非对称信息条件下APT攻防博弈模型
2017-11-15孙文君
孙文君,苏 旸,曹 镇
(1.武警工程大学 网络与信息安全武警部队重点实验室,西安 710086; 2.武警工程大学 信息安全研究所,西安 710086)(*通信作者电子邮箱sunwenjun94@163.com)
非对称信息条件下APT攻防博弈模型
孙文君1*,苏 旸1,2,曹 镇1
(1.武警工程大学 网络与信息安全武警部队重点实验室,西安 710086; 2.武警工程大学 信息安全研究所,西安 710086)(*通信作者电子邮箱sunwenjun94@163.com)
针对目前缺少对高级持续威胁(APT)攻击理论建模分析的问题,提出了一种基于FlipIt模型的非对称信息条件下的攻防博弈模型。首先,将网络系统中的目标主机等资产抽象为目标资源节点,将攻防场景描述为攻防双方对目标资源的交替控制;然后,考虑到攻防双方在博弈中观察到的反馈信息的不对称性以及防御效果的不彻底性,给出了在防御者采取更新策略时攻防双方的收益模型及最优策略的条件,同时给出并分别证明了达到同步博弈与序贯博弈均衡条件的定理;最后通过数例分析了影响达到均衡时的策略及防御收益的因素,并比较了同步博弈均衡与序贯博弈均衡。结果表明周期策略是防御者的最优策略,并且与同步博弈均衡相比,防御者通过公布其策略达到序贯博弈均衡时的收益更大。实验结果表明所提模型能够在理论上指导应对隐蔽性APT攻击的防御策略。
博弈论;非对称信息;网络攻击;高级持续威胁;网络安全
0 引言
近年来,针对关键基础设施(Critical Infrastructure, CI)和政府、大型企业、军事机构等信息系统的高级持续威胁(Advanced Persistent Threat, APT)[1]攻击事件频发,信息资产受到的安全威胁越来越严重。APT攻击以其目标性强、隐蔽性高、方式多维性、不易被侦测等特点成为常用且危害巨大的攻击方式之一。传统的基于边界保护的网络防范技术往往只针对已知类型的一次性攻击,而APT攻击发动者往往通过社会工程学等手段非法获取内部权限,同时攻击者还利用零日漏洞实施攻击,这都使得传统网络防护技术效果甚微[2]。如何制定合理的策略、合理地分配防御成本以使防御收益最大化已成为防御的主要目标之一。
在网络安全领域,博弈论被广泛地应用于成本效益分析和最优策略选择等领域[3-4]:文献[5]和[6]分别从静态与动态方面给出了最优主动防御策略;陈永强等[7]设计了一种非零和攻防博弈模型,并通过分析纳什均衡实现最优对策的选择;张恒巍等[8]构建了基于信号博弈的攻防博弈模型,并通过量化计算分析了博弈均衡。然而上述研究都是面向已知攻击或完全信息的假设,而目前针对极高隐蔽性的、攻防信息不对称场景的博弈模型研究仍不多。针对APT攻击,RSA实验室的Van Dijk等[9]基于时间博弈的思想设计出了FlipIt模型,将网络系统中的资产抽象为资源节点,并将攻击者与防御者的博弈描述为对单个目标资源节点的交替控制的过程,双方的收益表现为对资源的控制时间上,并且在行动(即“Flip”)前都不知道资源当前的状态。FlipIt模型最大的特点是适用于隐蔽攻击的场景,并且详细分析了防御者采取不同策略的情况。但是FlipIt是一种抽象的基本模型框架,为了更贴近应用实际,后续的研究从对FlipIt模型进行改进与完善等方面展开。Bowers等[10]对FlipIt在安全场景中的实际应用展开了研究;Pham等[11]对博弈参与者的能力进行了扩展,研究了在参与者具备在行动前检查资源状态的能力的场景;Laszka等[12]对目标资源的数量进行了扩展提出了FlipThem模型,并分别讨论了在AND与OR控制模型条件下的最优策略;Zhang等[13]则对资源限制的条件下博弈及其均衡展开了分析;Feng等[14-15]对参与者的数量进行了扩展,引入了内部威胁者组成三方博弈并给出了相应的理论分析。
在上述文献中都假设攻击行为是瞬时的,但是实际中从攻击开始到完成往往需要耗费一定的时间;此外对防御者的能力也过于理想化,即使采取防御措施也不可能保证100%的效果[16],当攻击者仍持有对资源部分的控制权时,如仍在目标主机上留有后门,依然会因此获得攻击收益;而考虑到APT攻击发动者的能力,双方对博弈信息获取的不对称性是完全合理的。基于此本文提出了一种攻防双方信息非对称条件下的APT攻防博弈理论模型,分析了模型场景的最优策略及博弈均衡策略,并给出了相应的数例分析,结论表明周期策略是防御者的最优策略,并且防御者通过公布其策略达到序贯博弈均衡时的收益更大。
