基于TF-IDF和余弦相似度的文本分类方法
2017-11-27武永亮赵书良李长镜魏娜娣王子晏
武永亮,赵书良 ,李长镜 , 魏娜娣,王子晏
(1. 河北师范大学 数学与信息科学学院,河北 石家庄 050024;2. 河北省计算数学与应用重点实验室, 河北 石家庄 050024;3. 河北师范大学汇华学院,河北 石家庄 050091;4. 中国科学技术大学 计算机科学与技术学院,安徽 合肥 230022)
基于TF-IDF和余弦相似度的文本分类方法
武永亮1,2,赵书良1,2,李长镜1,2, 魏娜娣3,王子晏4
(1. 河北师范大学 数学与信息科学学院,河北 石家庄 050024;2. 河北省计算数学与应用重点实验室, 河北 石家庄 050024;3. 河北师范大学汇华学院,河北 石家庄 050091;4. 中国科学技术大学 计算机科学与技术学院,安徽 合肥 230022)
文本分类是文本处理的基本任务。大数据处理时代的到来致使文本分类问题面临着新的挑战。研究者已经针对不同情况提出多种文本分类算法,如KNN、朴素贝叶斯、支持向量机及一系列改进算法。这些算法的性能取决于固定数据集,不具有自学习功能。该文提出一种新的文本分类方法,包括三个步骤: 基于TF-IDF方法提取类别关键词;通过类别关键词和待分类文本关键词的相似性进行文本分类;在分类过程中更新类别关键词改进分类器性能。仿真实验结果表明,本文提出方法的准确度较目前常用方法有较大提高,在实验数据集上分类准确度达到90%,当文本数据量较大时,分类准确度可达到95%。算法初次使用时,需要一定的训练样本和训练时间,但分类时间可下降到其他算法的十分之一。该方法具有自学习模块,在分类过程中,可以根据分类经验自动更新类别关键词,保证分类器准确率,具有很强的现实应用性。
文本分类;大数据;TF-IDF;余弦相似度;类别关键词
1 引言
20世纪90年代以来,互联网技术迅速发展,信息数据成指数级别增长。如何有效地对这些文本信息进行组织和管理,已经成为人们迫切需要解决的问题。文本分类是文本处理过程中最重要的步骤之一[1]。截至目前,很多文本分类方法已被应用在各个领域,例如分类实时新闻、搜索引擎分类搜索、互联网信息统计分析等。
目前,最常用的文本分类算法有KNN、SVM和朴素贝叶斯。KNN算法由T.M. Cover在1967年提出[2],根据近邻文本的类别统计完成文本分类。KNN算法易于理解和实现,但对异常值不敏感。Gongde Guo等研究者把KNN算法应用在自动文本分类领域[3]。Jiang S等研究者对KNN算法进行深入研究[4-5]。但KNN算法计算复杂度较高,不适合大规模的文本分类问题。支持向量机算法是由Vapnik等人在统计学习理论基础上对线性分类器提出的另一种设计准则[6],随后又发展为支持向量网络[7]。Joachims在1999年进行了SVM分类器的推导证明[8]。