基于信息熵与Mahout的推荐算法的研究∗
2017-11-17林满山
樊 利 林满山
(北方工业大学 北京 100144)
基于信息熵与Mahout的推荐算法的研究∗
樊 利 林满山
(北方工业大学 北京 100144)
针对传统Mahout提供的推荐算法中的噪音数据问题,提出了用户信息熵模型。用户信息熵模型采用了信息论中信息熵的概念,利用信息熵的大小衡量用户信息的含量,利用用户评分数据得到用户的信息熵,过滤信息熵低的用户以及它们的相关数据,从而达到过滤噪音数据的目的。利用Mahout提供的推荐算法,即基于用户的协同过滤,基于物品的协同过滤以及Slope-One推荐算法对该模型进行验证。实验结果表明,该模型可有效过滤噪音数据,并在平均绝对误差上有了一定的降低。
噪音数据;信息熵模型;Mahout;推荐算法
1 引言
随着信息技术的突飞猛进,互联网技术的朝夕更替,大数据时代的泡沫信息使得大量真实有用的信息被隐藏。过量的信息造成了用户选择的困难,使得用户无法有效获取自身所需信息,这既是所谓的信息过载问题[1]。数据挖掘中采集的数据可能会有各种噪声,如缺失数据,或者是异常数据。去噪是非常重要的处理步骤,其目的是在最大化信息量时去除掉不必要的影响。在一般意义上,我们把噪音定义为在数据收集阶段收集到的一些可能影响数据分析和解释结果的伪造数据。在Mahout提供的包括协同过滤在内的多种推荐算法中,噪音数据的问题对算法精确度有着十分重要的影响。我们推断通过预处理来提高数据质量能够简化算法的复杂度,优化系统性能,让海量数据在“清洗”中得以现出真颜。针对协同过滤中噪音的数据问题,国内外学者进行了广泛的研究,常见的有基于统计特征、分类和聚类等研究方法。如Bilge等[2]提出二分决策树的方法,该方法通过迭代执行二分K-means聚类算法生成二分决策树,从而将水军账号和正常用户聚类到不同的簇,达到过滤噪音数据的目的。然而这些方法都需要较为复杂的模型。本文从信息论角度,根据推荐系统的环境中恶意噪声的来源即[6]:网络水军,用户过于随意的评分等得出其评分极端、集中等特征,采用信息熵来衡量用户评分所含信息量的多少,过滤信息熵较低的用户,达到过滤噪音数据的目的。
2 相关工作
1)Mahout作为 Apache Software Foundation 的一个开源项目,提供了大量的轻功能实现,其中实现了包括聚类、分类、关联规则挖掘、回归、降维、协同过滤、进化编程、向量相似度计算、非MapReduce算法、集合方法扩展等机器学习和数据挖掘领域的经典算法,通过使用Apache Hadoop库,Mahout可以扩展到云中[3]。2008推出的开源Apache Mahout是基于Hadoop分布式框架的机器学习算法库。其中cf.taste包实现了推荐算法引擎,它提供了一套完整的推荐算法工具集,同时规范了数据结构,并标准化了程序开发过程[4]。Mahout是Hadoop的子项目。
