基于稀疏降噪自编码器的深度置信网络
2017-11-15张艺楠XiaoWeiSong
曾 安,张艺楠,潘 丹,Xiao-Wei Song
(1.广东工业大学 计算机学院,广州 510006; 2.广东建设职业技术学院 现代教育技术中心,广州 510440;3.西蒙弗雷泽大学 影像技术实验室,加拿大 温哥华 V6B 5K3)(*通信作者电子邮箱2656351065@qq.com)
基于稀疏降噪自编码器的深度置信网络
曾 安1,张艺楠1,潘 丹2*,Xiao-Wei Song3
(1.广东工业大学 计算机学院,广州 510006; 2.广东建设职业技术学院 现代教育技术中心,广州 510440;3.西蒙弗雷泽大学 影像技术实验室,加拿大 温哥华 V6B 5K3)(*通信作者电子邮箱2656351065@qq.com)
传统的深度置信网络(DBN)采用随机初始化受限玻尔兹曼机(RBM)的权值和偏置的方法初始化网络。虽然这在一定程度上克服了由BP算法带来的易陷入局部最优和训练时间长的问题,但随机初始化仍然会导致网络重构和原始输入的较大差别,这使得网络无论在准确率还是学习效率上都无法得到进一步提升。针对以上问题,提出一种基于稀疏降噪自编码器(SDAE)的深度网络模型,其核心是稀疏降噪自编码器对数据的特征提取。首先,训练稀疏降噪自编码;然后,用训练后得到的权值和偏置来初始化深度置信网络;最后,训练深度置信网络。在Poker Hand 纸牌游戏数据集和MNIST、USPS手写数据集上测试模型性能,在Poker Hand数据集下,方法的误差率比传统的深度置信网络降低46.4%,准确率和召回率依次提升15.56%和14.12%。实验结果表明,所提方法能有效地改善模型性能。
深度置信网络;受限玻尔兹曼机;稀疏降噪自编码器;深度学习
0 引言
深度置信网络(Deep Belief Network, DBN)是深度学习中一种代表性的模型,通过贪婪策略将网络分成若干个受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)网络,有效地降低了网络复杂度[1]。网络训练采用无监督预训练和有监督微调的方法,其中无监督逐层预训练RBM的方法解决了大量有标签数据收集费时费力的困难[2];且在一定程度上避免了有监督BP算法的局部最优弊端等,从而被广泛应用于语音识别[3]、手写数字识别[4]、图像识别[5]和自然语言处理[6]等领域。
然而,目前DBN模型也存在一些问题,如:DBN往往采用重构误差作为网络的评价指标,虽然这样可以反映网络对训练样本的似然度,但它并不可靠[7];RBM的目标函数不能直接最大化,从而无法知道训练是何时结束的,这在控制计算成本上是个巨大的挑战[8];学习率、动量等参数寻优对先验经验依赖性较强[7],隐含层层数也难以选择[9]。并且,DBN采用无监督逐层学习RBM以获得网络参数并初始化网络的方法,虽然这在一定程度上能提高训练精度和节省训练时间,但网络中RBM随机设定的初始化网络权值和偏置会导致重构后的数据和原始输入数据有较大的差别,从而影响精度的进一步提高。这是一个亟待解决的问题。于是,如何快速地找到较好的预训练网络参数,使其在一定程度上能更好地拟合训练数据,这对提高有监督学习时的迭代收敛速度[7]和提高分类准确率[2]都有重要的研究意义。这也正是本文的研究重点。
