基于FPGA的一种针对小波变换的快速流水线结构设计∗
2017-11-17常文利
常文利
(宝鸡职业技术学院 宝鸡 721013)
基于FPGA的一种针对小波变换的快速流水线结构设计∗
常文利
(宝鸡职业技术学院 宝鸡 721013)
提出一种适用于硬件的改进9/7提升小波变换模块的实现方法,以此建立一种针对小波变换的快速流水线结构,以满足系统高速运行的要求并针对图像需要二维变换的要求,提出了一种新的基于行的列变换结构,可以有效减小系统延迟及缓存需求。在FPGA上实现变换功能系统,外部数据输入后先进行边界延拓,然后开始行变换,由于在行列变换模块中有着大量的加法和乘法运算,数据读写操作等,在设计中使用了行列变换并行的处理方式,可以使图像的行变换与列变换同时进行,缓存数据保存在片内RAM中,一级变换的系数采用片外RAM存储以加快系统处理速度。
小波变;提升算法;快速流水线结构;图像处理
1 引言
目前小波变换是图像压缩领域应用最广泛的算法,但实际上小波变换本身并没有压缩能力[1],只是小波变换可以把图像分解成各个重要性不同的子图像[2],之后需要对子图像进行编码处理才能完成整个压缩过程[3]。本文改变了原始的小波变换公式,将预测和更新两个步骤的公式进行合并,并以此设计适合硬件实现的小波变换结构,同时加入了流水线的技术,提高了处理速度,最后在FPGA实现该结构。
2 改进的9/7小波变换算法
2.1 9/7小波变换
基于提升算法的离散9/7小波变换结构如图1所示,通常由一个分裂环节、一个预测环节和一个更新环节构成[4]。从图1中还可看出,提升变换和提升反变换的结构对称、运算符号相反,因此可以使用变换结果重构出原始信号,即这是一种可逆变换。
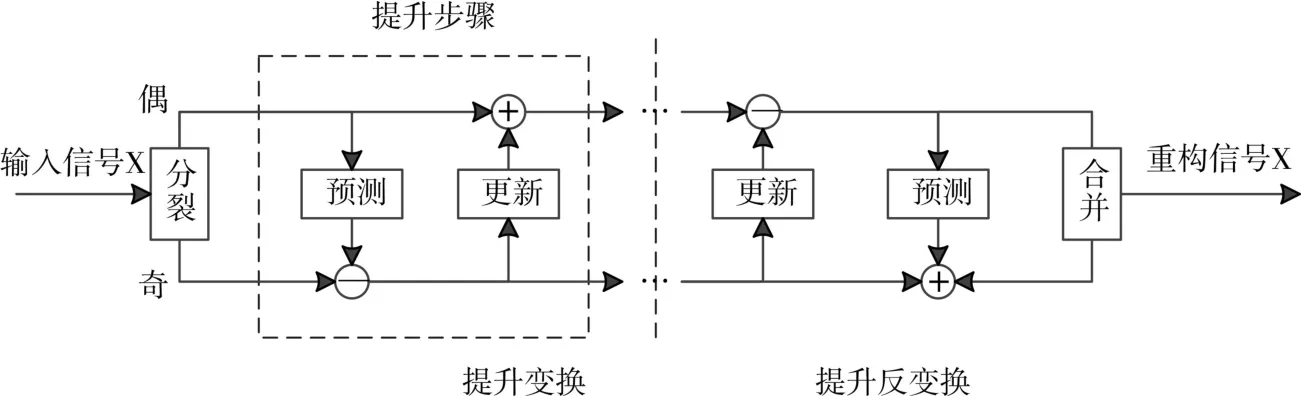
图1 提升小波变换和反变换示意图
9/7小波的提升步骤[5]:首先,将输入序列 xi分裂成奇偶两个部分和(i=0,1,2……)。