Mahout框架包含了一套完整的推荐系统引擎,标准化的数据结构,多样的算法实现,简单的开发流程。Mahout推荐的推荐系统引擎是模块化的,分为五个主要部分组成:数据模型,相似度算法,近邻算法,推荐算法,算法评分器。
2)信息熵:1962年,香农(Claude Shannon)在他著名的论文“通信的数学原理”(The Mathematic Theory of Communication)中提出了“信息熵”的概念,解决了信息的度量问题,它主要通过随机变量取值的不确定性程度来刻画信息含量的多少。这里用X表示一个随机变量,X取值为x的概率用p(x)表示,那么可以用信息熵表示它的不确定性程度,H(X)的计算如式(1)所示:
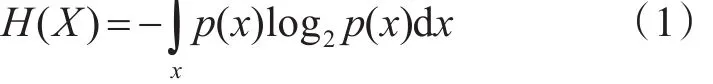
由式(1)可知,信息熵H(X)只与变量X的概率分布有关,而与其具体取值无关。这在某种程度上说明信息熵能有效地避免噪声数据的干扰,可以有效地过滤掉评分系统中评分信息含量少的用户。
3)基于用户的协同过滤[5]:它是基于邻居用户的兴趣爱好预测目标用户的兴趣偏好。算法先使用统计技术寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的偏好产生向目标用户的推荐。它的基本原理[8]是利用用户访问行为的相似性来互相推荐用户可能感兴趣的资源对当前用户,系统通过其历史访问记录及特定相似度函数,计算出与其访问行为(购买的产品集合、访问的网页集等)最相近的N个用户作为用户的最近邻居集,统计的近邻用户访问过而目标用未访问的资源生成候选推荐集,然后计算候选推荐集中每个资源对用户的推荐度,取其中K个排在最前面的资源作为用户的推荐集
4)基于物品的协同过滤[7]:基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。
5)slope-one推荐算法:Slope One是一系列应用于协同过滤的算法的统称。由Daniel Lemire和Anna Maclachlan于2005年发表的论文中提出。有争议的是,该算法堪称基于项目评价的non-trivial协同过滤算法最简洁的形式。该系列算法的简洁特性使它们的实现简单而高效,而且其精确度与其它复杂费时的算法相比也不相上下。
3 基于信息熵和Mahout的推荐算法
3.1 信息熵模型
在一般的推荐系统中,通常会包含两个实体:用户实体与项目实体,分别表示为U={u1,u2,u3,…,um-1,um} 与 I={i1,i2, i3, …, in-1,in}来表示所有用户与项目的ID集合,变量m,n分别表示用户与项目的数目。而我们将用户对项目的评价数据集表示为一个m×n的矩阵R,rui表示用户u对项目i的实际评分。为了使Mahout提供的推荐算法的准确度有所提高,我们引入了用户信息熵模型,对于用户u,其评分集用Su={s1,s1,s1,…,sp} 来表示,在本文情境下的评分系统,其值域为Sm∈{1 , 2,3,4,5} ,其中 p= | Su|表示用户u在系统中产生的评分个数。对于用户u,由信息熵的定义可对应得到其信息熵为
