《现汉》与《语法信息词典》词类对应分析
2017-11-27邱立坤俞士汶朱学锋
邱立坤,赵 慧,俞士汶,朱学锋
(1. 鲁东大学 文学院,山东 烟台 264025;2. 北京大学 计算语言学教育部重点实验室,北京 100871;3. 语言能力协同创新中心,江苏 徐州 221009)
《现汉》与《语法信息词典》词类对应分析
邱立坤1,赵 慧1,俞士汶2,3,朱学锋2
(1. 鲁东大学 文学院,山东 烟台 264025;2. 北京大学 计算语言学教育部重点实验室,北京 100871;3. 语言能力协同创新中心,江苏 徐州 221009)
词类标注问题历来受到中文信息处理、汉语语法和词汇学界的共同关注,学者们已提出多种词类标记体系,彼此间存在较大差异,但迄今尚无人对大规模词类标注工程进行系统比较。该文以《现代汉语词典》第5版和《现代汉语语法信息词典》两个大型词典词类标注工程为比较对象,基于所提出的词类对应算法,自动找出两部词典词类标注上的差异,进而对形成差异的原因进行分析。分析结果表明,两部词典词类标注一致性较高(83.5%完全相同),而存在差异的地方可归结为三类主要原因: 词类迁移;词类判断标准不一致;收录义项不同。
现代汉语词典;现代汉语语法信息词典;词类标注;词类对应
1 引言
从《马氏文通》[1]开始,我国语言学家就已认识到标注词类的目的是为了说明句法组合关系: 同类的词往往具有相同的句法功能,把数以万计的词归成若干类,就可以以此为基础说明语法规则,比如名词可以做主宾语、动词可以充当谓语、形容词可以受程度副词修饰等。因此,词类体系及词类划分的标准就成为现代汉语语法研究的基础性问题。20世纪50年代国内汉语学界就词类问题进行了一次大讨论,主要涉及汉语有无词类,以及依据何种标准划分词类等问题[2]。20世纪80年代以来,词类问题仍然是受到汉语学界关注的一个热点问题,吕叔湘、朱德熙先生的词类体系和词类划分标准[3-4]为多数学者所接受,其他代表性观点有原型范畴说[5]、表述功能说[6]等。
进入21世纪以来,有数项涉及词类划分的语言工程得以实施并向学界公布其成果。语料库词类标注是动态的词类标注,通常依据上下文为兼类词选择合适的词类,这方面的词类标注工程包括北京大学《人民日报》词语切分和词性标注语料库[7]、教育部语言文字应用研究所词语切分和词性标注语料库[8]。词典词类标注是静态的词类标注,以词典中收录的词语为对象,将每个词语归入一个或多个合适的词类,这方面的词类标注工程包括《现代汉语词典》第5版[9-10]和第6版、北京大学现代汉语语法信息词典(电子版)[11]。上述动态词类标注工程对数以千万词计的文本进行基于上下文的词类标注,静态词类标注工程则对数以万计的词语进行词类划分。
迄今为止,汉语词类问题仍然是一个颇有争议的问题。从不同的角度去看词类问题,所看到的难点和争议是不同的。从语言学的角度看,汉语词类问题的焦点是名物化及相关问题[12-13],侧重静态词类划分;从计算机词类标注的角度看,汉语词类问题的焦点是常用兼类词和未登录词的标注,名物化问题也是兼类词标注中的一个重点和难点所在,更侧重动态词类标注[14-15]。