研究人员还在支持向量机方法的基础上进行其他研究[9-10]。支持向量机方法在小样本空间的分类问题上性能突出。朴素贝叶斯算法的思想早在20世纪50年代已经被提出。在20世纪60年代成为搜索领域最流行的分类方法。Kim等把朴素贝叶斯方法应用到文本分类领域[11]。Frank把朴素贝叶斯方法应用到不均衡文本分类中[12],研究人员还基于朴素贝叶斯方法提出许多改进方法[13-14]。朴素贝叶斯方法是基于统计学理论的分类方法,但是无法处理特征组合分类问题,所以朴素贝叶斯算法无法在处理大量文本分类问题上有较高分类效率。
本文共分为六部分。第一部分描述文本分类领域的研究现状,指出常见文本分类算法的适用领域。第二部分描述TF-IDF技术的原理。第三部分描述余弦相似度的原理。第四部分提出基于TF-IDF的文本分类方法。第五部分通过实验对比常见文本分类方法在基准语料库上的性能。最后一部分总结本文的研究成果,并提出下一阶段的研究计划。
2 TF-IDF
本文基于TF-IDF词频权重技术[15-16]提出一种文本分类方法。TF-IDF技术用于评估词语对于文档集或语料库中文本的重要程度。词频(TF)表示特定单词在文档中出现的频率。逆文档频率(IDF)用来评价词语对于语料库的普遍性。TF-IDF值由TF值乘以IDF值得到。TF-IDF技术经常被用于关键词提取和文章摘要提取[17]。
TF-IDF技术用来提取文本关键词及类别关键词(KWC)。在本文第四节中,作者使用类别关键词和文本关键词的相似度来进行文本分类。
3 余弦相似度
余弦相似度是通过两个向量之间的夹角来衡量向量相似性。余弦相似度计算如式(1)所示。
在本文第四节中详细描述类别关键词的获取,及通过文本关键词和类别关键词的相似性进行文本分类的过程。
4 基于TF-IDF和余弦相似度的文本分类方法
4.1 方法架构
本文提出的文本分类方法整体架构如图1所示。
本文提出类别关键词提取算法来获取类别关键词。首先读取类别的所有文本,然后去除特殊符号及停用词,剩余词语为类别关键词。类别关键词数量过多会导致计算量增大,所以本文根据TF-IDF值进行关键词排序,筛选后得到类别关键词。具体筛选方法参见4.1节中类别关键字寻优过程。
算法1类别关键词提取算法
输入:
corpus:训练语料库
catelist:存储所有类别信息
dlist:训练集的根目录,把所有的训练样本放入一个文件夹。一级目录为类别名。每个一级目录中包含本类别的所有训练样本。
stopWordList:存储停用词表
输出:
catelist:包含类别关键词的类别信息
具体算法:
1: foreach d∈dlist do
2: t.realcategory = d.getDirectoryName()//得到类别目录
3: singleTypeContent = ‘’
4: foreach f∈getFileList(d) do
5: content= readFile(f)
