以用多种不同的表示方式来描述图片信息,包括使用RGB三原色光模型、HSV圆柱表示法和灰度图等。对于RGB和HSV而言,由于其每一个像素点由一个三元组表示,所以其实际对应的为三个实数矩阵,为了方便处理,我们采用纵向拼接的方式将图片的三维表示降为两维表示。对于灰度图来说,其每个像素点本身就以一个实数进行表示,因此不需要进行额外处理。
3.2 卷积层
卷积层的用途是为了对文本和图片进行采样,从而提取出一些有效的特征。我们使用宽卷积来对句子矩阵和图片矩阵进行卷积计算。相比于窄卷积,宽卷积能够更好地保留文本和图片的边界信息。同时当卷积窗口大小大于被卷积矩阵时,宽卷积也能够保证给出合法的输出,这种鲁棒性在大规模数据中是十分重要的。
为了使得网络能够学习到非线性决策边界,每一个卷积层之后都会紧跟一个非线性的激活函数,这个激活函数会对卷积层输出的每一个元素进行操作。在神经网络中,前人的工作[22]显示修正线性单元能够克服sigmoid函数和双曲正切函数的部分缺陷,从而取得较好的表现。因此本次框架中,我们采用了修正线性单元f(x)=max(0,x)来对卷积层输出元素进行激活。
3.3 池化层
在大多数的深度神经网络中,有两种常用的池化操作方式: 平均池化操作和最大值池化操作。其中,最大值池化方法因为没有弱化强激活值的缺点,被广泛地使用。因为我们本次模型的目标是为了测试将点击模型和卷积神经网络结合后的效果,所以我们在模型中仅测试最大值池化策略。我们将其他的池化策略例如第K大值池化策略作为未来工作的一部分。
3.4 相似度计算层
在之前的操作中,我们的模型学习将输入的文本信息和图片信息映射成向量,这样的话我们就能够计算查询词和文本、图片结果之间的相似性。在池化操作环节后生成了查询词、结果文本内容、图片内容对应的向量,定义xq为搜索查询词对应的向量,xdi代表搜索引擎结果页面第i条结果标题内容对应的向量,xpi表示图片垂直结果中的第i张图片内容对应的向量,我们根据Bordes等人工作中提出的方法[23],可以通过如下公式计算各个向量之间的相似度和相互影响程度。
在这里,M是相关性矩阵,会在训练过程中不断更新。其中公式(13)~(14)是针对文本向量的公式,可以被看作机器翻译中的噪声信道法,这一方法作为打分模型,被广泛地应用在信息检索和问题回答任务中[24]。受公式(13)~(14)的启发,我们针对文本与图片、图片与图片定义了类似的相似度计算公式。
3.5 全连接层
全连接层的作用是为了将传统点击模型得到的用户行为信息加入到我们模型的框架中。全连接层对所有的中间向量进行了串联,包括查询词与图片对应的向量和两者之间的相似度分数,以及一些附加信息等。其中附加信息包含点击模型给出的检验概率和相关性分数,还包含了四张图片所在的结果在结果列表中的排序位置。
3.6 隐层