最后,通过归一化因子k,可以得到低通及高通小波系数si、di。

2.2 改进提升算法
在流水线设计方法中,两个寄存器之间的关键路径上的延迟在传播延迟中占主导地位[6]。由于在直接映射的硬件结构中,传播延迟主要存在于预测和更新步骤,本文将式(3)代入式(4)之中,将预测和更新合并成一个表达式。可以使得流水线中的每一级只有一次加法或乘法。
第一次提升步骤公式可以写成:
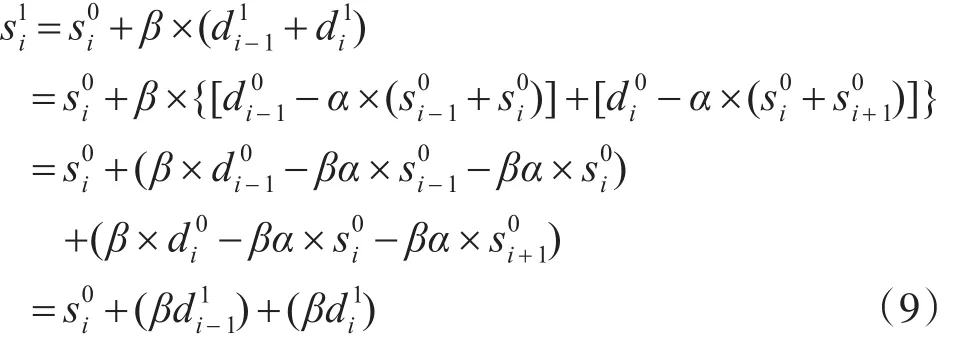

最后,归一化步骤可以表示为

依据修改后的提升算法,式(9)到(12)中使用的六个系数为:β,βα,δ/β,δγ, -k/δ,1/k 。由于原始的滤波器系数都是无理数,不适用于硬件,文献[7]提出了一组新的滤波器系数:

这组系数只需要很少的浮点数计算,极大的方便了硬件实现。将其运用于本文设计之中,如下表所示:β =-0.0625,βα =0.09375,δ/β =-7.5,δγ=0.375,-k/δ=-2.41359,1/k=0.88388。
3 系统方案设计
根据自上而下的设计思想,设计出图2所示的系统结构[8]。
外部数据输入后先进行边界延拓,然后开始行变换,由于在行列变换模块中有着大量的加法和乘法运算,数据读写操作等,在设计中使用行列变换并行的处理方式,使图像的行变换与列变换同时进行[9]。缓存数据保存在片内RAM中,一级变换的系数采用片外RAM存储以加快系统处理速度[10]。系统结构图如图3所示。

图2 二维小波正变换框图

图3 系统结构图
4 关键模块设计
4.1 边界延拓模块
图像数据是有限的,小波变换后会发生严重的边界效应,会降低重构图像的质量。边界延拓算法非常重要,对称延拓法是将原始图像对称的进行延拓,所以能够避免周期延拓中边界不连续性的缺点,本文选用对称延拓法。在使用FPGA进行硬件实现时,是以信号端点为对称轴,进行对称延拓。