基于数据降维与精确欧氏局部敏感哈希的k近邻推荐方法
2017-11-15郭喻栋郭志刚
郭喻栋,郭志刚,陈 刚,魏 晗
(信息工程大学 信息系统工程学院,郑州 450002)(*通信作者电子邮箱20374042@qq.com)
基于数据降维与精确欧氏局部敏感哈希的k近邻推荐方法
郭喻栋,郭志刚*,陈 刚,魏 晗
(信息工程大学 信息系统工程学院,郑州 450002)(*通信作者电子邮箱20374042@qq.com)
针对基于k近邻的协同过滤推荐算法中存在的评分特征数据维度过高、k近邻查找速度慢,以及评分冷启动等问题,提出基于数据降维与精确欧氏局部敏感哈希(E2LSH)的k近邻协同过滤推荐算法。首先,融合评分数据、用户属性数据以及项目类别数据,将融合后的数据作为输入对堆叠降噪自编码(SDA)神经网络进行训练,取神经网络编码部分最后一个隐层的值作为输入数据的特征编码,完成非线性降维。然后,利用精确欧氏局部敏感哈希算法对降维后的数据建立索引,通过检索得到目标用户或目标项目的相似近邻。最后,计算目标与近邻之间的相似度,利用相似度对近邻的评分记录加权得到目标用户对目标项目的预测评分。在标准数据集上的实验结果表明,在冷启动场景下,均方根误差比基于局部敏感哈希的推荐算法(LSH-ICF)平均降低了约7.2%,平均运行时间和LSH-ICF相当。表明该方法在保证推荐效率的前提下,缓解了评分冷启动问题。
信息推荐;堆叠降噪自编码器;精确欧氏局部敏感哈希;数据降维;冷启动
0 引言
随着互联网的飞速发展,人们在互联网平台上的活动越来越频繁,信息推荐在网络中发挥的作用也越来越重要。在电子商务领域,商品推荐根据客户的注册信息、商品信息以及客户对商品的反馈信息等分析客户的偏好,模拟销售人员向其提供商品购买建议,从而提高电子商务交易量。在社交网络领域,好友推荐系统能够为用户建立复杂的人际关系网络图谱,向用户推荐可能认识的好友或群体,扩展用户的交际圈,最终提高用户对于社交平台的满意度。在网络媒体领域,由于新闻资讯数量呈爆炸式增长,广大读者受到了信息过载问题的困扰,新闻推荐通过分析读者的行为记录(浏览、分享、点赞、评论等),识别读者的兴趣点,向他们推荐其感兴趣的内容,在读者目的不明确的情况下,大大提高了其信息获取的效率,缓解了信息过载问题。
基于k近邻的推荐算法[1-3]是一种常用的推荐模型,可以分为基于用户近邻的推荐算法和基于项目近邻的推荐算法。基于用户近邻的推荐算法主要分为以下步骤:根据用户的特征计算两两用户之间的相似度;针对目标用户,找到与之最相似的用户近邻集合;在估计目标用户对某一项目的评分时,利用近邻集合中用户对该项目的评分,通过相似度加权,来预测目标用户的评分。
基于项目近邻的推荐算法与基于用户近邻的推荐算法原理大致相同,区别在于基于项目近邻的推荐算法通过计算项目之间的相似度来完成预测和推荐。两种方法的适用场合不同,在实际应用中,需要结合具体的场景进行选择。在一些系统中,项目的数量较为稳定且远远小于用户的数量,此时计算项目之间的相似度更节省时间,适合采用基于项目近邻的推荐算法。但是还有一些系统,如新闻推荐系统和微博推荐系统,项目的更新速度要远远高于系统中用户的更新速度,且数量也要远远超过用户的数量,此时适合选择基于用户近邻的推荐算法。因此需要具体问题具体分析,根据系统的实际需要选取合适的推荐算法。
k近邻推荐算法的关键在于评分特征提取和相似度计算。基础算法将原始高维稀疏的评分作为用户和项目的特征,采用余弦相似度进行计算,最后根据相似度最高的k个近邻进行评分预测和推荐。这种方法存在空间消耗大、相似度计算不精确、相似近邻选取效率低等缺点。近年来,国内外学者针对上述关键点进行了不同的改进。在特征提取方面,文献[4-6]分别采用主成分分析(Principle Component Analysis, PCA)和奇异值分解(Singular Value Decomposition, SVD)对数据进行降维,提高相似度计算速度和相似近邻选取效率,但是PCA降维方法假设评分数据之间是线性的,而实际中的数据可能是非线性的。在相似度计算方面,经典的相似度计算方法有余弦相似度、皮尔森相关系数和修正的余弦相似度等[7],后续工作大都在这些基础上改进,文献[8]对相似度加权方法进行改进,文献[9]对项目属性相似度和评分相似度进行动态组合,文献[10]引入Tanimoto系数进行相似度计算,这些改进能够提高评分预测的准确率,但都是在原始评分特征上进行的,特征降维以后,这些相似度计算方法便不再适用。另外,上述方法没有考虑评分冷启动问题(在评分数据过于稀疏或没有评分数据时,无法进行准确推荐),且在推荐过程中仍然需要大量的相似度计算,不能真正提高推荐效率。