本文不涉及词类划分标准的理论讨论,而是试图通过对两项词典词类标注工程——《现代汉语词典》第5版[以下简称DCC(Dictionary of Contemporary Chinese)]和北京大学现代汉语语法信息词典[电子版,以下简称GKB(Grammatical Knowledge-Base Dictionary of Contemporary Chinese)]的整体比较,求同存异,通过定量分析弄清楚静态词语归类的分歧有多大,分歧(词类对应)的种类有多少,各自的原因是什么。
本文剩余部分组织如下: 第二节提出一个用于求同存异的自动对应算法,基于该算法对DCC和GKB进行比较,将词类相同的和不同的对应实例分开来,进而依据词类数量是否相等将词类不同的对应实例区分为两类;第三节和第四节分别对两类对应实例进行分析;最后是结语。
2 静态词语归类结果自动对应
DCC和GKB是两个代表性的词类标注工程,其表现形式均为静态的词语归类,涉及数万个词语,每个词语被归入一个或多个词类。对DCC和GKB的词类标注结果建立对应关系时,第一步是建立两者词类体系的对应,第二步则是建立词语级的对应。通过词类对应工作,可以揭示出两部词典词类划分结果的分歧。
2.1 词类体系对应关系
正如Qiu等[16]所说,DCC和GKB的词类体系大体上是一致的。GKB的基本词类数为18类,包括名词(n)、动词(v)、形容词(a)、数词(m)、量词(q)、代词(r)、副词(d)、介词(p)、连词(c)、助词(u)、叹词(e)、拟声词(o)、时间词(t)、方位词(f)、处所词(s)、区别词(b)、状态词(z)、语气词(y)。DCC的基本词类为12个,正好是上述18个词类中的前12个;DCC的名词、形容词又分别有附类时间词、方位词、属性词、状态词,正好与GKB中的时间词、方位词、区别词、状态词相对应。GKB的词类中仅有处所词和语气词在DCC中没有独立的词类或附类与之对应。
此外,GKB和DCC中还收录了小于词的单位(语素)和大于词的单位(成语、习用语、缩略语等)。GKB对成语、习用语、缩略语和语素的标记分别为i、l、j、g,并且对语素进一步区分名语素(Ng)、动语素(Vg)、形语素(Ag)、副语素(Dg)等。DCC没有为不成词语素、成语、习用语、固定词组和其他熟语标注词类。DCC中动词下还有助动词和趋向动词两个附类,本研究中暂不考虑这两个附类。
整体上,GKB中有40个词类标记: 18个基本词类标记,三个大于词的单位标记,一个标点符号标记(w),非语素字标记(x),前接成分标记(h)和后接成分标记(k),15个语素细分类标记;DCC中有17个词类标记: 16个基本词类标记,一个语素标记。

2.2 个体词语词类对应关系
个体词语间的词类对应关系可分为四种情况: ①义项相同,词类相同;②义项不同,词类相同;③义项相同,词类不同;④义项不同,词类不同。由于义项对应工作量过大,有必要对问题进行适当简化。本文的研究目标是找出词类划分差异即第③种对应。为实现这一目标,我们的策略是: 首先找出词类不同的对应关系(含第③和第④种对应),接下来再依据义项是否相同对词类不同的对应关系进一步区分;前一步自动进行,后一步人工进行。前一步中所使用的词类对应关系判定规则为:
如果某词语w在GKB中被归入词类t,在DCC中也被归入词类t,则可以认为两个词典中该词语在词类t上对应成功,判断为词类相同;
反之,如果词语w仅在一个词典中被归入词类t,则两个词典中该词语在词类t上对应失败,判断为词类不同。