1 模型描述
1.1 FlipIt模型
Van Dijk等提出了应对APT等高隐蔽性攻击的博弈分析模型FlipIt。如图1所示,透明矩形表示的是资源受保护的状态,阴影矩形表示资源被入侵的状态,透明圆与阴影圆分别表示防御者与攻击者采取对策,竖箭头表示资源状态发生了变化。在FlipIt模型中,目标资源只有两个状态即要么处于受保护状态要么处于被入侵状态,只有在未拥有控制权的一方采取行动时发生状态的改变,而当双方同时行动时,或者已拥有控制权的一方采取行动时其状态保持不变。双方在采取行动前都不知道当前资源的状态,也不知道对方何时采取策略,并且每次行动都是有成本的,因此需要制定最优的策略。
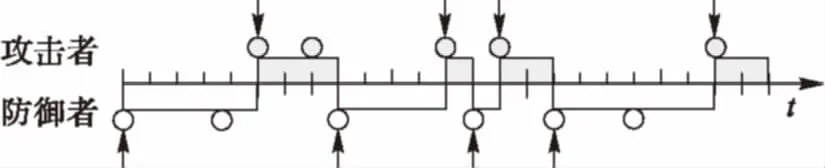
图1 FlipIt模型
FlipIt包含有系统安全的关键元素[17],但只是抽象的理想化的模型。本文在FlipIt及其相关扩展模型的基础上,针对APT攻击的高隐蔽性等特点,提出了一种在非对称信息条件下的网络攻防博弈模型,并推导出了纳什均衡及序贯均衡存在的定理。
1.2 本文模型
模型中两个参与者防御者与攻击者,分别用D和A表示。定义双方连续两次行动间的时间间隔为其各自的策略,采取不同的行动间隔表明采取不同的策略。模型的建立基于以下3个假设:
假设1 信息的不对称性,即攻击者可以观察到防御者执行行动,而防御者并不能观察到攻击者何时采取行动。
假设2 攻击的非瞬时性,即攻击者从展开攻击到攻击完成需要一定的攻击时间a,定义a是满足概率密度分布为fa(a)的随机变量,即攻击在a时间完成的概率为pa=1-e-λaa,Fa(a)为其对应的累积分布函数。
假设3 防御效果的不彻底性,即防御者采取行动后,攻击者仍有可能控制部分资源并据此获得收益,定义残留部分比例为服从概率密度函数分布为fε(·)的随机变量ε。
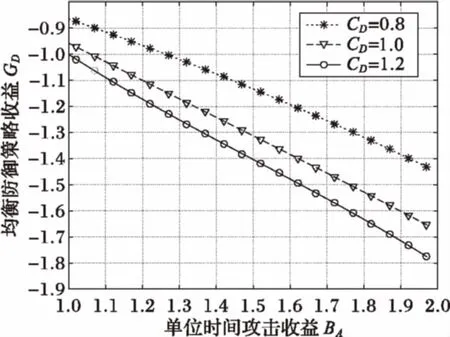
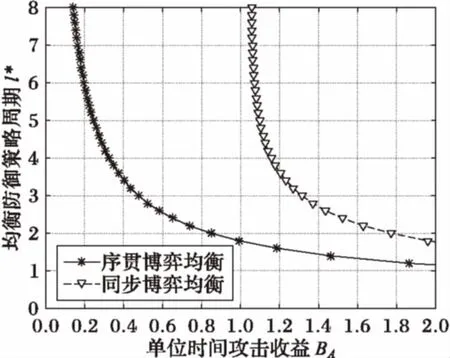
同时假设博弈在时间t上是连续的。如图2所示,在t=0博弈开始时目标资源处于受保护状态。在任意时刻,玩家A或D需要花费一定成本CA或CD实施行动。防御者采取行动的效果是即时的,并将立即获取资源的控制权,定义变量l为连续两次防御行动的时间间隔;但攻击者从行动实施到攻击完成是需要一个过程而并非是瞬时的,引入随机变量a表示该过程的时间。当攻击者未完成攻击而防御者又实施了下一次行动即a 图2 本文模型 文献[9]将参与者采取的策略分为适应性策略及非适应性策略。适应性策略表示参与者基于从博弈过程中接收到的反馈信息执行相应的对策,而非适应性策略则指参与者不接收反馈信息而执行相应的对策。更新策略是一种典型的非适应性策略,常见的更新策略包括周期策略及指数策略。在周期策略中,参与者每次行动间隔是固定的周期,而第一次行动则从中均匀随机选取某一相位开始;指数策略是一种常见的更新策略,参与者两次连续行动间隔服从指数分布(泊松分布)。在本文中,由于防御者不能接收到反馈信息,因此设定其采取的是更新策略。 考虑在某个防御间隔内l的攻防双方的平均收益。 1)a>l。 在这种情况下,攻击者未完成攻击控制目标资源防御者便采取了下一次的行动。此时由于假设的防御对策效果的不彻底性,攻击者仍能由于之前的行动而拥有对目标的部分控制权ε。故此时攻击者在[0,l]内的期望收益表示为: (1) 对防御者而言,收益包括因攻击招致的损失和行动成本,因此期望收益表示如下: (2) 但是由于式(1)、(2)是在a>l条件之下得出的,而由式(1)可得出a>l成立的概率: (3) 综合式(1)、(2)、(3)得出攻防双方的条件期望收益分别为: (4) (5) 2)a≤l。 在这种情况下,攻击者可在防御者下一次行动之前完成攻击并且控制目标系统,则其收益函数在条件1)的基础上还要增加控制目标后单位时间带来的效用,期望收益表示如下: (6) 防御者则相应地增加了因攻击者控制目标资源带来的损失,其期望收益表示为: (7) 同样地考虑其条件期望收益。a≤l条件成立的概率为: (8) 则由式(6)、(7)、(8)可得出攻防双方的条件期望收益分别为: (9) (10) 综合1)、2)两种情况,得出最后的攻击者与防御者的收益函数表达式分别为: (11) (12) 在实际分析中,可将具体的函数及参数值代入表达式中计算。 