针对上述问题,本文融合了评分数据、用户属性数据和项目类别数据,采用堆叠降噪自编码(Stack Denoising Auto-encoder, SDA)神经网络对上述数据进行非线性降维,引入精确欧氏局部敏感哈希(Exact Euclidean Local-Sensitive Hash, E2LSH)快速检索算法进行相似近邻检索,并改进了相似度计算方法,在保证推荐效率的前提下,缓解了评分冷启动问题。
1 相关理论
1.1 堆叠降噪自编码网络
降噪自编码器(Denoising Auto-Encoder, DAE)是由Vincent等[11]提出的一种由输入层、隐藏层和输出层组成的三层神经网络,输出层是对输入层的重构,输入层到隐藏层是编码器,隐藏层到输出层是解码器。DAE向输入层数据中加噪,在学习过程中去噪,这样能够消除干扰特征提取的噪声,学习到的特征更具有代表性。SDA是一种特殊的深度神经网络[12],其网络结构可认为是对称的,前半部分从输入层到中间层逐层编码,后半部分从中间层到输出层逐层解码,因此通常网络层数为2L+1,如图1所示。
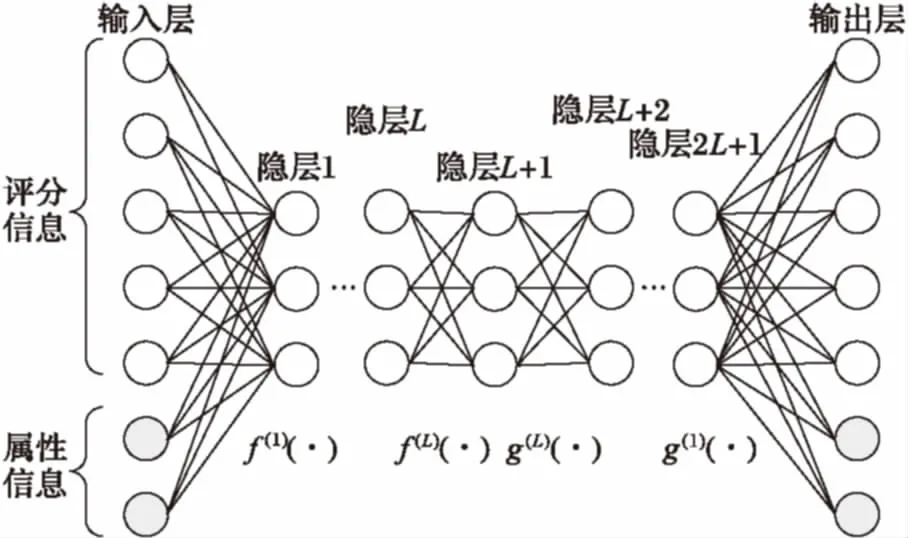
图1 SDA神经网络结构
SDA的第l层隐层到下一层和第2L-l+1层隐层到下一层构成一对编解码器,编码函数和解码函数分别如式(1)和式(2)所示:
hl+1=fl(Wlhl+bl)
(1)
h2(L+1)-l=gl(W2L-l+1h2L-l+1+b2L-l+1)
(2)
其中:f(·)和g(·)分别为编码器和解码器函数,通常采用sigmoid函数,其自变量为网络参数W和b。Wl是第l层与上一层之间的权重,Wl和W2L-l+1互为转置,由编码器和解码器共享,称为一对捆绑权重[12]。hl和h2L-l+1分别是编码器和解码器的输入向量,bl和b2L-l+1是偏置向量。
SDA的训练过程分为预训练和微调两个阶段。预训练将每一对编码器和解码器都当作一个DAE进行训练,通过随机梯度下降法最小化单个DAE的损失函数,如式(3)所示,得到预训练参数。微调阶段利用预训练参数作为网络的初始化参数,通过后向传播算法最小化损失函数,如式(4)所示,得到最终的网络参数。在这种深度神经网络结构下,在预训练阶段,每一个DAE可以看作是一种无监督的预训练过程,依次进行。由于当前DAE的输入是前面DAE的隐层值,因此,只有当前面的DAE训练好后,才能开始当前DAE的训练。具体的训练步骤将在第2章中详细阐述。
C(hl,h2(L+1)-l)=-hlln(h2(L+1)-l)+
(1-hl)ln(1-h2(L+1)-l)
(3)
C(x,x′)=xln(x′)+(1-x)ln(1-x′)
(4)
x′=g1∘…∘gL∘fL∘…∘f1(x″)
(5)
其中:C(hl,h2(L+1)-l)是预训练阶段的损失函数,C(x,x′)是微调阶段的损失函数,x″是加噪后的输入,hl是网络第l层的数据,当l=0时,hl分和h2(L+1)-l分别为整个网络的输入x和输出x′。
1.2 精确欧氏局部敏感哈希算法
局部敏感哈希(Local-Sensitive Hash, LSH)算法是一种近似近邻搜索策略[13],能够得到近似却高效的候选结果,这往往比低效精确的策略更具实际意义。LSH的基本思想是以较大的碰撞概率保证空间中的相似点哈希到同一个哈希桶中,同时过滤掉不相似的点以减少相似性计算,从而快速检索到相似近邻。E2LSH是对LSH的一种改进[14],通过基于p稳态分布的LSH函数对数据进行哈希表示,使相似的数据哈希到同一个桶中的概率更高。
位置敏感哈希函数族是LSH算法的基础,是根据一组由点域S到数集域U的映射函数定义的,用E={e:S→U}表示。随机选取哈希函数族E中的一个,对于数据点t,v∈Rd,如果满足下列条件,则E即为位置敏感哈希函数族。
若‖t-v‖
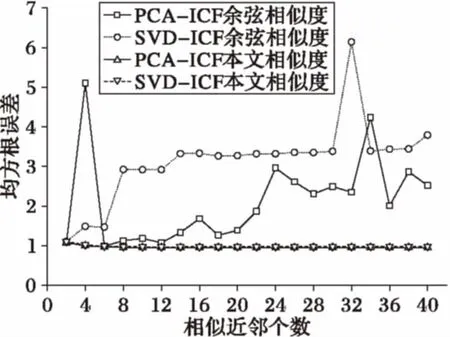