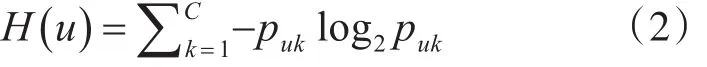
其中C表示评分区间数目,本实验的数据采用5分制,即C=5。 puk是用户u的评分落在区间k的概率,puk的计算过程如下
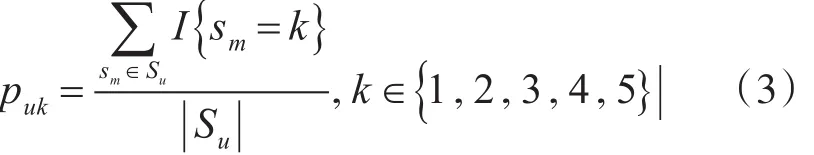
其中I{*}为指示函数,I{t r ue}=1,I{ f alse}=0。由式(2~3)两式即可得到用户的信息熵。为了过滤噪音数据,需要确定系统中的信息熵阈值Ht,即当H(u)<Ht时,则可以过滤掉u的评分信息,以及在用户集中过滤该用户,而Ht的选择可通过十折交叉验证法来获取,Ht的合理选择对推荐算法的推荐精度有着较大影响。原数据处理完成后,由原始评分矩阵R得到的新的评分矩阵RN,显而易见RN的数据质量更高。
3.2 协同过滤推荐算法
协同过滤推荐算法主要有基于用户的协同过滤,基于item的协同过滤以及SlopeOne推荐算法[9]。基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到K邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。基于ItemCF的原理和基于UserCF类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。基于物品的协同过滤算法可分为三个步骤,步骤1:建立物品的同现矩阵,按用户分组,找到每个用户所选的物品,单独出现计数及两两一组计数。步骤2:建立用户对物品的评分矩阵,按用户分组,找到每个用户所选的物品及评分。步骤3:矩阵计算推荐结果,推荐结果是同现矩阵和评分矩阵的乘积,即同现矩阵×评分矩阵=推荐结果。SlopeOne是一种简单高效的协同过滤算法。通过均差计算进行评分。其基本思想是采用平均加权计算。Slope One的核心优势是在大规模的数据上,它依然能保证良好的计算速度和推荐效果。
3.3 Mahout环境下的推荐开发模型
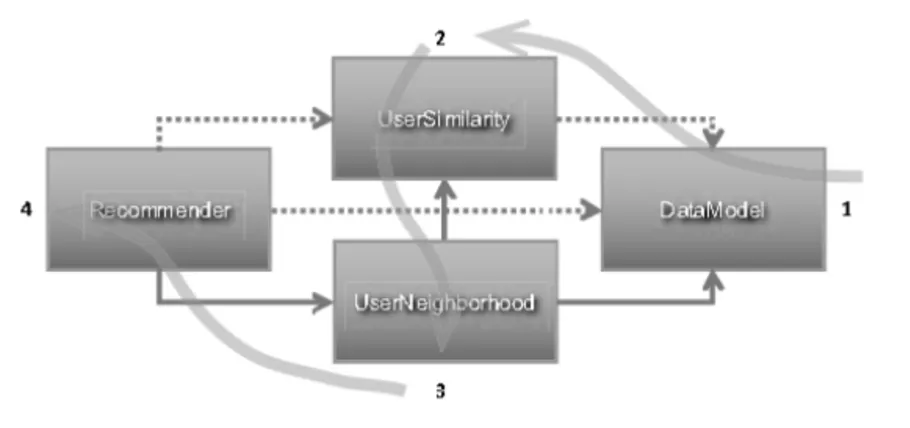
图1 Mahout环境下的开发模型
4 实验与结果分析
本文采用的实验数据为MovieLens(M)数据集,该数据集由明尼苏达大学(University of Minnesota)GroupLens研究院小组提供,其中包含6040名用户和3900部电影,用户评分范围为1~5分,每位用户至少对20部不同的电影进行过评分,总的评分次数为1000209次。数据集的每一行(rating.dat)由用户ID、项目ID、项目评分值与评分时间4个字段构成,数据集被随机分为训练集和测试集。实验使 用 Matlab2014a、Eclipse Mars,jdk1.7,Maven3,Mahout-0.8。