6: singleTypeContent += textClean (content)
7: end for
8: corpus.append(singleTypeContent)
9: catelist.append(t)
10: end for
11: TF-IDF = fit_transform(corpus)
12: word = get_feature_names()
13: weight = getTF-IDF()
14: foreach c∈catelist do
15: order( c. keywordList )//根据TF-IDF值,排序类别关键词
16: end for
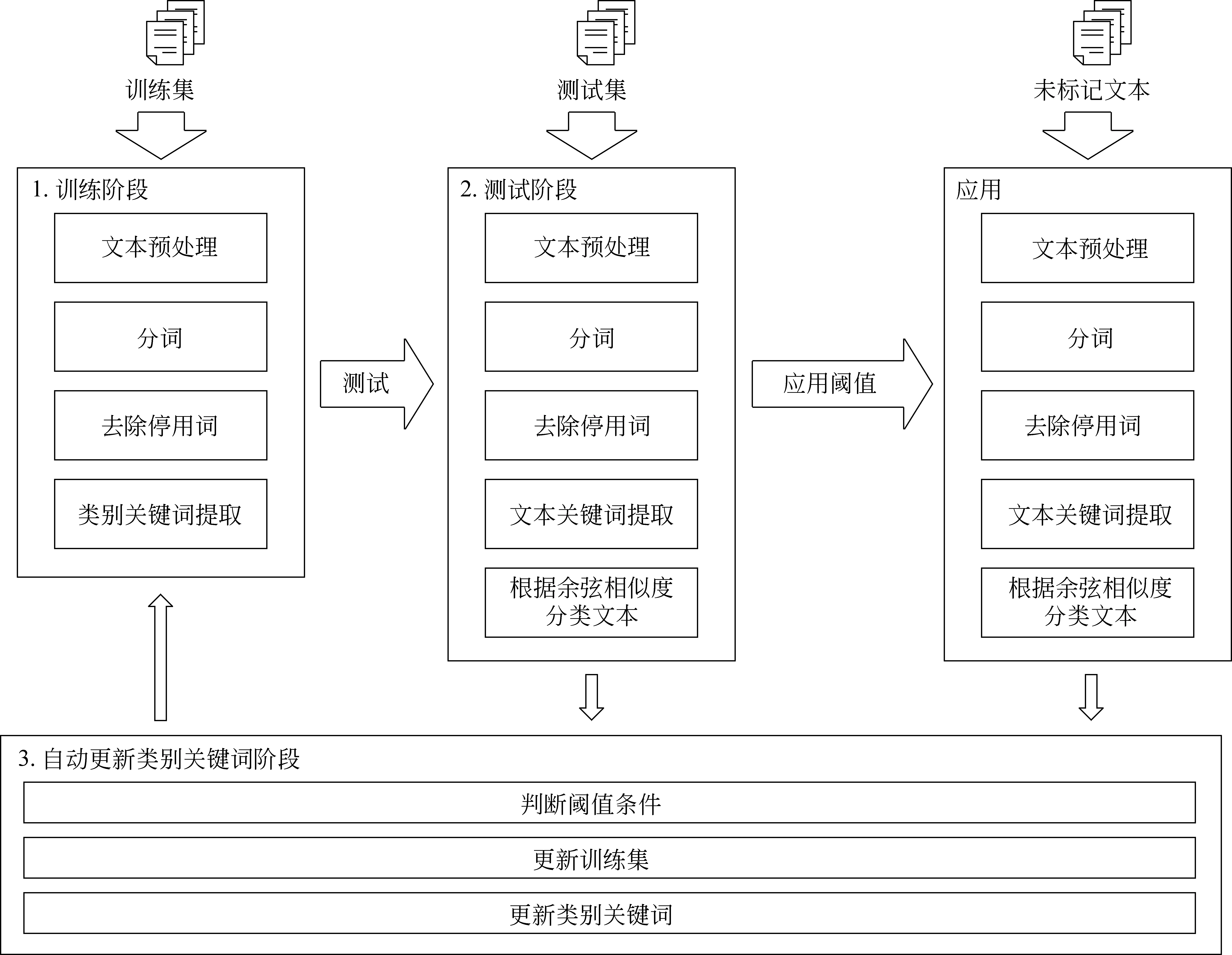
图1 基于TF-IDF和余弦相似度的文本分类方法的架构
在算法1中,第1~3步,读取训练集的根目录,其中每一个子目录代表一个类别。在第4~10步中依次读取各类别所有的文本,进行文本预处理、分词等操作。在第11~13步中计算出所有单词的TF-IDF值,在第14~16步中按照TF-IDF值进行排序。最终得到每个类别的所有关键词。
算法2的目的是得到文本关键词。
算法2文本关键词提取算法
输入:
corpus:训练语料库
testFilelist:保存所有的待分类文本
dtlist:测试集的根目录,把所有的测试样本放入一个文件夹。一级目录为类别名。每个一级目录中包含本类别的所有测试样本。
stopWordList:存储停用词表
输出:
testFilelist:得到所有的待分类文本的关键词
具体算法:
1: foreach d∈dtlist do
2: foreach f∈getFileList(d) do
3: text.realCategory= readRealCategorys(f)
4: content= readFile(f)
5: text.content = textClean (content)
6: corpus.append(text.content)
7: testFilelist.append(text)
8: end for
9: end for
10: TF-IDF = fit_transform(corpus)
11: word = get_feature_names()
12: weight = getTF-IDF()
13: foreach f∈testFilelist do
14: order( f. keywordList )//根据TF -IDF值排序文本关键词
15: end for
在算法2中,第1~9步进行待分类文本根目录的读取。第3步中记录测试集的真实类别。在第2~7步中预处理所有文件内容。在第10~11步中计算每个单词的TF-IDF值,然后在第13~15步中按照TF-IDF值进行关键词的排序。