若‖t-v‖>d2,则P[e(t)=e(v)] 其中,P[·]表示t和v的哈希值取等时的概率,0 ea,b(v)=⎣(a·v+b)/w」 (6) 其中:a是从R上的p稳态分布中随机取样构成的d维向量,b是从[0,w]上的均匀分布中随机取样得到的随机数,⎣·」表示向下取整。函数e将d维向量v映射成一个整数,作为该向量的哈希值。由p稳态分布的定义可知,向量v在a方向上的投影av与‖av‖pX同分布,X服从p稳态分布。哈希函数ea,b(v)的几何意义如图2所示,a方向上的实线以w为间隔进行分割,将投影a·v+b所处的间隔作为向量v的哈希值。 图2 基于p稳态分布的哈希函数几何意义 (7) (8) 本章首先给出基于数据降维和E2LSH的k近邻推荐算法基本流程,然后对其中的关键技术逐一进行详细阐述。 2.1 基本流程 本文方法的基本流程如图3所示,对基础k近邻推荐算法进行了改进,主要包括数据降维、相似近邻检索和评分预测三部分。 图3 本文方法基本流程 1)数据降维。通过SDA神经网络对评分数据和用户/项目标签数据融合后所形成的高维稀疏向量进行非线性降维,得到低维稠密的用户/项目特征向量。 2)相似近邻检索。利用精准欧氏局部敏感哈希算法为降维后的数据构建索引,通过检索得到目标用户或项目的近似近邻集合。 3)评分预测。计算目标用户或项目与相似近邻之间的相似度,利用相似近邻的评分记录,通过相似度加权来预测未知评分。 2.2 基于神经网络的数据降维 在计算用户或项目之间的相似度时,若采用原始评分作为特征,随着推荐系统中用户数和项目数的不断增多,特征维度将急剧增加,从而降低运算效率,甚至造成维数灾难,因此对评分数据进行降维十分必要。传统的PCA和SVD降维是一种线性模型,而推荐系统中的数据可能是非线性的,因此本文引入自编码神经网络作为一种非线性降维方法。自编码神经网络有深层和浅层之分,前者能够拟合更复杂的函数,降维后得到的特征更具有代表性[16]。所以本文采用深层网络——SDA对评分数据和标签数据进行非线性降维。训练步骤如下: 1)确定SDA的网络结构,设置输入层维数、隐藏层个数、各隐藏层维数以及各层的加噪比例。然后融合评分数据和用户/项目标签数据,对数据加噪后以向量的形式作为SDA的输入。 图4 SDA训练过程 2)训练第一层DAE,即图4(a)中输入层N维,隐层N1维的DAE,利用式(1)和式(2)计算网络的输出值,通过随机梯度下降法最小化损失函数,如式(3)所示。 3)将第一层DAE的隐层数据作为第二层DAE的输入,按照步骤2)中的方法训练第二层DAE。以此类推,训练多层DAE。 4)将多层DAE展开成深度网络的结构,分为编码和解码两部分,如图4(b)所示。利用步骤2)、3)中得到的权值对深度网络进行参数初始化。 5)将输入数据作为深度网络的整体输入,通过经典的后向传播算法对网络参数进行微调,如图4(c)所示。将编码部分最后一个隐层的值保留(即维度为N3的隐藏层的值),作为输入数据的特征编码。 2.3 基于E2LSH的相似近邻选择 针对传统的基于余弦相似度来计算近邻用户的方法存在计算量大、耗时长的缺点,本文采用E2LSH算法实现相似近邻的快速检索。在进行用户/项目的相似近邻检索时,以用户为例,根据索引键搜索目标用户u的特征向量所在的L个哈希桶,将这些桶中用户的并集作为目标用户的近似近邻集。具体实现方法如下: 1)初始化函数φ(v)=(e1(v),e2(v),…,ek(v)),φ(v)将用户特征向量v哈希成k个整数,连成一个k维向量。其中,e(·)由式(6)给出,不同的ei(·)和ej(·)彼此随机独立产生。 2)随机独立的选取L个φ(·)函数,为每个用户生成L个k维哈希向量,对应L个哈希表。 图5 索引构建示意图 图5中,每个用户的特征向量对应高维空间的一个点,根据索引键(Value,Index)将该点分别存入L个哈希表中的其中一个桶。按照此法将所有数据点存入哈希桶,同一个桶中的点索引键相同,从而完成索引构建。 4)在对目标用户进行检索时,根据目标用户的索引键,找到该用户所在的L个哈希桶。将这些桶中的所有用户取出,去掉重复的用户,剩下的即为目标用户的相似近邻。 2.4 相似度计算 本文在余弦相似度的基础上,为了消除差异较大的相似近邻对后续预测评分计算的干扰,对相似度计算公式进行改进,以项目相似度计算为例,改进前后的具体计算方法分别如式(8)和式(9)所示: (8) (9) 其中:α和β分别表示两个项目的特征向量,sim(α,β)表示两个项目之间的相似度,q表示特征维度的大小,αi和βi分别表示特征向量的第i个元素,当sim(α,β)>0时,说明两个项目较为相似,否则说明二者差别较大。