译文语序的领域性思考:一种融合主题信息的领域自适应调序模型
2017-11-27刘梦眙姚建民
刘梦眙,姚 亮,洪 宇,刘 昊,姚建民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
译文语序的领域性思考:一种融合主题信息的领域自适应调序模型
刘梦眙,姚 亮,洪 宇,刘 昊,姚建民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
领域自适应研究的目标是建立一种动态调整翻译模型,使翻译模型对目标领域的语言特征具备较强的学习和处理能力,借以保证翻译系统在不同领域获得平衡可靠的翻译能力。现有翻译模型的自适应研究已经取得显著进展,但调序过程的领域适应性研究相对较少。在该文前期工作中通过对大规模源语言和目标语言的真实互译样本统计发现,在语义等价的短语级互译对子中,36.17%的样本在不同领域中的语序存在显著差异。针对这一问题,该文从主题角度出发,探索不同主题分布下的短语调序差异,提出一种融合主题信息的领域自适应调序模型。实验结果显示,嵌入调序适应性模型的翻译系统取得了较为明显的性能优势。
统计机器翻译;领域适应性;调序模型;主题模型
1 引言
通常认为,统计机器翻译(statistical machine translation,SMT)系统的性能很大程度上依赖于语料的规模和质量[1]。一般地,训练语料的规模越大、质量越好,则有效的翻译知识越多,涵盖的语言现象越充分,因而更有助于提升翻译系统中统计模型(翻译模型、语言模型、调序模型)的训练效果。
然而,当训练数据和测试数据所属领域不一致时,机器翻译系统的性能往往偏低。造成这一问题的核心原因是,语言现象在特定领域中具有一定的独立性,换言之,语义的收敛性和语用的多样性促成了不同领域文字表述的本质的差异,文法、修辞、术语、语序和惯用规则,都在特定领域有着明显的独立性,而在不同领域间有着可见的差异,这对双语之间的互译造成了一定影响。本文研究的主要对象,即为语序的领域特性,尤其是如何识别、模拟和应用这一特性,改进现有的机器翻译模型。
本文侧重研究利用主题信息提升调序模型领域适应性的可行性及方法学。这一探索源于如下经验性的发现: 主题的分布往往能够表现领域的特性,比如,法律领域的主题往往集中于“审判”“拘捕”和“罪行”等,自然科学领域则集中于“发现”“方法学”和“实验”等。而语言的组织(如语用形式、语序关系和语义表示形式等)往往与主题有着更为直接的联系。因此,我们提出一种基本的直推式假设: 领域→主题→语言组织→语序。通过这一间接推理,语序作为语言组织的重要组成部分,可通过与主题的关联程度和形式,决定其与特定领域的关系。这一点将成为支持本文方法学的核心,即利用主题信息调整翻译过程中的语序结果,以适应特定领域的文字特点。为了便于理解上述例子,下面给出了一对源语言(中文)和目标语言(英文)的语序样例,及其关联的主题和领域:
源语言: 保安 司 可 随时 指示 将 一个 根据 羁留 令 被 羁留 的 人 释放。
目标语言: the secretary for security may at any time direct that a person detained under a detention warrant be released.
[例1]
源语言: 可以 随时 根据 偏好 重新 排列 搜索 规则。
目标语言: you can reorder the search rules according to the preference at any time.
