基于双语信息的问题分类方法研究
2017-11-27李寿山王红玲
徐 健,张 栋,李寿山,王红玲
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
基于双语信息的问题分类方法研究
徐 健,张 栋,李寿山,王红玲
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
问题分类是问答系统研究的一项基本任务。先前的研究仅仅是在单语语料上训练得到问题分类模型,存在语料不足和问题文本较短的问题。为了解决这些问题,该文提出了融合双语语料的双通道LSTM问题分类方法。首先,利用翻译语料分别扩充中文和英文语料;其次,将两种语言语料中的样本都分别用问题文本和翻译文本表示;最后,提出了双通道LSTM分类方法用于充分利用这两组特征,构建问题分类器。实验结果表明,该文提出的方法能有效提高问题分类的性能。
问答系统;问题分类;LSTM
1 引言
问答系统主要针对用户提出的问题进行自动化处理,给用户一个简明、准确的答案反馈。现有的问答系统主要包括三个模块: 问题分析、信息检索和答案抽取。问答系统为了能够正确回答用户所提出的问题,首先需要对问题进行分析,理解用户想要获取的信息。问题分类作为问题分析最基础的任务,为整个问答系统提供了重要的技术支持[1]。问题分类的目标是将某个给定的问题映射到多个类型中的某一个或者几个类别,以此确定问题的类型。
问题分类在问答系统中主要有两个作用。一方面是能有效地减小答案的候选空间。例如,问题“耳鸣的症状表现有哪些?”若将该问题正确分类为“健康”类问题,问答系统就可以从“健康”类的相关答案集合中检索合适的答案。这样能非常有效地减小候选答案集合,提高检索效率。另一方面是能决定答案的抽取策略,即根据问题的不同类别采用不同的答案选择策略和知识库。例如,针对问题“天蝎座的男生与哪个星座的女生最合适?”问题分类方法可以推理出该问题是“感情”类问题,检索这类问题的答案时利用情感分析技术就能提升问题答案的准确性。
值得注意的是,传统的问题分类普遍都是基于单语问题文本的分类方法。然而,已标注的问题资源比较匮乏,而且问题文本一般较短,包含的信息量比较少,传统的问题分类方法往往无法捕捉到有效特征。与以往研究不同的是,本文认为翻译语料对语料的扩充及问题的表示都有较大的帮助。一方面翻译语料扩充了语料,解决了问题资源匮乏的问题;另一方面翻译文本的信息对问题分类提供了更多的信息量,使得基于长短期记忆的循环神经网络算法(LSTM)可以学习到长期依赖关系,从而提高问题分类的性能。如表1所示,在例(1)中“联想”翻译成“Lenovo”,而在例(2)中“联想”翻译成“think”,此时翻译文本为问题的分类提供了更多的信息。