基于上述规则找出的词类划分差异(对应失败)分属于上述第③和第④两种情况,即义项可能相同,也可能不同。第④种情况本质上属于义项收录差异,并不属于词类划分差异,相对于第③种对应所占比例较小。通过人工判断义项是否相同,可以将第③、④两种情况区分开来,对义项不同的现象予以特别说明(称之为伪对应),将之与事实上的不等值对应现象(称之为真对应)区分开来。
2.3 自动对应算法
基于上述分析,本文的自动对应算法如下。
遍历两个词典中的所有共有词语,设当前词语为w:
(1) 如果词语w在DCC中没有词类标记,在GKB中词类标记为“i”或者“l”,则将该词语归入第一类,对应结束;
(2) 如果词语w在两个词典中的词类标记数量不相等,则对应失败,将该词语归入第四类,对应结束。
(3) 如果词语w在两个词典中的词类标记数量相等,则遍历GKB中w的所有词类标记,设当前标记为tg:
① 如果tg为i、j、l、g、x五个标记中的一个,则对应成功,继续处理下一个词类标记;
② 如果DCC中w的词性标记中包含tg,则对应成功,继续处理下一个词类标记;
③ 否则,遍历DCC中w的所有词类标记,设当前标记为tc:
(a) 如果tc为标记“g”,则对应成功,继续处理下一个词类标记;
(b) 如果GKB中w的词性标记中也含有tc,则对应成功,继续处理下一个词类标记;
(c) 否则,对应失败,将该词语归入第三类,对应结束;
如全部词类标记均已遍历完毕且未遇到对应失败,则将该词语归入第二类,对应结束。
使用上述算法对DCC和GKB进行对应之后,可以将两者共有词语分为四类,分别称为无标记类(第一类,DCC中无词类标记)、等值对应类(第二类,词类标记一一对应)、等数不等值对应类(第三类,词类标记数量相等,但不能一一对应)、不等数不等值对应类(第四类,词类标记数量不相等)。
2.4 自动对应结果
不考虑同形词(汉字相同)的区分,DCC中词语数量为61 992(含单字词和不成词语素),GKB中词语数量为74 148,两者共有词数为46 741。使用自动对应算法进行对应之后,将共有词语分为四类,其数量分别为4 926、36 586、1 584、3 645,如表 1所示。无标记类在DCC中没有词类标记,本文中不对之进行深入分析。
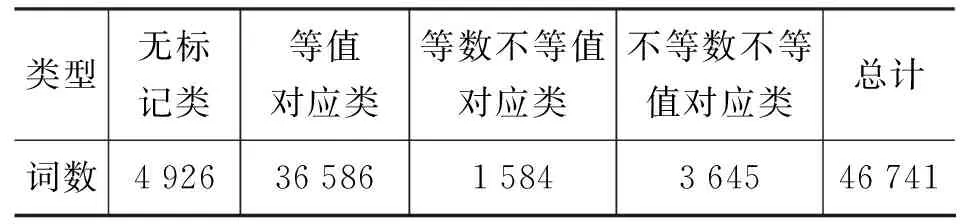
表1 GKB和DCC词类对应结果
等值对应类(第二类)数量最多,占78.3%;如果不考虑无标记类的话,第二类占比将达到83.5%。这说明两部词典中大部分词语词类标记是完全对应的。等值对应的词语词类数量的分布为: 34 844个词的词类数为1,1 525个词的词类数为2,171个词的词类数为3,34个词的词类数为4,10个词的词类数为5,1个词的词类数为6,1个词的词类数为7。其中,词类数为6和7的词分别为“重”和“和”。在DCC中两者的词类分别为: ['a', 'd', 'g', 'n', 'q', 'v'] 和['a', 'c', 'g', 'n', 'p', 'q', 'v']。在GKB中两者的词类分别为: ['Ng', 'a', 'd', 'n', 'q', 'v'] 和['Ag', 'Ng', 'c', 'n', 'p', 'q', 'v']。对比之下,可以发现,在DCC中两个词均有部分义项标记为g,我们的对应规则对g进行了模糊对应,因此可以将“重”和“和”识别为等值对应。