[例2]
上述是“at any time”在法律和科技领域下调序的一个实例。例1来源于法律条文,从例句中可以看出,“at any time”相对于前一个短语“may”,在源语言端对应的短语相对位置保持不变。此时短语“at any time”的调序类型是单调调序(M)。例2来源于科技文献,从例句中可以看出,“at any time”相对于前一个短语“preference”,在源语言端对应的短语相对位置进行了交换且间隔开了。此时短语“at any time”的调序类型是不连续调序(D)。基于此调序现象,本文利用法律和科技领域较大规模的平行文本进行统计分析,结果发现,“随时 at any time”在法律领域下单调调序(M)的概率为62%,而在科技领域下不连续调序(D)的概率为97%。从统计中可以发现,该短语对在法律领域下更倾向于单调调序,而在科技领域下更倾向于不连续调序。
从上述分析可以看出,短语调序受领域影响,在不同领域下短语调序的倾向不同。庞弘燊等[2]指出: 通过对某一领域文献的主题进行分析,是了解和评价学科领域发展的历史、现状和趋势的一种有效途径。可以看出,主题能够表现领域特性,上述法律领域的主题多集中于“失职”“释放”“审判”等;科技领域的主题多集中于“软件”“服务器”“计算机”等。因而本文猜测具有与特定领域对应性的主题分布,能够间接反映该领域中调序的特点,这就构成了本文通过捕捉主题信息,将其引入调序模型,让调序具备领域特点的基本动机。
基于上述现象,本文提出一种融合主题信息的调序模型领域自适应方法。其核心思想如下: 首先,利用主题模型估计不同领域下双语文档的主题分布;其次,利用极大似然估计的方法,获取不同主题下短语对的调序分布。最终在解码时,该方法借助待测文本的主题信息对短语对的调序概率进行加权,从而优化短语对的调序分布,以提升特定领域机器翻译系统的性能。基于NIST标准测试集的实验表明,本文所提优化调序模型的方法改进了机器翻译系统的性能,相比于基准系统,BLEU值提升了0.76%。
本文章节组织如下: 第二节介绍相关工作;第三节介绍传统调序模型;第四节描述融合主题信息的调序模型领域自适应方法;第五节给出实验结果和分析;第六节总结工作并提出展望。
2 相关工作
调序问题是统计机器翻译中的重要问题,常见的词汇化调序模型主要出现在短语模型中,包括基于词、基于短语、基于层次化短语的调序。近年来在调序模型上的探索不乏一些值得借鉴的工作: 冯洋等[3]认为正确地对介词短语进行调序对提高翻译质量至关重要,在层次短语模型基础上,利用条件随机场模型识别出介词短语,然后抽取带有介词短语的规则,构建新的同步上下文无关文法;何钟豪等[4]针对最大熵调序模型中短语调序实例样本分布不平衡的问题,引入集成学习多分类器融合的模型训练方法,发现通过性能加权投票融合的无放回欠采样的方法,相比于基线系统提升最为显著;肖欣延等[5]提出面向层次短语模型的词汇化调序方法,定义变量与邻接词语的调序关系,并使用变量所泛化短语片段的边界词信息来指导调序,解码时将此调序模型作为新特征融入基准系统中;Cao等[6]提出一种直接构建在同步文法规则上的词汇化的调序模型,对包含在文法规则里的每个目标端短语,计算其在文法规则下的调序概率,在解码时将该调序模型融入翻译解码器,提高了系统系能。
当训练数据和测试数据所属领域不一致时,机器翻译系统的性能往往偏低。统计机器翻译领域自适应研究大致包括如下两种思路:
(1) 领域相关数据选择