目前,权值和偏置的参数寻优方法主要集中在浅层学习上,比较流行的有:随机初始化取值方法、基于样本特征提取初始化法、遗传和免疫取值法、均匀设计取值法、记忆式取值法和感受野型取值法等算法,而较少文献研究DBN的参数寻优问题。Srivastava 等[10]提出一种dropout参数加入DBN网络的反向微调中,每次训练时让特征检测器以概率p停止工作以提高网络的泛化能力,该方法现已成功应用到DBN模型中;Ranzato等[11]提出在RBM的模型中加入稀疏惩罚项,即在无监督预训练RBM时加入稀疏限制参数,更好地重构数据并提高模型的分类精度;胡振等[12]提出了一种基于降噪自编码器的五层混合神经网络,前两层是降噪自编码器,中间两层是RBM,最后用Logistic层进行分类,网络模型旨在提高DBN无监督预训练的特征提取能力以获得更好的初始权重,该模型已成功运用在作曲家分类的问题上。
研究表明,RBM权值的设定可以影响隐含单元的状态,使其不会一直处于被激活或者抑制状态,从而提高网络的运行效率[13]。同时合理的RBM初始化权值和偏置可以减小网络重构与输入数据的差距,从而提高分类精度。稀疏降噪自编码器具有更好的特征提取能力[14]和较高的模型分辨率,于是,本文尝试用稀疏降噪自编码器对无标签数据训练,并将得到的网络参数作为深度置信网络的初始权值和阈值,以期克服网络易陷入局部最优和训练时间长的弊端,从而提高模型的分类精度和运行效率。
1 模型简介
1.1 深度置信网
DBN是一个概率生成模型,如图1所示,由多个RBM串联堆叠而成。DBN的学习可分为两个过程:无监督逐层预训练RBM和有监督BP算法微调。

图1 DBN网络结构
RBM是一种基于随机神经网络的概率图模型[15],也是一个能量模型,可视层v为数据输入层,隐藏层h为特征提取层,层内节点无连接,层间节点全连接。学习过程是将上一层的输出作为下一层的输入,以获取有效特征。对于一组给定的状态向量,可见状态向量v和隐藏状态向量h的联合概率分布为:
(1)
其中,Z(θ)是归一化因子。
由于RBM层内无连接,层间全连接[16],由已知的其中一层节点可得到另一层节点的值,即:
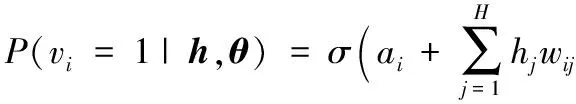
(2)

(3)
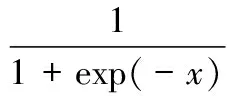
RBM的学习是为了求出参数的θ值,采用梯度下降的方法最大化式(1)的联合分布。由于归一化函数Z(θ)很难获取,本文采用对比散度(Contrastive Divergence, CD)算法[8]对RBM网络进行学习以提高计算速度和精度,并采用重构误差(Reconstruction Error)作为其评价指标。
经过大量无标签数据逐层对RBM无监督训练初始化网络后,利用有标签数据对网络进行微调,即BP算法反向微调整个网络。
1.2 稀疏降噪自编码器
稀疏降噪自编码器(Sparse Denoising AutoEncoder, SDAE)是一种特殊的自编码器(AutoEncoder, AE),可视为一个三层神经网络:输入层-隐藏层-输出层,其中,输入层和输出层具有相同的结构,当输入等于输出时,隐藏层即为输入的一种特征表达。而SDAE即在AE网络中加入随机性和在损失函数中加入稀疏性限制,相比AE具有更好的鲁棒性和高效性,模型如图2。
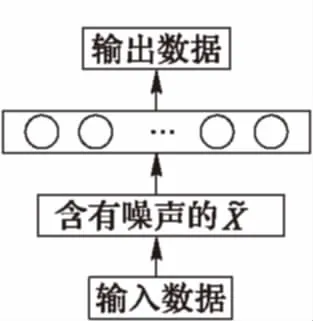
图2 SDAE网络结构
自编码网络中加入随机性是指在输入数据中加入一定概率分布的噪声(通常是将输入矩阵每个值都随机置0),让网络学习去除这种噪声的能力,使其学习到的特征更具鲁棒性,提升模型对输入数据的泛化能力[17]。稀疏性限制是指神经元大部分时间都被抑制的限制,如果当神经元输出为1时,认为其被激活,那么当输入为0时则被抑制,因此,稀疏性限制就是神经元输出矩阵只有个别非零元素或者有很少的几个远大于零的元素,加入稀疏性限制的网络使用较少的激活单元表示特征,使模型更具高效性。