在得到博弈的收益模型后,需要对双方最优应对及均衡存在的条件进行分析。由于双方的收益是在防御者的行动间隔内完成的,因此本文对任意某个时间区间进行分析,任意区间内收益最大化时则总的收益也可达到最大化。 首先分析防御者最优应对策略。由前文假设,即使攻击者没有完成攻击,由于防护行动效果的不彻底性,攻击者仍有部分目标资源的控制权ε。为了便于分析,首先假设在整个博弈中ε是个常量。给出防御者最优应对策略的条件。 引理1 定义 (13) 则当攻击者采取适应性策略,并且其从上一次防护行动结束到攻击完成的时间a服从固定的条件概率分布fa(a)时,有: 1)如果不存在l使得BRD=0成立,则不采取任何行动是防御者的最优应对策略; 2)否则以满足BRD=0的解l*为周期的周期策略是唯一的最优应对策略。 证明 当防御者采取更新策略时,其选择的每个行动间隔都是服从某一固定分布的。为了获取最优应对策略,需要使得每个行动间隔li内的收益最大化。由式(12)可知其收益公式为 (14) 为了获得极值,需求GD关于l的偏导: (15) (16) 显然BRD是关于l的单调递增函数,故如果存在着l*使BRD=0成立,那么该l的值是唯一的。此外,当取l=l*时,GD关于l的二阶偏导数 (17) 即当l取使等式(13)成立的唯一值l*时GD取得最大值,即有最大收益。因此,采取周期为l*的周期策略是此时防御者的最优应对策略。而当不存在l满足式(13)时,若l→∞,防御者的期望收益GD→-BA,相当于是不采取任何策略时的收益;若l→0,GD→-∞。因此当不存在l满足等式(13)时,防御者的期望收益都小于-BA,防御者的最优策略为不采取任何行动。 证毕。 接下来分析攻击者的最优应对策略。 引理2 当防御者采取周期为l的周期策略时,令: (18) 1)若CA 2)若CA>M(l),则攻击者的最优应对策略是不采取任何行动; 3)若CA=M(l),则无论是不采取行动或者立即实施攻击都可视为攻击者的最优应对策略。 证明 首先计算攻击者的期望收益。 (19) 因此当CA 证毕。 基于引理1与引理2,得出均衡存在定理。首先考虑攻击者与防御者的行为是同步的,得出纳什均衡存在定理。 定理1 当防御者采取更新策略而攻击者采取适用性策略时,则博弈均衡为: 1)当BRD=0存在解l*为防御者的最优策略时,则 ①如果CA≤M(l*),则存在唯一的纳什均衡策略:防御者采取周期为l*的周期性策略而攻击者在观察到攻击者采取行动时也立即采取攻击行为; ②如果CA>M(l*),则不存在纳什均衡。 2)当BRD=0不存在解l*作为防御者的最优策略时,则存在唯一的纳什均衡策略:防御者不采取任何行动而攻击者在博弈开始时展开一次攻击之后便不采取任何行动。 证明 由引理1知防御者的最优应对策略是采取周期策略或者不采取任何行动。同样地由引理2可知攻击者最优应对策略也是两种即在观察到防御者的行为后立即攻击或者不发动任何攻击。而纳什均衡策略对参与双方来说都是其最优应对策略。 首先考虑当BRD=0不存在解的情况,此时防御者的最优策略是从博弈开始到结束都不采取任何行动,因此攻击者只需在博弈开始的时候实施一次攻击便能一直控制目标系统获得最大收益,即2)成立。 其次考虑当BRD=0存在唯一解l*时,防御者的最优策略是采用参数为l*的周期策略,根据引理2可知攻击者面临两种选择:当CA≤M(l*)时,攻击者的最优应对策略是在观察到防御者的防御行为之后立即采取攻击行动,即满足条件1)中的①条件;当CA>M(l*)时,攻击者不采取任何行动并退出博弈,此时由于没有攻击者的参与,防御者的最优策略是不采取任何行动以减少防御行动成本,但是如果防御者这么做的话,对于攻击者来说在博弈一开始就采取攻击并持续控制目标资源能够获得最大收益,因此这种情况下不存在纳什均衡,即证明了条件1)中的②条件。证毕。 至此已经找到了攻防双方同时博弈条件下的均衡。但在实际应用中,考虑到信息的不对称性,防御策略可能被攻击者提前获知,这种情况下就需要求导序贯博弈。定理2给出了序贯均衡条件。 定理2 令l1为BRD=0的解,l2为使得CA=M(l)成立的最大值,攻击者总是采取最优策略,那么在子博弈精炼均衡中,防御者的最优策略为不采取行动或者采取周期为{l1,l2}的周期策略。 证明 使用反证法进行验证。假设防御者采用的是周期为l′(l′不等于l1或l2)的周期策略。 1)若l′>l2,则必有CA 2)若l′ 证毕。 为了能直观形象地说明模型的特点,对模型进行实例化分析。