在全连接层得出的向量会经过一个隐层,该隐层使得全连接向量的组成元素之间可以进行交互。隐层通过式(17)进行计算。
在这里,wh是隐层的权重向量,α()是非线性变换。在经过隐层操作后,向量被传递给点击模型层,在点击模型层生成最终的点击预测概率。
3.7 点击模型层
点击模型层的节点被分为两部分,一部分代表检验,另一部分代表相关度。最后的点击概率使用大部分点击模型都会使用的检验假设得出:

检验概率与相关度通过一个sigmod函数,从输入特征中计算得出,如以下公式所示:
P(examination=1)=
P(relevance=1)=

虽然神经网络拥有强大的学习复杂决策函数的能力,它们在小规模数据集上也容易出现过拟合的情况。为了改善过拟合现象,我们增加了使用L2范数正则项的花销(cost)函数,作为网络中的节点。我们也采用了其他的正规化策略去约束检验节点和相关性节点所表达的物理含义。本次模型使用的花销函数如式(21)所示。
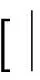
在这里,xexam和xrel是从xm中得到的检验和相关性的特征。Ce和Cr是用来平衡约束项的参数,在本次实验中,我们设置Ce=Cr=0.5。
这个模型的训练目标就是为了最小化花销函数的交叉熵(其中yi=0,1是实际点击的信息,θ向量包含了被该网络优化的所有参数),如式(22)所示。
Loss=cost+C‖θ‖2-∑[yilogP(clicki=1)+

4 实验结果与讨论
上述的模型能够应用于大多数基于概率图的点击模型,因此,本次实验我们选择了其中一种基于概率图的点击模型——用户浏览模型(UBM)来测试我们框架的性能。
我们采用点击概率预测得分(click perplexity)这一指标来评估点击模型的性能。点击概率预测得分是评价一个概率分布或概率模型对于测试样例的预测准确度,该指标值越低就代表该概率分布或概率模型对于样例的预测越精确[7,11]。预测点击概率得分可以用公式(23)进行计算。
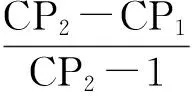
4.1 实验设置
在实验中,我们将使用其他几个基准模型与我们的模型进行比较。接下来的部分,本次工作的基于深度神经网络的点击模型将被简写为HDCM(异质化深度点击模型)。我们将对以下几个模型与HDCM模型的性能对比:
① 用户浏览模型(UBM)。这个基准模型主要用于考量合并了神经网络和点击模型后,整体的性能是否有所提高。
② 仅使用结果文本信息的HDCM(使用HDCM-text进行简写)。这个基准模型将主要用于比较合并了文本信息与图片信息和仅使用纯文本信息对于模型性能的影响。
③ 使用文本信息,同时将输入图片信息进行全零操作后作为输入的HDCM(使用HDCM-zero进行简写)。这个基准模型主要用于确认HDCM模型是否真正挖掘出了图片的语义信息。