值得注意的是,等值对应并不意味着词类划分就没有任何争议,比如“机要”一词,两个词典中均归为区别词。DCC中的释义为“机密重要的”,所举的例子有“~工作”、“~部门”、“~秘书”。“机要工作”和“机要部门”可以理解为“机密重要的工作”和“机密重要的部门”,但“机要秘书”并不宜理解为“机密重要的秘书”,而应为“处理机密重要事务的秘书”,其中的“机要”与“参与军政机要”中的“机要”相同,均指“机密重要的事务”。因此,“机要”应兼属名词和区别词。但是,这种有问题的词类划分是比较罕见的。
在绝大多数情况下,等值对应意味着两个词典对词语词类做出相同的划分,而不等值对应意味着两个词典在词类划分上存在分歧,本文接下来将重点分析包含在等数不等值对应和不等数不等值对应中的分歧。
3 等数不等值对应分析
当两个词类标记数量相等,但不能一一对应时,先把能够对应上的词类挑出来,将剩下的词类标记当作关键字,从而可以将等数不等值对应类进行细分。据此,可以将等数不等值对应类词语进一步分为101小类。考虑到篇幅原因,本文未对GKB中标记为不成词语素的情况进行分析,仅涉及剩余的70小类,如表 2所示(见下页)*完整对应列表可从http://pan.baidu.com/s/1c1zNcZY下载。。表2有两列。第一列是对每个小类的描述,以逗号将各属性分开,分别表示GKB中的词类、DCC中的词类、该小类词语数(从1到268不等)、例词(至多给出三个)。该表格以GKB词类代码的升序排列,再以词语数降序排列;第二列是下面划分的对应关系类别的编号。以表2中的第一个小类为例,该类的描述为“a,v,101,多疑、够格、畏难”,表示GKB中的词性为“a”,DCC中的词性为“v”(GKB中归为形容词,而DCC中标为动词),此类词的数量为101个,例词为“多疑、够格、畏难”。该小类的对应关系类别编号是31,即属于增加迁移型。
进一步分析表 2,可以发现其中的对应关系形成不等值对应的原因各不相同,可以分成四种类型,第三、四类还可以进一步分成几个小类。
第一类,覆盖型对应(表 2中标记为1)。这一类是因为两种体系词类粒度大小不同造成的,一个体系的某一词类对应着另一个词类体系中某一词类的并未明确划分出来的子类。有两个小类属于此种对应: “y,u,16,呀、哇、嘛”表示GKB中的语气词实际对应DCC中助词的某个子类;“s,n,78,天底下、暗地里、路上”表示GKB中的处所词实际对应DCC中名词的某个子类。
第二类,伪对应(标记为2)。这一类对应是因为词语在两部词典中的义项不同(即不具有同一性)造成的,这些小类所涉及的词语通常较少。例如,“y,n,1,也”,在两部词典中“也”均有助词词类,在DCC中“也”有多个助词义项,其中一个对应GKB的语气词,但是均被我们的算法视为等值对应(助词对应助词),使得GKB中的语气词对空了,DCC中恰好又多出一个“也”充当姓氏的名词义项,从而产生了“y,n”对应。两者义项不同,因此是一个伪对应。属于此类的还有“u,m,1,一般”,“q,d,1,轮次”,“s,v,1,上身”,“f,v,1,顶头”,“h、j,g、n,1,以”,“j、v、x,g、n、q,1,摩”,“k,n,1,者”,“m,d,1,左右”等。
第三类,迁移型对应(标记为3)。这一类对应是因为某一类词功能正在变化之中,朝另一个词类迁移所形成的。根据迁移后功能增加还是减少,可以进一步分为增加迁移型和减少迁移型。