表1 翻译文本提供更多信息的实例
具体而言,本文首先用翻译的语料扩充单语语料的规模,其次用问题本身和问题的翻译两种表示共同训练双通道LSTM分类模型,通过Merge层联合学习问题文本和翻译文本两种表示的关系,最后得到问题分类模型并用测试语料进行测试。实验结果表明,双语信息有助于提升问题分类准确率。
本文其他部分组织如下: 第二节介绍问题分类的相关工作;第三节描述问题语料的收集和翻译;第四节介绍本文提出的融合双语语料的双通道LSTM问题分类方法;第五节给出实验设置与结果分析;第六节简述结论及下一步工作。
2 相关工作
目前,问题分类研究主要是基于统计的机器学习方法。Ray[2]等人充分利用WordNet的语义特征和维基百科存储的相关知识来扩充问题所蕴含的信息,从而提升问题分类性能;Hui[3]等人考虑了问题文本中的词序和词间距,提出一种扩展类顺序规则模型;Mishra[4]等人从问题文本中抽取出词特征、句法特征和语义特征,训练最近邻朴素贝叶斯和支持向量机分类器进行问题分类;Yadav[5]等人使用了一元、二元、三元词特征和词性特征,使用朴素贝叶斯分类方法进行问题分类;田卫东[6]等发现问题中的疑问词和中心词等关键词对问题类型起着决定性的作用,提出利用自学习方法建立疑问词-类别和疑问词+中心词—类别两种规则,改进了贝叶斯模型的问题分类方法;张巍[7]等针对中文问题分类方法中布尔模型提取特征信息损失较大的问题,提出了一种新的特征权重计算方法;Liu[8]等人认为标准核函数的SVM方法忽视中文问题的结构信息,因而提出一种问题文本属性核函数的SMO方法。
刘小明[9]等先对问题文本进行浅层语义分析,再根据预定义的问题焦点结构和焦点抽取规则,获取问题焦点语义特征,问题的类别标签为问题焦点中疑问对象在领域本体中的标识,最后将焦点相同的问题归为一类。
张栋[10]等提出了一种基于答案辅助的半监督问题分类方法。首先,将答案特征结合问题特征一起实现样本表示,然后,利用标签传播方法对已标注问题训练分类器,自动标注未标注问题的类别,最后,将初始标注的问题和自动标注的问题合并作为训练样本,利用最大熵模型对问题的测试文本进行分类。
多年来,传统的问题分类研究仅仅是在单语语料上用机器学习方法训练得到分类模型。与之不同的是,本文认为翻译语料对语料的扩充及问题的表示都有较大的帮助,一方面扩充了语料,另一方面翻译文本对问题分类提供了更多的信息量,以此来提高问题分类的性能。
3 语料收集与翻译
3.1 语料收集
本文中文语料来自360问答社区*http://wenda.so.com/。本文抓取了其中四个类别的问题数据,分别是艺术、电脑、健康和体育,每个类别1 250个问题。英文语料来自亚马逊Askville问答社区*http://www.askville.com/,本文抓取与中文语料相同类别和数量的数据。