文本分类算法根据文本关键词和类别关键词的相似度进行文本分类。
算法3文本分类算法
输入:
KWCs:每个类别的类别关键词
Key-words:测试文本的文本关键词
输出:
predictCategory:存储测试文本的预测类别
具体算法:
1: foreach fkw∈dtlist do
2: foreach kwc∈catelistdo
3: if max lt; getCosineSimilarity(fkw , kwc)
4: max = getCosineSimilarity(fkw , kwc)
5: end if
6: end for
7: predictCategory = argmax( kwc )//相似度最大的类别为预测的文本类别
8: end for
在算法3中,第1~6步中计算文本与所有类别的相似度。第7步中找到最大相似度的类别。
分类器自学习算法可以提升分类器性能。通过设置阈值条件把文本加入训练集,重新训练分类器。分类算法就在分类过程中自学习,提升分类器的性能,具体算法在第4.4节类别关键词自更新机制中介绍。
4.2 类别关键词寻优
本文提出类别关键词提取算法来获取类别关键词。以BBC语料库(BBC语料库的介绍请参考第5.1节)为例,在表1中列出每个类别排名前10位的关键词。

表1 BBC数据集中各类别前10个关键词
数据表明,类别关键词可表明类别特征。关键词的TF-IDF值决定关键词在此类别中的重要程度。但类别关键词过多会导致分类效率降低。实验表明,选取的类别关键词达到一定比例时,分类精度保持稳定。以BBC语料库为例,实验结果如图2所示。

图2 类别关键词百分比和分类器精度的关系
4.3 文本关键词寻优
本文提出文本分类算法来获取文本关键词。表2中列举五个待分类文本中排名前十位的关键词。
根据以上关键字进行仿真实验,当类别关键词比例固定,文本关键词比例增加时,分类精度会大幅提升,达到临界点后,分类效率稳定。故选文本关键词取临界点比例,效率最优。以BBC语料库为例,实验结果如图3所示。
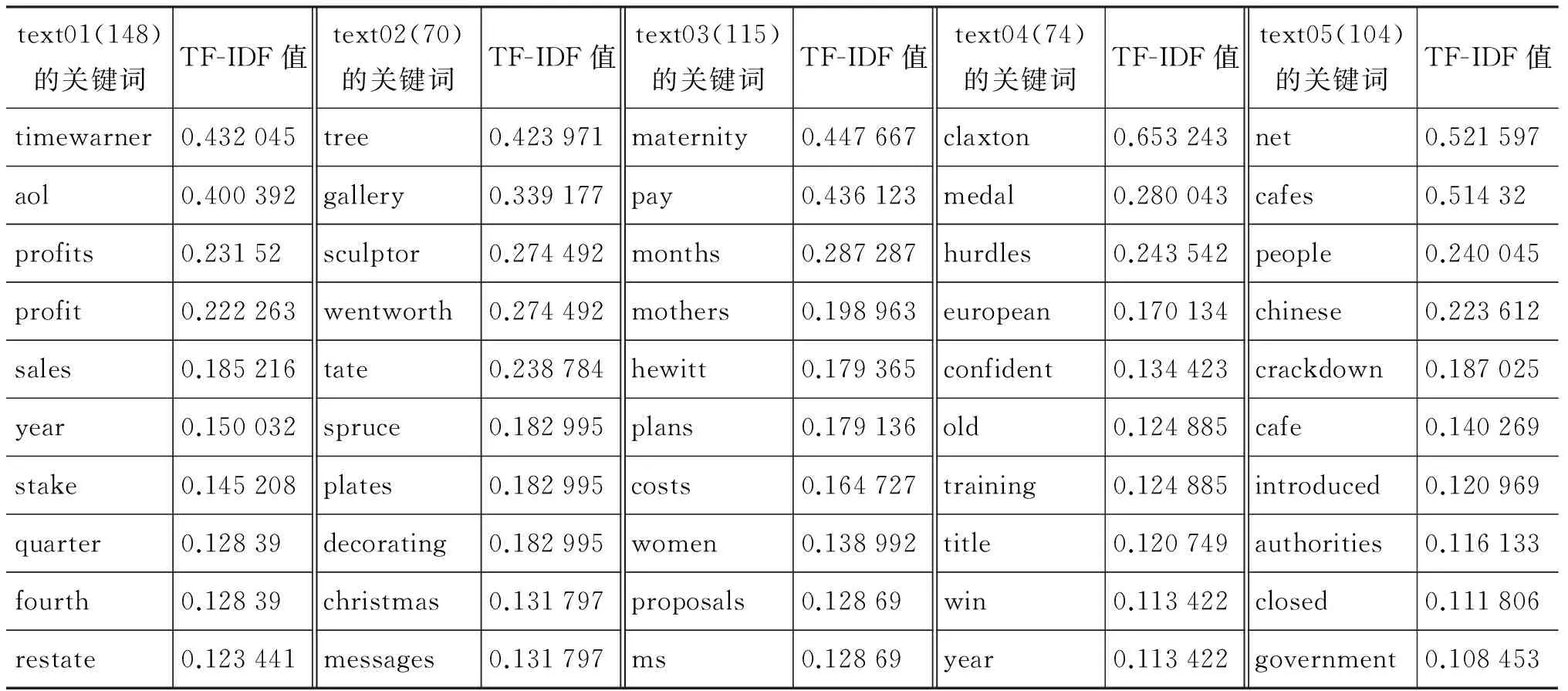
表2 BBC语料库中测试文本的前10个关键词
图3 文本关键词比例和分类器精度的关系
4.4 类别关键词自更新机制
通过4.2节,4.3节的描述,对本文提出的分类算法进行参数优化。本算法(算法4)加入类别关键词自更新机制来解决冷启动现象。
算法4自学习文本分类算法
输入:
KWCs:每个类别的类别关键词
Key-words:待分类文本的关键词
输出:
predictCategory:待分类文本的预测类别
具体算法:
1: foreach fkw∈dtlist do
2: foreach kwc∈catelist do
3: if max lt; getCosineSimilarity(fkw , kwc)