当某一项目与目标项目差别较大时,该项目对目标项目的评分预测贡献意义不大,因此本文将它们的相似度置为0,从而减小异类项目对评分预测的干扰。类似地,在计算用户a与用户b之间的相似度时,在消除不同用户平均评分不同的差异的同时,也排除异类用户对目标用户评分预测的干扰。 2.5 评分预测 在利用E2LSH得到用户/项目的相似近邻后,需要根据相似近邻的评分来预测未知评分。评分预测分为基于用户的评分预测和基于项目的评分预测,计算公式分别如式(10)、(11)所示。对于基于用户的方法,由于每个用户的评分习惯不同,例如有的用户习惯评分较高,有的用户则习惯评分较低,因此在评分预测在用户的评分均值的基础上进行。基于项目的评分预测是利用同一用户已评价过的项目来预测未评价过的项目,因此不存在这个问题,可直接通过相似度加权进行评分预测。 (10) (11) 3.1 实验数据 本文使用MovieLens100K数据集,该数据集包含943名用户对1 682个项目的100 000条真实评分记录,同时包含用户和项目的属性信息。本文设计了热启动和冷启动两种场景:在热启动场景下,将数据集分为两部分,80%用作训练集,20%用作测试集;在冷启动场景下,训练集和测试集都为原始数据集的20%。实验采用5折交叉验证的平均值作为最终结果。 3.2 评价指标 评分预测的准确率通常采用均方根误差(Root Mean Square Error, RMSE)计算,误差越小表示评分预测越准确。230对于测试集Test中的用户u和项目i,定义为: (12) 3.3 实验设置与结果分析 3.3.1 实验参数设置 本文结合SDA降维和E2LSH近邻检索技术,改进了相似度计算方法,分别实现了基于用户的k近邻推荐和基于项目的k近邻推荐,对比实验包括传统的协同过滤推荐[8]和其他基于数据降维的推荐[4,6](基于PCA和基于SVD的推荐)。经过大量实验测试,在保证各算法相对公平的条件下,各算法参数设置如下:降维后的特征维度大小统一设置为25,DAE实验中,加噪程度为0.2,梯度下降的学习率为0.8,迭代次数为15。SDA隐藏层设置为三层,节点数分别为300,25,25,三层的加噪程度分别为0.2,0.3,0.3,梯度下降的学习率为0.8,迭代次数为15。E2LSH算法参考文献[14]进行参数设置,哈希表的个数L设置为20,因为该值过小导致检索精度不够,该值过大导致空间浪费且检索精度并不会显著提高。g(v)中哈希函数h(v)的个数k取5,h(v)中w值取经验值4。 3.3.2 实验结果分析 图6显示了相似度计算方法对不同算法的影响,其中受相似度计算影响较大的两种算法为基于SVD降维的项目近邻推荐(记为SVD-ICF)和基于PCA降维的项目近邻推荐方法(记为PCA-ICF)。采用原始数据、DAE降维和SDA降维后的数据以及文献[14]的方法计算得到的近邻相似度都大于0,因而不受影响。这是由于采用线性降维方法在提取特征时,特征向量的元素出现负值,导致计算相似近邻时不够稳定和准确,这种情况可以通过本文所提出的相似度计算方法进行弥补,通过消除相似度过低的近邻对评分预测的干扰,仅考虑相似度更高的近邻,性能得到较大提升。 图6 相似度计算对实验结果的影响 图7(a)(b)两图分别显示了在热启动和冷启动场景下,基于项目的不同推荐算法的准确率对比。在热启动场景下,各算法RMSE相差不大,改进相似度后的线性降维算法PCA-ICF和SVD-ICF的RMSE最小,文献[14]的方法(LSH-ICF)、非线性降维算法DAE-ICF、本文方法与基本的ICF算法相当,本文方法略好。在冷启动场景下,算法的预测准确率较于热启动有所下降,降维后比降维前的算法准确率高,本文方法较其他算法提升较为明显,这是由于本文算法融入了项目的类别信息。 图7 基于项目的推荐算法准确率对比 类似的,图8(a)、(b)分别显示了在热启动和冷启动场景下,基于用户的各种推荐算法的准确率对比。在热启动场景下,各算法准确率差异不大。在冷启动条件下,文献[14]的方法(LSH-UCF)准确率略高于基于SVD降维的方法(SVD-UCF),基非线性降维算法的准确率明显高于其他基于线性降维的算法,由于本文方法结合用户的属性信息,故在冷启动场景下准确率最高。 图9显示了不同推荐算法的平均运行时间对比。