平行句对选择是翻译模型适应性研究中简单而有效的实施方法。当前,面向特定领域的双语文本往往比较匮乏,从大规模通用领域句对中选择与目标领域相关的平行句对,可作为扩充特定领域翻译模型训练数据的重要来源。Yasuda等[7]利用小规模目标领域双语语料,分别在源端和目标端训练语言模型,利用语言模型困惑度衡量通用领域平行句对和目标领域的领域相关性,进而选择相关程度较高的平行句对扩充目标领域训练数据,提升特定领域机器翻译系统的性能;Axelrod等[1]改进基于语言模型困惑度的句对选择方法,分别计算特定领域和通用领域的语言模型困惑度,并利用其差值评价句对的领域相关性;Duh等[8]首次应用深度神经网络语言模型代替传统的N-gram语言模型评价平行句对,进而选择句对扩充目标领域训练数据,取得较好的性能;王星等[9]提出基于分类的平行语料选择方法,特征采用双语词典翻译质量、翻译模型概率、语言模型、句子长度及未对齐词数量,利用少数句对特征差异较大的句对构建分类器,从而对其他未分类句对进行分类;Liu等[10]提出融合特定领域翻译模型和语言模型评价双语句对质量,有效地解决了基于语言模型方法选取的领域相关句对中存在翻译质量较差的问题。
(2) 统计特征优化。
Foster等[11]提出从短语特征层次出发,对来自不同领域的翻译模型进行线性或对数线性融合;Matsoukas等[12]通过计算通用领域句对和目标领域的领域相似程度,给句对赋予不同的权重值;曹杰等[13]提出一种基于上下文信息的翻译概率计算模型。该模型利用上下文相关的领域特征,重新估计双语短语的翻译概率,实现了领域信息和翻译知识的有效融合;Foster等[14]在前人的基础上从短语实例粒度考虑,为领域相关的短语实例赋予较高的权重,并重新估计翻译模型,提升了翻译性能;Su等[15]借助领域单语语料训练主题模型,并通过构建目标领域和通用领域主题映射,重新估计通用翻译模型的参数;Hewavitharana等[16]将测试文本与训练文档的主题相似度作为额外的翻译特征,以提升口语的翻译性能。Hasler等[17]通过改进LDA模型,提出推理双语主题模型的方法,并将其应用于计算主题适应的短语翻译特征。Chen等[18]首次进行了调序模型领域适应性的研究,提出将线性混合模型技术运用到调序模型领域适应性中,该方法为不同领域的子语料赋予不同的权重,以获取适应目标领域的调序模型。此外,Chen等[18]还通过平滑领域内语料和文档频率加权的方法提高了翻译系统性能。
上述研究仍存在以下不足: 首先,依据语料来源标签人工划分语料领域(例如,若语料标签为news-wire(新闻专线),则将其划分为新闻领域)。但新闻语料可能包含各种主题(体育、娱乐、政治等)的文本,因此,该方法在划分时过于泛化,缺乏对文本内容的分析。其次,该方法并不适用于测试文本来源未知的情况,即无法根据测试文本的变化动态优化调序模型。
针对上述问题,Wang等[19]在判别相邻短语的调序方向时,融入短语对所在文档的主题信息作为特征,将该特征加入最大熵分类器中,此外,还使用边界单词及单词主题作为特征。在解码时,将该调序模型融入统计机器翻译系统中,提升了翻译性能;Zhang等[20]提出一种基于结构化学习的判别式调序模型(discriminative reordering model,DRM),用以探索不同领域中调序特征的关联性,以使从通用领域中学习的调序规律更适应于目标领域,该模型挖掘不同领域共有的调序特征,并将这些特征融入翻译解码过程中。
受上述工作鼓励,本文尝试强化调序模型的适应性,但区别于将主题作为特征维间接干涉调序过程,本文利用主题分布概率计算调序概率,直接影响调序结果。
3 传统调序模型
利用不同语言对同一语义进行表述时,语序往往存在较大差异。就句子级的表述形式而言,句子结构迥异。调序模型用于对译文片段的相对位置进行建模,以生成符合常用语言表述习惯的译文。例如,中文“树上有只小鸟”,对应的英文译文为“there is a bird in the tree”。由此可见,互译的短语中“树(tree)”和“小鸟(bird)”的相对位置发生了变化。调序模型旨在将目标端译文短语重新排序,以满足目标语言的表述习惯。同样地,调序模型的训练也包括调序表的抽取和调序概率计算,表1所示为调序表样例。

表1 调序表样例
调序模型包括以下三部分: 源端短语(如上“上海 浦东 发展”)、目标端短语(如上“and pudong development”)、短语对调序特征得分(如上“-0.51 -1.61 -1.61 -0.51 -1.65 -1.63”)。其中,调序特征常根据具体情况而定,此处特征为短语模型中常用的MSD调序特征。词汇化调序模型由Tillmann等[21]首次提出,对任意一个短语对,这种调序模型考虑三种调序类型: 单调调序(M);交换调序(S);非连续调序(D)。