4: max = getCosineSimilarity(fkw , kwc)
5: end if
6: end for
7: predictCategory = argmax( kwc )
8: if thresholdfun (max)//如果相似度达到阈值条件
9: updatKWC();//加入待训练文本集合,重新训练分类模型,更新类别关键词
10: end for
算法4与算法3相比加入第8~9步来更新类别关键词。当文本关键词和类别关键词达到相似度阈值时,则把此文本加入待训练文本集合中。当待训练文本集合的文本数量达到固定数量阈值时,重新训练分类器,更新类别关键词。本算法通过控制相似度阈值降低噪声文本加入待训练集的概率,提升分类效率。
5 实验
5.1 数据集
BBC(英国广播公司新闻数据): 此数据集经常被用于文本分类、文本聚类等任务。原始的BBC语料库包括2 225个新闻文本,5个不同的类别。数据集中五个类别分别是商业、娱乐、政治、体育和科技。(来自于http://mlg.ucd.ie/datasets/bbc.html)
20 Newsgroups: 此数据集由Ken Lang收集,包括20 017个文本,20个类别,经常被用于文本分类任务。 (来自于http://www.qwone.com/~jason/20Newsgroups/)
Reuters-21578:包含21 578个1987年的路透社新闻文档[18]。此数据集使用自动语音识别系统创建。研究人员经常使用本数据集代替原始数据集进行分类实验。 (来自于http://archive.ics.uci.edu/ml/datasets/Reuters + Transcribed + Subset)
5.2 评价指标
本文采用准确率、召回率和F1值进行分类评价,并定义分类指标TP(真正)、FN(假负)、FP(假正)、TN(真负)。
准确率被用来作为分类器正确识别文本的一个统计测量。准确率P由TP和FP计算如式(2)所示。

召回率指检索出的相关文档数和文档库中所有相关文档数的比率,测量检索系统的查全率的召回率R由TP和FN计算如式(3)所示。
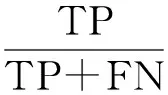
F1值是衡量分类器分类准确性的标准。F1值的计算方法是准确率P和召回率R的加权平均。F1值最大值为1,最小值为0。计算公式如式(4)所示。

5.3 实验结果
本文对于每个数据集,随机选择80%作为训练集和20%作为测试集进行实验。本文采用交叉验证方法,选择F1值作为综合性能指标,在Reuters-21578数据集中各分类方法的实验结果如图4所示。
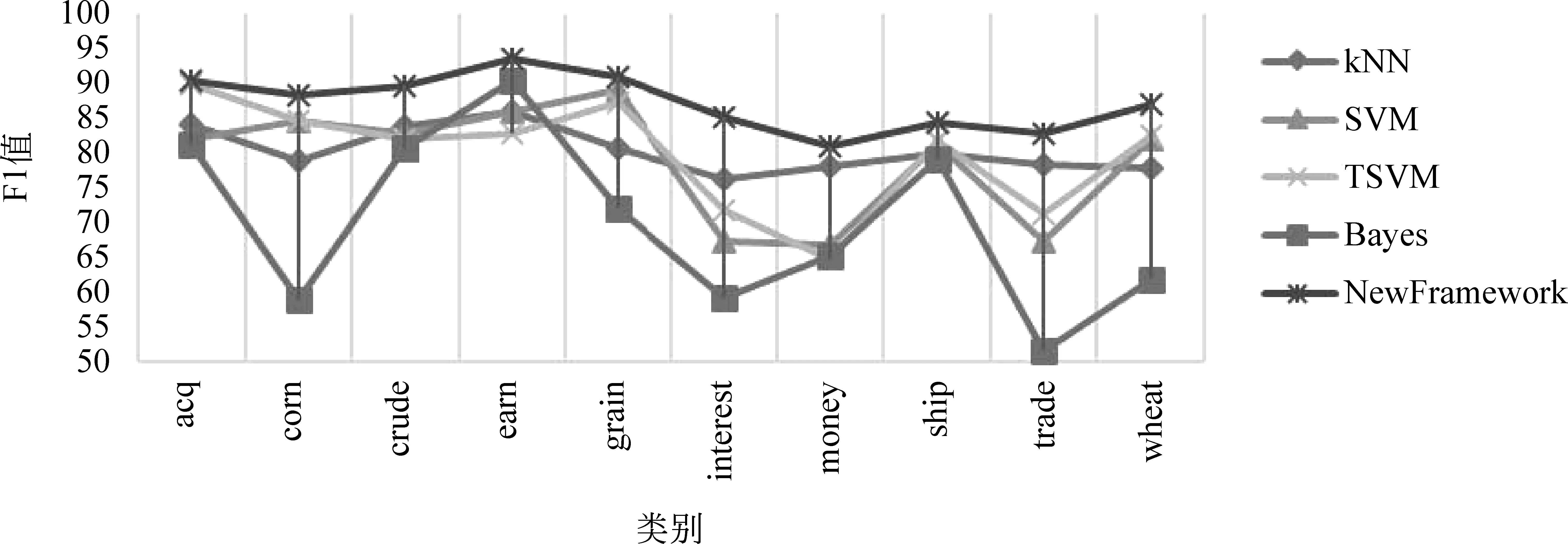
图4 在Reuters-21578数据集上的结果对比