设置从攻击实施到攻击完成需要的时间a服从的指数分布λa=1,因防御行为的效果不彻底性导致的攻击者剩余控制比例ε=0.05。 图3、图4分别给出了达到同时博弈时的防御者的行动周期和收益与攻击者单位时间内的收益BA以及当防御成本分别取CD=1.2、CD=1.0、CD=0.8时的曲线图。 图3 达到同步博弈均衡时的防御策略 由图3、4可知,CD越高时,防御者将采取均衡策略的周期越也大,其相应的防御收益也越低,即因防御成本升高防御者从收益的角度考虑而不得不降低其防御速率,比如当BA=1.2时,当CD分别取0.8、1.0和1.2时的均衡策略周期为2.44、3.62和∞,而其对应的防御收益为-0.97、-1.10和-1.18。而另一方面,当BA越大,即目标资源价值越大时,防御者的防御速率越快,所需的防御成本也增加,导致相应的防御收益降低,例如当CD=1.0时,当BA分别取1.2、1.4、1.6时对应的策略周期分别为3.62、2.71、2.25,防御收益分别为-1.10、-1.25、-1.39。但是当目标资源的价值BA太低时防御者的行动周期l*→∞,表明防御者退出博弈并不采取任何的防御行为。这些结论都与实际场景中相符合。 图4 达到同步博弈均衡时的防御收益 图5、图6分别给出了在CA=1.0且CD=1.0条件下达到序贯博弈均衡与同步博弈均衡时的防御周期、防御收益与攻击者单位时间内的收益的关系曲线。 图5 序贯博弈均衡与同步博弈均衡的防御周期比较 图6 序贯博弈均衡与同步博弈均衡的防御收益比较 从图5图6中可知序贯博弈均衡下的防御周期和收益与BA的关系与同步均衡时类似。另外可看出,当BA及其他条件相同时,序贯博弈均衡下的防御周期比同步博弈均衡条件下的防御周期要短,相应的防御收益却要更大,例如当BA=1.2时,序贯均衡与同步均衡时的防御周期分别为1.59和3.62,对应的防御收益分别为-0.63和-1.10。说明当防御者采取快速的防御速率并达到序贯均衡时会因迫使攻击者放弃行动而获得比同步均衡时更大的收益。 本文对FlipIt模型进行了扩展,结合攻防场景中攻击的隐蔽性、攻防双方信息的不对称性等特点,并考虑到因攻击者使用零日漏洞等未知攻击手段而导致的防御对策的效果不彻底性,建立了面向APT攻击的攻防博弈模型。通过建模理论分析推导与实例验证,主要得出两点结论:1)周期策略是防御者的最优策略,可带来最大收益;2)面对能力强的攻击者,防御者应当提前公布其策略以对攻击者产生震慑,迫使其因收益为负而放弃攻击。另外,通过分析还可知,当防御成本越高时防御者采取行动的速度也会越慢。这些结论对现实中如何改进防御措施具有一定的理论指导意义。 为了便于分析,本文提出了许多假设,例如假定ε在博弈中是固定不变的。今后的研究重点是减少假设条件,特别是对完全不知道其攻击能力及攻击完成时间分布fa(a)时的场景展开研究以使模型更加符合实际。 References) [1] TANKARD C. Advanced persistent threats and how to monitor and deter them [J]. Network Security, 2011, 2011(8): 16-19. [2] 付钰,李洪成,吴晓平,等.基于大数据分析的APT攻击检测研究综述[J].通信学报,2015,36(11):1-14.(FU Y, LI H C, WU X P, et al. Detecting APT attacks: a survey from the perspective of big data analysis [J]. Journal on Communications, 2015, 36(11): 1-14.) [3] RASS S, KÖNIG S, SCHAUER S. Defending against advanced persistent threats using game-theory [J]. Plos One, 2017, 12(1): e0168675. [4] MANSHAEI M H, ZHU Q, ALPCAN T, et al. Game theory meets network security and privacy [J]. ACM Computing Surveys, 2013, 45(3): Article No. 25. [5] 姜伟,方滨兴,田志宏,等.基于攻防博弈模型的网络安全测评和最优主动防御[J].