以一组8点数据x(0)、x(1)、x(2)、x(3)、x(4)、x(5)、x(6)、x(7)为例,在输入数据时,先读入左边界x(0)后面的第三、二个数据x(2)、x(1),接着按顺序读入图像数据,最后在右边界后再延拓一个数据x(6),使序列变成 x(2)、x(1)、x(0)、x(1)、x(2)、x(3)、x(4)、x(5)、x(6)、x(7)、x(6)。
4.2 行变换模块
行变换模块即对图像的每一行分别进行DWT变换,即1-DDWT。为了提升系统的运行速度,在行变换模块中运用了流水线技术。DWT变换有两次提升变换,因为二次提升变换计算公式相似,对第一次提升变换进行研究。通过改进后的计算公式,第一次提升变换的数据流图如图4所示。
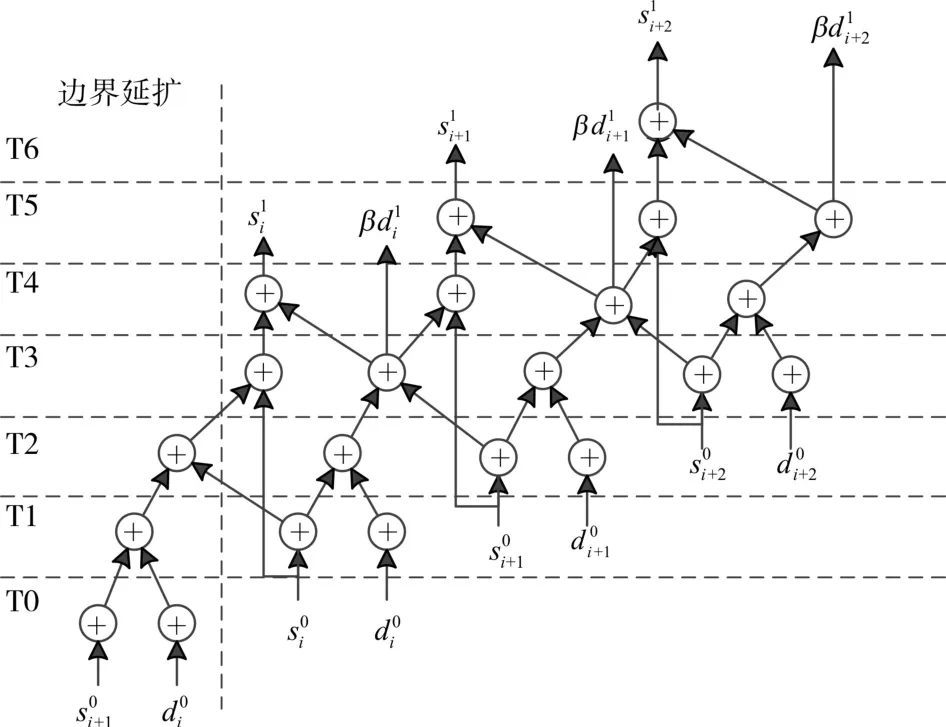
图4 流水线结构的数据流图
根据该数据流图,构建新的流水线结构,如图5所示。每级流水线通过虚线相隔,并将此定义为一个处理单元,其中包含2个乘法器和4个加法器。一个完整的9/7小波变换结构包含两个处理单元。此外,需要2个额外的乘法器完成归一化步骤。
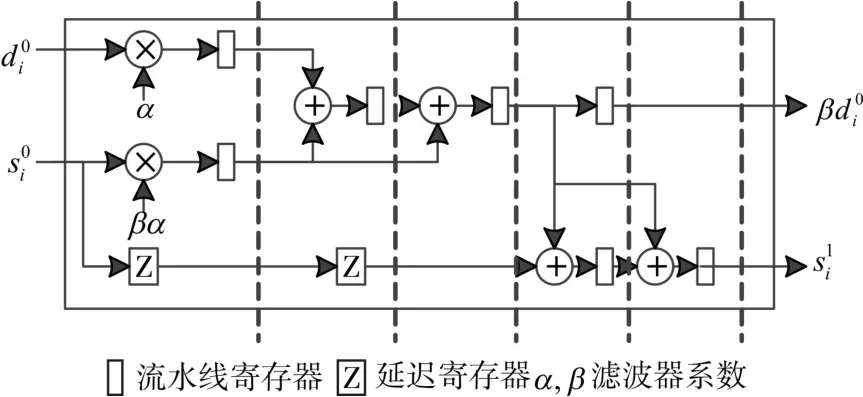
图5 处理单元硬件实现结构图
关键路径中两个寄存器之间只有一个乘法器或加法器,和传统直接映射结构的两个加法器加一个乘法器相比大为减少,因此可以工作在更高的时钟频率下。
利用Verilog Hdl语言编写行变换模块相关代码,其关键部分如下所示:
……R4<=R2+R3;begin Z11 <=Z10;R0[11:0]<={d[11],d[11],d[11],d[11],d[11],d[10:4]};R5 <=R3+R4;
R1[11:0]<=s-{s[11],s[11],s[11],s[10:2]};Z12 <=Z11;
R2 <=-R0;R7 <=R5;
R3[11:0]<={R1[11],R1[11],R1[11],R1[11],R1[10:3]};R6 <=R5+Z12;