SDAE的代价函数为:
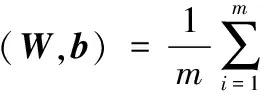
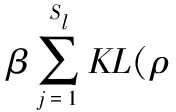
(4)
其中函数的第一项为均方误差重构项,第二项为稀疏惩罚项,为保证稀疏性限制,要求:
(5)
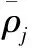
2 基于稀疏降噪自编码器的深度置信网
深度学习采用无监督学习策略获得网络参数并初始化网络的方法,在一定程度上解决了BP算法反向微调易陷入局部最优的问题,因为预训练后的网络的权值能更好地表达输入数据结构,提高网络的特征表达能力和泛化性能,这也正是无监督学习在深度置信网中起关键作用的原因。本文基于这一点提出基于稀疏降噪自编码器的深度置信网络。
深度置信网络的实质是通过受限玻尔兹曼机的堆叠混合得到,应证了深层神经网络在构建中强调模型的混合这一理论[20],因此,结合稀疏降噪自编码器和深度置信网络构建深层神经网络也是可行的。由自编码器的原理可知,编码过程和解码过程实现将原始数据与高维特征空间的相互投影,具有保持原始数据的可恢复性的作用[12],而投影过程中的可恢复性作用可以保证投影结果的相对稳定并增加数据的可分性。因稀疏降噪自编码器中降噪的表达能起到降维的作用,并很好地发现隐含在输入数据内部的结构与模式;稀疏的表达则是网络的特征选择,从大量维度中筛选出对系统有用的若干维,有较好的特征提取能力,能很好地特征表达输入数据,因此,相比于深度置信网络,稀疏降噪自编码器在数据的特征提取、分析、降维和表达方面有更好的效果。
而深度置信网络,RBM的初始化是指随机设定且范围在(0,1)间的网络权值和偏置,会导致重构后的数据和原始输入数据有较大的差别,从而使网络无论在准确率还是效率上都无法达到最优。不仅如此,初始值的选择会影响局部极小值的性能,较好的预训练初始值可以在一定程度上提高局部极小值的性能,提高网络的特征表达能力和泛化性能,并使模型更加稳定(加快收敛)。
综合以上两点,本文采用稀疏降噪自编码器初始化RBM:提出用单隐层稀疏降噪自编码器对数据进行预训练,将模型所产生的权值和偏置直接赋值给首层RBM,然后进行DBN的无监督预训练和有监督反向微调,在一定程度上优化网络参数,以进一步改善局部最优问题并提高模型的分类精度和训练效率。
胡振等[12]提出一种基于降噪自编码器的五层混合神经网络(前两层是降噪自编码器,后两层是RBM),该模型中降噪自编码器的输出即为深度置信网络的输入,由此证明了在深度置信网络和降噪自编码器这两个模型间参数传递是可行并有效的。而本文采用的稀疏降噪自编码器在降噪自编码器的基础上加入稀疏因子,并没有改变降噪自编码器的本质,于是,参数传递依然可行。因此,本文用参数传递的方法实现两个模型的对接,以达到用稀疏降噪自编码器对模型参数进行预训练的目的。当稀疏降噪自编码器训练后得到的权值和偏置赋值给深度置信网络后,通过BP算法对整个深度置信网络(两层隐藏层)微调并在数字手写数据集和纸牌游戏数据集上验证,实验证明,用SDAE进行预训练能取得很好的结果。
基于稀疏降噪自编码器的深度置信网的流程如图3所示。
步骤1 建立并训练单隐层的稀疏降噪自编码器,得到权值W和偏置b。