其中oi为M、S或D,概率以ai-1和ai为条件来确保方向oi与短语对齐一致,如式(2)所示。
因此,可以用以下三个特征函数对调序方向构建模型,每个函数对应一个调序方向。此处的短语对调序方向是相对于前一个短语对来确定的,分别对应表1中短语对的前三个特征,如式(3)~(5)所示。
除了上述的三种特征,也可以融入另外三个相似的特征(fM-b,fS-b和fD-b,分别对应表1中短语对的后三个特征)。这三个特征中的短语对调序方向是相对于后一个短语对来确定的,其中oi以(ai,ai+1) 为条件,而不是(ai-1,ai)。
4 融合主题信息的调序模型领域自适应方法
本文提出一种融合主题信息的调序模型领域自适应方法,该方法旨在解决测试文本领域未知的翻译问题,并利用文档主题分布动态优化调序模型。核心思想如下: 首先,利用主题模型估计包含不同主题的双语文档的主题分布;其次,统计短语对在每篇文档中以M、S或D为调序方向的次数,利用文档的主题分布对调序次数进行加权,从而获取不同主题下短语对的调序分布;最终在解码时,该方法借助待测文本的主题信息对不同主题下短语对的调序概率进行加权,从而优化短语对的调序分布,以提升跨领域机器翻译系统的性能。方法框架如图1所示。
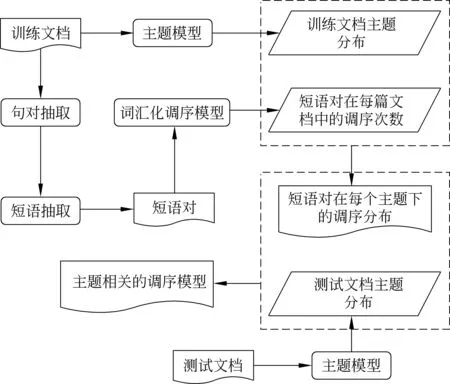
图1 融合主题信息的调序模型自适应方法框架
4.1 估计不同主题下短语对的调序分布
本文这一部分内容旨在量化同一短语对在不同主题下调序的差异性。借助于Latent Dirichlet Allocation(LDA)[22]主题模型,本文从规模较大的领域混杂平行文档中学习短语对的调序分布,并借助文档主题对调序进行优化。
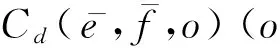
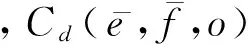
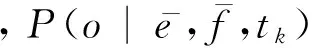
4.2 利用测试集文档主题分布优化调序模型
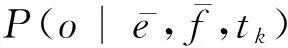

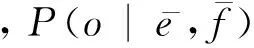
本文分别对部分调序特征及全部调序特征进行优化,旨在验证本文所提方法的有效性。部分调序特征包括: 短语对相对于前一个短语的调序方向(fM-f,fS-f和fD-f)、短语对相对于后一个短语的调序方向(fM-b,fS-b和fD-b)。
5 实验与结果分析
5.1 语料配置
为了验证不同领域下的短语调序分布存在差异,本文对法律和科技语料进行统计。其中法律语料来源于LDC香港平行文本法律部分(规模为: 400k句);科技语料来源于中国科学技术信息研究所英汉科技文献句子级对齐语料库(规模为: 600k句)。统计分析语料如表2所示。

表2 统计分析语料
①香港平行文本400k科技中信所英汉科技文献句子级对齐语料库600k①LDC2004T08香港平行文本法律部分。
本文实验使用NiuTrans[25]机器翻译引擎搭建汉英短语翻译系统。翻译模型训练语料是由LDC官方提供的英汉双语平行语料,本文过滤句子数少于10或大于50的文档(规模为: 933k句);语言模型训练语料取自LDC2005T12英语单语语料(规模为: 11m句);翻译系统的开发集使用2002年NIST MT公开测试集(NIST02),包含878个中文句子和对应4个英文翻译结果;翻译系统的测试集1使用NIST03,包含919个中文句子和对应4个英文翻译结果;翻译系统的测试集2使用NIST04,包含1 788个中文句子和对应4个英文翻译结果。机器翻译系统的语料如表3所示。
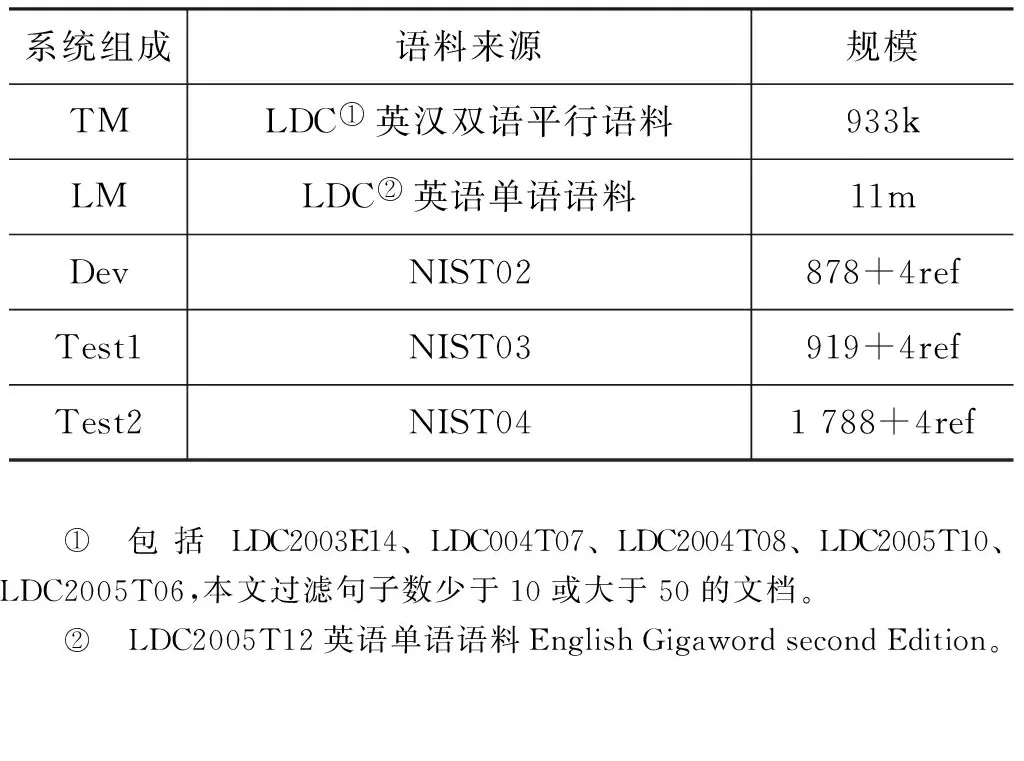