图中对比了三种有代表性的推荐算法在平均运行时间上的差异。ICF利用高维稀疏的原始评分数据进行推荐,平均运行时间最长;其次是PCA-CF,利用降维后的数据进行推荐,缩短了平均运行时间;平均运行时间最短的是本文方法和文献[14]的方法(LSH-ICF),两种方法利用E2LSH检索到相似近邻后,仅需计算目标与近邻之间的相似度,无需计算所有用户或项目两两之间的相似度,从而提高了算法效率。与LSH-ICF相比,本文方法在冷启动场景下的准确率更高,RMSE指标平均降低了约7.2%。 本文提出一种基于SDA数据降维与E2LSH的信息推荐方法,该方法将高维稀疏的用户-项目评分数据与用户属性、项目类别数据融合后作为SDA深度神经网络的输入,通过迭代训练得到低维稠密的用户特征和项目特征。然后利用E2LSH算法对降维后的用户或项目特征构建索引,通过检索得到目标用户或目标项目的相似近邻。最后根据目标用户或项目与相似近邻之间的相似度,通过相似度加权来预测用户对项目的评分。实验结果表明,本文提出的数据降维方法能够较好的提取原始评分数据中的有效信息,在降低数据维度的同时提高评分预测准确度,尤其是在冷启动场景下优势较为明显。另外,本文结合E2LSH检索算法能够快速找到目标的相似近邻,运行效率较高。但是本文仅考虑了推荐准确率和运行效率,实际中推荐性能还受到推荐结果新颖度和覆盖率的影响。通常情况下,准确率提高会导致新颖度和覆盖率下降,因此,如何利用多策略推荐方法,在保证准确率的同时提高新颖度和覆盖率是推荐算法的一个难点,也是未来研究工作的一个重点。 图8 基于用户的推荐算法准确率对比 图9 不同推荐算法平均运行时间对比 References) [1] MEHTA S J, JAVIA J. Threshold based KNN for fast and more accurate recommendations [C]// Proceedings of the 2015 IEEE 2nd International Conference on Recent Trends in Information Systems. Piscataway, NJ: IEEE, 2015: 109-113. [2] YANG C, YU X, LIU Y. Continuous KNN join processing for real-time recommendation [C]// Proceedings of the 2014 IEEE International Conference on Data Mining. Washington, DC: IEEE Computer Society, 2014: 640-649. [3] ZHU T, LI G, PAN L, et al. Privacy preserving collaborative filtering for KNN attack resisting [J]. Social Network Analysis and Mining, 2014, 4(1): 1-14. [4] 李远博,曹菡.基于PCA降维的协同过滤推荐算法[J].计算机技术与发展,2016,26(2):26-30.(LI Y B, CAO H. Collaborative filtering recommendation algorithm based on PCA dimension reduction [J]. Computer Technology and Development, 2016, 26(2): 26-30.) [5] 郁雪,李敏强.一种结合有效降维和K-means聚类的协同过滤推荐模型[J].计算机应用研究,2009,26(10):3718-3720.(YU X, LI M Q. Collaborative filtering recommendation model based on effective dimension reduction andK-means clustering [J]. Application Research of Computers, 2009, 26(10): 3718-3720.) [6] 林建辉,严宣辉,黄波.基于SVD与模糊聚类的协同过滤推荐算法[J].计算机系统应用,2016,25(11):156-163.