增加迁移型(标记为31)在迁移过程中原有功能继续保持,同时增加新的功能。比如某些名词本身具有一定的描述性语义特征,可以受程度副词修饰,逐渐向形容词迁移[17-18]。这些词在迁移之后,原本的语法功能通常会保留下来,属于增加迁移型的小类包括: “a,v,101,多疑、够格、畏难”属于动词向形容词迁移,“a,b,9,根本、新式、优质”属于区别词向形容词迁移,“a,n,7,热忱、廉价、清香”属于名词向形容词迁移,等等。
减少迁移型(标记为32)在迁移过程中并不增加新的功能,而是主要功能退化成次要功能或者完全消失,使得次要功能成为主要功能。例如,某些动词性结构或动词在迁移过程中主要充当状语,很少充当谓语,从而逐步向副词迁移。属于减少迁移型的小类包括: “b,n,38,五金、狭义、鸭黄”属于名词充当主宾语的功能弱化,“b,v,26,死难、开国、离心”属于动词充当谓语的功能弱化,“d,v,49,纵步、择优、即席”属于动词充当谓语的功能弱化,“d,a,28,团团、悍然、飒然”属于形容词充当谓语的功能弱化,“d,n,22,起首、冷眼、近来”属于名词充当主宾语的功能弱化,“n,v,133,农垦、言教、海蚀”属于动词性结构充当谓语的功能弱化,等等。
第四类,标准不一型(标记为4)。这一类对应产生的原因是因为两个词类体系判断词类的标准不一致。根据不一致的具体情况可以进一步分为是否依据句法功能标准、是否严格依据句法功能标准、标准是否严密三种情况。
是否依据句法功能标准(标记为41)指的是该词类的判断是否依据句法功能标准,有没有采用诸如意义之类的标准。例如,拟声词(DCC中的定义为“模拟事物或动作的声音的词”)是依据语音形式确立的词类,数词(DCC中的定义为“表示数目的词”)是依据意义确立的词类,代词根据它所指代对象的功能来确定类别,这些词类均不是依据句法功能标准确立的。
是否严格依据句法功能标准(标记为42)指的是虽然依据句法功能标准确定某个词类,但是在具体操作时没有严格依照该标准。例如,DCC和GKB均采用“能够受程度副词修饰”这一标准来判定形容词,但是在执行的严格程度上不一致。GKB严格依据这一标准。DCC中形容词还包括属性词和状态词两个附类,这两个附类都是不能受程度副词修饰的,因而在判定词类时没有严格执行这一标准,例如,“b,a,70,银灰、湖蓝、银白”即属于此种情况。忽略了某种句法功能也属于此类,例如,“z,b,1,全优”这一对应是因为DCC中忽略了“全优”可以充当谓语这一功能造成的。
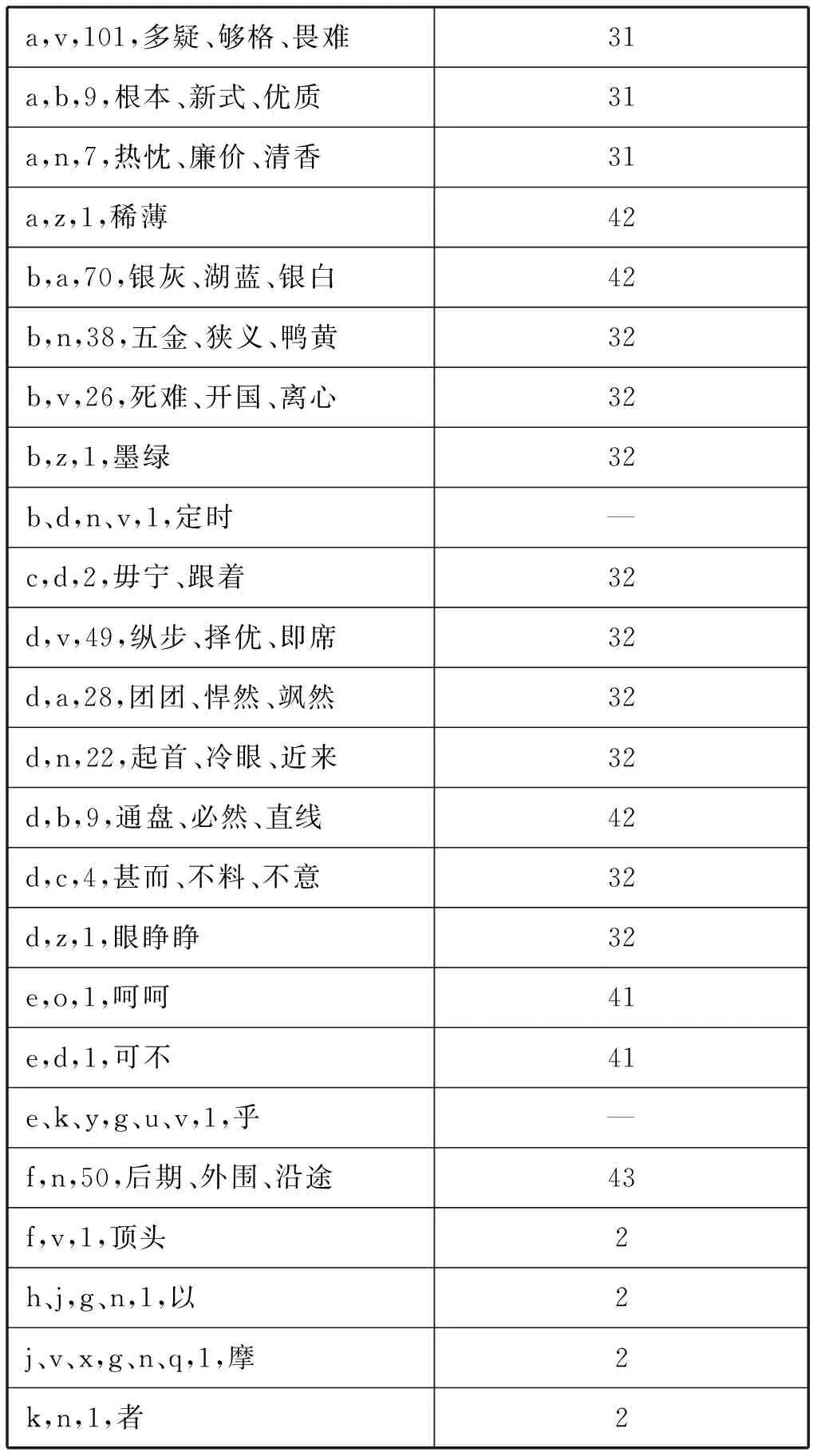
表 2 等数不等值对应细分类
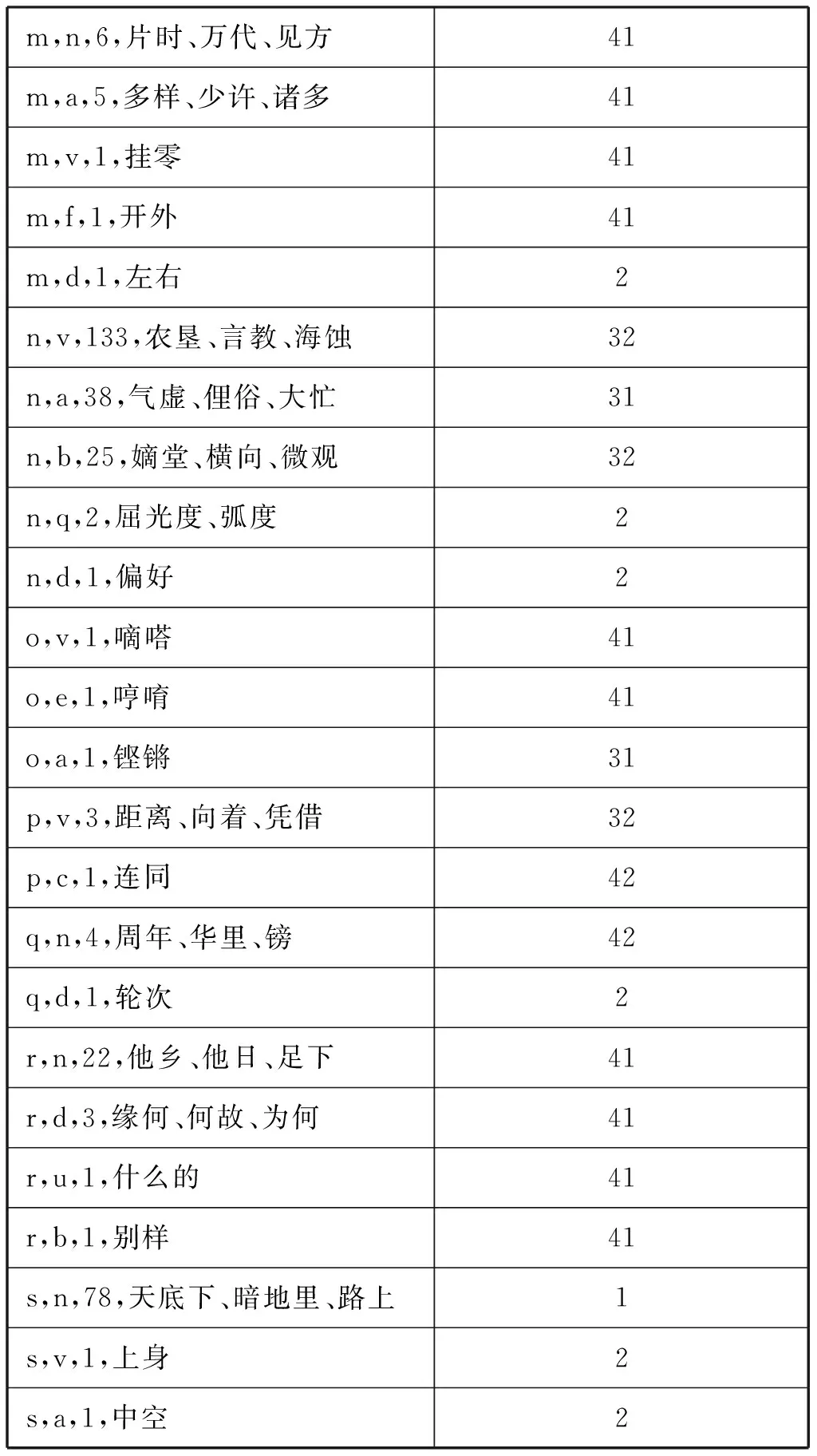
m,n,6,片时、万代、见方41m,a,5,多样、少许、诸多41m,v,1,挂零41m,f,1,开外41m,d,1,左右2n,v,133,农垦、言教、海蚀32n,a,38,气虚、俚俗、大忙31n,b,25,嫡堂、横向、微观32n,q,2,屈光度、弧度2n,d,1,偏好2o,v,1,嘀嗒41o,e,1,哼唷41o,a,1,铿锵31p,v,3,距离、向着、凭借32p,c,1,连同42q,n,4,周年、华里、镑42q,d,1,轮次2r,n,22,他乡、他日、足下41r,d,3,缘何、何故、为何41r,u,1,什么的41r,b,1,别样41s,n,78,天底下、暗地里、路上1s,v,1,上身2s,a,1,中空2