首先计算数据集中每一个用户的信息熵,得到用户信息熵分布图,如图2所示,横轴表示数据集中用户的ID,纵轴表示用户的信息熵值。观察图1中用户的信息熵分布,可以发现绝大部分用户的信息熵值大于1.1,可以认为信息熵偏低的用户的评分数据为噪音数据。
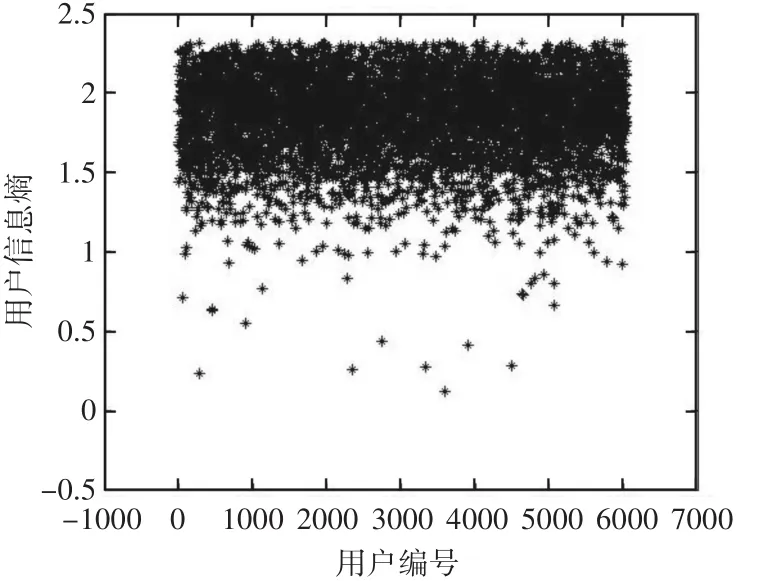
图2 用户信息熵分布图
为了过滤噪音数据,对信息熵的阈值Ht,我们选取了0、0.5、0.8、1.0、1.1、1.2、1.3、1.4这八个值,对每一个值通过十折交叉验证法结合本文提到的Mahout提供的协同过滤推荐算法进行验证,对其均方误差和召回率、准确率做了对比,验证可得在Ht=1.3时,均方误差较小,召回率、准确率最好,Ht=1.4时,均方误差最小,但召回率[10]有所降低。
将完成的数据集作为新的数据集,导入Mahout平台下的推荐算法中,进行实验。本次实验采用的评价指标是平均绝对误差(MAE)。平均绝对误差[11]是所有单个观测值与算术平均值的偏差的绝对值的平均。与平均误差相比,平均绝对误差由于离差被绝对值化,不会出现正负相抵消的情况,因而,平均绝对误差能更好地反映预测值误差的实际情况。其定义为
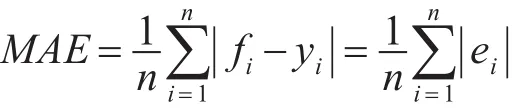
其中 fi为预测值,yi为真实值,ei= ||fi-yi为绝对误差。
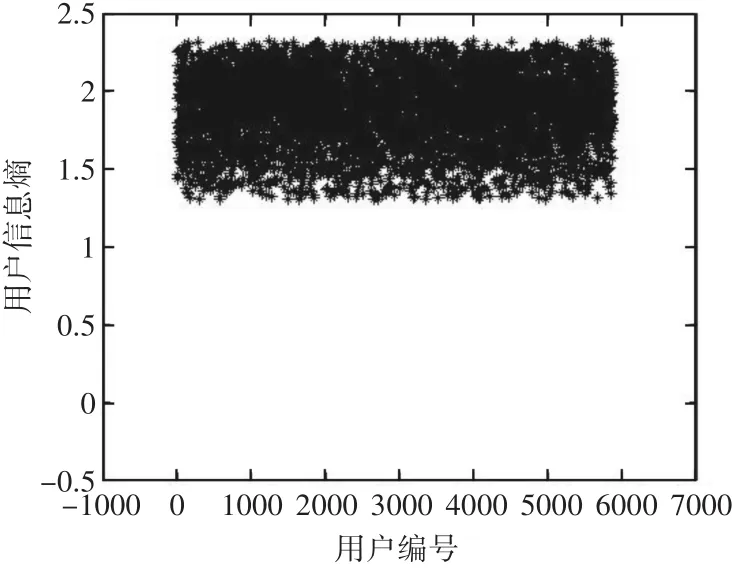
图3 过滤后的用户信息熵分布图
经过七种算法组合的测试,平均绝对误差有所降低。七种算法组合为

结果如图4所示。
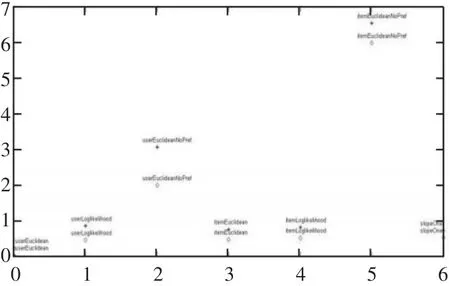
图4 MAE对比图
5 结语
本文提出了用户信息熵模型,解决了一般协同过滤推荐算法中存在的噪音数据问题,同时将用户信息熵模型应用于Mahout平台下的推荐推荐算法,利用该平台提供的多种推荐算法的的组合对该模型进行验证实验结果表明该模型在平均绝对误差上有着良好的表现。然而在过滤噪音数据的过程中,采取的是直接删除噪音数据用户的方式,但是其中不可避免地存在误分类的正常用户,如何能够降低误识率是进一步的研究方向。
[1]许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.XU Hailing,WU Xiao,LI Xiaodong,et al.Comparisonstudy of Internet recommendation system[J].Journal of Software,2009,20(2):350-362.