表3 机器翻译系统语料
5.2 系统配置
本文实验采用NiuTrans开源机器翻译系统,该系统融合GIZA++[26]工具实现双语句对词对齐,并从词对齐的平行句对中抽取短语翻译规则。本文采用SRILM[27]工具训练4-gram语言模型,并以传统MSD调序模型作为基线系统的调序模型,翻译系统模型权重采用最小错误率[28]训练方法获得,系统输出结果采用大小写不敏感的BLEU-4[29]值进行评价。本文设置如下五个翻译系统,以验证本文所提方法的有效性:
(1) Baseline: 搭建基于短语的翻译系统,包含翻译模型、语言模型、调序模型等特征。
(2) Hybrid: 实现文献[18]提出的基于混合模型的调序模型领域适应性方法,并搭建基于短语的翻译系统。
(3) LDA_a: 利用主题信息优化调序模型的全部调序特征,作为新特征融入短语翻译系统。
(4) LDA_f: 利用主题信息优化相对于前一个短语的调序特征(fM-f,fS-f和fD-f),将得到的调序模型作为新特征融入短语翻译系统。
(5) LDA_b: 利用主题信息优化相对于后一个短语的调序特征(fM-b,fS-b和fD-b),将得到的调序模型作为新特征融入短语翻译系统。
为了训练融入主题信息的调序模型,本文选用吉布斯采样方法推断LDA模型的参数,使用GibbsLDA++*http://sourceforge.net/projects/gibbslda/。开源工具来进行主题的估计和推断。本文在进行主题估计前去除了中文停用词(共558个),主题数目取20,超参数均设为0.05,迭代次数设为1 000。
5.3 实验结果及分析5.3.1 统计现象
为验证不同领域中短语调序分布存在差异这一猜想,本文对法律和科技领域的语料进行统计。本文只保留在两个领域下共现次数大于20的短语对,并分别计算两个领域下的调序分布RDlaw和RDtech。 本文用KL距离来衡量同一个短语对在两个领域下调序分布的差异性,KL距离计算如式(9)所示。
对符合条件的10 661个短语对根据其KL距离从大到小进行编号排序,做出如图2所示折线图,为了折线图显示效果,编号5000以后的点不在图中显示。其中,横坐标表示短语对的编号,纵坐标表示短语对的两个调序分布RDlaw与RDtech之间的KL距离。
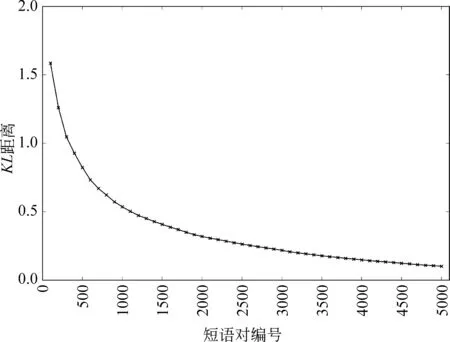
图2 短语对的调序分布差异——KL距离折线图
其中,编号3856的短语对为“效果 effect”,其在两个领域下的调序分布如表4所示,分布的KL距离为0.157 1,三个概率值分别表示短语对以M、S或D进行调序的概率。从表中可以看出,该短语对在法律领域下更倾向于单调调序(M),而在科技领域下更倾向于不连续调序(D)。KL距离越大,短语对在两个领域下的调序分布差异越大。那么,KL距离大于0.157 1的短语对调序分布差异更加明显,所占比重为36.17%(3 856/10 661),故至少36.17%的短语对在不同领域的调序存在差异。
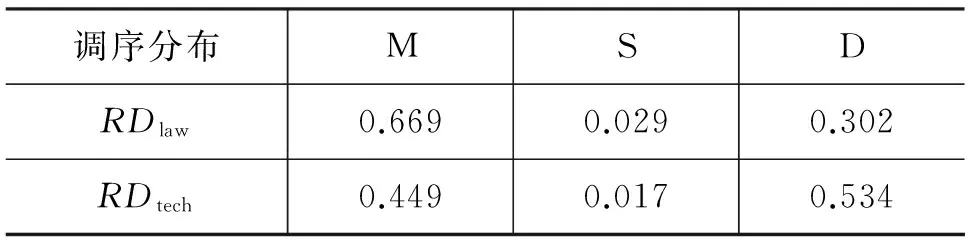
表4 短语对“效果 effect”在两个领域下的调序分布
此外,从语料中也可以发现短语对“效果 effect”在两个领域下的不同调序现象,如表5所示。目标端短语“effect”相对于其前一个短语“possible”,在源语言端对应的短语(“可能”“效果”)相对位置保持不变,故此时的调序类型是单调调序(M);而在科技领域下,目标端短语“effect”相对于其前一个短语“display”,在源语言端对应的短语(“显示”“效果”)相对位置发生了改变,不再保持连续,故此时调序类型是不连续调序(D)。
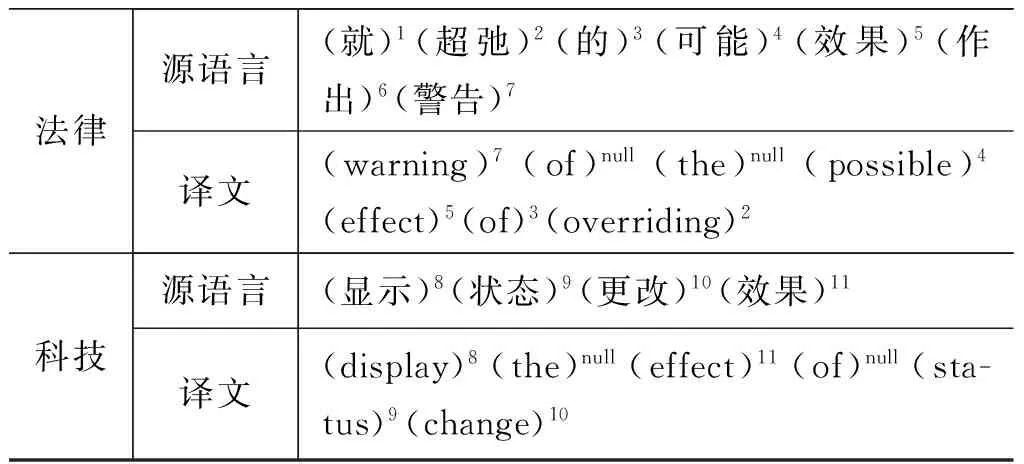
表5 短语对“效果 effect”在不同领域下的调序现象
综上所述,至少36.17%的短语对在不同领域的调序存在差异性,本文针对这部分短语对的调序分布进行优化,融入短语所在文档的主题信息,以期提高翻译系统的性能。