(LIN J H, YAN X H, HUANG B. Collaborative filtering recommendation algorithm based on SVD and fuzzy clustering [J]. Computer Systems & Applications, 2016, 25(11): 156-163.) [7] SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms [C]// Proceedings of the 10th International Conference on World Wide Web. New York: ACM, 2001: 285-295. [8] WANG B, LIAO Q, ZHANG C. Weight based KNN recommender system [C]// Proceedings of the 2013 5th International Conference on Intelligent Human-Machine Systems and Cybernetics. Washington, DC: IEEE Computer Society, 2013,2: 449-452. [9] 吴月萍,郑建国.改进相似性度量方法的协同过滤推荐算法[J].计算机应用与软件,2011,28(10):7-8.(WU Y P, ZHENG J G. Collaborative filtering recommendation algorithm on improved similarity measure method [J]. Computer Applications and Software, 2011, 28(10): 7-8.) [10] 文俊浩,舒珊.一种改进相似性度量的协同过滤推荐算法[J].计算机科学,2014,41(5):68-71.(WEN J H, SHU S. Improved collaborative filtering recommendation algorithm of similarity measure [J]. Computer Science, 2014, 41(5): 68-71.) [11] VINCENT P, LAROCHELLE H, BENGIO Y, et al. Extracting and composing robust features with denoising autoencoders [C]// Proceedings of the 25th International Conference on Machine Learning. New York: ACM, 2008: 1096-1103. [12] BENGIO Y, LAMBLIN P, POPOVICI D, et al. Greedy layer-wise training of deep networks [EB/OL]. [2016- 12- 05]. http://papers.nips.cc/paper/3048-greedy-layer-wise-training-of-deep-networks.pdf. [13] ANDONI A, INDYK P. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions [C]// Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science. Washington, DC: IEEE Computer Society, 2006: 459-468. [14] 李红梅,郝文宁,陈刚.基于精确欧氏局部敏感哈希的协同过滤推荐算法[J].计算机应用,2014,34(12):3481-3486.(LI H M, HAO W N, CHEN G. Collaborative filtering recommendation algorithm based on exact Euclidean locality-sensitive hashing [J]. Journal of Computer Applications, 2014, 34(12): 3481-3486.) [15] 周杰,李弼程,唐永旺.