计算机学报,2009,32(4):817-827.(JIANG W, FANG B X, TIAN Z H, et al. Evaluating network security and optimal active defense based on attack-defense game model [J]. Chinese Journal of Computers, 2009, 32(4): 817-827.) [6] 林旺群,王慧,刘家红,等.基于非合作动态博弈的网络安全主动防御技术研究[J].计算机研究与发展,2011,48(2):306-316.(LIN W Q, WANG H, LIU J H, et al. Research on active defense technology in network security based on non-cooperative dynamic game theory [J]. Journal of Computer Research and Development, 2011, 48(2): 306-316.) [7] 陈永强,付钰,吴晓平.基于非零和攻防博弈模型的主动防御策略选取方法[J].计算机应用,2013,33(5):1347-1352.(CHEN Y Q, FU Y, WU X P. Active defense strategy selection based on non-zero-sum attack-defense game model [J]. Journal of Computer Applications, 2013, 33(5): 1347-1352.) [8] 张恒巍,余定坤,韩继红,等.基于攻防信号博弈模型的防御策略选取方法[J].通信学报,2016,37(5):51-61.(ZHANG H W, YU D K, HAN J H, et al. Defense policies selection method based on attack-defense signaling game model [J]. Journal on Communications, 2016, 37(5): 51-61.) [9] VAN DIJK M, JUELS A, OPREA A, et al. FlipIt: the game of “stealthy takeover” [J]. Journal of Cryptology, 2013, 26(4): 655-713. [10] BOWERS K D, VAN DIJK M, GRIFFIN R, et al. Defending against the unknown enemy: applying flipIt to system security [C]// International Conference on Decision and Game Theory for Security, LNCS 7638. Berlin: Springer, 2012: 248-263. [11] PHAM V, CID C. Are we compromised? Modelling security assessment games [C]// International Conference on Decision and Game Theory for Security, LNCS 7638. Berlin: Springer, 2012: 234-247. [12] LASZKA A, HORVATH G, FELEGYHAZI M, et al. FlipThem: modeling targeted attacks with flipIt for multiple resources [C]// International Conference on Decision and Game Theory for Security, LNCS 8840. Berlin: Springer, 2014: 175-194. [13] ZHANG M, ZHENG Z Z, SHROFF N B. Stealthy attacks and observable defenses: a game theoretic model under strict resource