步骤2 将第一步训练得到的权值W和偏置b赋值给DBN的第一层RBM,初始化RBM。由第一步的结果得知,稀疏降噪自编码器将会产生两个权值矩阵:编码过程生成W矩阵和解码过程生成W′矩阵,因W就能很好地学习输入中的特征[20],W′可被约束为权值矩阵W的转置,在模型参数传递中并没有明显的作用,因此本文直接将W矩阵赋值给RBM。
步骤3 建立并训练双隐层DBN并输出结果。
步骤4 输出错误率并解释分析数据。
以上四步形成了本文提出的模型:先建立并训练单隐层的稀疏降噪自编码器,随后将训练得到的权值和偏置赋值给第一层RBM,初始化RBM,之后建立并训练双隐层DBN并输出结果,最后通过模型输出的数据进行对比分析。
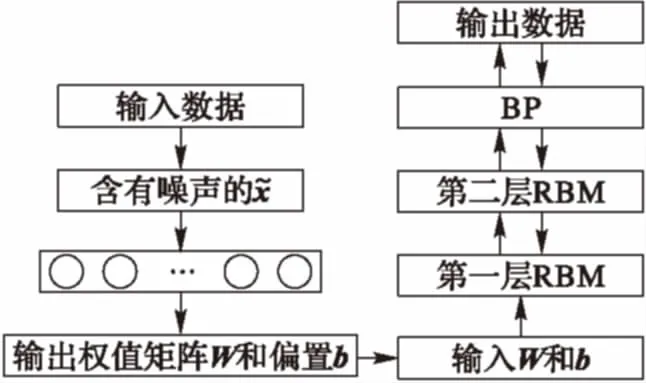
图3 基于稀疏降噪自编码器的深度置信网流程
3 实验分析
3.1 实验数据集
本文所采用的实验数据集为MNIST和USPS标准手写体库和Poker Hand扑克牌游戏数据集,MNIST和USPS标准手写体库各包含0~9共10个手写阿拉伯数字样本,实验中样本被归一化、中心化统一大小,数据集MNIST为28×28 的标准灰度图像,数据集USPS是16×16 的标准灰度图像。Poker Hand数据集是一种以扑克牌游戏的手牌牌型作为数据来源,数据包含10个随机属性。为保证实验的高效性(加快运行速度)和准确性,实验过程采用小批量数据模式,因此选取MNIST数据60 000 个训练样本和10 000个测试数据,批量大小为100;USPS数据选取7 290个训练样本和2 000 个测试样本,批量大小为10。Poker Hand数据选取25 010个训练样本和10 000个测试样本,批量大小为10。
3.2 实验参数设置
为了与本文提出的方法作一个详实的比较,本文一共实现了6个模型,分别是:
1)本文提出的基于稀疏降噪自编码器的深度置信网络(简称为DBNS)。先构建只含一个隐藏层的稀疏降噪自编码器网络,所得权值和偏置设置为RBM模型的初始化权值和阈值,然后利用有标签数据反向微调DBN网络。其中,DBN网络含有两个隐藏层,其节点数均为100,其输出层为Logistic分类层。
2)潘广源等[9]提出的DBN深度确定方法(简称为DBNN)。首先建立一个隐藏层并计算重构误差,通过判断重构误差是否小于预设值来增加模型的隐藏层数,最后反向微调整个网络以提高模型的精度。其中,本文设定重构误差正确率为99%以上,隐藏层节点个数均为100(包括增加的隐藏层)。
3)胡振等[12]提出的基于深度置信网络和级联去噪自编码器的混合模型(简称为SDA2_DBN2),SDA2_DBN2是一个五层的神经网络,包括两层降噪自编码、两层RBM和一层Logistic分类层。首先建立并初始化网络,随后无监督逐层预训练,最后,反向微调整个网络。
4)胡振等[12]提出的基于深度置信网络和级联去噪自编码器的混合模型的修改(简称为SDA_DBN2),由于文献[12]提出的模型深度较大导致训练时间较长,于是本实验在SDA2_DBN2的基础上减少一层降噪自编码,该模型包含四层。
5)传统的深度置信网络(DBN)[19],本文采用含有两个隐含层的深度神经网络(确保模型规模相同,方便对比)。
6)传统的稀疏降噪自编码器(SDAE)[20],本文采用含有两个隐含层的深度神经网络确保模型规模相同,方便对比。
3.3 实验结果
实验中,稀疏降噪子编码器的网络结构为:784-100(可视层-隐藏层),DBN的网络结构为:784-100-100(可视层-隐藏层-隐藏层),不同模型的实现结果比较如图4所示。图4表示的是随着迭代次数的增加,各模型分类误差的变化情况。其中图4(a)是在MNIST数据集上迭代50次的结果,图4(b)是在USPS数据集上迭代150次的结果(确保实验结果收敛),图4(c)是在Poker Hand数据集上迭代50次的结果。为保证实验数据准确率,数据均为5次实验求平均值的结果。