Z10 <=s;……
在行变换模块中,使用到了乘法器,而由于传统乘法器消耗硬件资源多,且耗时较长,因此,可以改用移位加法来实现常数乘法,同时,采用正则符号编码(CSD编码)来表示滤波器的系数,可以减少移位加法器的数量。
4.3 列变换模块
在完成行变换后,还需要对图像的每一列进行DWT变换,即 2-D DWT[11]。基于行的列变换结构是行、列变换同时进行的。传统方法得到一组DWT输出需要9个输入数据,所以在得到9行行变换结果后,才可以进行列变换。本文提出一种改进方案,如图6所示,只需要完成3行行变换,即可开始列变换,从而极大地减少了存储器的消耗与系统的延迟。
列变换模块的具体步骤为:在T2时刻,读取缓存器1中的计算上一组数据时得到的寄存器r3中的值。在T3时刻,将寄存器r3中的值存入缓存器1中以供下一组数据使用。在T5时刻,读取缓存器2中的计算上一组数据时得到的寄存器r9中的值。在T6时刻,将寄存器r9中的值存入到缓存器2中,同时,读取缓存器3中计算上一组数据时得到的寄存器r11中的值。在T7时刻,即可得到最终输出了;同时将寄存器r11中的值存入缓存器3中。本文中使用3个缓存器,可以通过FPGA上的FIFO来实现。

图6 列变换数据组织
4.4 控制模块
控制模块,是控制整个小波变换系统的各个子模块协调工作。本文使用状态机来完成控制模块的设计,其状态图如图7所示。
模块初始时处于空闲状态,当收到外部使能信号后开始工作。首先起作用的是边界延拓模块,该模块根据延扩算法产生待变换数据的地址,将数据传入行变换模块。进入读取行状态后,启动行计数器和像素计数器,开始依照顺序处理每个输入,若像素计数器达到预设的数值,就表示完成了一行数据的读取;在行像素变换状态中,模块完成图像行方向的提升变换。一行变换完成后,会作为中间结果暂存入内部RAM中。