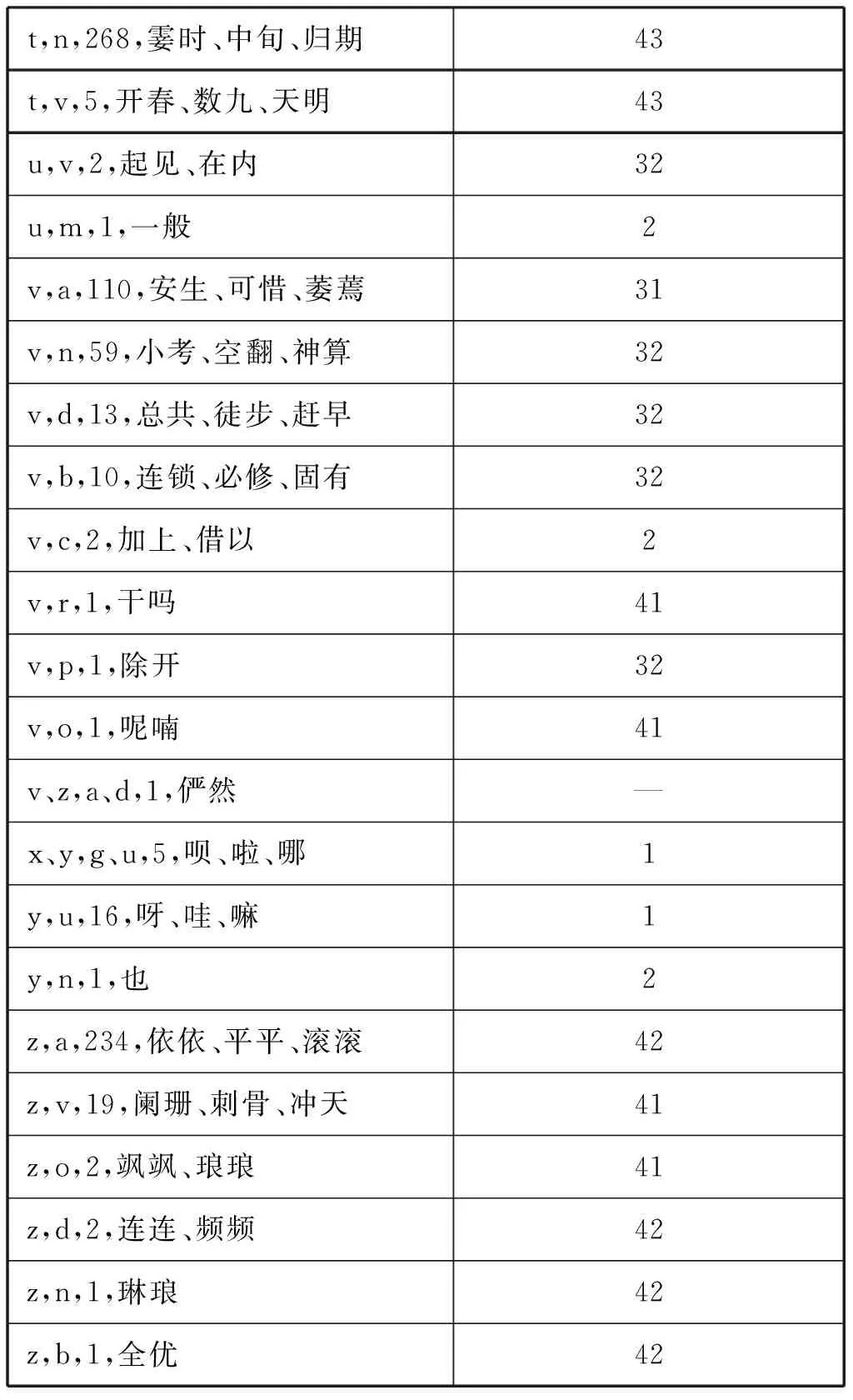
t,n,268,霎时、中旬、归期43t,v,5,开春、数九、天明43u,v,2,起见、在内32u,m,1,一般2v,a,110,安生、可惜、萎蔫31v,n,59,小考、空翻、神算32v,d,13,总共、徒步、赶早32v,b,10,连锁、必修、固有32v,c,2,加上、借以2v,r,1,干吗41v,p,1,除开32v,o,1,呢喃41v、z,a、d,1,俨然—x、y,g、u,5,呗、啦、哪1y,u,16,呀、哇、嘛1y,n,1,也2z,a,234,依依、平平、滚滚42z,v,19,阑珊、刺骨、冲天41z,o,2,飒飒、琅琅41z,d,2,连连、频频42z,n,1,琳琅42z,b,1,全优42
标准是否严密(标记为43)指的是所定的标准是否对外有排他性。例如,DCC中方位词的判定标准是“能够附着在名词的后面构成方位词组,方位词组能够做‘在、到、往’的宾语,部分方位词还能够直接做‘在、到、往’的宾语”,依据这一标准,典型的方位词“上、下、前、后”等没有争议,但是容易与诸如“后期、外围、沿途”之类的词产生纠葛。属于此类的还有“f,n,50,后期、外围、沿途”“m,f,1,开外”。
表 2中将70个小类归入了上述四个类型(少数小类涉及多个类型,暂未归类,标记为“—”)。属于覆盖型对应的只有三个小类。属于伪对应的有13个小类,但每个小类词语均较少。大多数小类属于第三和第四类。第三类主要涉及形容词、区别词、动词、名词四个词类,第四类则主要涉及状态词、叹词、拟声词、方位词、数词、代词、时间词等词类。由此可以看出,多数差异的成因可以归结为词类迁移和词类判断标准不一致。
4 不等数不等值对应分析
依据与上节类似的方法可以将不等数不等值对应类词语细分为421个小类。在不等数不等值对应中,如果一个词在A词典中的全部词类都在B词典中找到了对应词类,而且B词典中多出一个以上的词类,就会导致对空的情况出现,我们称之为B词典对空。在不等数不等值对应中,对空的小类为67个,覆盖1 918个词,占不等数不等值对应类词语的52.6%。
去掉GKB中标记为不成词语素的情况,剩余151个小类,覆盖2 081个词;其中对空的小类为57个,覆盖1 890个词,占151个小类词语的90.8%。
表 3中给出了部分示例。

表 3 不等数不等值对应示例

f、s,n,8,后方、南方、北方f、t,n,1,最后i,b、n,1,清一色i,a、n,1,零七八碎j,b、n,2,短平快、环保t,n、v,5,当前、立春、立冬t,空,3,春秋、青年、雨水t,a、n,1,清明u,空,2,不过、一样v,空,53,祝辞、空缺、明晰v,g、n,8,恋、即、掬v,b、n,2,高产、主导v,a、n,2,反感、喜庆v,a、d,2,可能、顺道v,a、g、n,1,淘v,a、c,1,相反y,u、v,1,罢了y,n、u,1,兮y,a、u,1,得了y,a、u、v,1,不成z,a、d,4,等闲、正好、笃定z,d、v,2,依旧、依然z,a、o,2,萧萧、萧瑟