由图4可知,随着迭代次数的增加,网络的分类误差在不断地减小,直到趋于稳定。 基于数据集MNIST、USPS和Poker Hand,本文提出的模型分类误差率最低,在相同隐藏层层数的模型中收敛速度最快。
不同模型在不同数据集的分类误差率及训练时间见表1。

表1 不同数据集训练结果
由表1 MNIST数据集结果可知,在MNIST数据集上,本文方法(DBNS)误差率(2.02%)相比DBN降低了10.62%,时间缩短了2.02%;相比DBN深度确定方法(DBNN)(2.16%)降低了6.48%,训练时间却增加了,这是因为DBN深度确定方法建立的模型只含有一个隐藏层,训练时间较少;相比两个混合模型(即SDA2_DBN2和SDA_DBN2),误差率分别降低了6.05%和7.76%,训练时间分别缩短了31.26%和16.69%;相比SDAE,虽然训练时间几乎相同,但在误差率上有明显降低(8.60%)。不仅如此,本文方法在准确率和召回率相比其他5个模型均有提高。
由表1的USPS数据集结果可知,在USPS数据集上,本文方法的误差率(5.8%)比DBN深度确定方法(DBNN)误差率降低了30.54%,时间缩短了3.35%;比SDA2_DBN2和DBN误差率降低了21.09%,时间缩短了17.77%和3.86%;比SDA_DBN2误差率降低了16.55%,时间缩短了8.55%;比SDAE误差率降低了18.3%,时间缩短了2.96%。在准确率和召回率上,DBNS相比其余模型均有不同程度的提升。
由表1结果可知,在Poker Hand数据集上,本文方法的训练时间和DBN深度确定方法、DBN和SDAE相近,但是误差率(18.04%)比DBN误差率明显降低了46.4%,准确率和召回率显著提高(15.56%和14.13%);相比DBN深度确定方法误差率降低了41.8%,准确率和召回率提高了8.2%和4.78%;相比SDAE误差率降低了26.72%,准确率提高了7.95%;相比SDA_DBN2和SDA2_DBN2在训练效率上有显著提高(训练时间分别缩短28.09%和35.31%),误差率分别降低了32.61%和16.25%,准确率提升了9.82%和4%,召回率提升了9.88%和3.83%。
从上述的实验数据,可以看出本文提出的方法不仅在分类误差上低于其他模型,而且训练效率(包含SDAE训练效率)、准确率和召回率也相应得到提升。实验数据表明,用稀疏降噪自编码器初始化深度置信网络的方法是可行的,并且相比其他较为流行的模型,在分类精度和训练效率上都取得了较好的效果。
4 结语
由于稀疏降噪自编码器对输入数据具有较好的特征提取能力,本文提出了一种基于稀疏降噪自编码器的深度置信网络,将训练好的稀疏降噪自编码器的权值和偏置赋值给深度置信网络。在MNIST、USPS手写数据集和Poker Hand数据集上的实验结果表明,SDAE的有效训练使深度置信网络模型在一定程度上克服了易于陷入局部最优的弊端,有效降低了分类误差率并提高了训练效率和准确率。如何使网络在保证精度和效率的基础上更智能化,自动寻优参数以减少对先验经验的依赖,将是接下来研究的重点。
References)
[1] LECUN Y, BENGIO Y, HINTON G. Deep learning [J]. Nature, 2015, 521(7553): 436-444.