内部RAM可以存储7行数据,当存满后,列读取使能状态发出使能信号,开始读取列操作,当列计数器到达设置的数值时,结束读取列操作。最后将变换结果写入外部存储器中,在写入列状态中生成待写入的地址,当外部存储器使能后,依次写入最终结果。在写操作结束后,判断行计数器是否达到设置的值,即是否所有行都已变换结束。若还没有完成全部数据的变换,则再次转入行读取状态,重复上述状态转换流程,同时,每当行计数器的值增加3,开始一次读取列操作。若已达到设置值,则判断列计数器是否也已达到设置值,若都达到,则表示所有图像数据已完成小波变换,此时状态机进入等待状态,等待下一幅图像的变换。
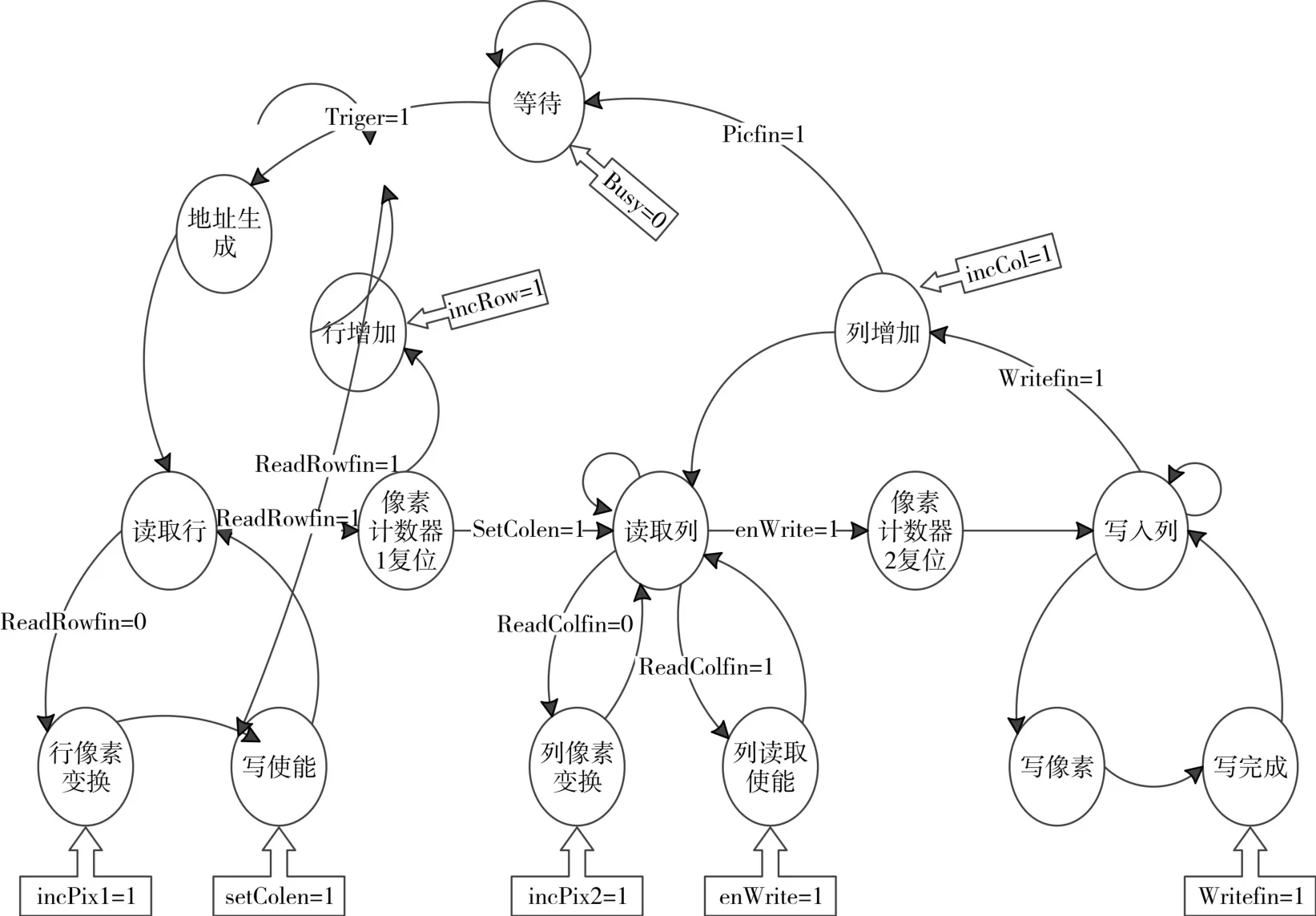
图7 控制单元状态机状态图
4.5 片外存储模块
片外存储模块的作用是保存变换结果,主要作用有两个,第一为生成待写入地址,第二是对将结果写入SDRAM的过程进行控制。变换结果分为LL、LH、HL和HH四个子带,这些子带的系数相互交织在一起,如图8(a)所示。为了便于后续处理及后期的图像显示,须要分别存储各个子带,如图8(b)所示位置。
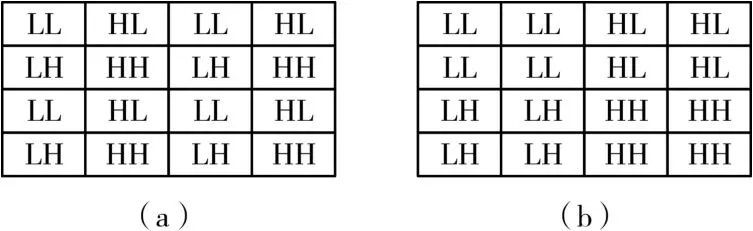
图8 小波系数存储分布示意图
模块功能通过定义状态机来完成,状态机共有5个状态,分别为:等待、写LL系数、写LH系数、写HL系数、写HH系数。其状态图如图9所示。

图9 片外存储模状态图
模块中设置了四个计数器,分别为LL计数器、LH计数器、HL计数器和HH计数器。首先将写操作所要消耗的时钟数传入计数器中,并通过设置初值的方式分配存储器的初始地址。将LL系数存入SDRAM的左上部分,LH系数存入SDRAM的左下部分,HL系数存入SDRAM的右上部分,HH系数存入SDRAM的右下部分;即LL计数器的初始值为零,LH计数器以图像列数的二分之一为初始值,HL计数器以图像行数的二分之一为初始值,HH计数器以图像数据中心点处坐标为初始值。当收到控制模块传入的写使能信号后,则各个计数器开始工作。若计数器达到设定的时钟数,即表示数据已全部写入,将计数器值复位,回到等待状态,并将写完成信号传入控制模块。