z,a、n,2,上乘、孤寡z,d、n,1,绝顶z,b、v,1,漫天z,b、n,1,锦绣空,n,441,早已、警觉、体面空,v,387,开心、呱唧、蘑菇空,g,256,河、拂、配空,a,223,平定、纵横、开展空,b,90,什锦、机制、机关空,d,68,大事、好赖、大小空,g、n,61,截、择、阔空,q,12,把子、方寸、方丈空,c,10,惟有、鉴于、何如空,a、n,8,下饭、慢性、长年空,a、v,6,隐秘、冤屈、罗锅空,n、v,4,狠心、矛盾、热闹空,m,4,万般、百般、一度空,g、q,4,版、背、茎空,d、n,4,多少、每、正经空,b、v,4,具体、经济、朝阳空,a、g,4,逗、团、竖
首先看对空的情况。DCC对空的小类为38个,覆盖1 613个词;GKB对空的小类为19个,覆盖277个词。比较之下,DCC对空的情况要远远多于GKB对空的情况。DCC对空的情况多数是因为DCC中收录了更多的义项造成的。比如DCC中“告白”兼收名词和动词,前者指“(机关、团体或个人)对公众的声明或启事”,后者指“说明;表白”;GKB中则漏收了后一个义项。又如GKB中漏收了“印记”的动词用法,DCC中的释义为“把印象深刻地保持着”。漏收的义项中,有的是现代汉语中比较常用的义项(如“告白”的动词用法),有的则是偏文言或书面的用法(如“印记”的动词用法)。
GKB对空的情况相对较少。其中有些是因为GKB收录了更多的用法造成的,比如“d,空,65,公费、头等、通常”这一类中多数是因为GKB中考虑了这些词语充当状语的用法,而DCC中没有涉及这些用法。还有一些是因为归类标准问题。比如“a,空,23,普及、权威、压抑”类中“普及、压抑”等词受程度副词修饰时不能带宾语,GKB因此将之归为动形兼类,而DCC将之统一为动词,两者所用的判断标准不一致。
对空的情况可以根据等值对应的词类做进一步分类。比如“空,a,223,平定、纵横、开展”可以进一步分为: “v,114,鼓舞、飘浮、鞠躬”(两词典中的相同词类为v,后同),“t,1,后来”,“n,93,高寿、马大哈、馨香”,“d,11,顺脚、霍然、正巧”等几种情况。在这几种情况中,DCC中均多出一个形容词的词类。
其次看非对空的情况。此类情况涉及词语总量较少(191词),每个类别涉及的词语多数只有一个或两个,需要一一具体分析。受篇幅限制,本文暂不对对空的情况和非对空的情况进行详细分析。
总体而言,不等数不等值对应与等数不等值对应的情况有较大差异: 等数不等值对应大多数是因为词类处于迁移状态或者词类判断标准不一致造成的,不等数不等值对应大多数则是因为词典所收录的义项不一致而形成的。比较之下,等数不等值对应只涉及词类问题本身,而不等数不等值对应则更多地涉及词义问题。
5 结语
本文考察了《现代汉语词典》和《语法信息词典》在词类划分上的异同, 重点对两者词类划分存在差异的地方进行了分析。分析结果表明: ①两部词典大部分(83.5%)共有词语的词类标记是相同的;②存在差异的地方一部分是因为收录的义项不同而造成的,涉及词义问题,不是单纯的词类问题;③只有一小部分差异是因为词语语法功能处于变化之中或者词类判断标准不一致而产生的,属于单纯的词类问题。后者应该是词类问题研究的重点所在,我们将在今后的工作中对相关词语逐一进行分析,以更清晰地揭示汉语词类问题的分歧,进而建立更为完善的词类标记体系。
[1] 马建忠. 马氏文通[M]. 北京: 商务印书馆, 1998.