基于关键证据与E2LSH的增量式人名聚类消歧方法[J].情报学报,2016,35(7):714-722.(ZHOU J, LI B C, TANG Y W. Incremental clustering method based on key evidence and E2LSH for person name disambiguation [J]. Journal of the China Society for Scientific and Technical Information, 2016, 35(7): 714-722.) [16] 邓俊锋,张晓龙.基于自动编码器组合的深度学习优化方法[J].计算机应用,2016,36(3):697-702.(DENG J F, ZHANG X L. Deep learning algorithm optimization based on combination of auto-encoders [J]. Journal of Computer Applications, 2016, 36(3): 697-702.) [17] 冷亚军,梁昌勇,陆青,等.基于近邻评分填补的协同过滤推荐算法[J].计算机工程,2012,38(21):56-58.(LENG Y J, LIANG C Y, LU Q, et al. Collaborative filtering recommendation algorithm based on neighbor rating imputation [J]. Computer Engineering, 2012, 38(21): 56-58.) RecommendationmethodbasedonknearestneighborsusingdatadimensionalityreductionandexactEuclideanlocality-sensitivehashing GUO Yudong, GUO Zhigang*, CHEN Gang, WEI Han (CollegeofInformationSystemEngineering,InformationEngineeringUniversity,ZhengzhouHenan450002,China) There are several problems in the recommendation method based onknearest neighbors, such as high dimensionality of rating features, slow speed of searching nearest neighbors and cold start problem of ratings. To solve these problems, a recommendation method based onknearest neighbors using data dimensionality reduction and Exact Euclidean Locality-Sensitive Hashing (E2LSH) was proposed. Firstly, the rating data, the user attribute data and the item category data were integrated as the input data to train the Stack Denoising Auto-encoder (SDA) neutral network, of which the last hidden layer values were used as the feature coding of the input data to complete data dimensionality reduction. Then, the index of the reduced dimension data was built by the Exact Euclidean Local-Sensitive Hash algorithm, and the target users or the target items were