5.3.2 实验结果与分析
本文搭建汉英机器翻译系统,并基于最小错误率训练方法调节特征权重,最终解码得到翻译结果。本文构建的五个翻译系统(Baseline、Hybrid、LDA_a、LDA_f、 LDA_b)性能如表6所示。实验结果表明, 优化调序模型的翻译系统相比于原始的翻译系统(Baseline),在测试集上性能均有提升。其中优化
全部调序特征的翻译系统(LDA_a)性能最好,相比于基准系统(Baseline),在NIST03上提升了0.76%,在NIST04上提升了0.38%;而优化部分调序特征的翻译系统性能则不如优化全部调序特征的翻译系统(LDA_a),其中优化相对于前一个短语对的调序特征的翻译系统(LDA_f),相比于基准系统(Baseline),在NIST03上提升了0.55%,在NIST04上提升了0.33%;优化相对于后一个短语对的调序特征的翻译系统(LDA_b),相比于基准系统(Baseline),在NIST03上提升了0.38%,在NIST04上提升了0.28%。综上所述,本文提出的利用主题信息优化调序模型的方法是有效的。原因在于,本文方法能充分考虑不同主题下调序的差异性,并根据测试文档的主题分布动态地进行优化,以获得最佳的调序效果。同时,调序的性能会最终影响整体的翻译效果,达到提升翻译性能的目的。
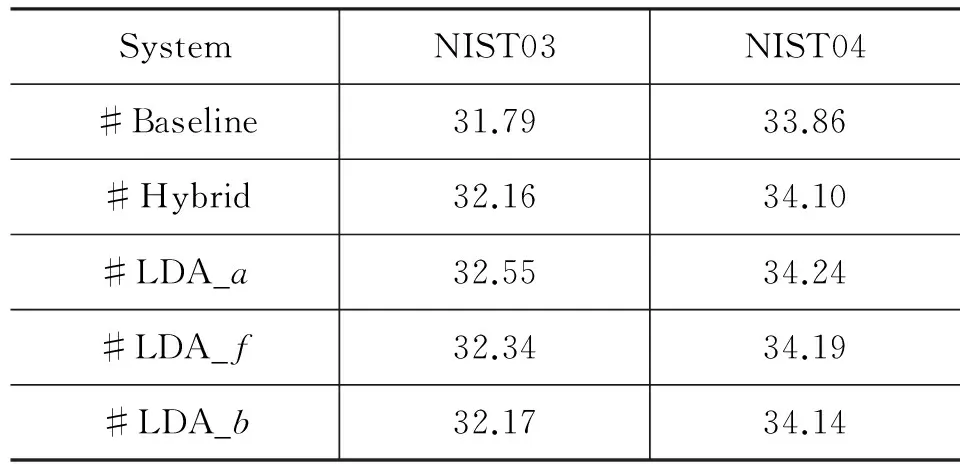
表6 机器翻译系统性能
另一方面,与Chen(2013)提出的基于混合模型方法优化调序模型搭建的翻译系统(Hybrid)相比,性能也有一定的提升。从表6可以看出,LDA_a在NIST03上比Hybrid提升了0.39%,在NIST04上提升了0.14%;而优化部分调序特征的翻译系统(LDA_f、LDA_b)在测试集上性能也有所提升。该部分实验结果表明,人工粗略地根据语料来源和文体进行领域划分并不是最优的,借助主题模型进而利用主题信息进行领域的区分相比于人工的方法更加的精确,且减少了人工标注需要的工作量。 表7为一个中到英的翻译实例,分别由本文所搭建的Baseline和LDA_a翻译所得。

表7 一个中英翻译实例
从表中可以看出,“海牙 法庭 医疗 小组”的翻译,LDA_a与参考译文基本一致,“海牙 法庭”的英文翻译调序到“医疗 小组”的后面。从词汇化调序模型的观点来看,调序方向是交换调序(S)。而在Baseline中,对“海牙 法庭”进行了顺序翻译,没做任何调序,反而将人名“波贝特克”错误地调序到“医疗 小组”前面。此外,对于“确认 波贝特克 的 病情”的翻译,LDA_a与参考译文都进行了顺序翻译,从词汇化调序模型的观点来看,调序方向是单调调序(M)。而在Baseline中,“确认 波贝特克 的 病情”对应的翻译片段及顺序是“波贝特克”、“the conditions of”、“confirm”,Baseline对短语“确认”进行了错误的调序。从以上分析可以看出,利用本文所提方法搭建的翻译系统对短语进行了正确的调序,证实了本文所提方法的有效性。
6 总结与展望
本文验证了短语调序分布在不同的领域下存在差异,并提出了一种融合主题信息的调序模型领域自适应方法,利用文档的主题信息优化短语的调序分布。本文所提优化调序模型的方法改进了机器翻译系统的性能,相比于基准系统,BLEU值提升了0.76%。这证实了在短语调序中融入文档主题信息的有效性。最后,本文分析了融入主题信息能够提升调序性能的原因。
[1] Axelrod A, He Xiaodong, Gao Jianfeng. Domain adaptation via pseudo in-domain data selection[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processins. Edingburg, Scotland, United Kingdom: Association for Computational Linguistics, 2011, 355-362.