[2] 邵敬敏. 汉语语法专题研究[M]. 北京: 北京大学出版社, 2009.
[3] 吕叔湘. 汉语语法分析问题[M]. 北京: 商务印书馆, 1979.
[4] 朱德熙. 语法讲义[M]. 北京: 商务印书馆, 1982.
[5] 袁毓林, 马辉, 周韧, 等. 汉语词类划分手册[M]. 北京: 北京语言大学出版社, 2009.
[6] 郭锐. 现代汉语词类研究[M]. 北京: 商务印书馆, 2002.
[7] 俞士汶,段慧明,朱学锋,等. 北京大学现代汉语语料库基本加工规范[J]. 中文信息学报, 2002,16(5): 49-64.
[8] 靳光瑾,肖航,富丽,等. 现代汉语语料库建设及深加工[J]. 语言文字应用, 2005(2): 111-120.
[9] 中国社会科学院语言研究所词典编辑室. 现代汉语词典[M]. 第5版. 北京: 商务印书馆,2005.
[10] 徐枢, 谭景春.关于《现代汉语词典(第5版)》词类标注的说明[J]. 中国语文, 2006(1): 74-86.
[11] 俞士汶, 朱学锋,等. 现代汉语语法信息词典详解[M]. 第2版. 北京: 清华大学出版社,2003.
[12] 沈家煊. 我只是接着向前跨了半步: 再谈汉语里的名词和动词[J]. 语言学论丛, 2009, 40: 3-22.
[13] 沈家煊, 乐耀. 词类的实验研究呼唤语法理论的更新[J]. 当代语言学, 2013(3): 253-267.
[14] 刘一佳, 车万翔, 刘挺, 等.基于序列标注的中文分词、词性标注模型比较分析[J].中文信息学报, 2013,27(4): 30-37.
[15] 王丽杰, 车万翔, 刘挺. 基于SVMTool的中文词性标注[J]. 中文信息学报, 2009,23(4): 16-22.
[16] QIU Likun, ZAN Hongying, ZHU Xuefeng, YU Shiwen. A Preliminary Contrastive Study on the Part-of-Speech Classifications of Two Lexicons[C]//Proceedings of CLSW 2015, 2015: 516-523.
[17] 施春宏. 名词的描述性语义特征与副名组合的可能性[J]. 中国语文, 2001(3): 212-224.
[18] 俞士汶, 段慧明, 朱学锋.词语兼类暨动词向名词漂移现象的计量分析[C]. 孙茂松, 陈群秀.自然语言理解与大规模内容计算. 北京: 清华大学出版社, 2005: 70-76.
[19] 赵慧.《现代汉语词典》与《现代汉语语法信息词典》词类标注比较研究[D].鲁东大学硕士学位论文,2016.

邱立坤(1979—),博士,副教授,主要研究领域为计算语言学、语料库语言学。
E-mail: qiulikun@gmail.com

赵慧(1989—),硕士研究生,主要研究领域为计算语言学。
E-mail: 353607498@qq.com

俞士汶(1938—),教授,主要研究领域为计算语言学、语言知识库。
E-mail: yusw@pku.edu.cn
AnalysisofParts-of-speechCorrespondenceBetweenDCCandGKB
QIU Likun1, ZHAO Hui1, YU Shiwen2, 3, ZHU Xuefeng2
(1. School of Chinese Language and Literature, Ludong University, Yantai, Shandong 264025, China;2. Key Laboratory of Computational Linguistics at Peking University, Ministry of Education, Beijing 100871, China;3. Collaborative Innovation Center for Language Ability, Xuzhou, Jiangsu 221009, China)
Part-of-speech annotation has attracted extensive attention from the areas including Chinese information processing, Chinese grammar study and Chinese lexicographer. Multiple part-of-speech systems have been proposed and there are significant differences between these systems. So far, little research has been done to systematically compare different large-scale part-of-speech annotations. Based on the part-of-speech annotation results in Dictionary of Contemporary Chinese and Grammatical Knowledge-Base Dictionary, this paper proposes a mapping algorithm, which can detect part-of-speech differences in two dictionaries automatically. Further, we analyze the differences and conclude in two perspectives. 1) about 83.5% of the part-of-speech annotation results is identical. and 2) all the differences can be attributed to three effects: part-of-speech shifting, different part-of-speech annotation standards and different senses.
Dictionary of Contemporary Chinese; Grammatical Knowledge-Base Dictionary; part-of-speech annotation; part-of-speech correspondence
1003-0077(2017)05-0001-07
TP391
A
2017-03-03定稿日期2017-05-10
国家自然科学基金(61572245);国家重点基础研究发展计划(2014CB340504);国家社会科学基金(15BYY094)