在20 Newsgroups数据集、传统BBC新闻网数据集、2016年爬取的BBC最新数据集(测试文本下载地址http://pan.baidu.com/s/1qXNrlTy)上也呈现出较好的分类结果。
6 结束语
本文提出一种基于TF-IDF和余弦相似度的有效文本分类方法。实验结果表明,该方法在BBC数据集、Reuters-21578数据集和20 Newsgroups数据集上表现良好。在实验数据集上分类准确度较高,可解决当前互联网信息系统处理大量文本分类任务的问题。本文提出的分类方法通过自学习功能维持分类效率。
后续拟开展的研究包括: 对类别关键词的阈值更新进行深入研究;本文提出的文本分类方法主要针对英文文本数据集,后续可以应用到中文文本数据集上进行文本分类;本文提出的文本分类算法只考虑了文本统计信息,后续将对提取的文本关键词进行组合,并提出“文本关键词组”的概念,提高分类准确度,优化文本关键词提取。
[1] Joachims T. A Probabilistic Analysis of the Rocchio Algorithm with TF-IDF for Text Categorization[R]. Carnegie-mellon univpittsburgh pa dept of computer science, 1996.
[2] Cover T, Hart P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1):21-27.
[3] Guo G, Wang H, Bell D, et al. Using kNN model for automatic text categorization[J]. Soft Computing, 2006, 10(5): 423-430.
[4] Jiang S, Pang G, Wu M, et al. An improved K-nearest-neighbor algorithm for text categorization[J]. Expert Systems with Applications, 2012, 39(1): 1503-1509.
[5] Soucy P, Mineau G W. A simple KNN algorithm for text categorization[C]//Proceedings IEEE International Conference on. IEEE, 2001: 647-648.
[6] Boser B E, Guyon I M, Vapnik V N. A training algorithm for optimal margin classifiers[C]//Proceedings of the fifth Annual Workshop on Computational Learning Theory. ACM, 1992: 144-152.