3.2 语料翻译
本文采用百度翻译*http://fanyi.baidu.com/和谷歌翻译*http://translate.google.com/对语料进行翻译,中英文问题及翻译如表2和表3所示。

表2 各类别中文问题及翻译

表3 各类别英文问题及翻译
4 问题分类方法
图1所示是本文提出的融合双语语料的双通道LSTM问题分类方法的完整架构图。本文首先将中英文语料分别翻译得到翻译语料,再将单语语料与对应的翻译语料合并为扩充的单语语料,然后将两种语言的扩充语料分别处理得到中文特征向量集和英文特征向量集,并用中英文特征向量集训练双通道LSTM模型,最后将测试集中的语料用问题和翻译两种特征向量表示,用来测试问题分类器的性能。

图1 融合双语语料的双通道LSTM问题分类方法架构图

图2 单通道LSTM神经网络结构
4.1 单通道LSTM问题分类方法
长短时记忆(LSTM)神经网络用来解决长期依赖问题,适用于处理和预测时间序列中间隔和延迟时间非常长的重要事件。LSTM循环神经网络具体传播过程的公式如下:
σ是激活函数sigmoid,符号⊙是指向量之间的点乘运算。输入门it、遗忘门ft和输出门ot取决于前一个状态ht-1和当前输入xt。 所提取的特征向量gt作为候选存储单元。当前存储单元ct是由候选存储单元和前一个存储单元ct-1分别乘以各自的权重输入门it和遗忘门ft,再相加得到。最后LSTM单元的输出由输出门ot和当前存储单元ct计算得到。
图2是单通道LSTM模型的结构,单通道的LSTM用词特征向量作为输入,通过LSTM层得到高维向量,LSTM的输出作为全连接层的输入,对输入进行加权后经过激活函数:
φ是非线性激活函数,在我们的模型中“relu”作为激活函数,h是LSTM层的输出(全连接层的输入)。Dropout层的作用是在训练时随机减少特征个数,能有效地防止过拟合,获得更好的范化能力。公式如下:
D表示dropout操作符,p是一个可调的超参(保留隐层单元的比率)。
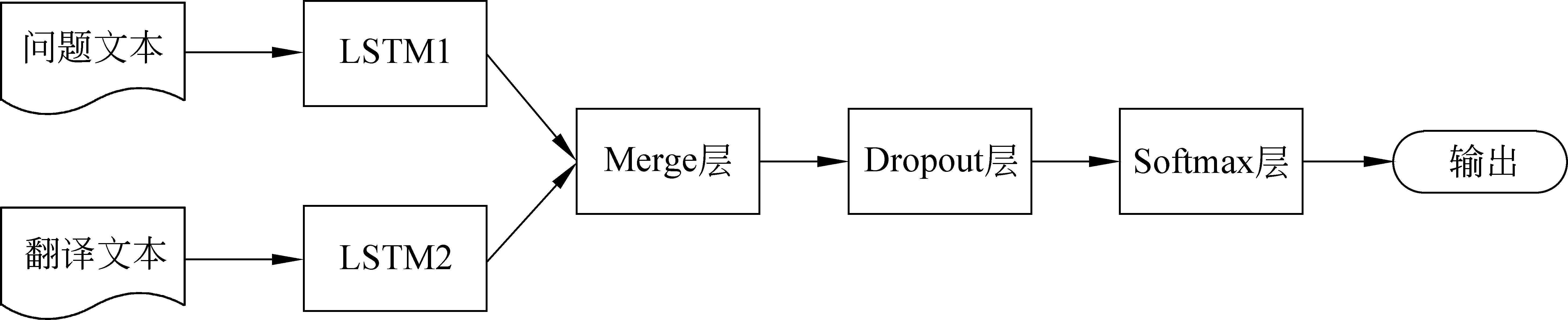
图3 双通道LSTM神经网络结构
4.2 融合双语语料的双通道LSTM问题分类方法
本文不仅加入翻译的语料来扩充训练样本,而且每个文档采用问题文本和翻译文本两种表示方式。为了充分学习这两组特征的关系,本文提出了融合双语语料的双通道LSTM问题分类方法,它可以联合学习问题文本和翻译文本这两组特征。如图2 所示,分别输入问题文本和翻译文本,两种特征分别经过单通道LSTM得到新的文本表示,在双通道LSTM神经网络的Merge层,我们对两种LSTM的输出采用相加的融合方式,具体公式如下:
式(9)中,g表示融合后的输出,h1i和h2i分别表示第一个通道和第二个通道在第i个时间点长短期记忆单元的输出,⊕表示对应元素相加的操作。
以中文问题分类为例,本文方法的算法流程如图4所示。
5 实验设计与结果分析
5.1 实验设置
① 实验数据。实验使用中英文各4个主题的问题语料,每种语言每个主题取80%的问题作为训练集,20%的问题作为测试集。语料收集的具体细节见3.1节。
② 特征选择及表示。实验所用分类特征为一元词特征(Unigram)。本文将训练集中出现的词,按照词频从高到低的顺序构建词典。问题文本中的每个词用词典中对应的数字替换,由此构建问题文本的特征向量。
③ 分词工具。中文语料分词采用复旦大学自然语言处理实验室开发的分词软件FudanNLP*http://www.nlpir.org/?action-viewnews-itemid-105。
④ 分类方法及参数设置: 实验中使用到的分类方法有最大熵和LSTM神经网络。最大熵使用

图4 融合双语语料的双通道LSTM问题分类方法
MALLET机器学习工具包*http://mallet.cs.umass.edu/,用默认参数;LSTM神经网络使用深度学习框架Keras*http://keras.io/,具体参数如表4所示。
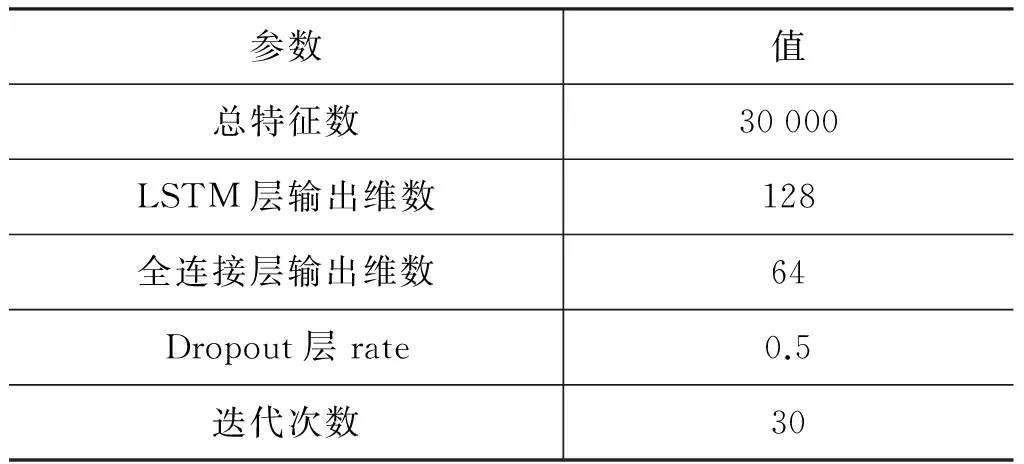
表4 LSTM参数
⑤ 评价标准。实验结果使用正确率(Accuracy)和F1值(F-Measure)作为评价标准。
5.2 实验结果与分析
为了与传统的问题分类方法比较,我们不仅实现了本文提出的方法,而且实现了传统的最大熵问题分类方法和基于单通道LSTM的问题分类方法。
① 基于最大熵的问题分类方法(Baseline)使用单语语料构建最大熵分类器;
② 基于单通道LSTM的问题分类方法(LSTM)使用单语语料构建单通道LSTM分类器;
③ 融合双语语料的双通道LSTM问题分类方法(双语语料+双通道LSTM),不仅加入翻译语料来扩充训练样本,而且每个文档采用问题文本和翻译文本两种表示方法,共同训练双通道LSTM分类模型。
表5给出了中文问题和英文问题分类的正确率,

表5 中文问题和英文问题分类正确率
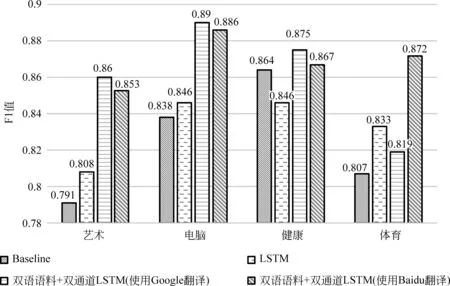
图5 中文问题分类各类别F1值
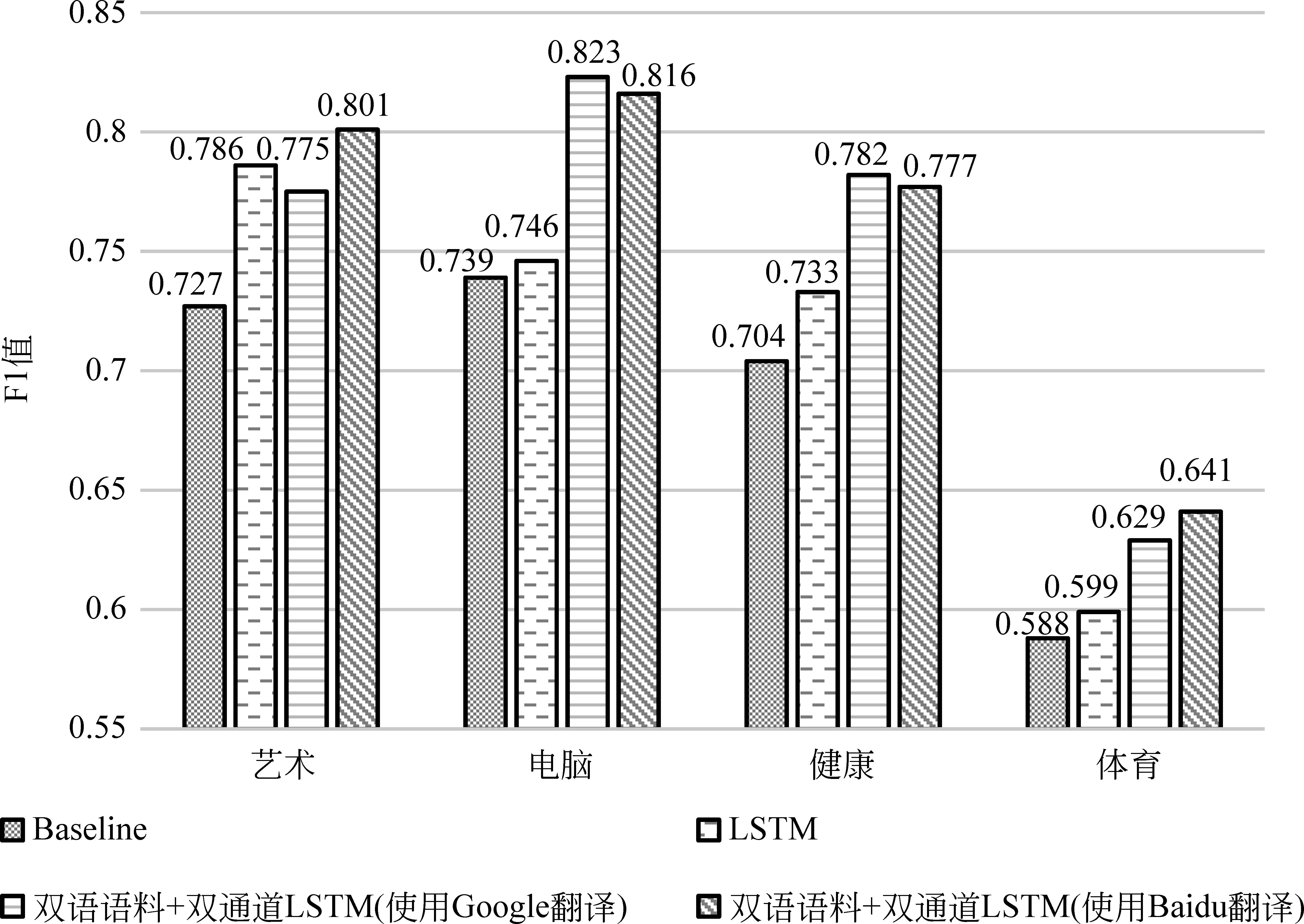
图6 英文问题分类各类别F1值
图5给出了中文问题分类各类别的F1值,图6给出了英文问题分类各类别的F1值。