④ 使用两层图片卷积层的HDCM(使用HDCM-double进行简写)。这个模型主要用于考察增加卷积层后是否有助于图片信息特征的提取。
在实验数据方面,我们采样了一个流行的商业搜索引擎的用户搜索日志。为了避免数据相关性带来的实验误差,我们在2016年4月和2016年5月之间以固定天数间隔采样了两个规模不同的数据集用于实验。并且和大多数点击建模工作一样,过滤了查询次数(查询会话数量)过多和过少的查询词。关于数据集的详细说明见表1。

表1 实验数据规模说明
4.2 不同图片规模对于模型性能的影响
由于用户在浏览搜索引擎结果页面时,对于多模态垂直搜索结果并不会进行全部查看,眼神覆盖范围可能只占据多模态的局部区域。同时,为了避免稀疏,在本次实验中,文本类信息结果的向量表示的维数为100维。因此太大的图片矩阵可能会在神经网络的训练中掩盖掉文本类信息的特征。所以我们在实际训练中,会选择对原始的大规格图片进行一定的压缩,但为此也可能会丢失一些关键的信息。所以,我们希望通过这一节的实验去探究图片规模对于模型性能的影响,考察随着图片大小的变化,模型的性能是不是也会有所变化。
在本节实验中,为了控制变量,我们对于图片类输入统一采用RGB三原色表示法。实验中使用了数据集1(包含4 647个查询),对UBM、HDCM-text、HDCM、HDCM-zero这四个模型进行了实验。在对实验数据进行预处理时,图片的放缩采用了立方插值法。表2展示了图片规模进行变化时,HDCM模型在perplexity这一指标上的性能变化。
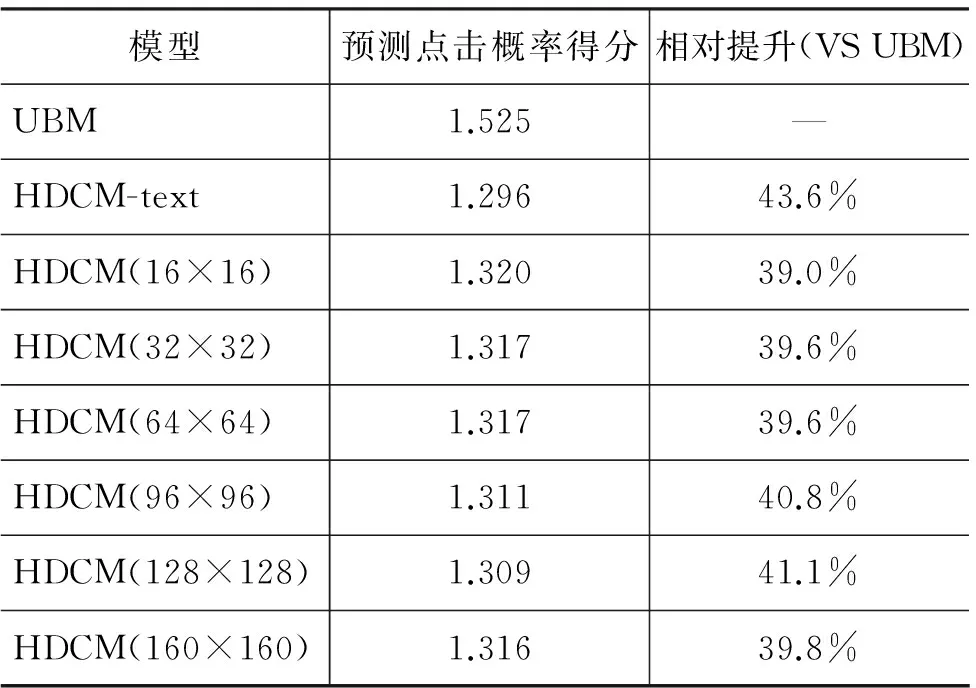
表2 不同图片规模下的模型性能
从表2可以看出,相较于基准模型UBM,HDCM在性能上有显著的提升,不管是仅考察文本结果,还是同时考察了文本和图片结果。同时,我们也注意到,使用不同的图片规模进行输入,对于HDCM而言,差别并不明显。并且从表中的数据可以看出,同时包含了文本和图片结果信息的模型相较于仅包含文本信息的模型,在性能上反而有所下降,这说明图片信息带来了一定的噪声,或者说对于当前的实验设置,我们的模型没有从图片信息中挖掘出语义相关性信息。为此,我们使用HDCM-zero模型对这一猜想进行了验证。
图3展示了HDCM模型在对图片输入进行全零化操作前后的性能对比。从图中可以看出,在所有图片规模下,使用实际图片对模型进行训练的结果比使用全零图片对模型进行训练的结果差,这说明对于这一数量级的训练数据,该框架很难从图片中挖掘出能够与文本建立相关性的特征。在接下来的实验中,我们将尝试使用其他的图片表示法进行实验,考察是否图片的其他的特性,例如亮度等,会对用户的浏览点击行为产生影响。
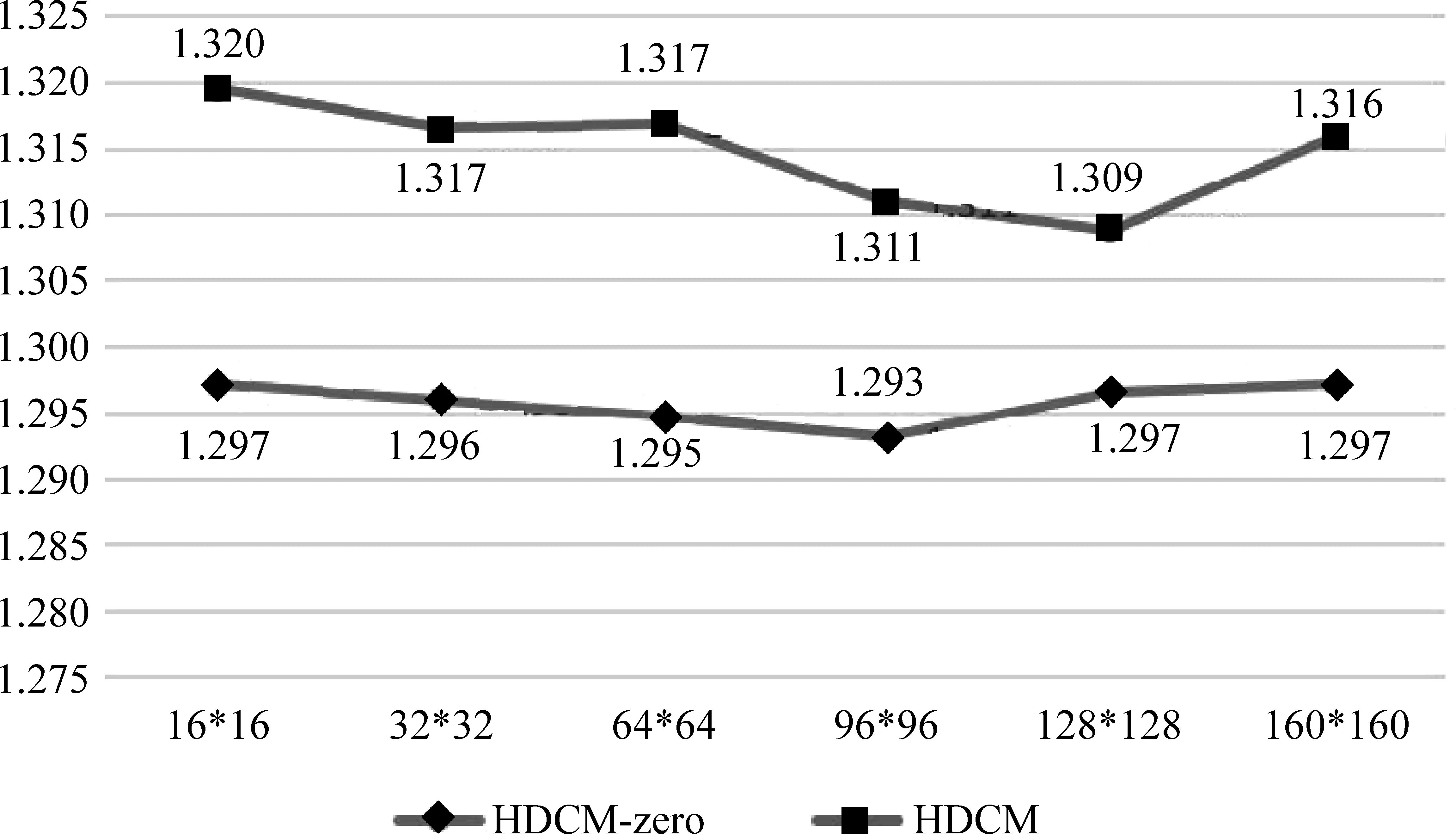