constraints [C]// Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing. Piscataway, NJ: IEEE, 2014: 813-817. [14] FENG X, ZHENG Z, HU P, et al. Stealthy attacks meets insider threats: a three-player game model [C]// Proceedings of the 2015 IEEE Military Communications Conference. Piscataway, NJ: IEEE, 2015: 25-30. [15] FENG X, ZHENG Z, CANSEVER D, et al. Stealthy attacks with insider information: a game theoretic model with asymmetric feedback [EB/OL]. [2016- 11- 22]. http://spirit.cs.ucdavis.edu/pubs/conf/xiaotao-milcom16.pdf. [16] FARHANG S, GROSSKLAGS J. FlipLeakage: a game-theoretic approach to protect against stealthy attackers in the presence of information leakage [C]// International Conference on Decision and Game Theory for Security, LNCS 9996. Berlin: Springer, 2016: 195-214. [17] 黄康宇,徐伟光.移动目标防御时间博弈相关研究介绍[J].军事通信技术,2016,37(4):98-102.(HUANG K Y, XU W G. Games of timing in moving target defense [J]. Journal of Military Communications Technology, 2016, 37(4): 98-102.) Attack-defensegamemodelforadvancedpersistentthreatswithasymmetricinformation SUN Wenjun1*, SU Yang1,2, CAO Zhen2 (1.KeyLaboratoryofNetwork&InformationSecurity,UniversityofthePeople’sArmedPoliceForce,Xi’anShaanxi710086,China;2.InstituteofInformationSecurity,UniversityofthePeople’sArmedPoliceForce,Xi’anShaanxi710086,China) To solve the problem of the lack of modeling and analysis of Advanced Persistent Threat (APT) attacks, an attack-defense game model based on FlipIt with asymmetric information was proposed. Firstly, the assets such as targeted hosts in the network system were abstracted as the target resource nodes and the attack-defense scenarios were described as the alternating control of the target nodes. Then, considering the asymmetry of the feedback information observed by the two sides and the incomplete defensive effect, the conditions of the payoff model and the optimal strategy