[2] 庞弘燊, 方曙, 杨志刚, 等. 研究领域的主题发展趋势分析方法研究: 基于多重共现的视角[J].情报理论与实践, 2012, 35(8): 44-47,73.
[3] 冯洋, 张冬冬, 刘群. 层次短语翻译模型的介词短语调序[J]. 中文信息学报, 2012, 26(1): 31-36.
[4] 何钟豪, 苏劲松, 史晓东, 等. 引入集成学习的最大熵短语调序模型[J]. 中文信息学报, 2014, 28(1): 87-93.
[5] 肖欣延, 刘洋, 刘群, 等. 面向层次短语翻译的词汇化调序方法研究[J]. 中文信息学报, 2012, 26(1): 37-41,50.
[6] Cao Hailong, Zhang Dongdong, Li Mu, et al. A lexicalized reordering model for hierarchical phrase-based translation[C]//Proceedings of the 25th International Conference on Computational Linguistics. Dublin, Ireland: Technical Papers, 2014: 1144-1153.
[7] Yasuda K, Zhang Ruiqiang, Hirofumi Y, et al.Method of selecting training data to build a compact and efficient translation model[C]//Proceedings of the 3rd International Joint Conference on Natural Language Processing. Hyderabad, India: The Association for Computer Linguistics, 2008: 655-660.
[8] Duh K, Neubig G, Sudoh K, et al. Adaptation data selection using neural language models: experiment in machine translation[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: Association for Computational Linguistics, 2013: 678-683.
[9] 王星, 涂兆鹏, 谢军, 等. 一种基于分类的平行语料选择方法[J]. 中文信息学报, 2013, 27(6): 144-150.
[10] Liu Le, Hong Yu, Liu Hao, et al. Effective selection of translation model training data[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 569-573.
[11] Foster G, Kuhn R. Mixture-model adaptation for SMT[C]//Proceedings of the 2nd Workshop on Statistical Machine Translation. Prague, Czech Republic: Association for Computational Linguistics, 2007: 128-135.
[12] Matsoukas S, Rosti A V I, Zhang B. Discriminative corpus weight estimation for machine translation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, 2009: 708-717.