图3 实际图片输入与全零操作后的模型性能对比
4.3 不同图片表示法对于模型性能的影响
用户在浏览搜索引擎结果页面的时候,对于图片类垂直搜索结果,会根据图片内容判断是否与自己的查询意图相关再选择对该结果进行点击。同时,用户也会受到图片的亮度、明暗程度等的影响。这一节中,我们希望考察不同的图片表示法对于模型性能的影响。
在这一节的实验中,我们将图片规格全部统一为32×32。我们还对色相(H)、饱和度(S)、明度(V)三个维度单独进行了考察。同时,为了验证模型是否真正地挖掘出了图片与文本信息之间的相关性,我们也使用HDCM-zero进行了实验。
图4展示了使用RGB和HSV两种不同的图片表示方法时,HDCM模型的点击概率预测得分。图5展示了使用色相图、饱和度图、明度图和灰度图几种不同的图片表示法时,HDCM模型的点击概率预测得分。从图中可以看出,虽然我们的模型相较于基准的点击模型——用户浏览模型(UBM)在点击概率预测得分上有所提高,但是从HDCM与HDCM-text和HDCM-zero的结果比较中,我们发现,即使使用基于深度神经网络的点击模型,也很难从图片的底层基本信息中提取出强语义的特征。因此在之后的实验中我们将尝试增加图片的卷积层数,并尝试增加训练数据量,观察模型的性能变化。
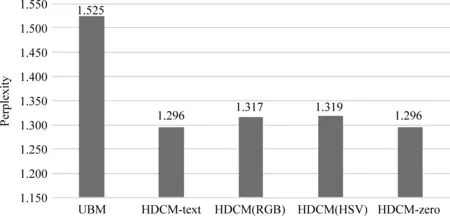
图4 RGB与HSV图片表示法对比
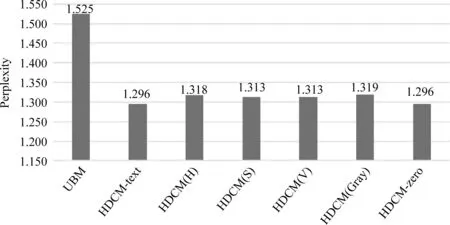
图5 色相图、饱和度图、明度图与灰度图表示法对比
4.4 不同卷积层数对于模型性能的影响
对于深度神经网络而言,一层卷积学到的特征一般是局部的,随着层数的增加,神经网络所能够学习到的特征就逐步趋于全局化。因此,我们在原有框架中增加卷积层数,希望能够得到图片更加丰富的特征信息。同时我们也在数据量上进行了增加,对比了数据集1(包含4 647个查询词)和数据集2(包含8 147个查询词),观察结果的变化。本节实验的图片输入规模均统一为32×32,图片均以RGB三原色表示法进行表示。
表3展示了这部分实验结果。对于两份采样的数据集,在对模型的图片矩阵处理模块增加卷积层数后,整体框架的性能相较于原本的仅有一个卷积层的框架并没有提升。并且,将图片输入矩阵进行全零化操作后,整体框架的性能反而变好,这说明即使使用了深度神经网络,在现有的实验设置下,也很难从图片的基本底层信息中挖掘出语义特征,换句话说,搜索引擎的结果图片内容与查询词的相关度关系较弱,通过现有框架很难在图片与文本之间建立相关性。
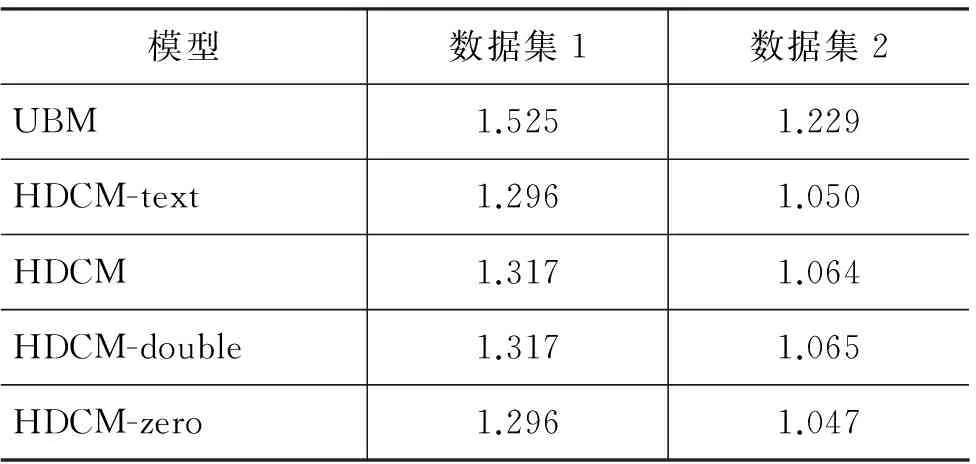
表3 图片采用双层卷积的模型性能对比
5 总结与未来工作