[2]ALPER B,ZEYNEP O,HUSEYIN P.A novel shilling attack detection method[J].Procedia Computer Science,2014,31:165-174.
[3]ANIL R,DUNNING T,FRIEDMAN E.Mahout in action[M].USA:Manning,2011:66-86.
[4]朱倩.浅谈基于Mahout推荐引擎的构建[J].数字技术与应用,2015(4):44-45.ZHU Qian.Discussion on the construction of the recommendation engine based on Mahout[J].Digital technology and Application,2015(4):44-45.
[5]周涛,李华.基于用户情景的协同过滤推荐[J].计算机应用,2010(4):1076-1082.ZHOU Tao,LI Hua.User context based Collaborative Filtering recommendation[J].Journal of Computer Applications,2010(4):1076-1082.
[6]CHIRITA P A,NEJDL W,ZAMFIR C.Preventing shilling attacks in online recommender systems[C]//WIDM 2005:Proceedings of the 2005 7th annual ACM international workshop on Web information and data management.New York:ACM,2005:67-74.
[7]樊哲.Mahout算法解析与案例实战[M].北京:机械工业出版社,2015:412-116.FAN Zhe.Mahout in Action:Algorithm and Cases[M].Beijing:China Machine Press,2015:412-116.
[8] ARM.Cortex-M0+Technical Reference Manual Rev.r0p0[R.2012.
[9] KOREN Y.Factorizationmeetstheneighborhood:Amulti-faceted collaborativefilteringmodel[C]//Proceedingsofthe14th ACM SIGKDD International Conference onKnowledge Discovery and Data Mining.NewYork:ACM,2008:426-434.
[10]SONG J,LEE S,KIM J.Spam filtering in Twitter using sender-receiver relationship[C]//RAID 2011:Proceedings of the 2011 Recent Advances in Intrusion Detection.Heidelberg:Springer-Verlag,2011,301-317.
[11]李文海,许舒人.基于Hadoop的电子商务推荐系统的设计与实现[J].计算机工程与设计,2014(1):130-143.LI Wenhai,XU Shuren.Design and implementation of recommendation system for E-commerce on Hadoop[J].Computer Engineering and Design,2014(1):130-143.
Research on Recommendation Algorithm Based on Information Entropy and Mahout
FAN LiLIN Manshan
(North China University of Technology,Beijing 100144)
Aiming at the noise data problem in recommendation algorithm offered by Mahout,the user entropy model is put forward.The user entropy model combines the concept of entropy in the information theory and uses the information entropy to measure the content of user information,which filters the noise data by calculating the entropy of users and getting rid of the users with low entropy.The proposed model is validated by using Mahout algorithm including user based collaborative filtering,collaborative filtering based on articles and Slope-One recommendation algorithm.The experimental results show that the proposed model can effectively filter out noise data,and the mean absolute error hava been decreased.
noisedata,information entropy model,Mahout,recommendation
TP301
10.3969/j.issn.1672-9722.2017.10.003
Class Number TP301
2017年4月7日,
2017年5月11日
樊利,女,硕士研究生,研究方向:数据挖掘。林满山,男,高级工程师,研究方向:数据挖掘。