retrieved to get their similar nearest neighbors. Finally, the similarities between the target and the neighbors were calculated, and the target user’s similarity-weighted prediction rating for the target item was obtained. The experimental results on standard data sets show that the mean square error of the proposed method is reduced by an average of about 7.2% compared with the recommendation method based on Locality-Sensitive Hashing (LSH-ICF), and the average run time of the proposed method is the same as LSH-ICF. It shows that the proposed method alleviates the rating cold start problem on the premiss of keeping the efficiency of LSH-ICF. information recommendation; Stack Denoising Auto-encoder (SDA); Exact Euclidean Locality-Sensitive Hashing (E2LSH); data dimensionality reduction; cold start 2017- 03- 22; 2017- 05- 22。 国家社会科学基金资助项目(14BXW028)。 郭喻栋(1991—),男,河南孟津人,硕士研究生,主要研究方向: 机器学习、数据挖掘; 郭志刚(1973—),男,河南郑州人,副教授,硕士,主要研究方向:智能信息处理、机器学习、数据挖掘; 陈刚(1979—),男,湖北黄冈人,讲师,博士研究生,主要研究方向:智能信息处理、机器学习、数据挖掘; 魏晗(1981—),女,河南郑州人,讲师,硕士,主要研究方向:智能信息处理、机器学习、数据挖掘。 1001- 9081(2017)09- 2665- 06 10.11772/j.issn.1001- 9081.2017.09.2665 TP391.1 A This work is partially supported by the National Social Science Foundation of China (14BXW028). GUOYudong, born in 1991, M. S. candidate. His research interests include machine learning, data mining. GUOZhigang, born in 1973, M. S., associate professor. His research interests include intelligent information processing, machine learning, data mining. CHENGang, born in 1979, Ph. D. candidate, lecturer. His research interests include intelligent information processing, machine learning, data mining. WEIHan, born in 1981, M. S., lecturer. Her research interests include intelligent information processing, machine learning, data mining.




2 基于数据降维和E2LSH的k近邻推荐算法





3 实验结果及分析
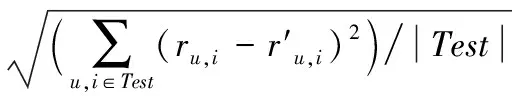


4 结语