[13] 曹杰, 吕雅娟, 苏劲松, 等. 利用上下文信息的统计机器翻译领域自适应[J]. 中文信息学报, 2010, 24(6): 50-56.
[14] Foster G, Goutte C, Kuhn R. Discriminative instance weighting for domain adaptation in statistical machine translation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Massachusetts, USA: Association for Computational Linguistics, 2010: 451-459.
[15] Su Jinsong, Wu Hua, Wang Haifeng, et al. Translation model adaptation for statistical machine translation with monolingual topic information[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju, Republic of Korea: Association for Computational Linguistics, 2012: 459-468.
[16] Hewavitharana S, Mehay D N, Ananthakrishnan S, et al. Incremental topic-based translation model adaptation for conversational spoken language translation[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: Association for Computational Linguistics, 2013: 697-701.
[17] Hasler E, Blunsom P, Koehn P, et al. Dynamic Topic Adaptation for Phrase-based MT[C]//Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. Gothenburg, Sweden: Association for Computational Linguistics, 2014: 328-337.
[18] Chen B, Foster G, Kuhn R. Adaptation of reordering models for statistical machine translation[C]//Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology. Atlanta, Georgia: Association for Computational Linguistics, 2013: 938-946.
[19] Wang X, Xiong D, Zhang Min, et al.A topic-based reordering model for statistical machine translation[M]. Berlin Heidelberg: Springer, 2014.
[20] Zhang B, Su J, Xiong D, et al. Discriminative reordering model adaptation via structural learning[C]//Proceedings of the 24th International Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI Press, 2015: 1040-1046.
[21] Tillmann C, Zhang T. A localized prediction model for statistical machine translation[C]//Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics. Ann Arbor, Michigan: Association for Computational Linguistics, 2005: 557-564.
[22] Blei D M, Andrew Y Ng, Michael I J. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[23] Koehn P, Och F, Marcu D. Statistical phrase-based translation[C]//Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology. Edmonton, Canada: Association for Computational Linguistics, 2003: 48-54.
[24] Koehn P, Hoang H, Birch A, et al. Moses: open source toolkit for statistical machine translation[C]//Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics on Interactive Poster and Demonstration Sessions. Prague, Czech Republic: Association for Computational Linguistics, 2007: 177-180.
[25] Xiao T, Zhu J, Zhang H, et al. NiuTrans: an open source toolkit for phrase-based and syntax-based machine translation[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju, Republic of Korea: Association for Computational Linguistics, 2012: 19-24.
[26] Franz J O, Hermann N. A systematic comparison of various statistical alignment models[J]. Computational Linguistics, 2003, 29(Jan): 19-51.
[27] Andreas S. SRILM-an extensible language modeling toolkit[C]//Proceedings of the 7th International Conference on Spoken Language Processing. Denver, Colorado, USA: Interspeech, 2002: 901-904.
[28] Franz J O. Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics. Sapporo, Japan: Association for Computational Linguistics, 2003: 160-167.
[29] Kishore P, Salim R, Todd W, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia, Pennsylvania: Association for Computational Linguistics, 2002: 311-318.

刘梦眙(1993—),硕士研究生,主要研究领域为自然语言处理、机器翻译。
E-mail: lmysd2015@163.com

姚亮(1993—),硕士研究生,主要研究领域为自然语言处理、机器翻译。
E-mail: yaoliang310@163.com

洪宇(1978—),通信作者,副教授,研究生导师,主要研究领域为话题检测、信息检索和信息抽取。
E-mail: tianxianer@gmail.com
DomainAdaptationofReorderingModelviaTopicInformation:WordOrderinTranslatedTextacrossDomains
LIU Mengyi, YAO Liang, HONG Yu, LIU Hao, YAO Jianmin
(School of Computer Science amp; Technology, Soochow University, Suzhou, Jiangsu 215006, China)
The research on domain adaptation (DA) for statistical machine translation (SMT) aims at dynamically adjusting the translation model to ensure balanced and reliable translation quality in different domains. Existing researches on adaptation of translation model have made remarkable progress, but neglect the reordering issue. This paper investigates the translation samples in a large scale source bilingual corpus, revealing that 36.17% samples exhibits clear word order differences in phrase level translation pairs. Therefore, we propose a domain adaptive reordering model based on fusing topic information, to explore the reordering differences of phrases under different topic distribution. Experimental results show that translation systems with adaptive reordering model yield obvious performance improvements.
statistical machine translation; domain adaptation; reordering model; topic model
1003-0077(2017)05-0050-09
TP391
A
2016-08-16定稿日期2017-04-26
国家自然科学基金(61373097,61672368,61672367, 61331011);江苏省科技计划(SBK2015022101);教育部—中国移动科研基金(MCM20150602)