回顾本次的工作,我们首先考察了流行搜索引擎的实际用户浏览数据,并与实际搜索页面进行比对,确定了具有图片垂直结果的搜索词。然后根据提取的搜索词列表,使用动态网页抓取技术,进行实际搜索结果页面(SERP)的数据抓取。接着我们设计了一个结合深度神经网络和点击模型信息的框架,并对框架进行了代码实现,实验证明我们的框架相较于原点击模型在性能上有显著提升。
在第四节中,我们对比了不同的图片基础特征对于模型性能的影响,发现这些特征的变化对模型的影响很小。实验表明,直接应用图片的最底层特征,即使是在深度神经网络的框架下也很难与文本信息建立强相关性关系,可能是因为本论文的数据采自商业搜索引擎的实际用户行为日志所致。与以往的图片分类任务不同,实际的图片搜索日志存在查询词不规范、搜索目的模糊、图片搜索结果各异、结果质量参差不齐等问题,导致了查询结果中部分图片与查询词的相关性不高,从而在神经网络对于语义相关性的理解过程中产生了噪声。同时,不同用户之间对于符合查询需求的图片判断也存在差异,也使得框架的性能受到了影响。
在未来的工作中,我们将会尝试对图片使用更加复杂的特征提取方法。例如通过白化操作降低输入数据的冗余信息,更好地突出图片的边缘特征,更加类似于人眼对于事物的识别等。同时,我们也会进一步利用图片的点击信息。目前的点击日志信息,不针对具体的图片,使得对于用户在二维排布模块上的点击行为难以建模。在未来,我们会设计图片的点击实验,记录用户在二维模块上的浏览点击行为,同时比较被点击与未被点击图片之间的特征差异。
[1] Sparck J K. A statistical interpretation of term specificity and its application in retrieval[J]. Journal of documentation, 1972, 28(1): 11-21.
[2] Agichtein E, Brill E, Dumais S, et al. Learning user interaction models for predicting web search result preferences[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2006: 3-10.
[3] Chuklin A, Markov I, Rijke M. Click models for web search[J]. Synthesis Lectures on Information Concepts, Retrieval, and Services, 2015, 7(3): 1-115.
[4] Severyn A, Moschitti A. Learning to rank short text pairs with convolutional deep neural networks[C]//Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2015.
[5] Craswell N, Zoeter O, Taylor M, et al. An experimental comparison of click position-bias models[C]//Proceedings of the 2008 International Conference on Web Search and Data Mining, ACM, 2008: 87-94.
[6] Guo F, Liu C, Wang Y M. Efficient multiple-click models in web search[C]//Proceedings of the Second ACM International Conference on Web Search and Data Mining, ACM, 2009:124-131.
[7] Dupret G E, Piwowarski B. A user browsing model to predict search engine click data from past observations[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 2008:331-338.
[8] Chapelle O, Zhang Y. A dynamic bayesian network click model for web search ranking[C]//Proceedings of the 18th International Conference on World Wide Web, ACM, 2009:1-10.
[9] Wang H, Zhai C, Dong A, et al. Content-aware click modeling//The 23rd International World Wide Web Conference (WWW’2013), 2013.
[10] Wang C, Liu Y, Wang M, et al. Incorporating non-sequential behavior into click models[C]//Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 2013:283-292.
[11] Salakhutdinov R, Hinton G. Semantic hashing. International Journal of Approximate Reasoning, 2009,50(7):969-978.