5 系统实现与仿真
本文使用ModelSim进行仿真验证,首先需要确定仿真所需的全部信号,并赋予输入信号给定的值,经过仿真软件的仿真后,便可以得到待观察信号的时序图10。clk是50Mhz的全局同步时钟;RSTn为复位信号,低电平有效;shuju为原始图像数据;当enable处于低电平时,模块处于工作状态;hang为行计数器,lie为列计数器;q_hang为行变换结果,q_lie为列变换结果。
仿真开始,首先要设置输入信号的波形,然后设置仿真时间,本文采用默认设置。

图10 提升小波变换仿真时序图
图10 为提升变换的仿真时序图,通过比较可以发现:输入信号shuju与输出信号q_hang,q_lie之间的关系符合式10至21所示的9/7提升小波变换算法。
图11右侧是仿真结束后得到的变换结果的开始部分,左侧是使用Matlab得出的变换结果的开始部分,从图中可以看出两者十分契合。
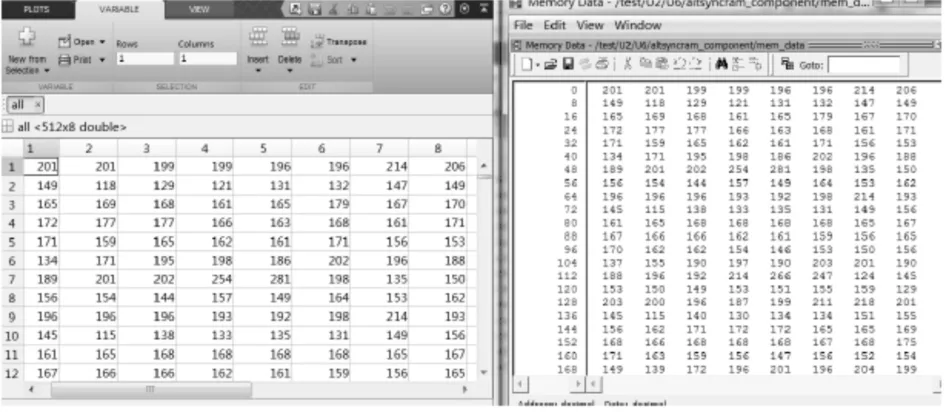
图11 提升小波变换仿真结果
6 结语
在原有提升算法的基础上,进一步改进,设计出了一个适合硬件实现的小波变换结构,并详细介绍了该结构的各个部分的基本原理及实现方法。最后对改进的小波变换结构进行仿真验证,结果表明,本设计法案是有效的。
[1]Karakaya F.Hardware Implementation of Discrete Wavelet Transform andInverse Discrete Wavelet Transform on FPGA[C]//Signal Processing andCommunications Applications Conference,2010:22-24.