[2] ERHAN D, BENGIO Y, COURVILLE A, et al. Why does unsupervised pre-training help deep learning? [J]. Journal of Machine Learning Research, 2010, 11(3): 625-660.
[3] MOHAMED A R, DAHL G E, HINTON G. Acoustic modeling using deep belief networks [J]. IEEE Transactions on Audio Speech & Language Processing, 2012, 20(1): 14-22.
[4] WALID R, LASFAR A. Handwritten digit recognition using sparse deep architectures [C]// Proceedings of the 2014 9th International Conference on Intelligent Systems: Theories and Applications. Piscataway, NJ: IEEE, 2014: 1-6.
[5] BU S, LIU Z, HAN J, et al. Learning high-level feature by deep belief networks for 3-D model retrieval and recognition [J]. IEEE Transactions on Multimedia, 2014, 16(8): 2154-2167.
[6] SARIKAYA R, HINTON G E, DEORAS A. Application of deep belief networks for natural language understanding [J]. IEEE/ ACM Transactions on Audio Speech & Language Processing, 2014, 22(4): 778-784.
[7] HINTON G. A practical guide to training restricted Boltzmann machines [EB/OL]. [2016- 12- 12]. http://www.csri.utoronto.ca/~hinton/absps/guideTR.pdf.
[8] HINTON G E. Training products of experts by minimizing contrastive divergence [J]. Neural Computation, 2002, 14(8): 1771-1800.
[9] 潘广源,柴伟,乔俊飞.DBN网络的深度确定方法[J].控制与决策,2015,30(2):256-260.(PAN G Y, CHAI W, QIAO J F. Calculation for depth of deep belief network [J]. Control and Decision, 2015, 30(2): 256-260.)
[10] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting [J]. Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[11] RANZATO M, BOUREAU Y L, LECUN Y. Sparse feature learning for deep belief networks [J]. Advances in Neural Information Processing Systems, 2007, 20: 1185-1192.
[12] 胡振,傅昆,张长水.基于深度学习的作曲家分类问题[J].计算机研究与发展,2014,51(9):1945-1954.(HU Z, FU K, ZHANG C S. Audio classical composer identification by deep neural network [J]. Journal of Computer Research and Development, 2014, 51(9): 1945-1954.)
[13] BENGIO Y, LAMBLIN P, POPOVICI D, et al. Greedy layer-wise training of deep networks [C]// Proceedings of the 19th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2006: 153-160.
[14] VINCENT P, LAROCHELLE H, BENGIO Y, et al. Extracting and composing robust features with denoising autoencoders [C]// Proceedings of the 25th International Conference on Machine Learning. New York: ACM, 2008: 1096-1103.
[15] SALAKHUTDINOV R, HINTON G. Deep Boltzmann machines [J]. Journal of Machine Learning Research, 2009, 5(2): 1967 -2006.
[16] BENGIO Y, COURVILLE A C, VINCENT P. Unsupervised feature learning and deep learning: a review and new perspectives [EB/OL]. [2016- 12- 22]. http://docs.huihoo.com/deep-learning/Representation-Learning-A-Review-and-New-Perspectives-v1.pdf.
[17] VINCENT P, LAROCHELLE H, LAJOIE I, et al. Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion [J]. Journal of Machine Learning Research, 2010, 11: 3371-3408.