从实验结果中我们可以发现:
① 单通道LSTM与最大熵分类器相比,中文问题分类正确率提高了0.9%,除了“健康”类别外其他类别F1值均有提高;英文问题分类正确率提高了2.7%,每个类别的F1值均有提高。
② 当使用Google作为翻译引擎时,融合双语语料的双通道LSTM问题分类方法与最大熵相比,中文问题分类正确率提高了3.7%,每个类别的F1值有一定程度的提高;英文问题分类正确率提高了6.6%,每个类别的F1值都有一定程度的提高。与LSTM分类器相比,中文问题正确率提高了2.8%,除“体育”类外其他类别的F1值均有提高;英文问题分类正确率提高了3.9%,除了“艺术”类外其他类别的F1值均有提高。
③ 当使用Baidu作为翻译引擎时,融合双语语料的双通道LSTM问题分类方法与最大熵相比,中文问题分类正确率提高了4.5%,每个类别的F1值都有一定程度的提高;英文问题分类正确率提高了7.1%,每个类别的F1值都有一定程度的提高。与LSTM分类器相比,中文问题正确率提高了3.6%,每个类别的F1值均有提高;英文问题分类正确率提高了4.4%,每个类别的F1值均有提高。
④ 融合双语语料的双通道LSTM问题分类方法使用Baidu作为翻译引擎时效果比Google更佳。具体而言,在中文问题分类任务中,使用Baidu比使用Google提高0.8%的正确率;在英文问题分类任务中,使用Baidu比使用Google提高0.5%的正确率。
综上所述,本文提出的融合双语语料的双通道LSTM问题分类方法优于最大熵和单通道LSTM。主要原因是本文用翻译语料扩充了训练语料,从翻译语料中学习到了更多的信息,并且双通道LSTM结合问题文本和翻译文本,学习到了两组特征间的关联信息。而且我们发现本文方法在英文问题分类任务上性能提高更大,这可能由于中文问题信息对英文问题分类提供了更有效的信息量。
6 总结
本文针对问题分类任务,提出了融合双语语料的双通道LSTM问题分类方法。该方法的特点在于用翻译语料扩充了语料,而且同一问题用问题文本和翻译文本两种表示方法,结合两种文本学习到了它们的关联信息。实验结果表明,本文提出的方法,在中文语料和英文语料上,与最大熵和LSTM方法相比,分类性能都有较大程度的提高,充分说明了本文提出的融合双语语料的双通道LSTM问题分类方法的有效性。
下一步工作,我们将考虑更多的分类方法(如CNN)以进一步提高问题分类性能。此外,我们也将考虑更多的特征(如答案、结构句法和依存句法等),并考察这些特征是否可以提高问题分类的性能。
[1] 李鑫, 黄萱菁, 吴立德. 基于错误驱动算法组合分类器及其在问题分类中的应用[J]. 计算机研究与发展, 2008, 45(3):535-541.