[12] Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using click through data[C]//Proceedings of the 22nd ACM International Conference on Conference on Information and Knowledge Management, ACM, 2013: 2333-2338.
[13] Shen Y, He X, Gao J, et al. Learning semantic representations using convolutional neural networks for web search[C]//Proceedings of the Companion Publication of the 23rd International Conference on World Wide Web Companion, International World Wide Web Conferences Steering Committee, 2014:373-374.
[14] Liu Q, Yu F, Wu S, et al. A convolutional click prediction model[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, ACM, 2015: 1743-1746.
[15] Zhang Y, Dai H, Xu C, et al. Sequential click prediction for sponsored search with recurrent neural networks. arXiv preprint arXiv:1404.5772, 2014.
[16] Severyn A, Moschitti A. Learning to rank short text pairs with convolutional deep neural networks[C]//Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 2015:373-382.
[17] Bengio Y, Lecun Y. Convolutional networks for images, speech, and time-series[J]. The Handbook of Brain Theory amp; Neural, 1995(10):3361.
[18] Krizhevsky A, Sutskever I, Hinton G E. Image net classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2):2012.
[19] Lin M, Lu Z, Li H. Learning to answer questions from image using convolutional neural network[C]//Proceedings of the AAAI,2016,3(7):16.
[20] Wan J, Wang D, Hoi S C H, et al. Deep learning for content-based image retrieval: A comprehensive study[C]//Proceedings of the 22nd ACM International Conference on Multimedia. ACM, 2014: 157-166.
[21] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of Advances in neural information processing systems, 2013: 3111-3119.
[22] Nair V, Hinton G E. Rectified linear units improve restricted Boltzmann machines[C]//Proceedings of the 27th International Conference on Machine Learning (ICML-10), 2010:807-814.
[23] A Bordes, J Weston, N Usunier. Open question answering with weakly superised embedding models[M]. In Machine Learning and Knowledge Discovery in Databases. Springer, 2014: 165-180.
[24] Echihabi A, Marcu D. A noisy-channel approach to question answering[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2003(1):16-23.
[25] 刘龙飞. 基于卷积神经网络的微博情感倾向性分析[J]. 中文信息学报, 2015,29(6): 159-165.
[26] 孙晓, 何家劲, 任福继. 基于多特征融合的混合神经网络模型讽刺语用判别[J]. 中文信息学报,2016, 30(6): 215-223.

谢晓晖(1994—),博士研究生,主要研究领域为互联网搜索结果排序和用户行为建模。
E-mail: xiexh_thu@163.com

王超(1989—),博士,主要研究领域为互联网搜索结果排序和用户行为建模。
E-mail: chaowang0707@gmail.com

刘奕群(1981—),副教授,博士生导师,主要研究领域为信息检索与互联网搜索技术。
E-mail: yiqunliu@tsinghua.edu.cn
ASearchEngineClickModelBasedonDeepNeuralNetwork
XIE Xiaohui, WANG Chao, LIU Yiqun, ZHANG Min,MA Shaoping
(State Key Lab of Intelligent Technology and Systems, Tsinghua University, Beijing 100084, China)
With the rich media introduced into searching interface, the result pages of the search engine appear to be heterogeneous and in a form of two-dimensional distribution. To deal with this new challenge to traditional click model, we analyze the result pages of a popular commercial search engine and build a click model based on deep neural network, trying to reveal correlations between multimedia information and text information. This framework contains both the characteristics of neural network and prediction ability of click model. The experiment demonstrates that our framework is well improved compared to original click model. However, due to the complexity of multimedia contents, even deep neural network would produce quite weak semantic correlations if we rely merely on basic characteristics of multimedia results.
heterogeneous results; deep neural network; click model
1003-0077(2017)05-0146-10
TP391
A
2016-05-16定稿日期2016-12-26
国家自然科学基金(61622208, 61532011, 61472206);国家973计划(2015CB358700)