[18] LIU Y, ZHOU S, CHEN Q. Discriminative deep belief networks for visual data classification [J]. Pattern Recognition, 2011, 44(10/11): 2287-2296.
[19] XIE J, XU L, CHEN E. Image denoising and inpainting with deep neural networks [EB/OL]. [2016- 11- 27]. http://staff.ustc.edu.cn/~linlixu/papers/nips12.pdf.
[20] DENG L. A tutorial survey of architectures, algorithms, and applications for deep learning [EB/OL]. [2017- 01- 10]. https://www.cambridge.org/core/services/aop-cambridge-core/content/view/S2048770314000043.
[21] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks [J]. Science, 2006, 313(5786): 504-507.
Deepbeliefnetworksbasedonsparsedenoisingautoencoders
ZENG An1, ZHANG Yinan1, PAN Dan2*, Xiao-wei SONG3
(1.FacultyofComputerScience,GuangdongUniversityofTechnology,GuangzhouGuangdong510006,China;2.ModernEducationTechnicalCenter,GuangdongConstructionPolytechnic,GuangzhouGuangdong510440,China;3.ImageTechLab,SimonFraserUniversity,VancouverV6B5K3,Canada)
The conventional Deep Belief Network (DBN) often utilizes the method of randomly initializing the weights and bias of Restricted Boltzmann Machine(RBM) to initialize the network. Although it could overcome the problems of local optimality and long training time to some extent, it is still difficult to further achieve higher accuracy and better learning efficiency owing to the huge difference between reconstruction and original input resulting from random initialization. In view of the above-mentioned problem, a kind of DBN model based on Sparse Denoising AutoEncoder (SDAE) was proposed. The advantage of the advocated model was the feature extraction by SDAE. Firstly, SDAE was trained, and then, the obtained weights and bias were utilized to initialize DBN. Finally, DBN was trained. Experiments were performed on card game data set of Poker hand and handwriting data sets of MNIST and USPS to verify the performance of the proposed model. In Poker hand data set, compared with the conventional DBN, the error rate of the proposed model is lowered by 46.4%, the accuracy rate and the recall rate are improved by 15.56% and 14.12% respectively. The results exhibit that the proposed method is superior to other existing methods in recognition performance.
Deep Belief Network (DBN); Restricted Boltzmann Machine (RBM); Sparse Denoising AutoEncoder (SDAE); deep learning
2017- 03- 28;
2017- 06- 07。
国家自然科学基金资助项目(61300107);广东省自然科学基金资助项目(S2012010010212);广州市科技计划资助项目(201504301341059, 201505031501397)。
曾安(1978—),女,湖南新化人,教授,博士,CCF会员,主要研究方向:人工智能、数据挖掘; 张艺楠(1993—),女,广东兴宁人,硕士研究生,主要研究方向:数据挖掘; 潘丹(1975—),男,广东兴宁人,高级工程师,博士,主要研究方向:人工智能、数据挖掘、大数据;Xiao-Wei Song(1962—),女,北京人,研究员,博士,主要研究方向:脑科学、神经影像。
1001- 9081(2017)09- 2585- 05
10.11772/j.issn.1001- 9081.2017.09.2585
TP183
A
This work is partially supported by the National Natural Science Foundation of China (61300107), the Natural Science Foundation of Guangdong, China (S2012010010212), the Science and Technology Program of Guangzhou (201504301341059,201505031501397).
ZENGAn, born in 1978, Ph. D., professor. Her research interests include artificial intelligence, data mining.
ZHANGYinan, born in 1993, M. S. candidate. Her research interests include data mining.
PANDan, born in 1975, Ph. D., senior engineer. His research interests include artificial intelligence, data mining, big data.
Xiao-WeiSONG, born in 1962, Ph. D., researcher. Her research interests include brain science, neuroimaging.