[2]Benkrid A,Crookes D.Design and Implementation of a Generic 2-D BiorthogonalDiscrete Wavelet Transform on an FPGA[J].Field-Programmable CustomComputing Ma-chines,2001:190-198.
[3]Chrysafis C,Ortega A.Line-based,reduced memory,wavelet image compression[J].IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society,2000,9(3):378-89.
[4]Adams M D,Kossentini F.Performance Evaluation of Reversible Integer-to-Integer Wavelet Transforms for Image Compression[C]//International Conference on Image Processing,1999.ICIP 99.Proceedings.IEEE,1999:541-545 vol.3.
[5]Wu B F,Lin C F.A high-performance and memory-efficient pipeline architecture for the 5/3 and 9/7 discrete wavelet transform of JPEG2000 codec[M].IEEE Press,2005.
[6]Jung G C,Park S M,Kim J H.Efficient VLSI Architectures for Convolution and Lifting Based 2-D Discrete Wavelet Transform[C]//Asia-Pacific Conference on Advances in Computer Systems Architecture.Springer Berlin Heidelberg,2005:795-804.
[7]Gholipour M.Design and Implementation of Lifting Based Integer Wavelet Transform for Image Compression Applications[M].Digital Information and Communication Technology and Its Applications.Springer Berlin Heidelberg,2011:161-172.
[8]Nath P K,Banerjee S.A high speed,memory efficient line based VLSI architecture for the dual mode inverse discrete wavelet transform of JPEG2000 decoder[J].Microprocessors&Microsystems,2016,40:181-188.
[9]Gall D L,Tabatabai A.Sub-band coding of digital images using symmetric short kernel filters and arithmetic coding techniques[C]//International Conference on Acoustics,Speech,and Signal Processing.IEEE,2002:761-764 vol.2.
[10]Bhanu N U,Chilambuchelvan A.High-Speed Systolic VLSI Architecture for 2-D Forward Lifting-Based DWT[J].Arabian Journal for Science&Engineering,2014,39(8):6125-6135.
[11]Srikanth.S,Jagadeeswari M.High Speed VLSI Architecture for Multilevel Lifting 2-D DWT Using MIMO[J].International Journal of Soft Computing&Engineering,2012,2(2).
A Kind of Quick Assembly Line Structure Design in View of Wavelet Transform Based on FPGA
CHANG Wenli
(Baoji Professional Technology Institute,Baoji 721013)
A kind of realization method suitable for the improvement of hardware 9/7 to promote the wavelet transformation module is put forward to establish a quick assembly line structure in view of wavelet transform,to meet the requirements of the system high-speed operation,and in accordance with the requirements of image two-dimensional transform.A new kind of column transform structure based on the row is put forward,which can effectively reduce system delays and caching requirements.The transform function system is realized in FPGA.After the external data is input,the boundary continuation is firstly proceeded,then row transform starts.Due to a large number of addition and multiplication in the row and column transformation module and the data read and write operations.etc,the row and column transformation parallel processing mode is used in the design.The row transform and column transform of the image can be carried out simultaneously.The cache data is stored in the chip RAM.The level I conversion coefficient uses external RAM storage to speed up the processing speed.
wavelet transformation,improved algorithm,fast assembly line structure,image processing
TN791
10.3969/j.issn.1672-9722.2017.10.040
Class Number TN791
2017年4月8日,
2017年5月27日
常文利,男,讲师,研究方向:电气自动化控制。