[2] Ray S K, Singh S, Joshi B P. A semantic approach for question classification using WordNet and Wikipedia[J]. Pattern Recognition Letters, 2010, 31(13):1935-1943.
[3] Hui Z, Liu J, Ouyang L. Question classification based on an extended class sequential rule model[C]//Proceedings of the 5th IJCNLP, Chiang Mai, 2011: 938-946.
[4] Mishra M, Mishra V K, Sharma H R. Question classification using semantic, syntactic and lexical features[J]. International Journal of Web amp; Semantic Technology, 2013, 4(3):39.
[5] Yadav R, Mishra M, Bhilai S. Question classification using Naïve Bayes machine learning approach[J]. International Journal of Engineering and Innovative Technology (IJEIT), 2013, 2(8):291-294.
[6] 田卫东, 高艳影, 祖永亮. 基于自学习规则和改进贝叶斯结合的问题分类[J]. 计算机应用研究, 2010, 27(8):2869-2871.
[7] 张巍, 陈俊杰. 信息熵方法及在中文问题分类中的应用[J]. 计算机工程与应用, 2013, 49(10):129-131.
[8] Liu L, Yu Z,Guo J, et al. Chinese question classification based on question property kernel[J]. International Journal of Machine Learning amp; Cybernetics, 2014, 5(5):713-720.
[9] 刘小明, 樊孝忠, 李方方. 一种结合本体和焦点的问题分类方法[J]. 北京理工大学学报, 2012, 32(5):498-502.
[10] 张栋, 李寿山, 周国栋. 基于答案辅助的半监督问题分类方法[J]. 计算机工程与科学, 2015, 37(12): 2352-2357.

徐健(1992—),硕士研究生,主要研究领域为自然语言处理。
E-mail: jxu1017@stu.suda.edu.cn

张栋(1991—),硕士研究生,主要研究领域为自然语言处理。
E-mail: dzhang@stu.suda.edu.cn

李寿山(1980—),通信作者,博士,教授,主要研究领域为自然语言处理。
E-mail: lishoushan@suda.edu.cn
ResearchonQuestionClassificationviaBilingualInformation
XU Jian, ZHANG Dong, LI Shoushan, WANG Hongling
(School of Computer Science and Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Question classification is a basic task in question answering system. Previous studies only employ the monolingual corpus to train the question classification model, suffering from problems such as lack of corpus and short length of question text. To solve these problems, we propose a new approach named dual-channel LSTM model with bilingual information. Firstly, we extend the Chinese corpus and English corpus with the corresponding translated corpus. Secondly, the samples are represented by the question text and translation word vector. Finally, we build an question classifier using dual-channel LSTM model. The experimental result demonstrates that our approach improves the performance of question classification.
Qamp;A system; question classification; LSTM
1003-0077(2017)05-0171-07
TP391
A
2016-09-16定稿日期2016-12-31
国家自然科学基金(61672366);国家青年科学基金(61402314)