[7] Cortes C, Vapnik V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273-297.
[8] Joachims T. Transductive inference for text classification using support vector machines[C]//Proceedings of the International Conference on Machine Learning. 1999(99): 200-209.
[9] Tong S, Koller D. Support vector machine active learning with applications to text classification[J]. The Journal of Machine Learning Research, 2002(2): 45-66.
[10] Kim H, Howland P, Park H. Dimension reduction in text classification with support vector machines[J]. Journal of Machine Learning Research, 2005: 37-53.
[11] Kim S B, Han K S, Rim H C, et al. Some effective techniques for naive bayes text classification[J]. Knowledge and Data Engineering, IEEE Transactions, 2006, 18(11): 1457-1466.
[12] Frank E, Bouckaert R R. Naive bayes for text classification with unbalanced classes[M].Knowledge Discovery in Databases PKDD 2006. SpringerBerlin Heidelberg, 2006: 503-510.
[13] Wang S, Jiang L, Li C. Adapting naive bayes tree for text classification[J]. Knowledge and Information Systems, 2015, 44(1): 77-89.
[14] Rennie J D, Shih L, Teevan J, et al. Tackling the poor assumptions of naive bayes text classifiers[C]//Proceedings of the ICML, 2003, 3616-3623.
[15] Yu C T, Salton G. Precision weighting: an effective automatic indexing method[J]. Journal of the ACM (JACM), 1976, 23(1): 76-88.
[16] Amati G, Van Rijsbergen C J. Probabilistic models of information retrieval based on measuring the divergence from randomness[J]. ACM Transactions on Information Systems (TOIS), 2002, 20(4): 357-389.
[17] Lin J. Using distributional similarity to identify individual verb choice[C]//Proceedings of the Fourth International Natural Language Generation Conference. Association for Computational Linguistics, 2006: 33-40.
[18] Liere R, Tadepalli P. Active learning with committees for text categorization[C]//Proceedings of the AAAI/IAAI. 1997: 591-596.

武永亮(1986—),博士研究生,主要研究领域为数据挖掘、智能信息处理。
E-mail: squallwu_2006@qq.com

赵书良(1967—),教授,博士生导师,主要研究领域为数据挖掘、智能信息处理。
E-mail: zhaoshuliang@sina.com

李长镜(1990—),硕士研究生,主要研究领域为文本挖掘。
E-mail: lee_0809hbsd@outlook.com
TextClassificationMethodBasedonTF-IDFandCosineSimilarity
WU Yongliang1,2, ZHAO Shuliang1,2, LI Changjing1,2, WEI Nadi3, WANG Ziyan4
(1. College of Mathematics and Information Science, HeBei Normal University, Shijiazhuang, Hebei 050024, China;2. Hebei Key Laboratory of Computational Mathematics and Applications, Shijiazhuang, Hebei 050024, China;3. Huihua College of Hebei Normal University, Shijiazhuang, Hebei 050091, China;4. College of Computer Science and Technology, University of Scienceamp;Technology China, Hefei, Anhui 230022, China)
Text classification is the fundamental task for text mining. Many text classification algorithms have been presented in previous literatures, such as KNN, Naïve Bayes, Support Vector Machine, and some improved algorithms. The performance of these algorithms depends on the data set and does not have self-learning function. This paper proposes an effective approach for text classification. The three key points of the approach are: 1)extracting the keywords of category (KWC) of labeled texts based on the TF-IDF approach, 2) classifying unlabeled text by the relevancy of category and unlabeled text, and 3) improving the performance of the approach via updating the KWC in the process of classification. Simulation experiment results show that the new approach can improve the accuracy of text classification to 90%, and even up to 95% when the data volume is large enough. The method can automatically update the keywords of category to improve the classification accuracy of the classifier.
text classification; big data; TF-IDF; cosine similarity; category keywords
1003-0077(2017)05-0138-08
TP391
A
2016-09-07定稿日期2017-04-11
国家自然科学基金(71271067);国家社科基金重大项目(13amp;ZD091);河北省高等学校科学技术研究项目(QN2014196);河北省科技计划项目(15210403D)