of the attacker and defender were proposed in the case of renewal defense strategy. Besides, theorems of simultaneous and sequential equilibrium were proposed and demonstrated. Finally, numerical illustrations were given to analyze the factors of equilibrium strategy as well as defense payoff and to compare simultaneous and sequential equilibrium. The experimental results show that period strategy is defender’s best strategy and the defender can achieve sequential equilibrium meanwhile obtaining more payoffs compared with simultaneous equilibrium by announcing her defense strategy in advance. Conclusions show that the proposed model can theoretically guide defense strategy towards stealthy APT attacks. game theory; asymmetric information; network attack; Advanced Persistent Threat (APT); cyber security 2017- 03- 17; 2017- 04- 13。 国家自然科学基金资助项目(61402531);陕西省自然科学基础研究计划项目(2014JQ8358, 2015JQ6231, 2014JQ8307)。 孙文君(1994—),男,江西上饶人,硕士研究生,CCF会员,主要研究方向:信息安全、网络攻防; 苏旸(1975—),男,陕西西安人,教授,博士,CCF会员,主要研究方向:信息安全、网络攻防; 曹镇(1994—),男,山东菏泽人,硕士研究生,主要研究方向:信息安全、信息隐藏。 1001- 9081(2017)09- 2557- 06 10.11772/j.issn.1001- 9081.2017.09.2557 TP393.08 A This work is partially supported by the National Natural Science Foundation of China (61402531), the Natural Science Foundation Research Project of Shaanxi Province (2014JQ8358, 2015JQ6231, 2014JQ8307). SUNWenjun, born in 1994, M. S. candidate. His research interests include information security, network attack and defense. SUYang, born in 1975, Ph. D., professor. His research interests include information security, network attack and defense. CAOZhen, born in 1994, M. S. candidate. His research interests include image security, steganography.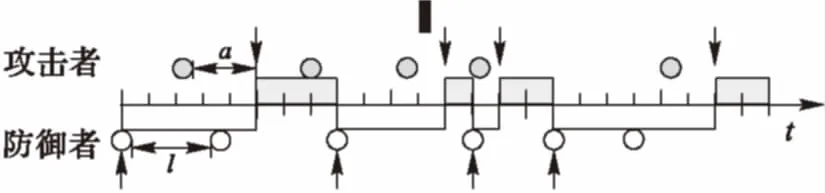
2 收益模型






3 理论分析

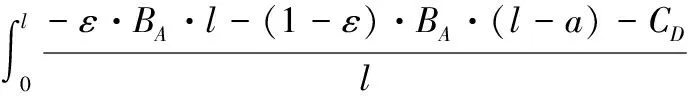

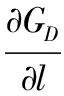




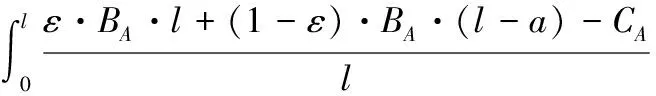


4 数例分析


5 结语
